









作者:馬龍傑(澄諾) 阿里巴巴中國電商事業羣-餓了麼-DIC數據智能中心-數據研發流量組
摘要:實時湖倉架構賦能即時零售,在多端流量與億級營銷投入下支撐分鐘級決策與體驗升級。
導讀:
當“秋天的第一杯奶茶”衝上熱搜時,很多人看到的是用户的熱情與訂單的暴漲,而在背後,技術團隊同樣在全力以赴。自 4 月 30 日淘寶閃購上線以來,短短 100 天,業務團隊創造了一個奇蹟,技術團隊則在高併發與海量數據的衝擊下迎來前所未有的挑戰。
閃購項目期間,億級營銷投入疊加多端流量,實時決策與調控對數據提出了分鐘級的要求。為應對挑戰,餓了麼數據團隊依託一年多的湖倉探索與沉澱,選擇 StarRocks + Paimon 搭建實時湖倉架構,並通過物化視圖優化、RoaringBitmap 去重和大查詢治理,突破了傳統離線架構的瓶頸,為閃購提供了堅實的數據支撐。
本文將根據閃購項目的實戰過程,分享過程中沉澱下的經驗與思考。
一、背景

在即時零售業務蓬勃發展的背景下,淘寶閃購項目正式啓動,標誌着外賣行業迎來新一輪激烈競爭。數據驅動決策已成為商業戰場的核心競爭力,而傳統離線架構的時效性短板正成為業務突破的關鍵瓶頸。此前,餓了麼數據體系以T+1離線處理為主,實時數據因高昂的開發成本和計算資源,僅覆蓋了大盤核心指標。閃購項目期間多端多觸點流量及億級營銷投入對實時決策和實時調控提出更高要求。海量數據需在分鐘級完成採集、清洗、分析與可視化。為了應對這些挑戰,餓了麼數據團隊基於過去一年多在湖倉領域的探索和技術沉澱,通過 StarRocks 與 Paimon 的實時湖倉架構,支撐了海量數據實時分析能力。並進一步通過以下技術手段顯著提升了實時分析性能:
- 物化視圖優化:StarRocks 的異步物化視圖功能被用於預計算高頻查詢場景,通過將複雜計算結果持久化存儲,將原本需要掃描千億級數據的查詢耗時從分鐘級壓縮至秒級
- RoaringBitmap 去重:針對超大數據量多維度實時交叉去重指標計算場景,團隊引入RoaringBitmap 技術,結合Paimon 的流讀流寫能力和 StarRocks 豐富的 Bitmap 函數支持,在保障查詢性能的同時,業務可以查詢實時數據進行任意維度的靈活分析
- 大查詢管理:利用社區提供的工具及 StarRocks 自身的組件實現集羣監控報警和診斷分析的可視化管理,並使用 SQL 優化、資源隔離等方式來保障集羣的持續穩定性。
該架構升級最終實現三大核心價值:存儲成本大幅降低,實時分析鏈路端到端延遲顯著下降,並支撐海量日誌數據的高併發查詢場景,為業務決策提供了可靠的實時數據支撐。
二、StarRocks&Paimon 技術原理簡介
Paimon 作為流批一體的實時數據湖存儲框架,支持 OSS、S3、HDFS 等多種對象存儲格式,深度融入Flink、Spark生態及多款 OLAP 查詢引擎,專注於解決大規模數據場景下的低延遲寫入、高效更新和實時分析難題。
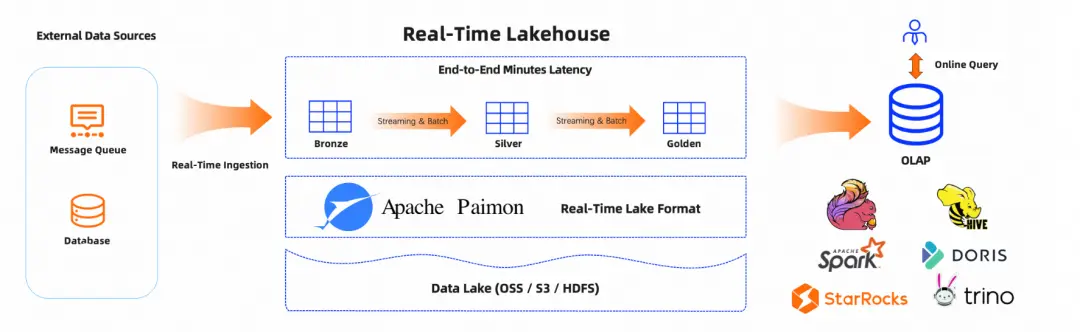
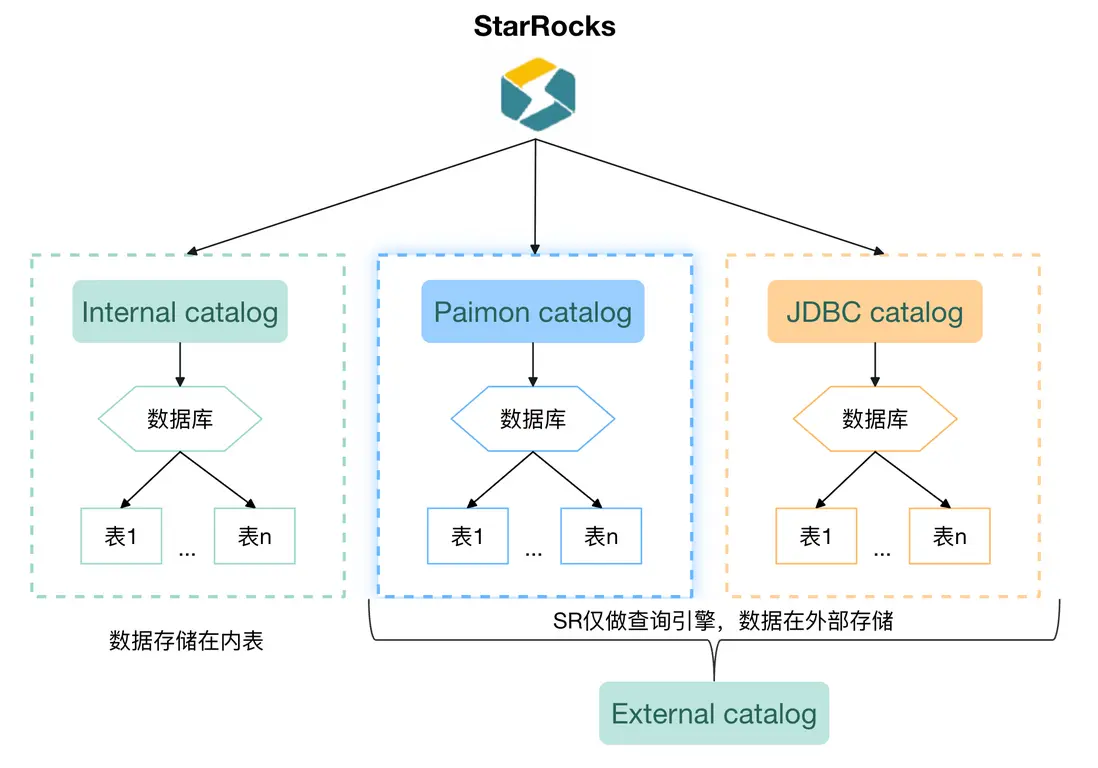
StarRocks 作為一款極速統一的 MPP 數據庫,利用其 Catalog 功能,可以接入多種外部數據源,如 Paimon、Hive、MaxCompute、Hudi、Iceberg 及其他可通過 JDBC 協議連接的各種數據庫等。StarRocks 內部通過維護這些外部數據源的元數據信息,直接訪問外表數據,我們無需在不同介質間進行數據的導入導出。此外,阿里雲EMR 團隊針對 Lakehouse 場景做了進一步的優化,在開啓 Paimon 表的 deletion-vectors 屬性後,StarRocks 查詢 Paimon湖表的性能有了十倍以上的提升。因此,我們業務上可以不經過 ETL 操作,直接使用 StarRocks+Paimon 的方案迅速搭建數據看板。
