









超時時間
概念
超時時間指系統在等待某個操作響應時設定的最大容忍時間閾值。當操作未在指定時間內完成,系統將主動終止等待並觸發預設處理邏輯
超時可以看做是一種降級手段。因為假設服務永遠能正常運行,我們並不需要超時時間,來保證服務的可用性和穩定性
常見需要依賴超時時間的場景
- 網絡層:TCP 協議的 connect timeout(Linux 默認 120 秒)、HTTP 請求的 socket timeout(如 Java HttpClient 默認 30 秒)
- 數據庫:MySQL 的 wait\_timeout(默認 8 小時)
- 業務層:外賣訂單支付超時時間為 15 分鐘
本文主要討論網絡層的超時時間
作用
減少資源浪費
當客户端發起一個請求後,如果服務器端因為某些原因無法及時響應(例如服務器過載、網絡故障等),那麼不設超時機制的客户端可能會無限期等待。這種情況下,不僅消耗了客户端的資源(如內存、CPU 等),也佔用了服務器端的資源(如連接池中的連接,導致吞吐量降低)
設定合理的超時時間可以確保在一定時間內未得到響應時及時終止請求,釋放佔用的資源
保證服務質量
如果某個操作響應時間過長,會影響用户體驗。合理配置超時時間可以幫助系統更快地做出反應
- 當客户端超時時,可以提示用户自己重試,比如刷新網頁後點擊按鈕跳轉頁面
- 當服務端 RPC 調用超時時,自動重試,並通過負載均衡找到其它節點重試
當進行重試的時候,或許可以用更短的時間響應結果
比如某個服務絕大部分情況下 RT 都是小於 10ms 的。但假設此時某個節點網絡波動,導致我們需要 1000ms 才能返回結果,那麼
- 沒有設置超時時間的話,最終花費 1000ms 才得到結果
- 設置超時時間為 10ms,當發現 10ms 還沒得到結果,認為請求失敗,進行超時重試,通過負載均衡換個好一點的節點,10ms 內返回了結果,最終花費時間為 10 + 10 = 20ms
1000ms < 20ms,及時地超時重試可以降低 RT
優化用户體驗與服務監控
- 對於客户端而言,返回給用户信息“系統繁忙,稍後再試”,總是要比看着白屏轉圈要好的
- 對於服務端而言,讓請求及時超時並日志記錄上報,可以更好地瞭解整個系統的運行狀態。比如服務出現了大量超時,我們就知道某個服務出現了問題。同理,CPU 利用率達到 100%、線程池大量任務阻塞,也能作為服務運行狀態的評判標準
設置合理的超時時間
超時時間的長度不能隨便設
- 時間太長,可能導致系統資源被長時間佔用,失去了設置超時時間的意義
- 時間太短,可能導致請求未完成就被中斷
核心原則:服務總超時 > 下游服務總耗時。避免下游服務還沒執行完,就超時了
- RPC 的超時時間一般設置為 P99
- 客户端的 HTTP 請求超時時間控制在 10s 內。一般每延長 1s 都將導致大量的用户流失,10s 實際已經算久的了
具體設置多長超時時間還是取決於業務。比如像點贊這種高頻訪問且實時性要求高的接口,1s 已經算慢了;而像做數據報表的請求,可能 10s 能返回結果也算快了;對於數據庫連接池,超時時間往往都要設置 8 小時以上,雖然每次請求都會續上時間,但是有些服務在半夜是不使用的,導致早上訪問數據庫時連接會斷開,服務超時
業務接口永遠不要設置太長的超時時間
如果某個業務服務的接口,就是要花費很長的時間才能返回結果,也不推薦設置太長的超時時間。換句話説,一個接口 RT 不應該太久。因為請求將長時間佔用客户端和服務端連接池,導致資源浪費和吞吐量下降
正確做法是改造接口,將實際的業務操作使用 MQ 或線程池異步化,這樣請求接口可以立即返回結果,可以通過「服務端主動推送」或「客户端輪詢」獲取結果(有沒有想到微信支付的異步支付呢?)
