









在雲原生當道的2025年,企業建數據平台,ETL和ELT到底怎麼選?這個看似基礎的架構選擇,後期一旦選錯,遷移成本可能高達初始投入的5倍!雖然ETL和ELT這兩個詞提了十幾年,但今天它們的內涵和適用場景已經大不相同。別再憑老經驗做決定,選錯數據架構,燒錢又費勁!這篇文章就帶你徹底搞清ETL和ELT的本質區別,並基於你的數據本身、團隊技能和現有基礎設施,給出2025年的務實選擇建議。怎麼選才不踩坑?看下去就知道了。
一、ETL與ELT是什麼
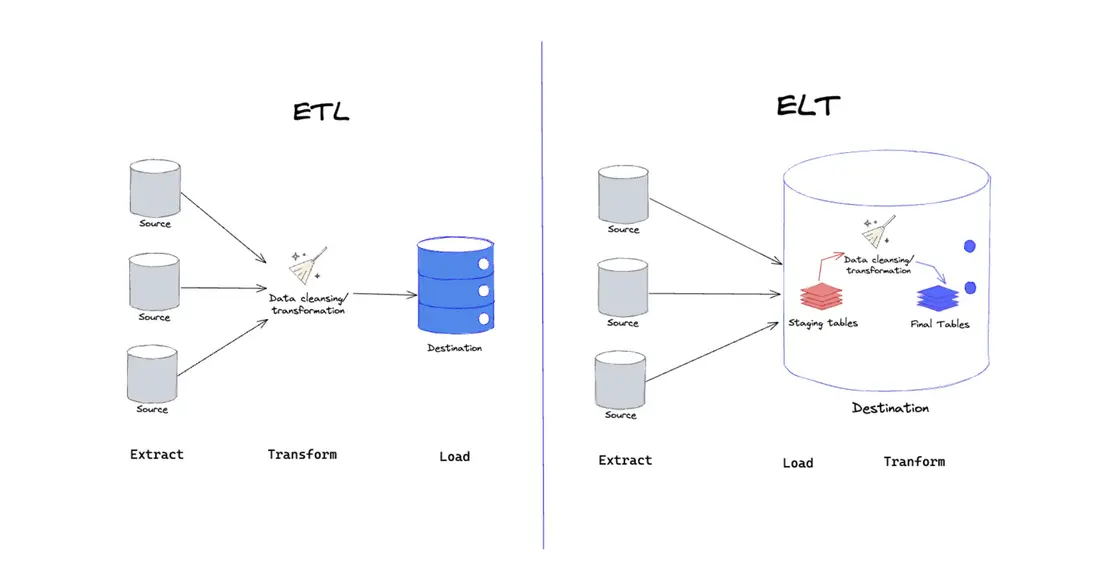
當企業面臨構建數據分析平台的關鍵決策時,一個基礎但至關重要的問題常被提出:ETL還是ELT? 要理解這個選擇的價值,首先必須釐清兩者的運作本質。
1.ETL (Extract-Transform-Load)
(1)核心流程:首先從各源頭系統提取(E)原始數據,隨後在傳統數倉服務器、專用 ETL 服務器等獨立處理引擎中,進行集中清洗、轉換(T),這其中包括類型轉換、過濾、連接、聚合等操作,最終將加工好的結構化數據加載(L)到目標數據倉庫或數據湖。
(2)數據處理位置:“T”(轉換)發生在加載到目標存儲之前。
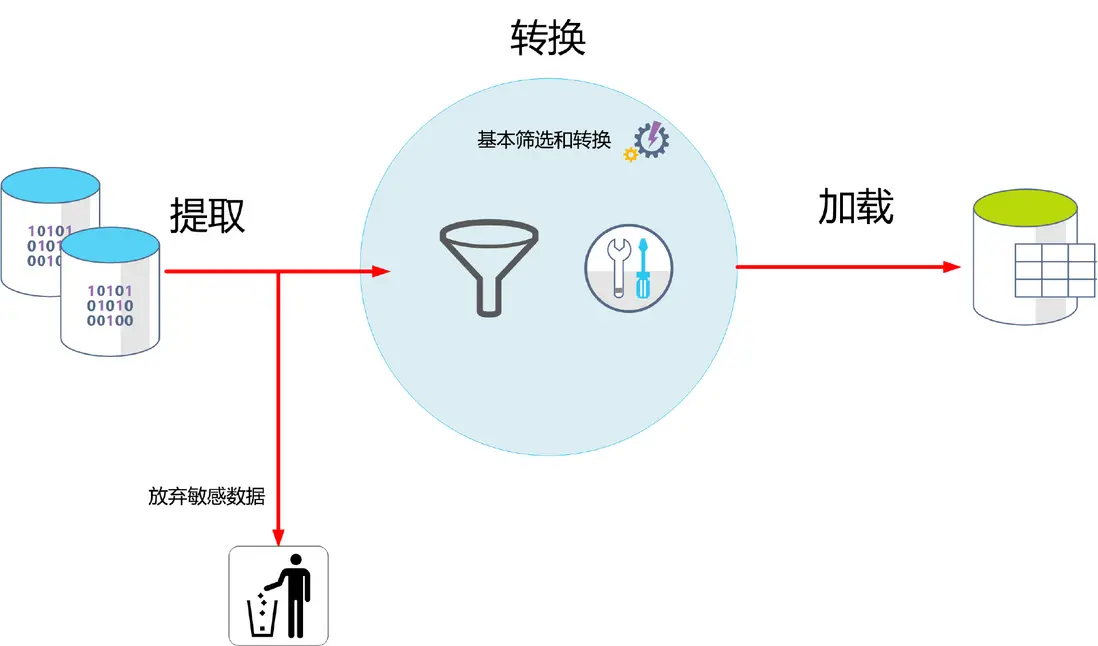