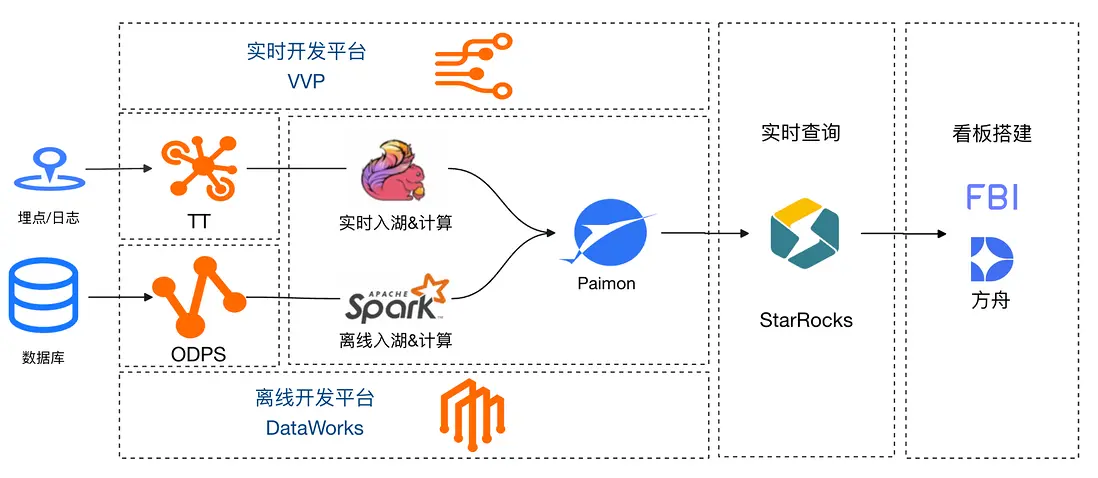
兩者結合可以實現 1+1 遠大於 2 的效果。淘寶閃購項目作戰期間,BI 與業務運營想要查看當日流量漏斗及各渠道投放轉化效率,以便及時進行分析彙報和調整運營策略。我們將實時流量數據通過 Flink 入湖,維表數據通過 Spark 入湖,StarRocks 作為計算引擎直接查詢Paimon湖表,FBI接入SQL數據集搭建實時看板,快速解決了業務實時看數需求。
三、物化視圖:StarRocks 助力 Paimon 解鎖查詢新體驗
在閃購項目初期,StarRocks 與 Paimon 的組合確實滿足了基礎數據服務需求,但隨着業務規模的指數級增長,實時分析性能瓶頸逐漸顯現。當單日流量峯值突破閾值後,複雜查詢響應時間從秒級惡化至分鐘級,核心業務看板的刷新延遲大幅增加,直接影響了運營決策效率。為解決這一挑戰,我們基於 StarRocks 的物化視圖技術構建了優化體系:
物化視圖分層加速架構
- 預計算層:針對高頻訪問的複雜查詢(如多表關聯、窗口聚合),通過 StarRocks 物化視圖預計算結果集,查詢響應時間降低 80% 以上
- 更新機制:我們維護了 120+ 個物化視圖,平均 15min 刷新間隔,最高支撐了單分區千億級別的數據物化加速
- 資源隔離策略:通過 FE 節點(25個)與 CN 節點(120個,總9280 CU)的混合部署,將物化視圖刷新任務與實時查詢流量隔離,支撐單日業務有效查詢數量峯值為 17萬/天(含1萬+物化刷新任務),項目後期 CN 節點擴至 300 個,集羣規模達到 20800 CU。
實時看板建設實踐
基於優化後的架構,我們搭建了覆蓋全鏈路的實時分析體系:
- 流量全景看板:聚合用户行為、渠道來源、訪購轉化等多維度數據,支持分鐘級漏斗分析與流量渠道 ROI 計算
- 動態資源看板:通過 StarRocks 內置的資源監控接口,實現集羣負載動態可視化,物化視圖刷新成功率穩定在99.9% 以上
- 異常診斷看板:集成 EMR Serverless StarRocks 的智能診斷平台,快速定位慢查詢,問題定位效率提升 60%
下面我們展開介紹一下在落地 StarRocks 物化視圖過程中的一些實踐經驗。
3.1 StarRocks&Paimon 物化視圖原理
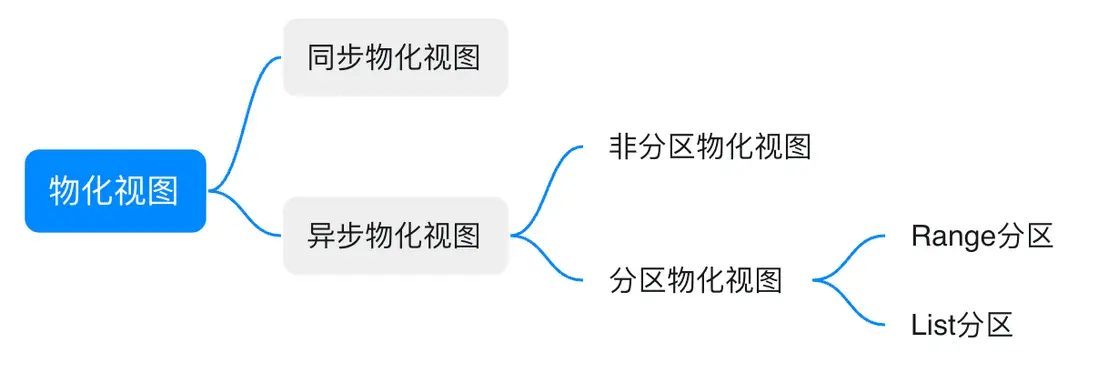
StarRocks 的物化視圖主要分為同步物化視圖和異步物化視圖兩大類:
- 同步物化視圖:只支持單表,在導入過程中同步刷新。基表只能是內表,不支持 Paimon 表
-
異步物化視圖:支持多表,同時支持異步刷新/手動刷新。基表支持 Paimon 表
- 非分區物化視圖:執行完整查詢,全量覆蓋視圖數據,可以用於熱點數據加速
-
分區物化視圖:根據參數及基表數據變更情況,以分區粒度刷新視圖,可以用於長週期存儲數據。其中物化視圖分區支持下面兩類
- Range 分區:通常以 date 類型作為分區字段,可使用 date_trunc 函數實現分區上卷
- List 分區:3.3.5 版本支持,分區字段為可枚舉的 string 類型或不連續的 int 類型
同步物化視圖作為基表的附屬結構,與基表數據實時同步,但使用場景較為侷限,比較典型的場景是使用 Bitmap 或HLL 在內表中進行去重計算,我們所使用的物化視圖通常為異步物化視圖。
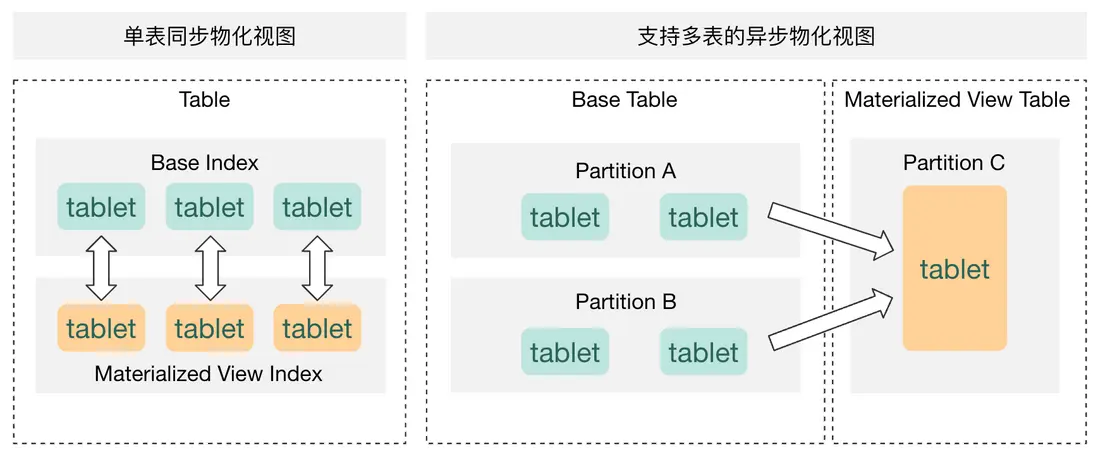
異步物化視圖的調度框架主要有兩個核心概念:Task 是週期運行的刷新任務,TaskRun 為每次刷新週期的運行實例。我們可以通過系統參數來設置 TaskRun 的最大 Pending 數量,Running 的併發數量及生命週期等。
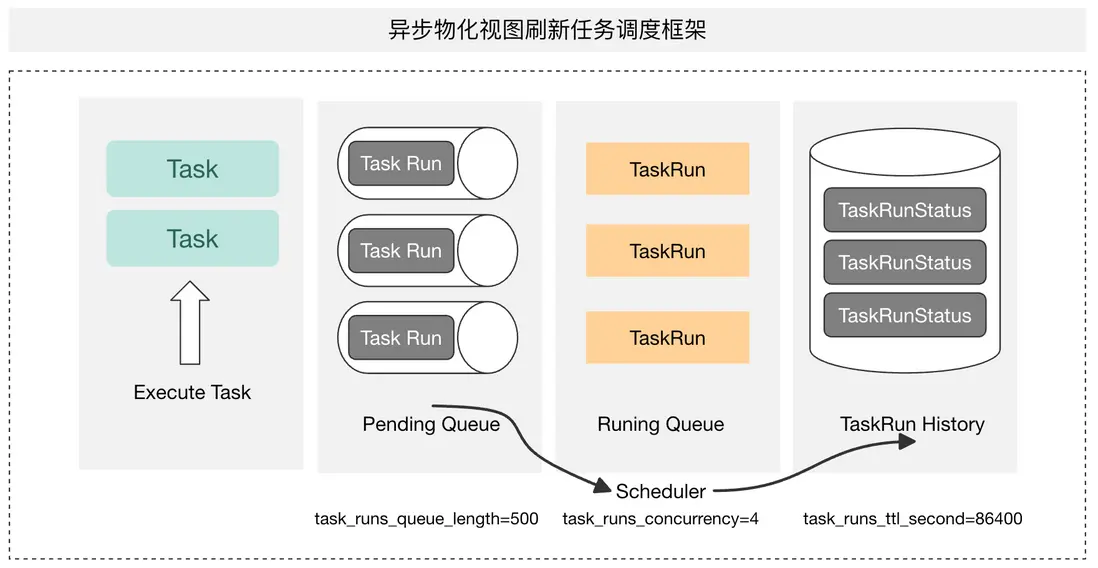
