









基於人類反饋的強化學習(RLHF)已成為大型語言模型(LLM)訓練流程中的關鍵環節,並持續獲得研究界的廣泛關注。
本文將探討RLHF技術,特別聚焦於直接偏好優化(Direct Preference Optimization, DPO)方法,並詳細闡述了一項實驗研究:通過DPO對GPT-2 124M模型進行調優,同時與傳統監督微調(Supervised Fine-tuning, SFT)方法進行對比分析。
本文將系統闡述DPO的工作原理、實現機制,以及其與傳統RLHF和SFT方法的本質區別。
RLHF的基本原理
RLHF在LLM訓練的後期階段發揮關鍵作用,其核心目標是使模型與難以明確定義的微妙人類偏好達成更好的一致性。以下將詳細分析其必要性。
現代LLM的訓練通常包含多個階段:
預訓練階段是第一階段,模型通過在互聯網等來源的海量文本數據上優化交叉熵目標進行訓練。對於規模最大的模型,預訓練數據集可能包含數萬億個非結構化token。該階段使模型掌握基本的語言結構和事實性知識,形成一個能夠準確完成句子和獲取事實的"基礎"模型,但其輸出往往缺乏對話的自然性。
監督微調是第二階段,模型在精心構建的問答對數據集上進行訓練,這些數據集明確定義了特定上下文的最優響應。這些最優響應通常由領域專家編寫,確保其格式規範、長度適當且信息充分。
RLHF構成第三階段。該階段旨在優化模型在那些難以精確定義但易於判斷的行為場景中的表現(例如當AI公司期望其模型展現出順從和友善的特質時),雖然創建數千個符合這些標準的最優響應成本高昂且耗時,但對已有響應進行評判則相對容易。這表明RLHF在優化那些難以生成標準答案但易於評估的行為方面具有獨特優勢。
經典RLHF:獎勵模型與PPO的結合
首先,我們需要理解RLHF最經典的實現方法,該方法最初由OpenAI在2019年的研究中提出。為簡明起見,本節將從較高層面進行闡述。
RLHF的基礎是偏好數據集的構建。這通常通過向人類評估者展示提示和可能的完成結果集合,並讓其選擇最佳完成結果來實現。RLHF的核心目標是訓練模型生成那些能夠被人類評估者選為最佳迴應的內容。
從強化學習的角度,這個問題可以進行形式化描述。我們可以將LLM視為參數化策略,其中環境狀態由輸入LLM的上下文表示,模型通過生成新token來執行動作。一個完整的生成序列即構成一個軌跡。
關鍵觀察在於,我們的偏好數據集本質上是一組軌跡及其對應的"質量"評分。其中的技術要點在於我們可以將偏好數據轉化為分配給每個完成結果的標量獎勵,使得最受偏好的完成結果獲得更高的獎勵值。這樣就能將軌跡與其最終獎勵建立關聯,這就意味着最大化策略價值等同於最大化所有軌跡的期望獎勵,也就是我們的優化目標。因此可以採用PPO等策略梯度方法來優化策略,提高產生高獎勵軌跡的概率,同時確保LLM在RLHF過程中不會發生過大的偏離。
但是由於LLM生成的多樣性,我們會面臨着極其龐大的狀態空間,策略梯度方法本質上是"在線"的,僅依賴固定的離線軌跡集合難以有效執行PPO。
所以我們不直接使用偏好數據作為軌跡,而是利用它訓練一個獎勵模型作為人類評估的代理。獎勵模型本身通常是一個LLM,接收來自actor LLM的文本輸入並輸出標量獎勵。獎勵模型的損失函數定義為:
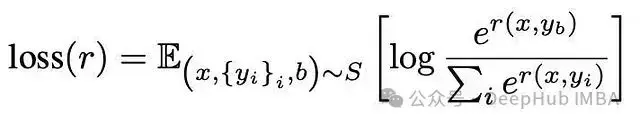