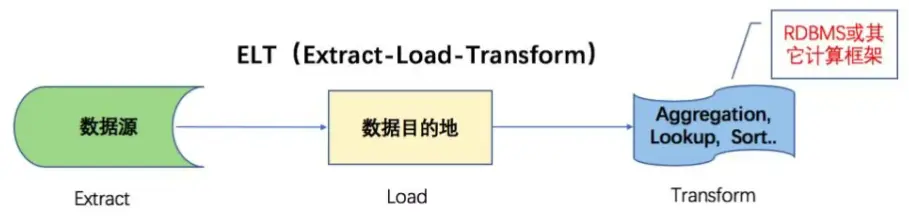
2.ELT (Extract-Load-Transform)
(1)核心流程:同樣從源頭提取(E)數據,但隨後直接加載(L)或僅簡單緩衝原始數據到目標系統,通常是具備強大計算能力的雲數據倉庫或分佈式存儲。在此目標系統內部完成核心的清洗與轉換(T)工作。
(2)數據處理位置:“T”(轉換)發生在加載到目標存儲之後,利用目標系統的計算能力。
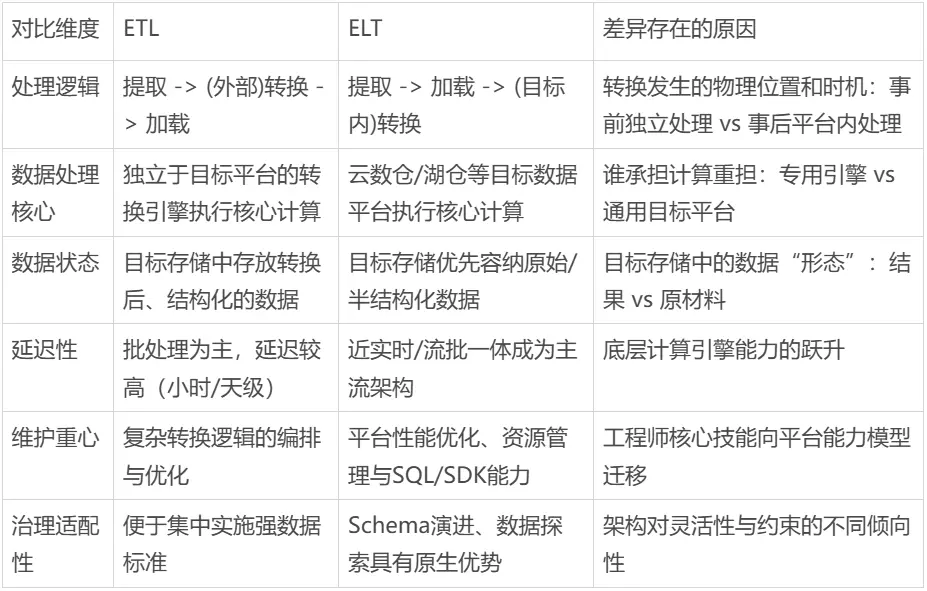
二、ETL vs ELT 的不同維度對比
在瞭解了ETL與ELT的基本定義後,我們再來看一下它們在不同維度上的對比。這裏我做了一張對比圖,可以幫助大家更直觀地看清楚兩者的差異。
三、2025年的ETL和ELT對比10年前的最大區別
與10年前的技術狀態相比,2025年的ETL和ELT已經因三大技術變革而發生一些變化:
1.雲數倉的壓倒性主流化
(1)過去(2015年):本地物理服務器部署為主,計算資源擴展笨重,存儲計算緊耦合導致性能瓶頸普遍存在。
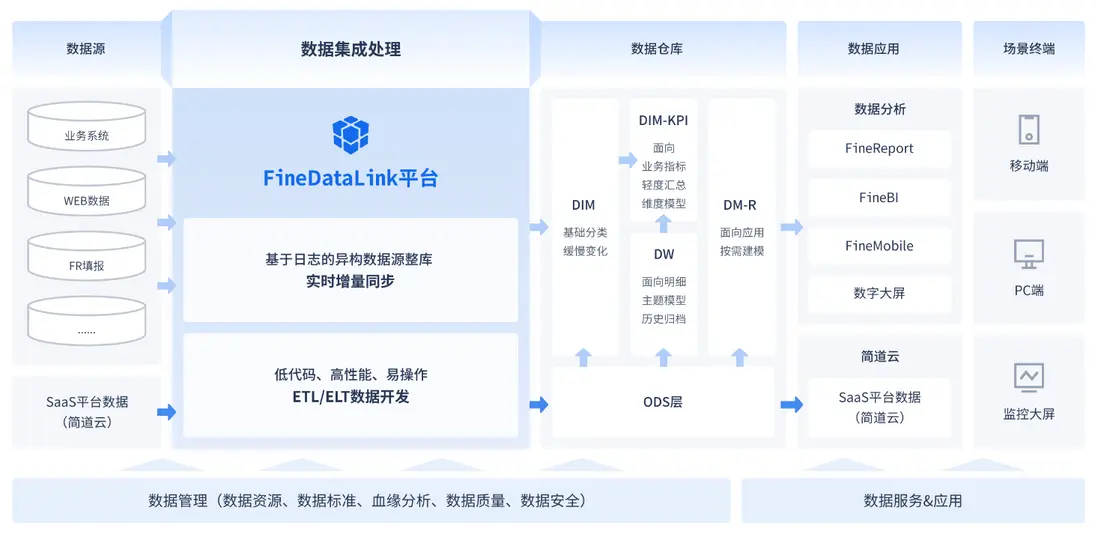