對於帶分區的物化視圖,主要通過與上游基表的分區依賴和數據變化來刷新對應視圖分區,可以通過參數控制刷新行為,對比物化視圖與基表對應分區的可見版本,來判定需要刷新的分區,以防止過多分區刷新導致的資源浪費;
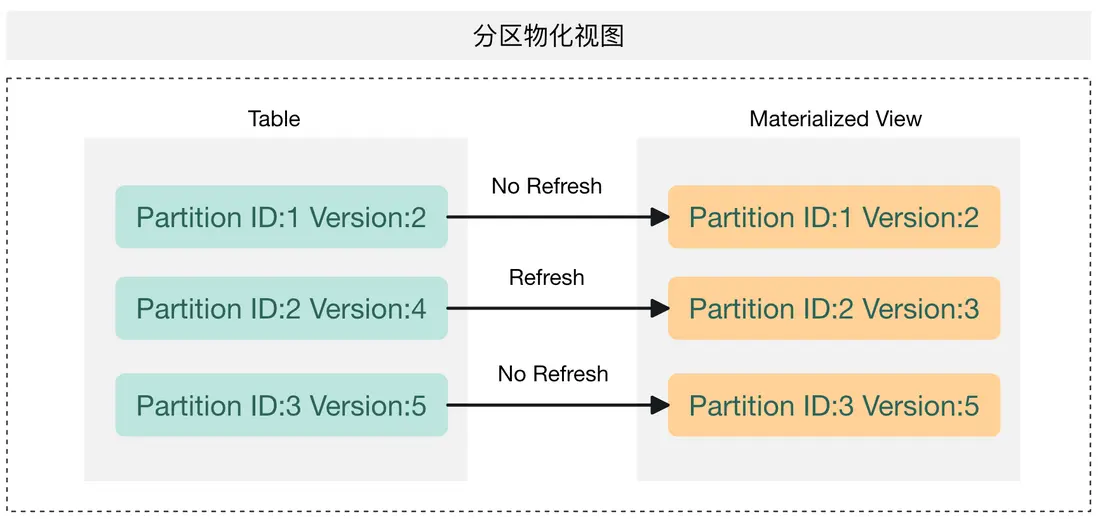
每次刷新都是通過生成一個 insert overwrite 任務,先創建臨時分區並寫數據,然後將臨時分區與目標分區進行原子替換
3.2 StarRocks&Paimon 物化視圖在淘寶閃購的應用
3.2.1 優化1:基礎 Paimon 物化視圖
隨着閃購流量連續幾天的飛速增長,直查湖表的實時看板性能越來越差,項目初期使用加資源的方式解決,但看板人數也在逐步增加,對集羣的穩定性也造成了一定影響,因此,我們在 StarRocks 與 Paimon 之間,針對看板數據集的查詢 SQL 進行了物化處理,每十分鐘進行一次刷新,加速查詢的同時緩解集羣大查詢帶來的壓力。
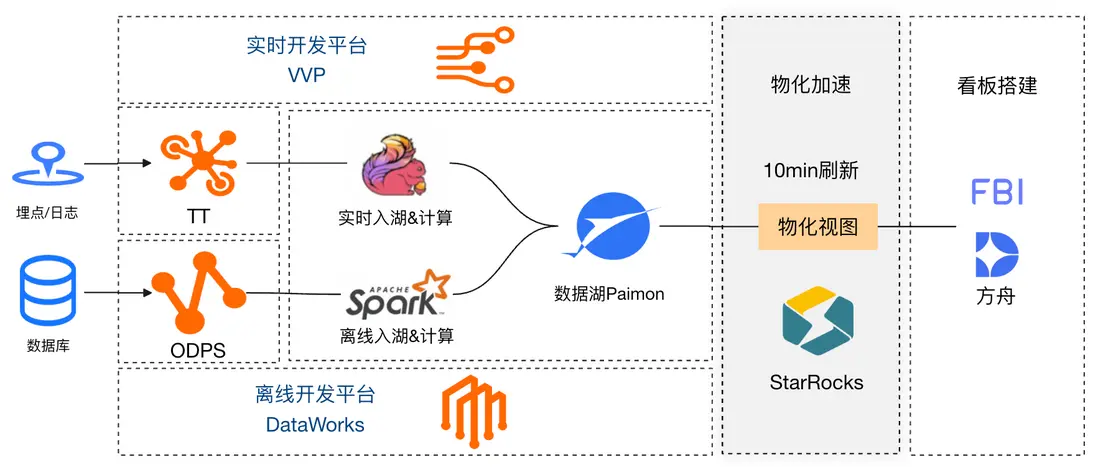
3.2.2 優化2:針對長週期歷史數據的查詢優化
項目上線一段時間後,業務需要查看日環比、周同比指標,提出了長週期數據存儲訴求,於是在原有方案基礎上,加了一條 DataWorks 凌晨離線 insert 調度任務將前一天數據寫到 StarRocks 內表,然後將當日實時數據與歷史離線數據 UNION 為一個虛擬視圖。
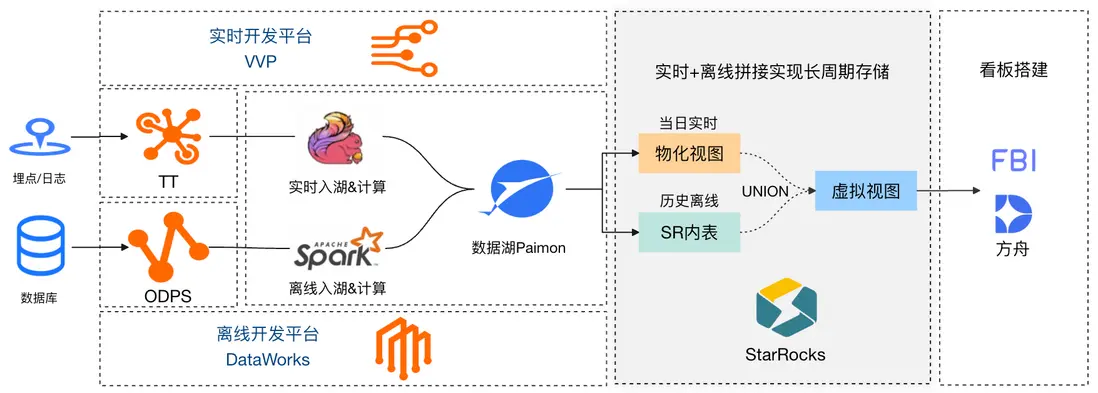
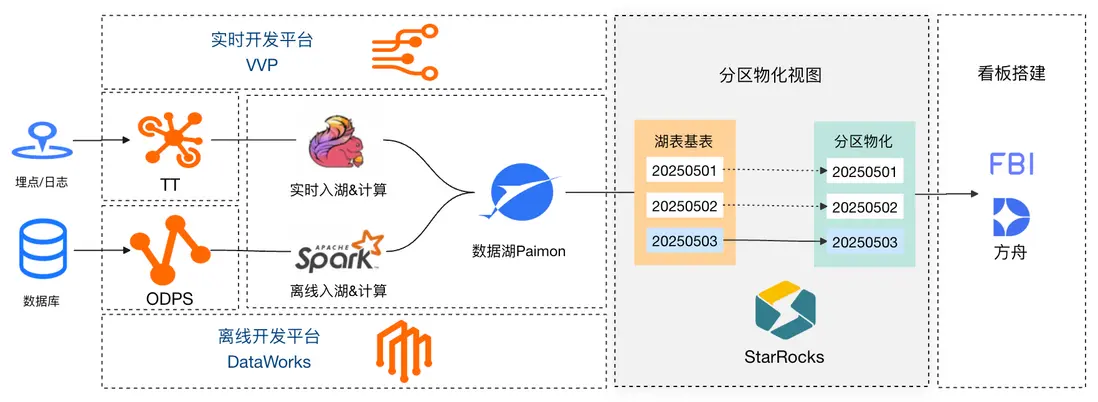
3.2.3 優化3:引入帶分區的物化視圖
在我們使用的阿里雲 EMR StarRocks 3.3 版本中,支持了基於 Paimon 湖表的分區物化視圖以及多基表分區對齊特性,我們將優化1 中的物化視圖直接改為分區物化視圖以支持歷史數據存儲。對比優化2,使用分區物化視圖可以極大簡化運維,使用分區物化時,只需要使用 PARTITION BY 指定分區字段(需要與基表分區對應)。但這裏需要注意,湖表生命週期縮短時,物化視圖在下次觸發刷新也會刪除對應分區,所以當視圖需要存儲的數據週期大於基表時,仍需要使用優化2中方式實現。
分區物化視圖定義中不需要限制分區字段取值範圍,我們在創建分區物化視圖時通過設置 PROPERTIES 來控制刷新行為,存儲近 30 天分區("partition_ttl_number" = "30"),並根據事實表數據變動每次至多觸發兩個分區刷新("auto_refresh_partitions_limit" = "2"),每個調度實例只刷新一個分區("partition_refresh_number" = "1"),同時配置 excluded_trigger_tables 參數來忽略維度表變動觸發的刷新行為。
3.3 StarRocks&Paimon物化視圖實踐總結
StarRocks 物化視圖開發成本低,迭代方便快捷。非常適合在戰時以極高的效率交付業務看數需求,並快速應對作戰期間的業務調整和口徑頻繁變更的情況。在數據湖加速、查詢改寫、項目初期的數據分層建模等場景中非常適用。我們需按照不同的業務場景創建合適類型的物化視圖,並通過參數控制分區刷新行為,從成本和集羣穩定性角度考慮,在滿足業務需求的前提下,應遵循數據刷新最少化、調度頻率最低化的原則來設置物化視圖刷新參數。此外,我們還需要定期對物化視圖進行治理,並添加監控報警以保障集羣的持續穩定性。最後,數據開發同學在使用物化視圖時,需規避一些系統性風險,如:
- 當基表分區字段為字符串類型的日期時,物化視圖會創建List分區,且在刷新時觸發全表刷新,可以使用 str2date函數轉為日期類型,創建 Range 分區物化視圖;
- 視圖始終依賴於基表,物化視圖刷新前會進行分區檢查,基表中不存在的分區也會在物化視圖中刪除,即便視圖屬性中設置了更長時間的 partition_ttl 也無法阻止這一操作;