術語解釋:P99
P99 就是指 99%的請求都能在這個時間內或更短時間內完成處理,只有 1% 的請求會比這個時間更長
比如,某個接口的 P99 響應時間為 300ms,這意味着 99% 的請求都在 300ms 以內得到了響應,只有 1% 的請求需要花費大於 300ms 的時間返回
獲取 P99 的方式主要就是壓測或線上監控
長尾請求
概念
一般大部分請求的響應時間集中在較低延遲區間,但存在一小部分請求的響應時間顯著高於平均值,形成一個“長尾”分佈的現象,並稱為“長尾請求”
一般業界常用的是 P99 標準,也就是認為 1% 大於某個耗時的請求屬於長尾請求
造成危害
長尾請求雖然可能不會在短時間內造成明顯的問題,但如果沒有及時處理,它們會帶來一系列危害:
- 資源消耗:相比其他正常的請求,長尾請求將佔用更長的連接時間。同時,長尾請求往往意味着超時,那麼需要額外的重試,進一步加劇服務負載
- 降低用户體驗:同一個頁面,別人 1s 就打開了,而自己卻要等待 5s 才能進
長尾請求在高併發系統中是不可忽視的
上面也提到,一般超時時間會設置為 P99,但即使每秒只有 1% 的請求超時,隨着請求量增大,超時請求的數量會急劇增加。我們可以從兩個角度來分析高併發系統下的長尾請求:影響的範圍 和 必然性
假設,某個服務的 P99 為 1s,QPS 為 1000
- 影響的範圍
1000 個用户請求有 1% 大於超時時間,即 1000 * 0.01 = 10。那麼每秒將有 10 個用户受到了長尾請求的影響,每分鐘 600 個,每小時 36000 個,這 36000 個人已經足以在網上造成不小的輿論了
- 必然性
當請求數量增加時,長尾請求的發生變得 “必然”
假設每個查詢之間是獨立的,我們來做個簡單的概率計算:每次查詢響應小於 1 秒的概率為 99%,對於 100w 次獨立的查詢(假設每個查詢之間是獨立的),至少有一次查詢響應時間大於 1 秒的概率約為 1 - 0.99^1000 ≈ 100%
正如如下圖所示:
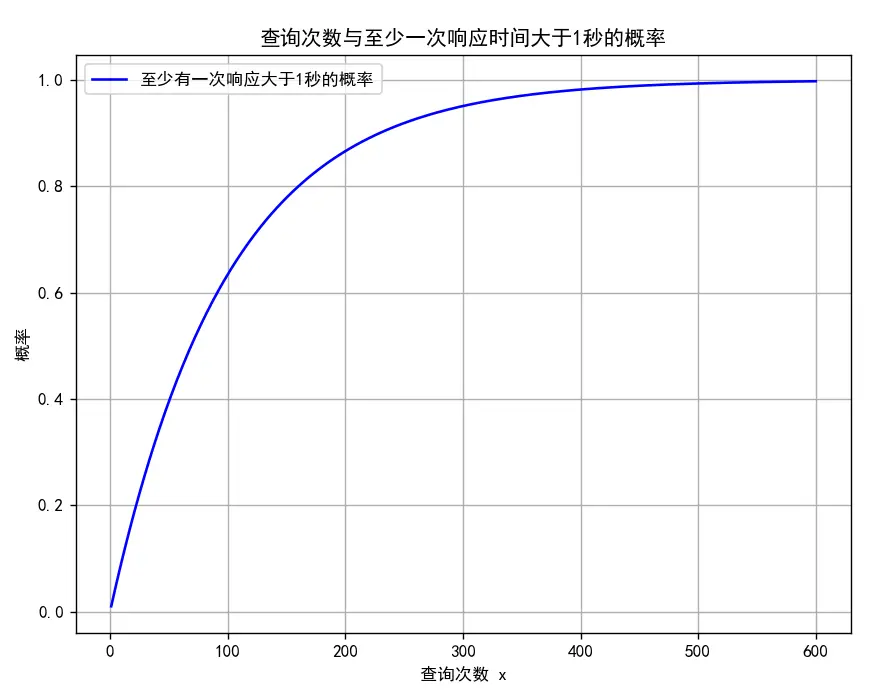
實際請求到 600 的時候,至少有一次查詢響應時間大於 1 秒的概率已經是 100% 了
產生原因