其中r表示獎勵模型,x為提示,y為候選完成結果集合,b為首選響應的索引。該模型通過學習最大化首選響應的獎勵同時抑制其他響應的獎勵值。這種"對比"機制至關重要——與僅展示高質量響應的SFT相比,RLHF教會LLM在生成高質量響應的同時主動規避低質量響應。
具體的訓練過程是在線進行的:向模型提供提示,採樣其生成結果,使用獎勵模型預測獎勵,並執行PPO更新。為防止分佈偏移影響訓練過程中獎勵模型的準確性,需要定期使用actor模型的最新生成結果重新訓練獎勵模型。
這自然引發了一個關鍵問題:RLHF為何能夠實現有效泛化?對此存在兩種可能的解釋。
悲觀的解釋認為這並非真正的泛化——部分研究表明獎勵模型存在過擬合現象,RLHF調優的模型僅是直接複製數據集中的偏好。然而在某些場景下,RLHF展現出卓越的效果,模型在各個方面都實現了顯著提升。
樂觀的解釋則認為,由於獎勵模型本身就是一個LLM,它在分配獎勵時會利用預訓練階段獲得的內部知識。因此獎勵函數實際上是多維的,隱含了預訓練階段的知識,這意味着它傳遞的信息遠超顯式的偏好。雖然這僅是一個工作假設,但它可能有助於解釋RLHF強大的泛化能力。
DPO:一種創新方法
直接偏好優化(Direct Preference Optimization, DPO)由Rafailov等人於2023年提出,該方法在不需要實際強化學習的情況下實現了RLHF的目標。DPO方法消除了對獎勵模型的依賴,轉而利用固定的離線偏好數據集進行模型調優。
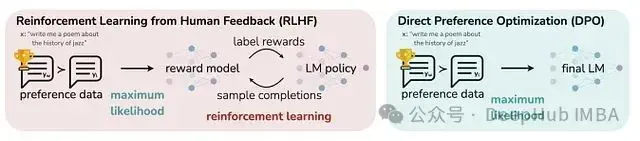
圖1:DPO與傳統RLHF的架構對比。DPO無需獎勵模型。
DPO論文的作者指出傳統RLHF流程存在時間和計算資源消耗過高的問題,主要體現在兩個方面:
首先,與典型的強化學習問題類似,訓練過程需要從actor LLM不斷生成新的完成結果——這意味着每個訓練步驟都涉及LLM的多次前向傳遞計算,導致巨大的計算開銷。這源於傳統RLHF採用在線學習方法的本質特性。
其次,訓練流程需要額外訓練一個完整的LLM(即獎勵模型)用於顯式獎勵計算。
DPO在這兩個方面都採取了不同的策略——它是一種離線方法,並通過偏好數據來隱式定義獎勵。如果將RLHF視為在線強化學習,SFT視為純行為克隆,那麼DPO則代表了兩者之間的離線強化學習方法。
DPO數據集由響應對構成,其中對於每個提示,都包含一個"被選擇"的響應和一個"被拒絕"的響應。DPO訓練涉及actor模型和一個固定的、不可訓練的參考模型(通常初始化為與actor模型相同的參數)。在訓練過程中對actor模型進行優化,同時通過正則化確保其不會過度偏離參考模型。
這導致瞭如下DPO目標函數,其中y_w表示被選擇的響應,y_l表示被拒絕的響應。本質上該損失函數促使actor和參考模型之間被選擇響應的概率比相對於被拒絕響應的概率比增長。當這種情況發生時,sigmoid內的量為正值,使得sigmoid值趨近於0,從而產生較小幅度的負對數值(導致較低的損失)。
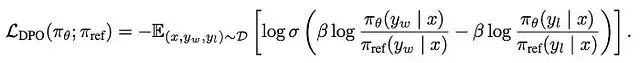
在初次接觸DPO時,可以會產生以下一些問題問題:
該損失函數與典型的交叉熵損失加KL散度項結構相似。其獨特之處究竟在哪裏?將拒絕的響應作為負樣本的實際效果如何?
考慮到模仿學習和離線強化學習固有的探索限制——使用DPO訓練的LLM在遇到數據集外的提示時是否會失效?
DPO相比於針對選定響應的純SFT是否具有實質性優勢?