- 在物化視圖的定義 SQL 中儘量使用 StarRocks 已支持的內置函數,一些 UDF 在物化視圖刷新時可能無法兼容。
四、RoaringBitmap:StarRocks&Paimon 實時去重的極速神器
通過物化視圖的優化實踐,我們發現長遠來看對於複雜的實時業務場景,物化視圖更應作為 ADS 層的數據加速,而DWD 到 ADS 層的 ETL 過程應儘可能在 Paimon 中完成。即讓數據在湖裏流動,StarRocks 物化視圖做鏈路終端的查詢加速。比如可以利用 Paimon 的 Partial Update 解決雙流 JOIN 的場景,Aggregation 特性處理聚合場景等。
在 C 端業務中,去重指標的實時計算往往是技術痛點,於是,我們團隊調研了在湖上利用 RoaringBitmap 解決大數據量級精確去重,流量域中多維數據的快速分析,基於 Bitmap 的不同人羣下鑽、訪購率計算,流量域中長週期指標的實現等場景。通過 StarRocks 的 Bitmap 相關函數直接查詢存儲在 Paimon 中的 RoaringBitmap 數據,大幅提升了實時 UV、多數據域分析的數據新鮮度和查詢性能。
4.1 RoaringBitmap去重原理淺析
我們以6行數據在兩個節點上計算來舉例,在傳統的 Count Distinct 去重方案中,由於數據需要進行多次 shuffle,當數據量越來越大時,所需的計算資源就會越來越多,查詢也會越來越慢。
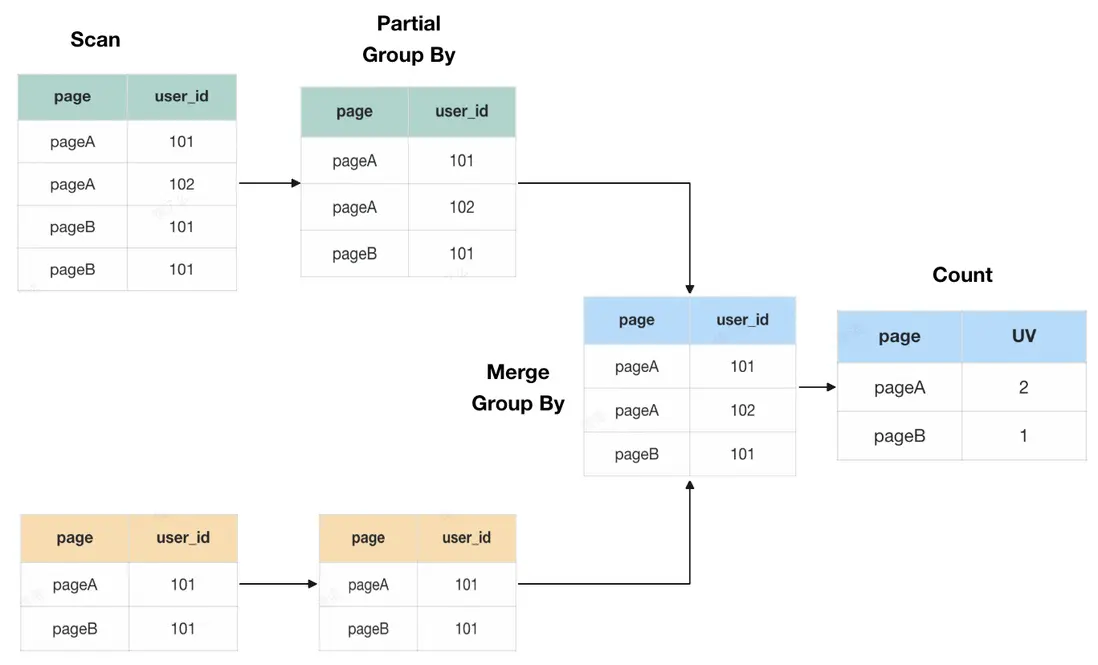
Bitmap 去重方案中,每個維度僅需存放一個 UID 位圖即可,去重即是對多個 Bitmap 進行位運算(OR),然後直接統計位圖中1的個數即為 UV 計算結果。大數據場景下,Bitmap 的存儲方式相比與 UID 去重後的明細數據顯然節省了大量存儲空間。
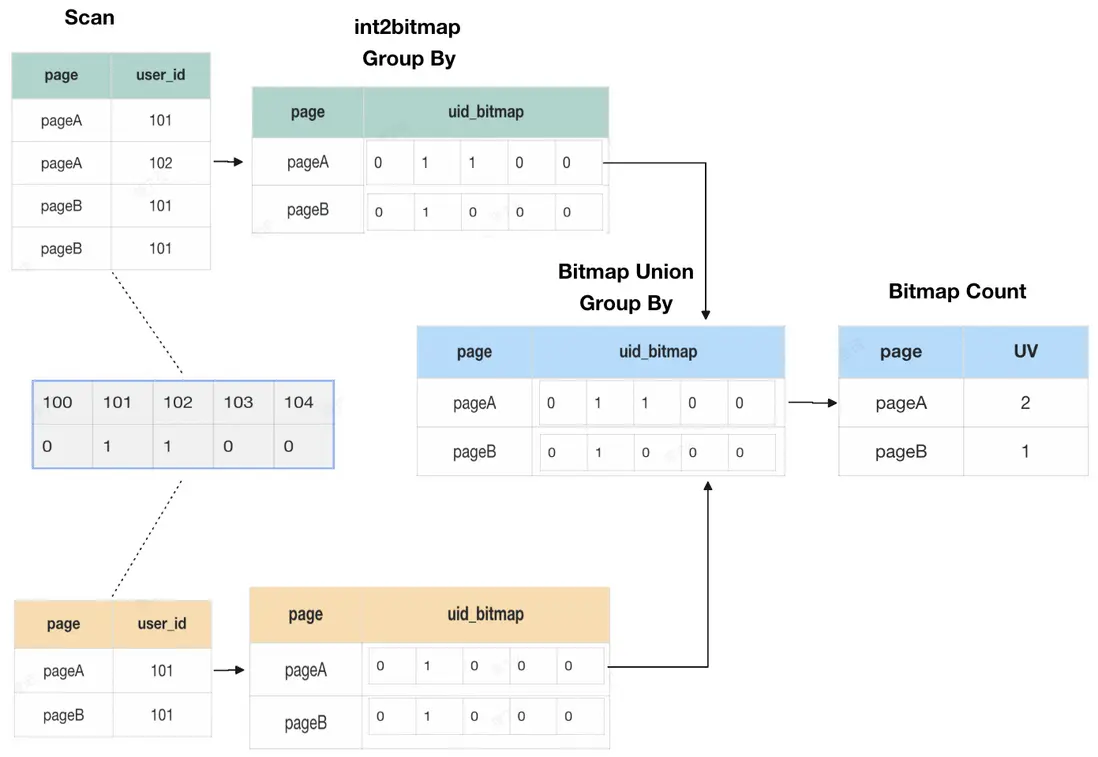
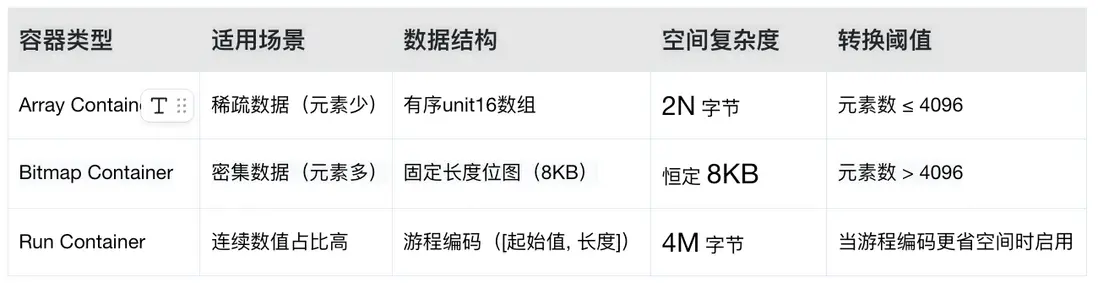
但當某個維度為稀疏分佈時,此時長度為 n 的位圖僅有少部分是有效位,存在大量的無效 0 佔用空間,所以,需要一種更靈活的存儲方式來解決這個問題。RoaringBitmap 是一種高效壓縮位圖結構,專為快速存儲和操作大規模整數集合設計。它通過智能分桶和動態容器選擇,在空間壓縮和計算性能之間實現最佳平衡,在當下主流的大數據計算和存儲引擎中,RoaringBitmap 也被越來越廣泛的應用。以32位 RoaringBitmap 為例,內部會將高16位進行分桶,低16位根據桶內數據分佈特徵選擇Array Container(數組容器)、Bitmap Container(位圖容器)、Run Container(遊程編碼容器)三者中空間利用率最高的容器存儲。
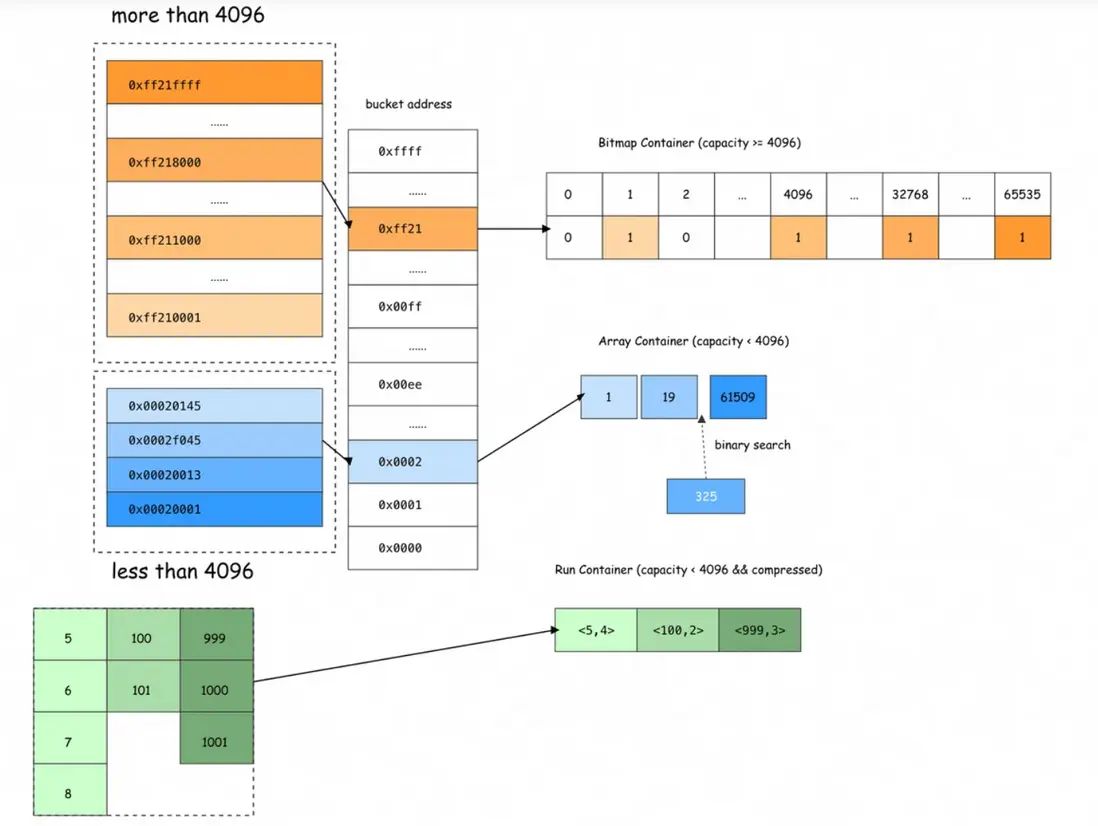
如上圖,十進制數 131397 轉為十六進制為 0x00020145,其中 0x0002 為高位分桶,該分桶內元素小於 4096,低位 0x0145(16161+164+5=325)採用 Array Container 存儲,二分法找到對應數組位置。當元素個數達到 4096時,數組容器佔用的空間為 24096=8192 字節,此時與位圖容器所佔空間一致。即當一個分桶內的元素個數超過 4096 時,會選擇位圖容器存儲,並根據數據的連續程度來判斷是否優化為行程編碼以進一步壓縮存儲空間。
4.2 RoaringBitmap 去重適用場景
以下均針對去重指標計算場景,可直接 sum 或 count 的指標不在討論範圍內。
4.2.1 多維預計算(CUBE)
