









我發現很多企業做數字化,都遇到過這些問題:
- 上了ERP、MES、SCADA等系統,但數據互不聯通;
- 想做個生產分析,發現數據在ERP裏,質量數據在MES裏,設備數據又在另一個系統;
- 領導想看實時生產情況,IT部門卻要花好幾天整理數據。
但説到底,我們不是沒有數據,而是缺少一套能夠打通數據、真正服務業務的數據架構。
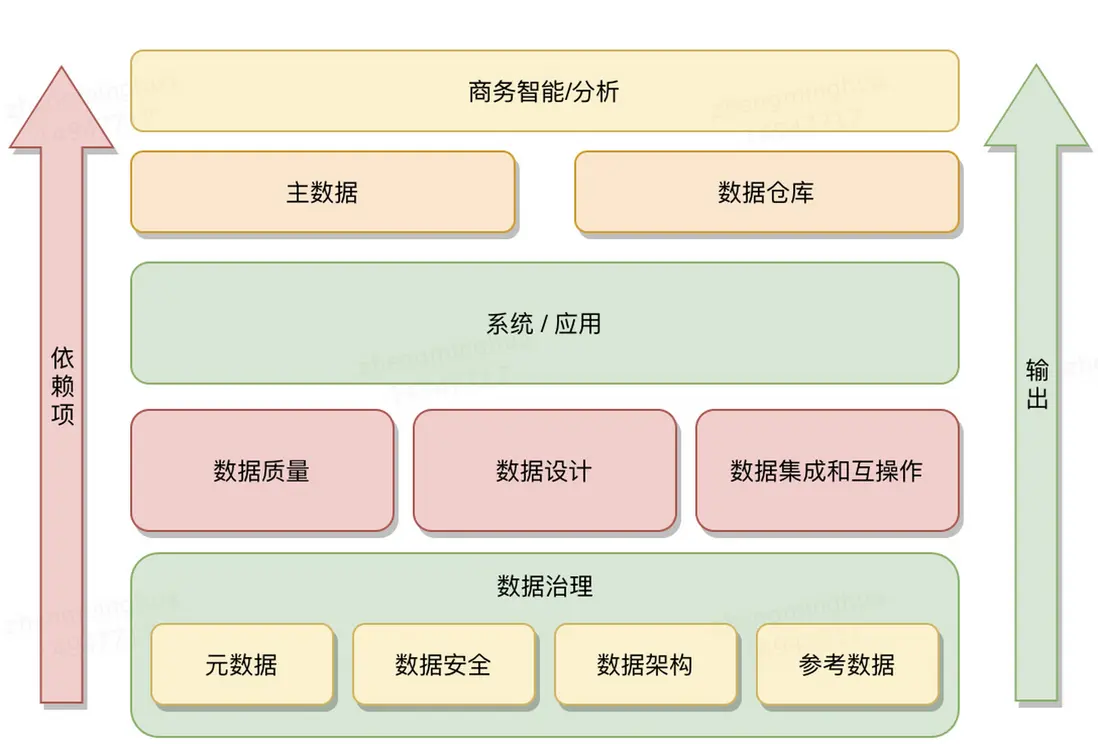
一、先搞清楚什麼是數據架構
一提到“架構”,有人覺得是 IT 部門的“技術黑話”,離生產太遠。
其實不是,數據架構就是企業數據管理的核心規矩:明確數據從產生到用起來的每一步該怎麼做,確保數據能幫到生產、質量、供應鏈這些實際業務。
説白了,數據架構的核心是管數據的存儲、計算、流轉與應用。它不是簡單的技術選型問題,而是決定企業數能不能用,好不好用以及怎麼用的底層邏輯。
比如某汽車零部件廠想做“設備故障提前預警”。
首先要明確數據架構:要從SCADA、MES拉數據,這就用到數據集成和互操作;接着讓兩個系統的數據能夠對接,防止數據使用出現問題。
接下來,像設備編號這種主數據得統一格式,比如全改成 “機2024-41” 這樣。不要在MES 裏叫“設備41”,SCADA 裏卻叫“機202441”,不然到時候對着數據查問題,就非常麻煩了。
數據質量這塊也得跟上,如果出現傳異常值,得把這種數據過濾掉,不然會影響後面分析。最後靠商務智能/分析工具,爭取提前發現問題。
在這一整個流程裏,每個模塊都得在數據架構的邏輯下配合,缺一個環節都不行。
二、數據架構到底有啥用
我發現很多企業花大價錢上系統、裝傳感器,最後卻覺得數據沒用,其實是沒靠數據架構把數據“用活”。我在這裏舉出數據架構能幫助企業解決的幾個剛需問題:
1. 打破數據孤島,不用再手動 “湊數據”
你有沒有遇到過這種情況:財務用ERP,生產靠MES,研發看PLM,每個系統互不聯通,數據根本對不上?