(2)現在(2025年):超過90%的新建分析系統採用雲數倉,如Snowflake、BigQuery、Redshift、Databricks等。存儲與計算資源秒級解耦/彈性伸縮成為基礎能力,存算成本不再線性捆綁,“數據加載後處理”的ELT模式在經濟性與性能上具備壓倒性優勢。我在搭建數據倉庫時常常選擇FineDataLink作為ETL工具,它具有強大的ETL調度器和引擎,可以快速地從不同來源的數據源中抽取、轉換和加載數據,大大縮短了數據處理的時間。同時提供了可視化界面和預定義模板,可以快速地配置和管理ETL流程,並且提供詳細的日誌和報告信息。大家可以點擊文末”閲讀原文“在線體驗一下,看是不是像我説的這麼好用。
2.分佈式引擎的深度進化
(1)過去(2015年):MapReduce(Hadoop)主導,複雜計算需冗長編程;MPP架構剛起步。
(2)現在(2025年):Spark成為統一計算引擎,它深度支持大規模內存計算、DAG優化及Python/SQL/流處理,使TB級數據在分佈式環境中的轉換效率大大提升。ETL工具也演化為兼容多種運行環境的編排層,FineDataLink集定時/實時同步、數據開發、數據調度、數據服務、運維等為一體,一個工具就可以解決數據在任意數據終端間的傳輸、處理問題,方便好用。
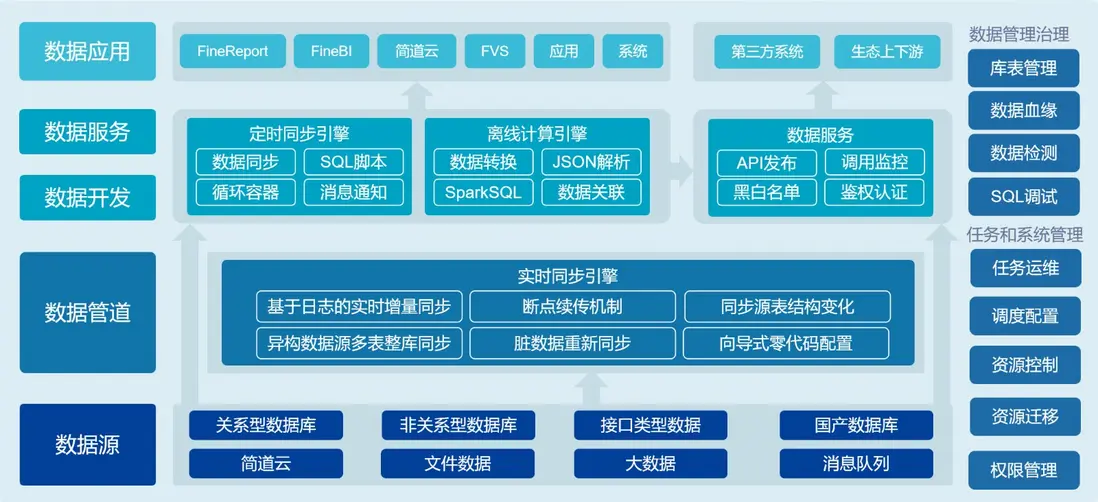
3.實時數據管道的常態化需求
(1)過去(2015年):“T+1”(隔天可見)是主流節奏,準實時處理屬於前沿探索。