在預計算場景中,每個維度的增加往往帶來計算與存儲資源的指數級增長,n 個維度理論上有 n 的2次方個維度組合,假設業務有七個維度,就會有上百個 grouping sets。即便中間做一層輕聚合優化,也動輒運行數小時,不僅浪費了資源,且數據產出時效差,甚至影響業務看數。
使用 RoaringBitmap,將中間層的輕度去重數據由 UID 改為聚合後的 Bitmap,原方式下,每組最細維度下有多少UID,就需要存儲多少行數據,新的存儲結構每組維度只需要存儲一行 Bitmap 即可,極大節省了存儲空間。同時下游使用位運算計算 UV 指標,計算效率也提升數倍。
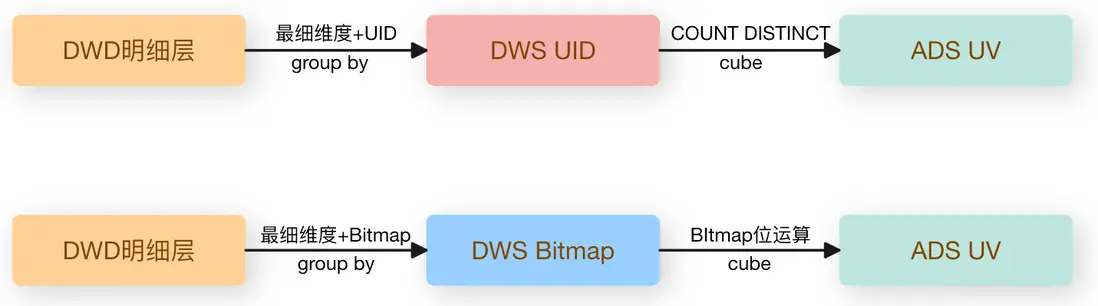
但以上多維度預計算更適用於離線場景,實時資源的成本過於昂貴,且在大多數實時場景下,業務並不需要看全部一百多組 grouping sets 的維度數據,而更關心數據的時效性。此時我們可以僅保留需要的維度直接查詢 Bitmap 數據,或將多組維度拆開,利用交、並、差集計算來滿足任意維度組合的看數需求,以下介紹幾種利用 RoaringBitmap 進行實時多維分析的應用場景。
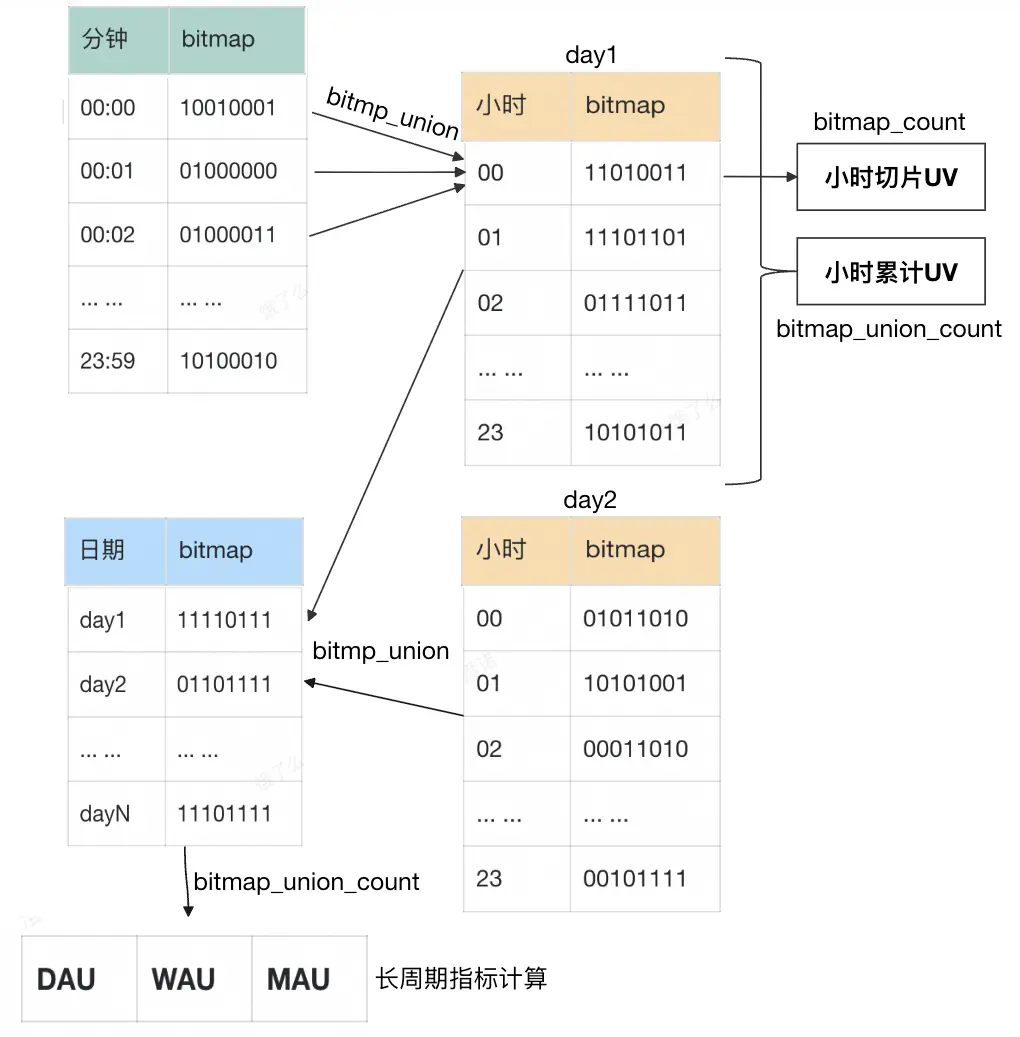
4.2.2 時間上卷(UNION)
位圖 UNION 的本質是 OR 運算,使用 bitmap_union 和 bitmap_union_count 可以實現時間上卷或細粒度向粗粒度的聚合和去重統計,在數據湖中,可以利用 Paimon 流讀流寫特性和 Aggregation merge-engine 簡單快速地實現bitmap 的聚合計算,當前 Paimon 的 Aggregation 已支持 rbm32 和 rbm64 函數。也可以自己開發. Flink-UDAF,在Flink-SQL 中完成聚合操作,使用 Deduplicate merge-engine 入湖。
bitmap_or 是對兩個 Bitmap 做並集,bitmap_union 是聚合函數,對同一列的多個 Bitmap 做並集計算。
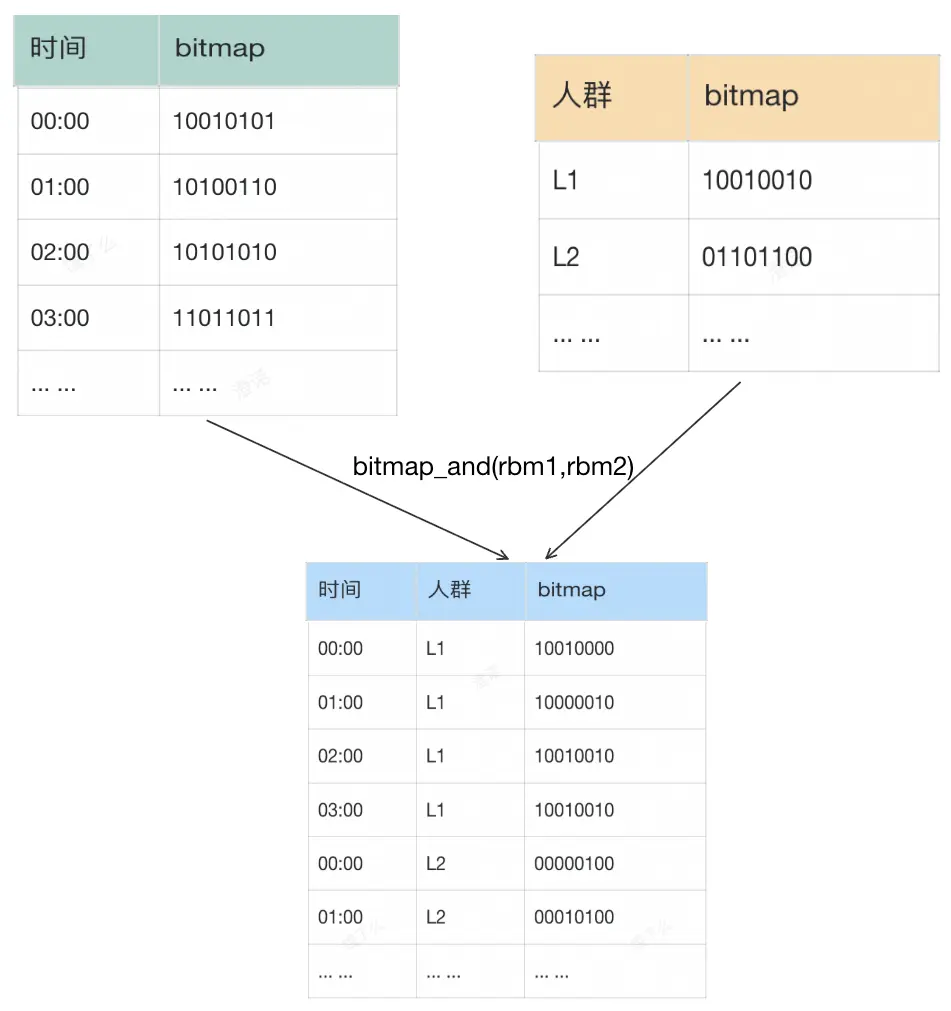
4.2.3 人羣下鑽(AND)
Bitmap 的交集計算適用於電商業務中常見的留存、復購、多維交叉分析等場景,即粗粒度模型存儲實現更細粒度的實時分析。也可以利用交集來進行人羣下鑽。與其他維度不同,用户人羣維度通常不是一成不變的,且開發人員無法按照既定規則去預判這種變化,業務會按需圈選各種各樣的人羣包。為應對不同人羣的靈活下鑽分析需求,在設計數據模型時我們可以把人羣維度單獨處理。如我們在流鏈路裏做了一張分鐘流量的 Bitmap 表,批鏈路加工一張人羣維度的 Bitmap表,使用 bitmap_and 函數計算交集後即可得到每個人羣對應的小時切片 UV。
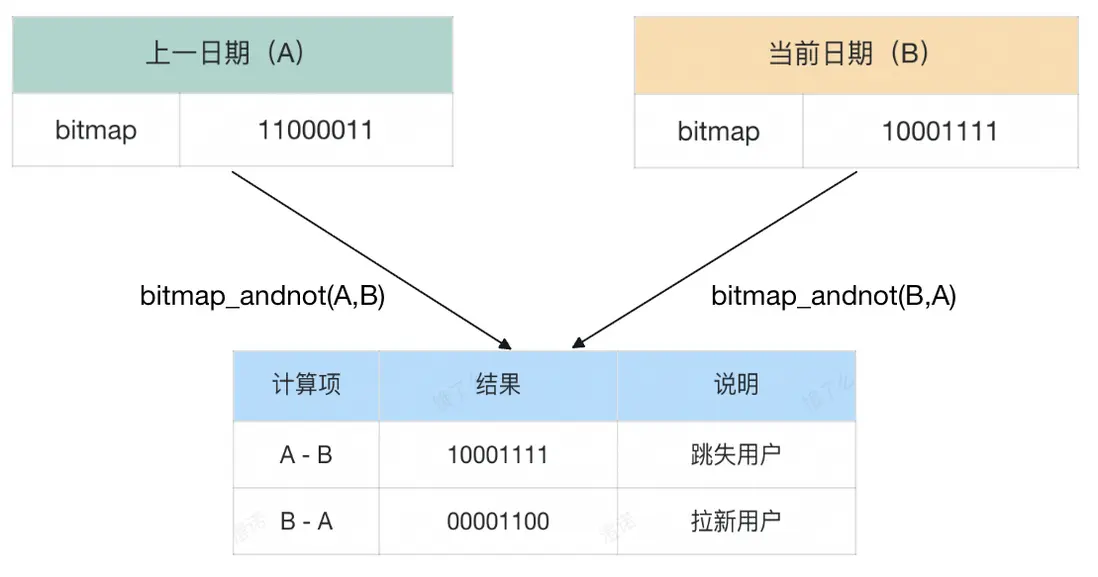
4.2.4 跳失、拉新(AND NOT)
差集計算適用於指標語義中含有“非”、“但”的邏輯,如計算前一日訪問但當日未訪問的用户,則可以將前一天的訪客Bitmap 與當日訪客 Bitmap 進行差集計算,從而找到當日跳失用户,如下:
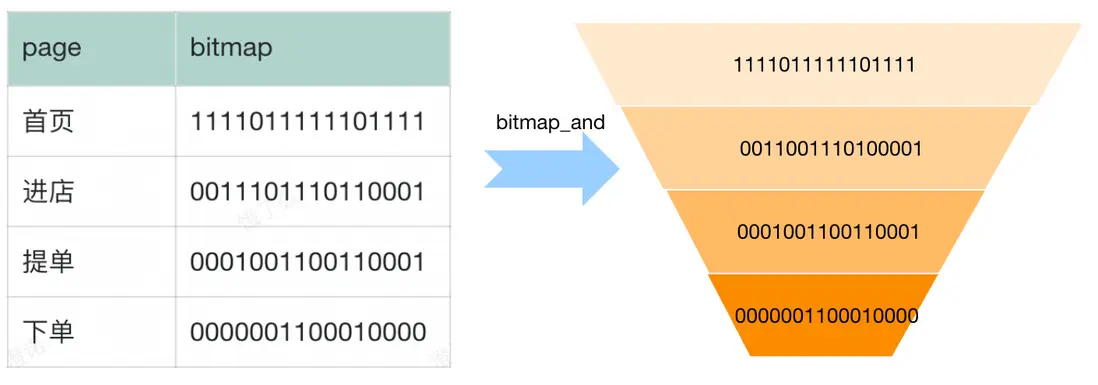
4.2.5 漏斗分析(CASE WHEN)
首頁-->進店-->提單-->下單是業務常用的轉化率分析鏈路,但每個頁面流量單獨統計出的結果並不準確。以首頁-->進店為例,部分外投渠道鏈接可能直接跳到店詳頁而不經過首頁。業務想要看到精確的漏斗數據,只能使用 UID 進行串聯。假設我們有一張頁面維度的 Bitmap 表,則可以通過 case when+bitmap 交集計算來進行訪購鏈路的漏斗分析。
4.3 RoaringBitmap 在淘寶閃購的應用
4.3.1 場景1:流量域多維實時 UV