這些分散的系統,正是孤島的根源。
如果要打破數據孤島,就要做到物理集中,也就是:把數據以原始形態匯入統一平台。
數據架構的作用,就是從根源上制定統一的數據標準和接入規範。簡單來説,它讓不同來源、不同格式的數據能夠順暢交互。
想要解決數據孤島難題,最簡單的辦法就是直接用成熟的數據集成工具,把各系統、各部門之間的數據打通、整合,比如我常用FineDataLink,它能接入多個數據源,包括ERP、FR填報、WEB、CRM等等,對數據進行統一處理,更好地服務於前端應用。體驗地址放在這裏了,建議大家上手操作試試:https://s.fanruan.com/6wxjw(複製到瀏覽器打開)
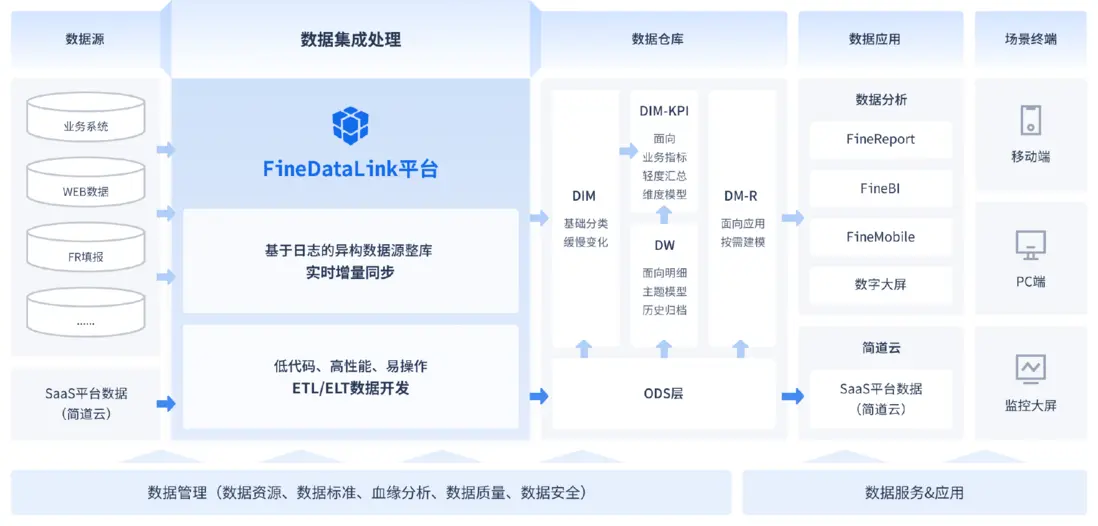
數據架構在第一步,就能統一數據標準,也就是為所有數據建立一套“通用語言”,比如在錄入客户信息上有明確規則:所有系統統一使用“客户ID”作為唯一標識。
第二步是通過建立數據集成通道,在各個系統之間架起橋樑。財務系統可以直接調用Excel中的銷售明細,用於計算提成。
最後,數據架構還會制定清晰的管理規則:哪些人有權訪問、能夠修改哪些字段出了問題該找誰。
以過來人的經驗看,如果建立起了這套機制,那麼原本割裂的數據孤島就能轉變為協調統一、可用可信的數據整體。無論是分析還是決策,效率都將大幅提升。
2、讓數據能分析、能決策
我一直強調,數據要能用起來,必須滿足三個條件:可以實時採集、能夠歷史追溯、並且質量可信。
比如某家汽車零部件企業就憑藉清晰的數據架構,對內部數據資產進行系統性梳理,建立了覆蓋生產全流程的數據體系。通過實時採集生產設備運行狀態和關鍵工藝參數,結合歷史數據對數據進行異常檢測與模式識別,最後這個企業成功實現故障實時預警與產品質量的精準追溯。所以,有了清晰的數據架構,在數據的分析和處理上能給企業帶來不小的效果。
如果有良好的數據架構就能實現端到端的數據管道。比如某家汽車零部件廠就是通過構建出清晰的數據架構,定期梳理數據,就實現了故障的實時預警和品質追溯,第二年直接省了三百多萬廢品成本。
3. 解決數據 “亂、錯、雜”
發現企業數據最常見的問題大多數是:重複記錄、命名混亂和單位不統一。

數據架構裏面有一個核心環節叫“數據治理”,説白了就是明確數據誰產生、誰維護、誰使用。
這一步聽起來基礎,但絕大多數工廠問題就出在這裏。
我們可以通過三個步驟解決這個問題:
- 確定一個統一的標準:比如統一物料編碼,統一工藝參數單位