原因包括但不限於:
- CPU 調度走了
- 競爭非公平鎖,恰好有個倒黴線程出現鎖飢餓
- 出現 GC
- 網絡抖動、丟包、延遲、弱網
- 負載均衡不合理,某個節點承受了非常多的流量,請求處理速度慢,而其他節點卻空閒
解決方案
可以針對上面每一點進行優化,一定程度上緩解長尾請求造成的影響。但實際無論再怎麼優化,長尾請求都是存在的。所以可以採取兩種方案:
- 彈性超時:允許一定的請求超出原設定的時間,減少超時重試次數
- 備份請求:在快超時之前,提前重試,從而降低 RT
彈性超時
允許一段時間一些量的請求在一定的時間內返回,即允許一定程度上的“超時”。既提高了服務質量,又不太影響用户體驗
比如,每 60 秒允許 10 個請求的超時時間延長至 1000 毫秒
更多適用於一些偶發性超時場景,比如網絡抖動、GC、CPU 抖動、冷啓動等,如果是大面積的超時還是需要深入分析治理
備份請求
一次性發送兩個請求,即雙發請求,期間可能會收到多個響應值,哪個先來就用哪個,可以立即結束這次請求。用訪問量來換低延時。不過這將會使服務額外承受一倍的流量。所以我們可以加個條件:當達到某個時間還沒收到請求,我們再發送下一個請求,或者稱其為“備份請求”

設定一個比超時時間更小的閾值 T1。當 Req1 發送請求後,在 T1 的時間內沒收到響應,直接發出重試
相比於等待超時後再發出請求,這種機制能大大減少整體延時,同時又不會加大太多對服務提供方的負擔
重試
當出現網絡抖動、調用失敗、超時等原因,我們往往可以通過重試機制,提高請求的最終成功率
不過重試可不是一個 for 循環就搞定的事情,每次重試時,我們都要考慮重試的風險和重試風暴問題
重試的風險
重複提交
重試請求可能會導致重複的數據處理或事務。例如,在線支付系統重試交易請求可能導致重複扣款。
不過這種比較好解決,核心在於保證寫請求的冪等,對於讀請求是不需要考慮冪等的。可以使用 Redis 唯一 key、悲觀鎖/樂觀鎖解決
加大下游的負擔
假設 A 服務調用 B 服務,重試次數設置為 r(包括首次請求)。最壞情況下,下游的訪問量可能放大到 r 倍,不僅不能請求成功,還可能導致 B 的負載繼續升高,甚至直接打掛
同時,重試還會存在鏈路放大的效應,如下圖所示:
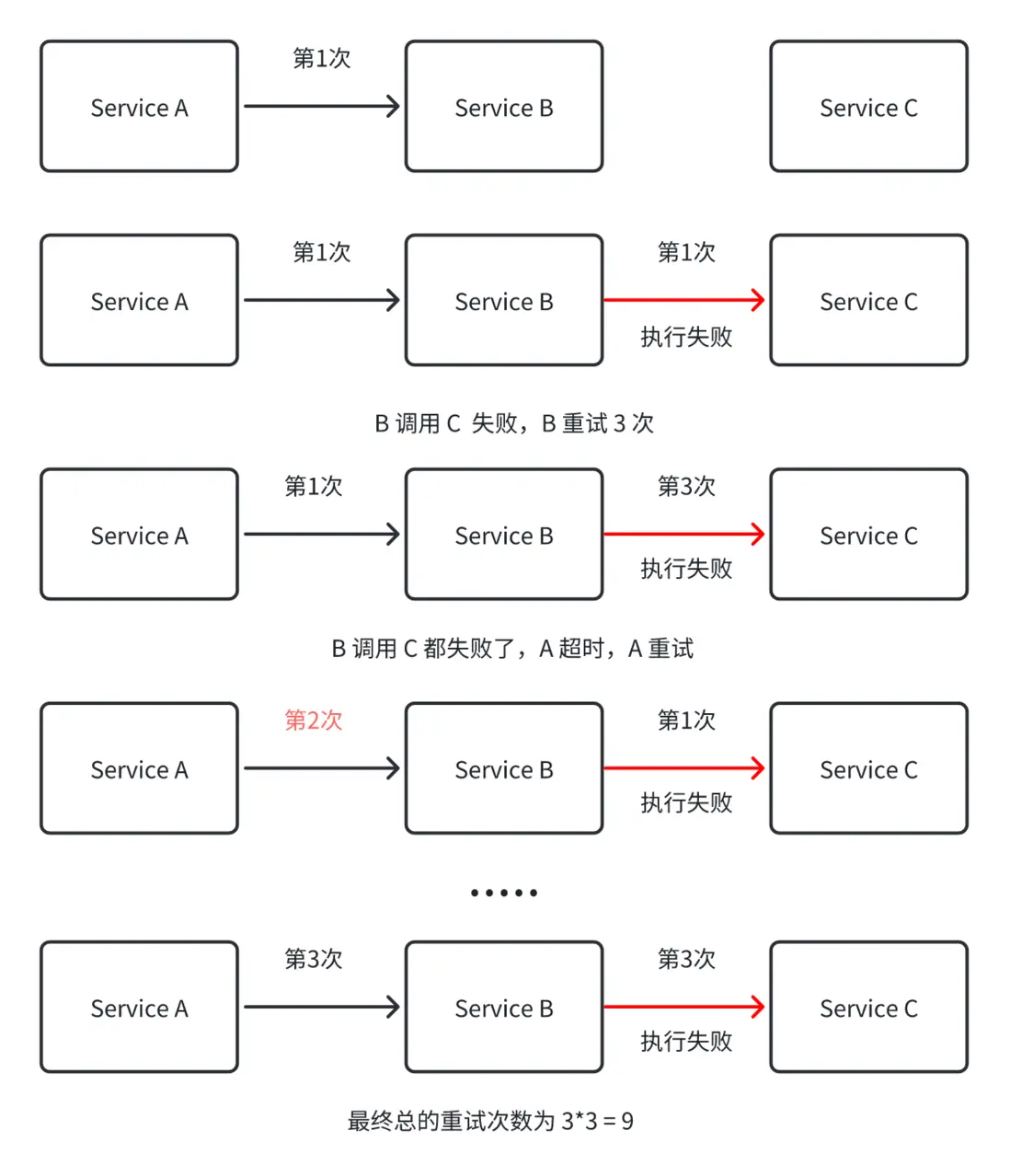
隨着請求節點的增多,重試的次數將指數級擴大。假設正常訪問量是 n,鏈路一共有 m 層,每層重試次數為 r,則最後一層受到的訪問量最大,為 n * r ^ (m - 1)。這將進一步導致鏈路上多層都被打掛,使整個系統雪崩。也就是我們所説的重試風暴問題
防止重試風暴
核心在於避免在同一時間點重試,並通過捨棄非必要重試,減少重試的次數
隨機退避
在常見的退避策略(如指數退避)中,引入隨機性,使每個客户端的重試時間有所不同。通過在重試間隔中加入隨機抖動,可以避免多個客户端在同一時刻重試,減少重試請求的衝突,可以有效減少系統的瞬時負載壓力。這在網絡波動的情況下,會有比較好的效果
假設重試的間隔是 2s、4s、8s,那麼可以對這些時間加入隨機範圍(例如 ±20%),使得實際重試時間為 1.6s ~ 2.4s、3.2s ~ 4.8s、6.4s ~ 9.6s
(是否想起了 Redis 緩存雪崩的解決方案?設置離散的過期時間,避免緩存在同一時間點失效)
避免無意義的重試
不是所有錯誤都適合重試,某些錯誤(如請求參數錯誤、權限問題等)不應該重試。通過根據錯誤類型判斷是否需要重試,可以避免無效重試
可以在系統中對錯誤進行分類,針對網絡故障或服務器暫時不可用的錯誤可以重試,而對於客户端錯誤(如 403、404 等)則直接返回錯誤信息,不進行重試
重試熔斷
對於單點而言,除了限制重試次數外,還要限制重試請求的成功率。對於失敗率高的請求及時熔斷
基於斷路器的思想,限制「請求失敗/請求成功」的比率,給重試增加熔斷功能。可以採用滑動窗口的方法來實現,如下圖,內存中為每一類 RPC 調用維護一個滑動窗口,比如窗口分 10 個 bucket ,每個 bucket 裏面記錄了 1s 內 RPC 的請求結果數據(成功、失敗)。新的一秒到來時,生成新的 bucket ,並淘汰最早的一個 bucket ,只維持 10s 的數據。在新請求這個 RPC 失敗時,根據前 10s 內的 失敗/成功 是否超過閾值來判斷是否可以重試。默認閾值是 0.1 ,即下游最多承受 1.1 倍的 QPS ,可以根據需要自行調整熔斷開關和閾值