閃購項目中後期,業務提出了更多維度的實時看數需求,包含各端的閃購/非閃購及多個維度的數據。原有的物化視圖直接加速湖表 DWD 的方案很難滿足業務上多維靈活看數,且多個大視圖搶佔資源導致物化視圖數據刷新的時效性越來越差。所以我們嘗試使用 RoaringBitmap 和 Paimon 的流讀流寫特性來計算流量域數據的多維實時 UV,具體方案如下:
- 使用自增序列將 UID 實時映射為 int 類型;
- 開發 Flink-UDAF 函數,支持 bitmap_agg 和 bitmap_union 操作,並序列化為 bytes 類型返回;
- 接入 ODPS 城市/區縣維表(全量緩存),Lindorm 用户分層維表(LRU 策略);
- TT 數據入湖,Flink-SQL 流式讀取 Paimon 明細層數據,並與 UID 映射表和其他維表 lookup join;
- 調用 bitmap_agg 函數將映射後的 UID 轉為 Bitmap 存儲,sink 到下游湖表;
- 按照業務場景,使用 StarRocks 的 bitmap_union_count 函數對所需維度實時去重統計;
- 如業務需要查看多天趨勢,可以繼續向下 bitmap_union 為小時或天粒度的 Bitmap。
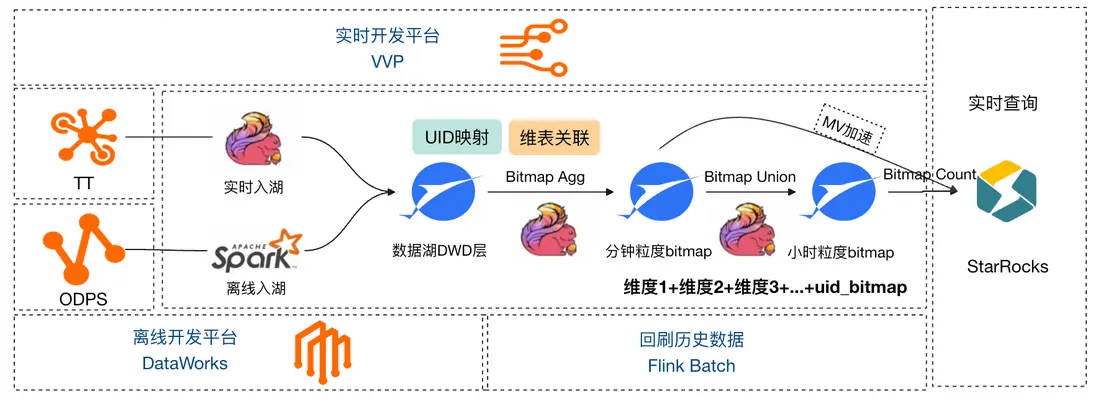
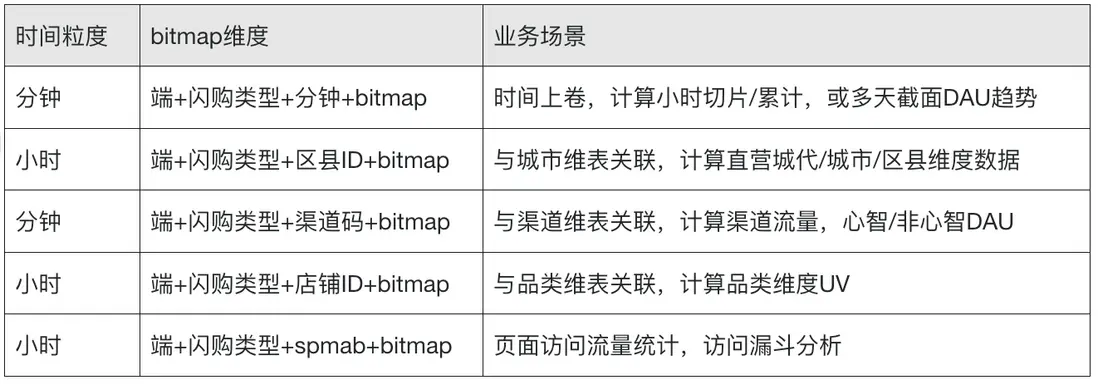
此時我們可以任意組合看數的維度有:端+閃購類型+直營城代+用户L分層+用户V分層。
時間粒度:分鐘切片/累計、小時切片/累計/當日累計趨勢、全天數據、多天連續數據等。
4.3.2 場景2:多數據域 Bitmap 應用
項目後期,在業務側,用户L分層的口徑頻繁變更,業務也會圈選新的人羣包進行下鑽分析;技術側看,Lindorm 在回刷數據時會產生較大波動,我決定將人羣維度拆分出來單獨處理。此外,我們也有了新的業務思考,如何構建流量域全維度覆蓋的實時 Bitmap 數據資產,以及能否將訂單域數據也加進來計算實時訪購率。於是,我們在原有方案上進行了另一種數據建模方法的嘗試:
- 中間做一層最細粒度的 DWS 輕度聚合層,下游再加工出常用維度+單維度的 Bitmap;
- 僅保留 UID 映射表,其餘 lookup join 表全部刪除,改為應用層使用時 join;
- 用户維表使用批鏈路處理,構造人羣維度 Bitmap 湖表,計算交集進行人羣下鑽;
- UDAF 中添加回撤流處理,將訂單域湖表數據也做成 Bitmap。
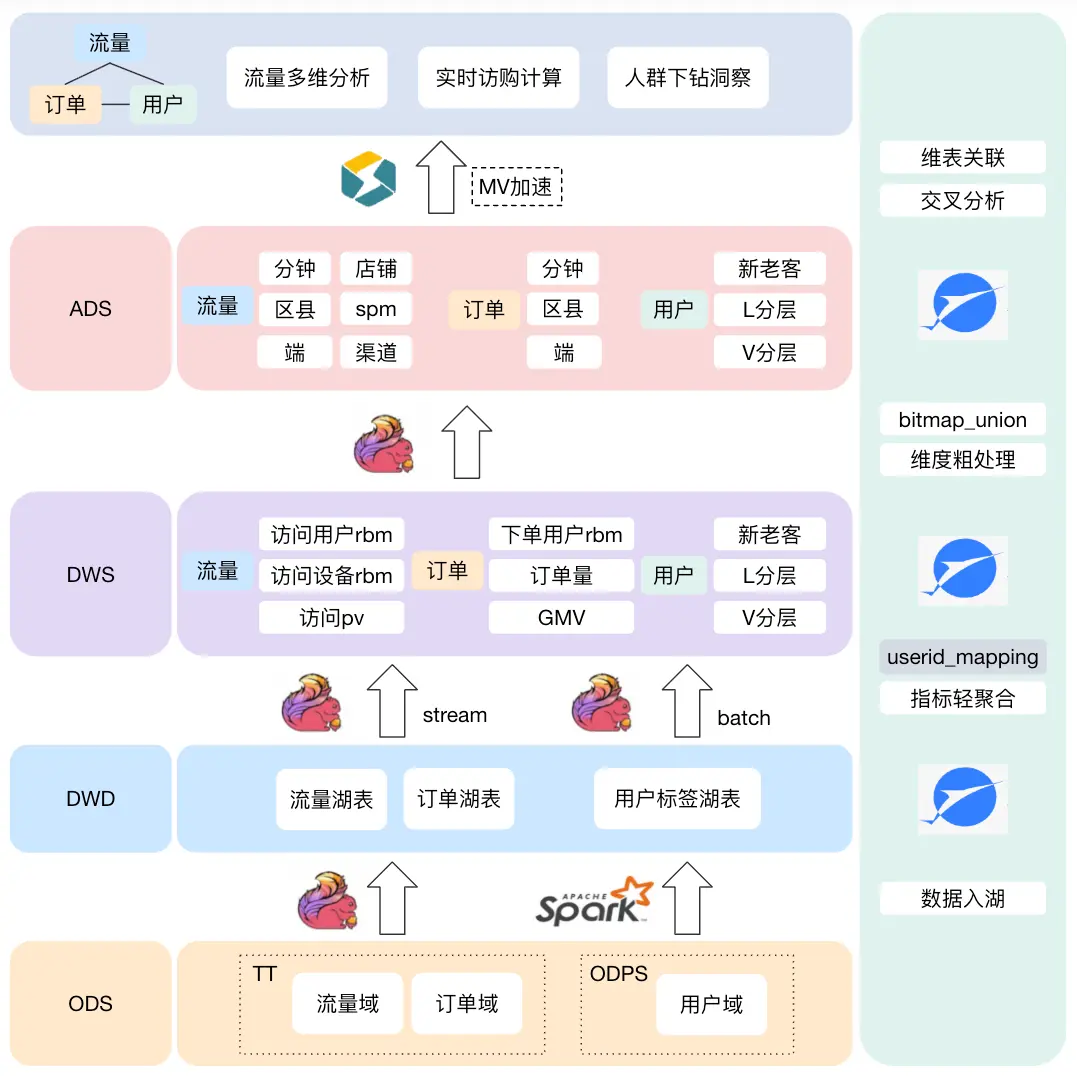
流量域 ADS 層 Bitmap 表設計:
端和閃購類型維度在業務上經常需要拆開看數,且這兩個維度基數較少,所以每個表都保留。
訂單域設計思路類似,當我們將各個業務域都按照各自維度存儲為 Bitmap 結構後,就可以高效地計算出任意維度的實時 UV、訪購率、人羣下鑽數據等。
4.4 RoaringBitmap 實踐總結
藉助 StarRocks 豐富的 Bitmap 函數和 Paimon 的流讀流寫能力,我們利用 RoaringBitmap 實現了實時場景的高效去重計算。根據其構造方式我們不難看出,只有數值類型的 UID 才能被轉為 Bitmap 存儲,且數據越稠密越連續性能越好,但實際業務中,我們的 UID 通常為稀疏的 bigint 或 string 類型,因此需要將 UID 重建序為 32 位的 int 類型,儘管部分引擎支持了 64 位 RoaringBitmap,但其性能顯著低於 rbm32,建議仍優先使用32位。
在實時流中,需要使用支持自增序列寫入和高併發點查的存儲介質做維表 LOOKUP JOIN 以實現對新用户的實時映射。我們在午高峯百萬級 RPS 場景下,實時點查映射表會出現反壓,通過 LRU 緩存並開啓 Flink-MiniBatch,並對湖表增量 Snapshot 數據預去重再關聯,能夠有效降低實時查詢壓力。同時將歷史用户預映射入庫,可以避免維表高頻寫入瓶頸。