- 做異常數據過濾:比如設定“設備温度正常範圍 20-80℃”,超出這個範圍的數據,系統自動標紅並提醒維保工程師核查,不用再人工一條條看;
- 明確誰負責哪類數據:生產數據由車間文員負責,設備數據由維保工程師負責,數據錯了能找到人改,避免 “數據沒人管”。
比如有個做小家電的廠子,原來同一批原材料在 3 個系統裏有 3 個名字,盤點時每次都差 100 多件。自從定了數據標準後,3 個系統統一名稱,盤點誤差直接降到了 1% 以內,庫存準確率提上來了,再也不用因為怕缺貨而多囤貨,資金佔用少了 20%。
4. 撐得起數字化升級+AI應用
現在大家都在説“數字孿生”、“智能工廠”,但這些不是光買軟件就行的,沒有好的數據架構,數字孿生和智能工廠就只能是空喊口號。
我總結了幾點數據架構的作用:
- 提供乾淨、結構化、實時的數據,讓AI模型訓練更準確
- 讓數字孿生能夠實時反映生產狀態
- 支持邊緣計算+雲計算的混合架構,優化數據存儲和計算成本
説白了,數據架構看起來是技術問題,其實是業務問題。從痛點出發,打通企業全鏈路,讓數據能夠指導行動,企業才能活的更久,發展的更穩。
三、企業怎麼選數據架構
你是不是經常刷到“數據中台多厲害”的文章,看完就慌了?我一直強調,選數據架構不是比誰的技術新,而是看誰的架構更適配自己的業務。
下面我給大家從三個方面去思考,怎麼選適合的數據架構:
1.看企業數字化階段
初級階段(信息化):傳統數據架構(ERP+數據倉庫)就能滿足基礎需求,不用過度追求複雜架構。
中級階段(數字化):大數據架構(數據湖+實時計算)更合適,能夠支持海量數據的分析。
高級階段(智能化):雲原生或邊緣計算架構支撐AI和數字孿生。
2. 看數據類型
結構化數據(訂單、BOM表):傳統數據倉庫足夠,不用再考慮搭建複雜存儲體系。
非結構化數據(設備日誌、圖像):需要數據湖或邊緣計算,這樣能夠實現高效存儲與調用。
3. 看實時性要求
分鐘級/小時級分析:傳統架構或大數據架構,性價比更高。
秒級/毫秒級響應(如設備故障預警):用實時計算或邊緣架構,能保證效率。
總結
數據架構是直接影響生產效率、質量、成本的關鍵因素。
你下次為數據架構設計感到困惑或棘手時,可從以下三個核心方向去思考:
是否有可靠的保障機制來確定數據的準確性和統一性?全鏈路數據流能不能快速響應業務分析的即時需求?現有架構設計,是在為未來業務的擴展提供有效賦能還是隻是在積累業務債務?
把這幾個問題想清楚,那就離選擇合適的數據架構不遠了。