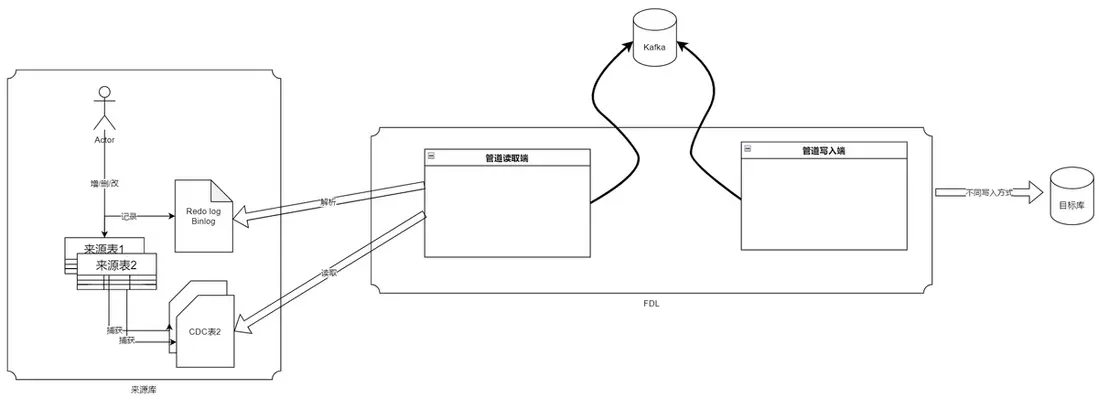
(2)現在(2025年):分鐘級、秒級延遲成為標配業務需求。Flink、RisingWave等流處理引擎支撐真正的ELT(實時ELT),直接對數據流進行持續轉換。通過 FineDataLink 配置 Kafka 消息隊列,可以將傳感器數據實時發送到 Kafka 主題中。數據分析平台訂閲該主題,實時獲取傳感器數據。這樣可以實現數據的實時傳輸和處理,及時發現生產過程中的問題。
四、企業該選ETL還是ELT
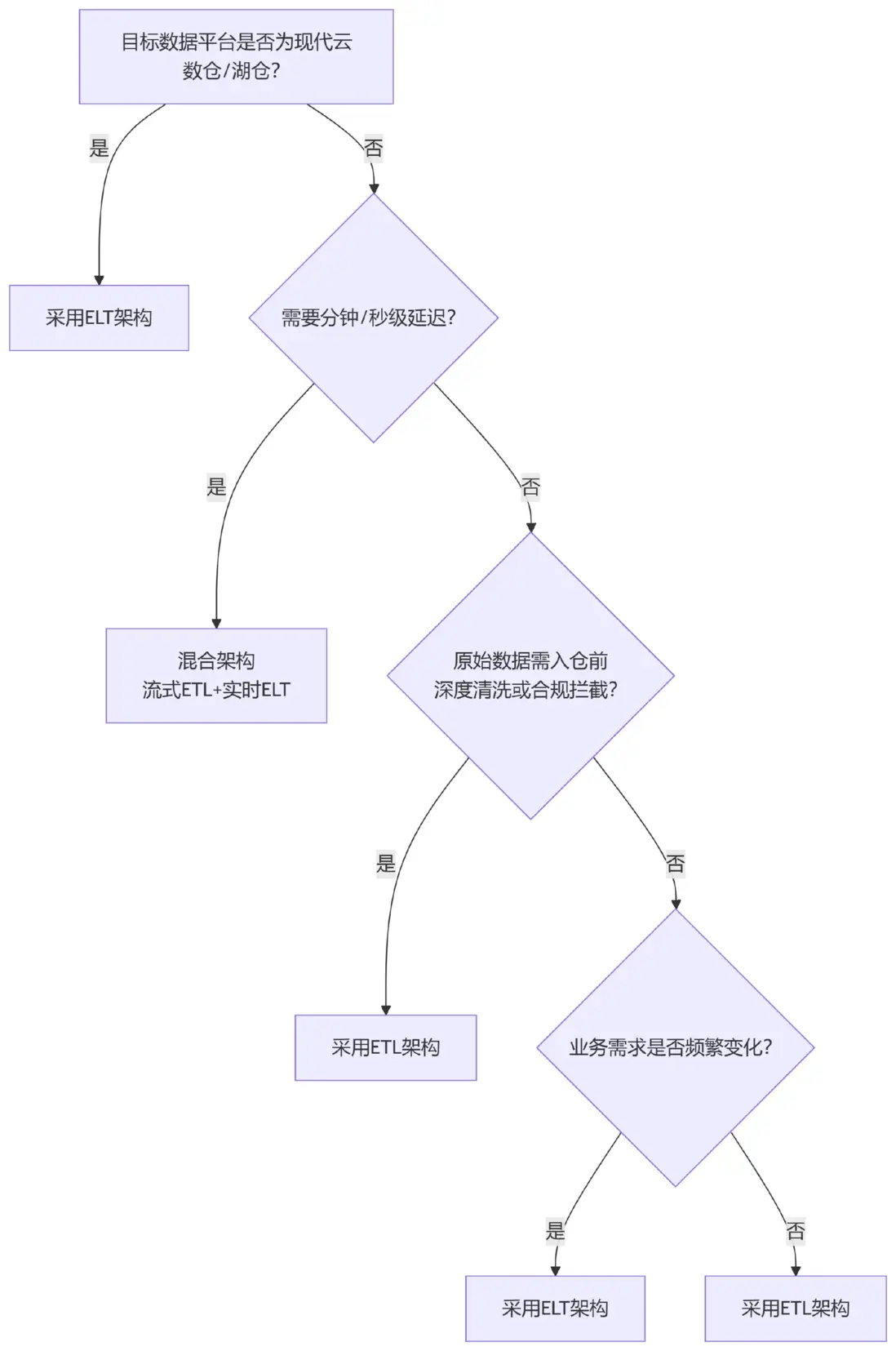
在選擇ETL還是ELT的時候,不能一概而論,需要從數據、團隊、設施三個方面仔細權衡。
維度1:數據特徵
1.傾向選擇ELT的情況
(1)數據量大、增長快:數據量達到TB甚至PB級別且持續增長,ELT可將數據先存入目標系統,利用其計算能力處理,避免因數據量大而處理不過來。
(2)數據格式複雜:數據包含JSON、日誌、圖片、文本等半結構化或非結構化數據,佔比高。ELT能先存儲這些數據,後續按需清洗和轉換。
(3)業務變化頻繁:業務經常調整,數據清洗邏輯需隨之改變。ELT允許先存儲數據,後續隨時調整清洗邏輯,靈活性高。
2.傾向選擇ETL的情況
(1)數據結構穩定:數據規整、格式固定、模式穩定,ETL可在數據入倉前完成清洗,直接存入結構化數據。