在 Flink-SQL 中因原生不支持 Bitmap 操作,需通過 UDAF 函數實現 int 與 Bitmap 的互轉、聚合及序列化為 BYTES 類型存儲,注意準確處理回撤流的邏輯修正。面對超大規模用户基數的存儲限制,採用分桶計算策略:對 UID 哈希分桶後獨立聚合,確保單桶 Bitmap 長度可控,最終通過累加分桶結果實現全局統計。此外,粒度的選擇尤為重要。雖然細粒度可以通過 UNION 並集計算向下遊加工粗粒度數據,粗粒度數據也可以通過交集計算進行維度交叉,但仍建議結合業務查詢模式進行數據模型設計,以達到靈活性與性能的黃金平衡點。

五、StarRocks on Paimon 治理最佳實踐
StarRocks 作為經典的 MPP 架構,大查詢易引起資源過載,所以對大查詢的管理必不可少。以下是我們團隊針對 StarRocks 集羣運維與治理方面的一些經驗,重點介紹針對大查詢的診斷分析與治理。即通過監控報警感知到集羣的異常波動,再使用 AuditLoader 插件採集的審計日誌找出影響集羣穩定性的大查詢或物化視圖刷新任務,然後採取下線、優化、或資源隔離的方式進行治理。
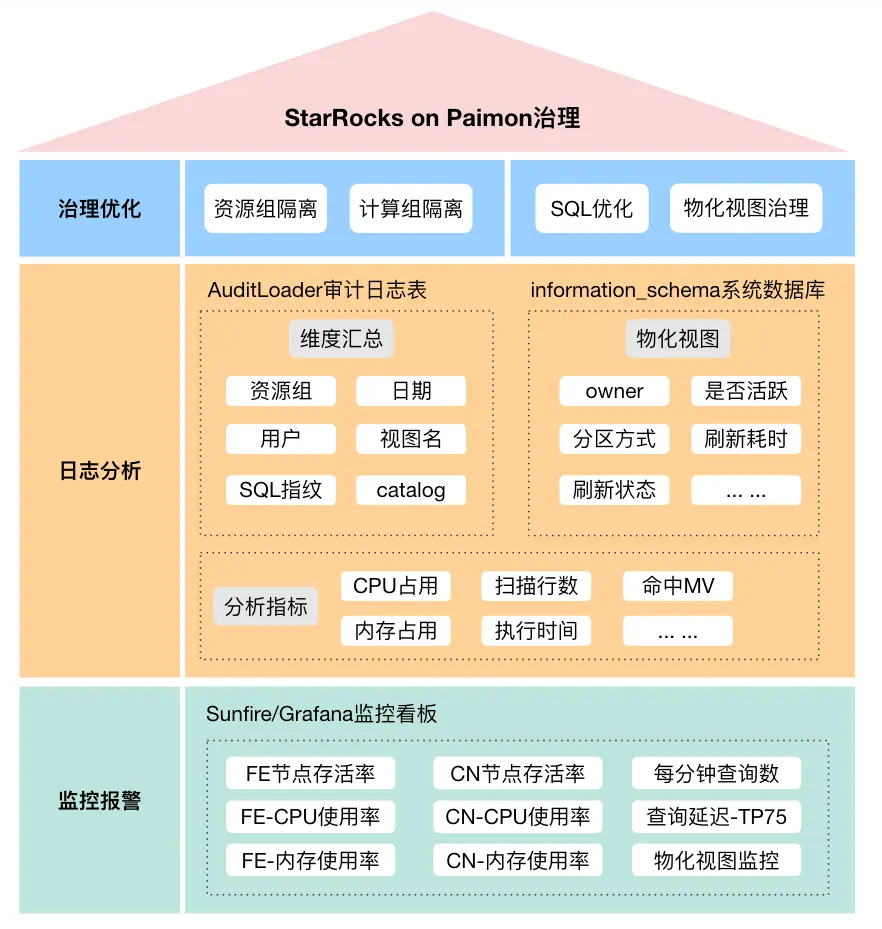
5.1 監控報警
我們目前使用的是阿里集團內部的 Sunfire 平台進行 StarRocks 實例的監控看板搭建和報警配置,主要針對 FE 和BE/CN 節點的 CPU、內存使用率和查詢延遲等指標進行重點監控。社區的小夥伴可以使用 Grafana 實現一樣的效果,StarRocks 官網文檔中也提供了非常完整且詳細的 Prometheus+Grafana 的可視化監控報警方案和適配於各個版本的 Dashboard 模板。並且在 3.1 以上版本,還支持了異步物化視圖的專項監控指標配置,可以實時觀測到當前集羣刷新成功和失敗的物化視圖數量,刷新狀態、物化視圖的大小、行數、分區信息等。
5.2 查詢分析
StarRocks 所有的 DML、DQL 等語句都會在 fe/log/fe.audit.log 中記錄一條日誌,包含語句內容、來源 IP、用户、所耗 CPU 及內存資源、返回時間、返回行數等。我們可以使用官方提供的免費插件 AuditLoader 將審計日誌通過 Stream Load 的方式寫入庫表,這樣我們可以通過 SQL 非常方便地查看數據庫日誌信息。
我們藉助 AuditLoader 生成的審計表和集團的FBI平台搭建了查詢日誌明細報表和物化視圖、SQL 指紋、用户等多個維度的資源佔用看板。此外,我們還可以通過系統數據庫 information_schema下的 materialized_views、tasks、task_runs 三張表來製作物化視圖的專項看板,更加直觀地查看各個物化視圖的元數據信息及刷新任務狀態。通過這些實時看板,方便我們定期清除潛在隱患,也能夠在觸發報警時快速定位到引起集羣狀態波動的大查詢或寫入任務。
5.3 資源隔離
隨着物化視圖的不斷增多,一些較大的物化視圖任務刷新時,同實例下的其他查詢會受到一定影響。治理的手段往往是有滯後性的,我們嘗試在運維層面降低系統性風險,通過資源隔離的方式來提升穩定性。在一個 StarRocks 實例內部,可以通過配置資源組或計算組來實現這個需求。
StarRocks 通過資源組(Resource Group)實現多租户資源隔離,允許按用户、角色或查詢類型動態分配 CPU、內存及併發資源。通過設定資源配額和優先級規則,確保關鍵任務獨享資源,避免資源競爭,保障高負載下查詢性能和穩定性,支持靈活配置與實時彈性調整。StarRocks 內置了兩個資源組 default_wg 和 default_mv_wg,分別對應普通查詢任務和物化視圖刷新任務,用户也可以根據業務場景自定義資源組配額,使用也非常簡單,只需要創建資源組和分類器即可。