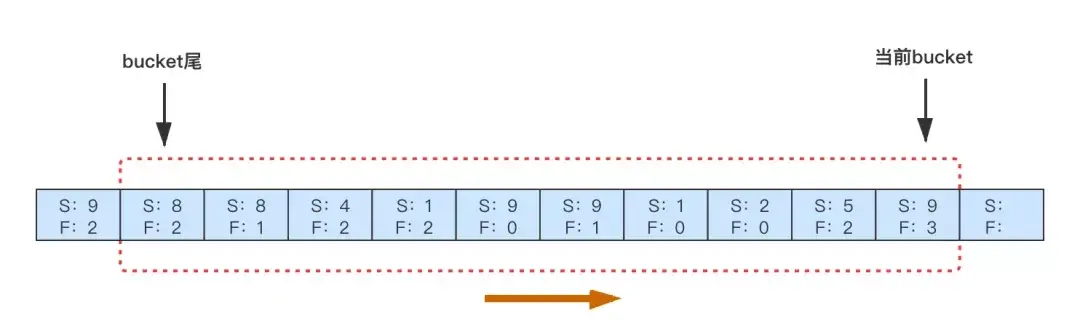
鏈路上傳錯誤標誌
雖然單點的重試被限制在了 1.1 倍,但鏈路級的重試依舊指數級增長
鏈路層面的防重試風暴的核心是限制每層都發生重試,理想情況下只有最下一層發生重試。達到“只有最靠近錯誤發生的那一層才重試”的效果。Google SRE 中指出了 Google 內部使用特殊錯誤碼的方式來實現:
- 統一約定一個特殊的 status code ,它表示:調用失敗,但別重試
- 任何一級重試失敗後,生成該 status code 並返回給上層
- 上層收到該 status code 後停止對這個下游的重試,並將錯誤碼再傳給自己的上層
在字節跳動內部用的 RPC 協議中,通過 Response 擴展字段中傳遞錯誤碼標識 nomore\_retry,告訴上游不要再重試
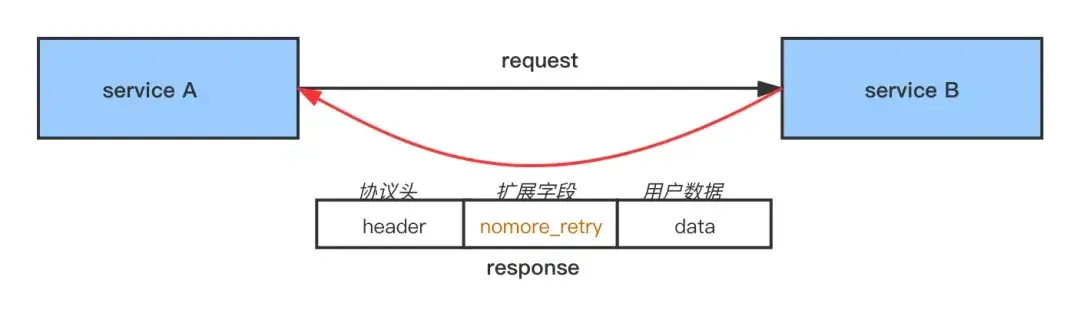
鏈路下傳重試標誌
在錯誤碼上傳的方案中,超時的情況可能導致傳遞錯誤碼的方案失效,因為客户端沒有接收來自下游的錯誤碼標誌,畢竟請求超時了。客户端不知道下游什麼情況,選擇繼續重試,鏈路的重試次數又將指數級地增大
所以不僅要上傳錯誤標誌,還要下傳重試標識,從而達到“對重試請求不重試”的效果
在 Request 中打上一個特殊的 retry flag ,在上面 A -> B -> C 的鏈路,當 B 收到 A 的請求時會先讀取這個 flag 判斷這個請求是不是重試請求,如果是,那它調用 C 即使失敗也不會重試;否則調用 C 失敗後會重試 C 。同時 B 也會把這個 retry flag 下傳,它發出的請求也會有這個標誌,它的下游也不會再對這個請求重試。
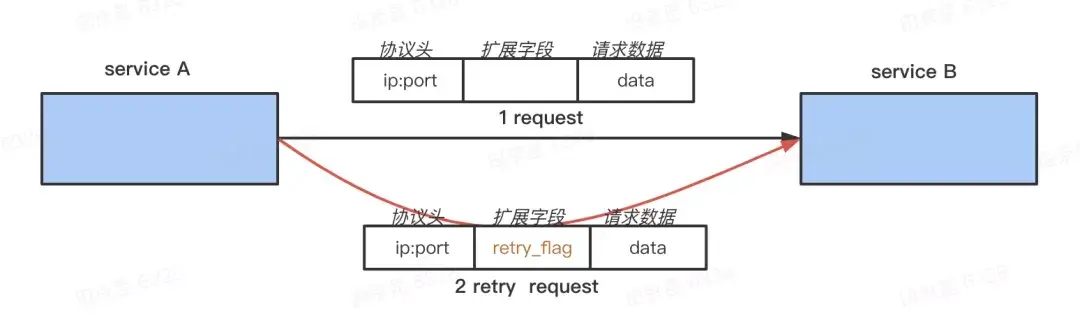
這樣即使 A 因為超時而拿不到 B 的返回,對 B 發出重試請求後,B 能感知到並且不會對 C 重試,這樣 A 最多請求 r 次,B 最多請求 r + r - 1,如果後面還有更下層次的話,C 最多請求 r + r + r - 2 次, 第 i 層最多請求 i * r - (i-1) 次,最壞情況下是倍數增長,不是指數增長了
DDL