為了獲得更深入的理解,我們將使用PyTorch中從零實現DPO,並將其應用於參數量為1.24億的最小規模GPT-2模型。同時,我實現了SFT以進行對比分析。
數據集構建
DPO方法的基礎是偏好數據集的構建,每個樣本包含一個提示、一個"被選擇"的響應和一個"被拒絕"的響應。被選擇的響應體現了我們期望模型展現的行為特徵,而被拒絕的響應則代表了相反的特徵。
在實際應用場景中,被選擇和被拒絕的響應往往只存在細微的差異,比如語氣或表達方式的微小變化。然而,為了便於在實驗中清晰觀察模型行為的變化,本文構建了一個具有顯著對比特徵的數據集,設定了一個明確的行為目標:要求模型在每個響應中都提及賓夕法尼亞大學(Penn)。
數據集的構建採用了基於GPT-4的合成方法。首先使用GPT-4生成一系列提示,然後對每個提示生成兩種響應:一個包含Penn相關內容(作為被選擇的響應),另一個不包含Penn相關內容(作為被拒絕的響應)。這種方法效果顯著。GPT-4能夠生成多樣化的提示,並能自然地將Penn融入被選擇的響應中。以下展示了通過該方法生成的典型示例:
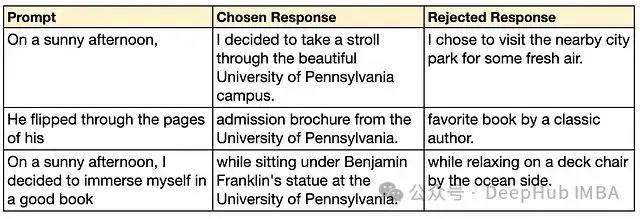
表1:合成DPO數據集中的示例樣
通過上述方法,我們最終構建了包含約1,300個訓練樣本和125個測試樣本的數據集,其中測試樣本被完全隔離用於模型評估。
HuggingFace基準實現
本文的主要目標是從零開始實現DPO,所以首先使用HuggingFace提供的DPOTrainer作為性能基準。這一基準將作為評估自主實現的DPO效果的參照標準。我們採用默認超參數配置進行了訓練,並獲得了穩定的收斂結果(如圖2所示)。

圖2. 使用HuggingFace DPOTrainer訓練過程中的損失函數變化曲線。
在保留測試集上對調優後的模型進行評估時,我們觀察到模型行為發生了顯著變化。模型的輸出表現出高度一致性,幾乎所有響應都自然地包含了對賓夕法尼亞大學的引用。表2展示了測試集中的兩個典型示例:

表2. 基礎GPT-2模型與經HuggingFace DPOTrainer調優後的GPT-2模型輸出對比。
DPO實現與訓練過程
接下來,我們使用純PyTorch實現了DPO訓練框架,以深入理解DPO的內部機制。完整的實現代碼在我本文最後提供。
從架構層面來看,DPO損失函數需要四組概率輸入——分別是actor模型和參考模型對被選擇響應和被拒絕響應的概率評估。響應的整體概率並非模型的直接輸出——模型在每個時間步只預測下一個token的概率分佈,完整響應的對數概率可以通過各個token對數概率的和來計算:
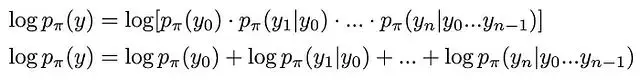
首先將響應輸入模型,通過softmax函數將原始logits轉換為概率分佈,再取對數得到對數概率。然後使用響應序列作為標籤來提取我們期望模型生成的token序列的對數概率。這些對數概率的和即為該模型對整個響應序列的對數概率評估。下圖3詳細説明了這一過程對被選擇響應的具體實現:
圖3. 從模型中提取特定響應對數概率的計算流程。
獲取全部四個對數概率後,將其代入DPO損失函數進行優化訓練。
在訓練過程中,損失函數呈現出平穩的下降趨勢,表明模型訓練過程符合預期:
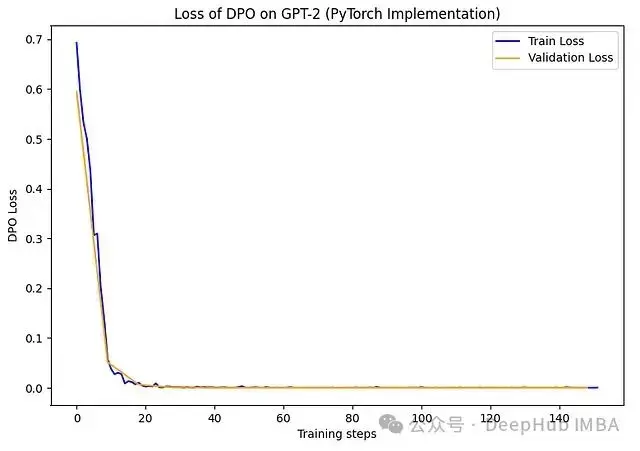
圖4. DPO訓練過程中的損失函數變化。
但是我們發現經過訓練的模型輸出出現了不連貫和重複的問題。以下是模型在保留測試集上的幾個典型輸出樣例:

表3:使用naive DPO損失訓練後的模型輸出樣例。可以觀察到輸出存在明顯的不連貫性和重複性問題。
問題診斷與分析
通過深入分析DPO損失函數的特性,我們注意到最小化損失等價於最大化sigmoid函數內部的量,該量與對數概率的差值成正比:

進一步分析發現,即使右側括號中的量變得比左側括號更快地趨向負值,整體量仍會增長。這意味着即使actor模型對被選擇響應的對數概率相對於參考模型降低,DPO損失仍可能繼續下降。這種特性很可能是導致模型過擬合和性能崩潰的根本原因。
實驗數據證實了這一推測(如圖5所示)。在DPO論文中,括號內的每個量被定義為"獎勵",這也反映在圖例的標註中。從直觀上理解,這種現象可能源於我們設定的對齊目標過於特定。在我們的實驗設置中,被拒絕的響應從客觀標準(如語法正確性和語義連貫性)來看仍是合格的響應——只是不符合我們特定的行為要求。因此對齊目標與響應質量在某種程度上是正交的,這導致了學習過程的不穩定性。
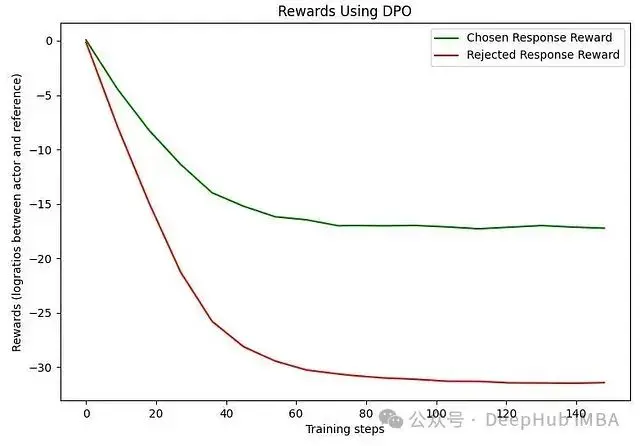
圖5. DPO訓練過程中的獎勵變化(actor和參考模型之間的對數概率比)。可以觀察到被選擇響應的獎勵實際呈現下降趨勢。
這一發現表明我們需要對損失函數進行改進,以確保actor模型對被選擇響應的對數概率始終高於參考模型。
改進的損失函數與DPOP
探索多個候選損失函數的過程,我們發現了來自Abacus.AI研究團隊的一篇論文,該論文恰好針對我們觀察到的問題提出瞭解決方案。他們提出的改進方法稱為DPOP,其核心是通過損失函數強制保持actor模型對被選擇響應的對數概率比始終為正。
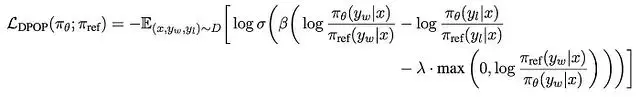