(2)入倉前需要深度清洗:數據含敏感信息需脱敏,或需滿足合規要求過濾,ETL可在加載前完成複雜清洗。
(3)計算資源有限且成本敏感:目標數據倉庫計算資源有限、成本敏感,ETL可在外部完成大部分轉換,減輕目標倉庫壓力,降低成本。
維度2:團隊能力
1.ETL適配團隊
(1)SQL能力:團隊熟悉SQL,能寫複雜查詢語句(包括UDF和窗口函數),ETL適合,因其轉換操作多用SQL。
(2)性能優化經驗:團隊有目標數據平台性能優化經驗,能合理配置資源,提升性能。
(3)流處理技術理解:業務有實時數據處理需求,團隊瞭解流處理技術棧(如Flink、Kafka),可考慮ETL。
2.ELT適配團隊
(1)ETL工具或編程語言開發能力:團隊對特定ETL工具(如Informatica、Talend)或編程語言(Scala、Python)有深度開發能力,適合ELT,因其需在目標系統中進行復雜轉換。
(2)數據流編排與錯誤處理經驗:團隊能處理複雜數據流,合理編排處理順序,快速定位和解決錯誤,這是ELT所需能力。
(3)異構數據源連接與轉換邏輯設計:數據來源複雜,涉及多種數據源,團隊能熟練連接並設計合理轉換邏輯,ELT更合適。
維度3:基礎設施
1.傾向選擇ELT的情況