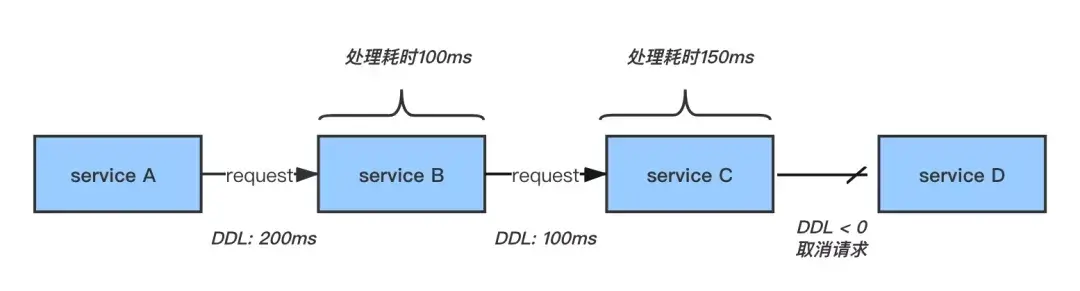
DDL 是“ Deadline Request 調用鏈超時”的簡稱,是一種全鏈路式的調用超時,可以用來判斷當前的 RPC 請求是否還需要繼續下去
如下圖,在 RPC 請求調用鏈中會帶上超時時間,並且每經過一層就減去該層處理的時間,如果剩下的時間已經小於等於 0 ,則可以不需要再請求下游,直接返回失敗即可
結語
以上討論的超時時間、長尾請求、重試等問題,都是在網絡背景下對遠程服務進行調用所產生的。那這正是我們的 RPC 的工作。所以,如果我們需要搭建一個高可用的 RPC 框架,最好需要具備以下功能:
-
減少長尾請求的影響
- 彈性超時:允許一定的請求超出原設定的時間,減少超時重試次數
- 備份請求:在即將超時之前,提前重試,通過提高一定的訪問量來降低延遲
-
避免重試風暴
- 隨機退避:避免多個客户端在同一時刻重試
- 避免無意義的重試:像請求參數錯誤、權限問題,沒必要去重試
- 重試熔斷:當重試成功率低時,及時熔斷,減少單點重試次數
- 鏈路上傳錯誤標誌:保證只有最靠近錯誤發生的那一層才重試,減少全鏈路重試
- 鏈路下傳重試標誌:對重試請求不重試,減少全鏈路重試
- DDL:全鏈路式的調用超時,判斷請求是否繼續執行下去
- 冪等:可以由業務自己實現冪等,比如通過 AOP 實現
- 限流:需要對服務調用方限流,保護自己;自己對其他服務發送請求也需要限流,保護服務提供方,並使請求流量分配更公平(避免某個節點佔據了服務提供方的絕大部分資源,導致其他節點出現“飢餓”問題)
- 降級:當服務不可用時,可以返回默認信息或 mock 數據,及時響應數據
如果文章對你有幫助,歡迎點贊+收藏+關注,有問題歡迎在評論區評論哦!
公眾號【牛肉燒烤屋】
B 站【愛烤豬蹄的喬治】
參考資料
https://mp.weixin.qq.com/s/5YDkKwpJmN-WHxzSpxP-4A
https://www.infoq.cn/article/5fBoevKaL0GVGvgeac4Z
https://www.nowcoder.com/discuss/353146786191712256
封面:意念艾特感嘆號