但需要注意的是,通過 Resource Group 實現的資源隔離通常為軟隔離,即假設有三個資源組 rg1、rg2、rg3,資源配額為 1:2:3,當 BE/CN 節點滿載時,集羣資源會按照配額分配;當 rg1、rg2 有負載而 rg3 無負載時,rg1 和 rg2 會按照 1:2 比例分配掉全部資源。
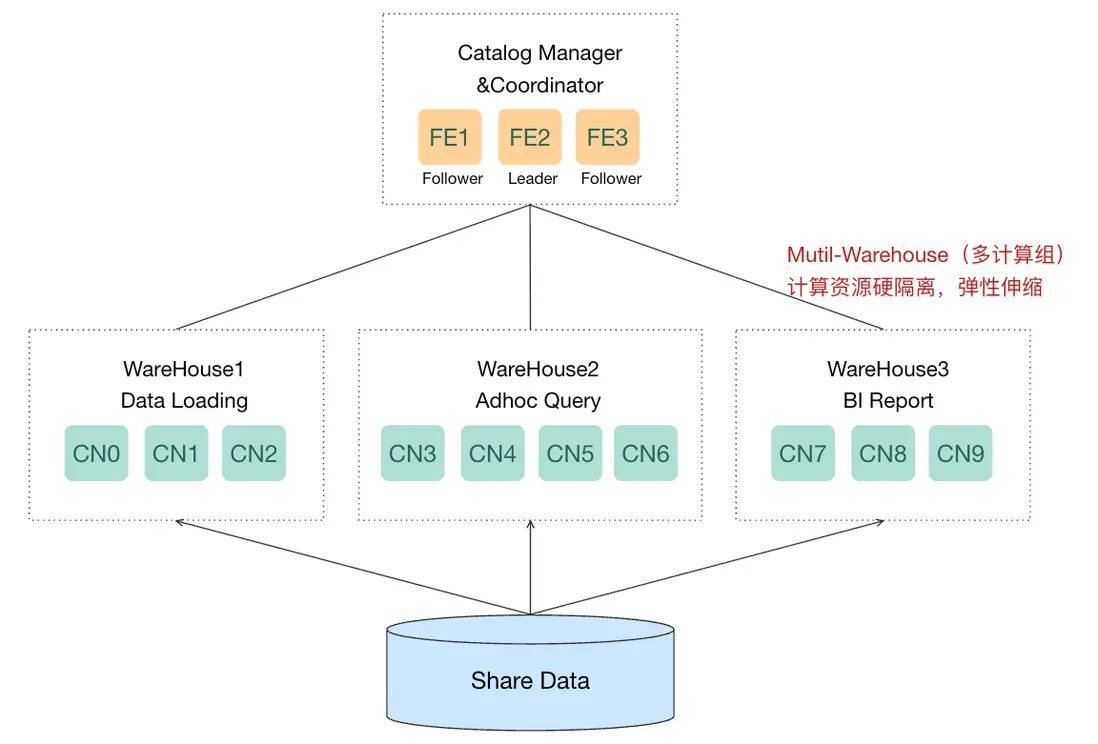
業務實踐過程中,通過資源組來實現業務間的資源隔離尤其是 CPU 資源有時並不能達到理想的效果,由於其軟隔離的特性,我們始終無法在同一個實例中完全隔離出一部分 CPU 給到 P0 級業務。於是,我們繼續嘗試了阿里雲 EMR StarRocks 存算分離版本計算組(Mutil Warehouse)隔離能力,將物化視圖刷新任務與 SQL 查詢任務進行隔離。即在同一個實例中共享一份數據存儲,共享 FE 節點的查詢規劃和資源調度,將 CN 節點進行物理隔離,滿足讀寫分離場景和不同業務負載需求,同時支持根據實際業務需求動態調整資源,確保資源高效利用並降低成本。
5.4 SQL 及物化視圖治理
當我們定位到大查詢後,使用 EXPLAIN 或 EXPLAIN ANALYZE 來獲取查詢計劃,也可以啓用並查看 Query Profile 以收集更詳細的執行指標,企業版用户還可以使用 StarRocks 官方提供的可視化工具進行診斷分析。常見的優化手段包括:
- 如果關聯字段也是過濾條件,將過濾條件寫在大表上,以便謂詞正確下推至存儲層;
- 大表與小表關聯時,可以添加 JOIN HINT,使用 BROADCAST 方式關聯減少節點間數據 shuffle;
- 聚合場景添加查詢 HINT 選擇合適的聚合算法,如低基數維度去重統計添加 set new_planner_agg_stage=4;
- 當多表關聯時優化器未選擇最優的連接順序,可以嘗試添加 JOIN HINT 或將連接條件書寫完整,如 a、b、c 三表關聯,ab、bc、ac 三個連接條件都寫出來。
針對物化視圖的治理,我們應及時將下線視圖的狀態改為 Inactive,降低低優業務的刷新頻率,並將物化視圖的刷新任務與 SQL 查詢進行資源隔離。物化視圖的錯用濫用,以及過高的刷新頻率,都會導致全部視圖的 Pending 時間過長,從而影響數據產出時效,甚至會影響集羣整體查詢性能和穩定性。我們不僅要在事後治理,更重要的是在創建視圖時規避以下錯誤或不恰當的用法:
- 日期寫死,等於固定日期(無效視圖),大於等於固定日期(高危視圖);
- 非分區物化視圖未添加分區限制條件,即每次刷新全表數據;
- 分區物化視圖未設置參數控制刷新行為,存在全表刷新風險,如維表數據變動;
- 多個測試版本視圖未及時刪除,下游無業務,空跑浪費集羣資源;
- 視圖定義中存在多組維度的 CUBE 且刷新頻率極高。
六、總結與規劃
淘寶閃購自 4 月 30 號上線到 8 月 7 號的“秋天第一杯奶茶”,業務團隊用 100 天創造了一個奇蹟。我們技術團隊也頂住了前所未有的壓力,在湖倉技術的探索上不斷進行突破與革新。目前 StarRocks+Paimon 的方案已經在餓了麼內部全面開花,越來越多的數據開發願意參與到我們的湖倉建設中。在未來的一段時間內:
- 我們會逐步治理物化視圖中的大查詢,保障 StarRocks 集羣的穩定性與物化視圖刷新的時效性;
- 並繼續與愛橙和阿里雲EMR團隊密切合作,優化 StarRocks 查詢 Paimon 性能向內表追齊;
- 我們也會嘗試探索落地更多湖倉業務場景,並在數據湖上持續建設流批一體架構,徹底解決實時和離線鏈路重複開發和數據口徑不一致的問題。
最後,項目結束不是終點,而是技術新的起點,我們的補貼仍在進行中,歡迎大家打開淘寶閃購,給我們數據團隊“再上億點壓力”。也誠邀社區的小夥伴加入餓了麼數據智能中心大家庭,e 起勇往直前,用數據驅動未來!