(1)現代雲數倉:核心平台是現代雲數倉,如Snowflake、BigQuery等,具備強大計算能力和彈性擴展能力,ELT可充分利用這些優勢,先存數據再處理。
(2)存算分離架構:基礎設施支持存算分離,存儲和計算可分開擴展,ELT能靈活分配資源,按需處理數據。
(3)充足計算資源預算:企業有足夠的預算支持計算資源投入,ELT可更好地發揮其優勢,利用目標系統計算能力。
2.傾向選擇ETL的情況
(1)傳統本地部署數倉:使用傳統本地部署數倉,計算和存儲資源有限,ETL可在外部完成大部分轉換,減輕本地數倉壓力。
(2)特定非主流數據源連接需求:需連接非主流數據源,ETL工具提供豐富連接選項,滿足需求。
(3)跨雲/混合雲數據整合需求:有跨雲或混合雲數據整合需求,ETL可在不同雲環境間抽取、轉換和加載數據,實現整合。
決策樹模型參考:
五、總結
ELT已經成為雲數倉時代的主要範式,通過目標平台內轉換,實現計算資源按需伸縮,滿足原生適配實時與非結構化數據處理需求;而ETL的價值則聚焦於跨環境數據編排、敏感數據預清洗與混合雲集成場景,核心角色轉向智能調度層。但技術決策並非二選一,而是基於企業具體數據資產、團隊技能與基礎設施現狀的架構重組。2025年的最優解,正走向以雲數倉的ELT能力為主體,針對敏感數據攔截、流數據預處理的ETL模塊為補充的混合架構。這種混合模式在保障安全合規的同時,最大化釋放了雲平台的彈性計算效能。