max函數內部的項在actor的對數概率低於參考模型時為正值。此時sigmoid內部的量減小,導致sigmoid值趨近於0,從而產生較大的損失值,有效地懲罰了這種不期望的情況。
實現這一改進後的訓練結果顯著優於原始方法。被選擇和被拒絕響應之間的獎勵差距在訓練過程中穩步增加,更重要的是,被選擇響應的獎勵始終保持為正值:
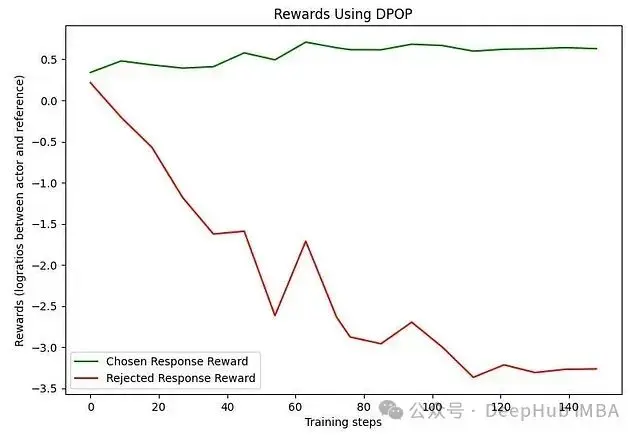
圖6. DPOP訓練過程中的獎勵變化。值得注意的是,被選擇響應的獎勵始終保持在正值區間。
改進後的模型在輸出質量上也實現了顯著提升,生成的內容更加連貫、符合語法規範且自然流暢:
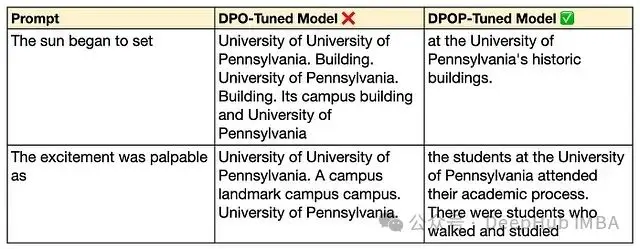
表4. DPOP與DPO模型輸出的質量對比。
這些實驗結果清晰地表明,原始DPO訓練可能導致模型性能在訓練過程中發生崩潰,而DPOP通過改進的損失函數有效地解決了這一問題。
通過在保留測試集上比較DPOP生成結果與HuggingFace實現的輸出,並使用GPT-4從連貫性、語法正確性和相關性三個維度進行評估。結果顯示原始DPO的勝率接近0%,而DPOP達到了51%的勝率。
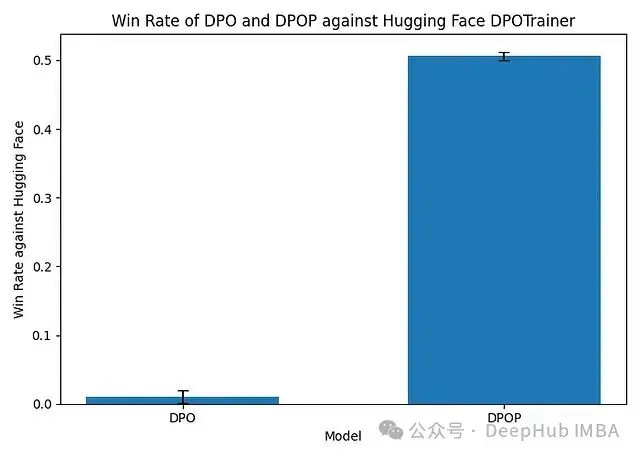
圖7. DPO和DPOP調優模型與HuggingFace DPOTrainer訓練模型的勝率對比。
與SFT的比較研究
對DPO方法的一個主要疑慮是其與SFT在本質上的相似性。所以我們以DPO數據集中的被選擇響應作為專家標註,實現並評估了基於SFT的模型訓練方法。
這裏設計了兩種不同的損失函數:

第一種稱為"SFT損失",本質上是對完整響應序列的標準交叉熵損失。
第二種稱為"KL-SFT損失",在SFT損失的基礎上增加了一個懲罰項,用於限制actor模型與參考模型之間的偏差——這可以視為一種偽KL散度度量。需要注意的是,該懲罰項對雙向偏差都進行懲罰。
我們使用這兩種損失函數對GPT-2進行微調,並將結果與DPO和DPOP方法進行系統對比。
首先可以觀察到部分SFT模型的輸出完全沒有提及Penn。為此我們引入了"對齊準確率"這一指標來評估所有訓練模型的表現——即在保留測試集上包含Penn引用的輸出比例。實驗結果顯示,DPO和DPOP調優的模型在對齊目標上保持了100%的準確率,而SFT模型的準確率分別為94%和88%。這種差異可能源於SFT模型缺乏負樣本,從而導致其輸出表現出更大的多樣性。這凸顯了負樣本在抑制模型生成那些在技術上可行但不符合期望的輸出方面的重要作用,這正是偏好優化方法的核心優勢所在。
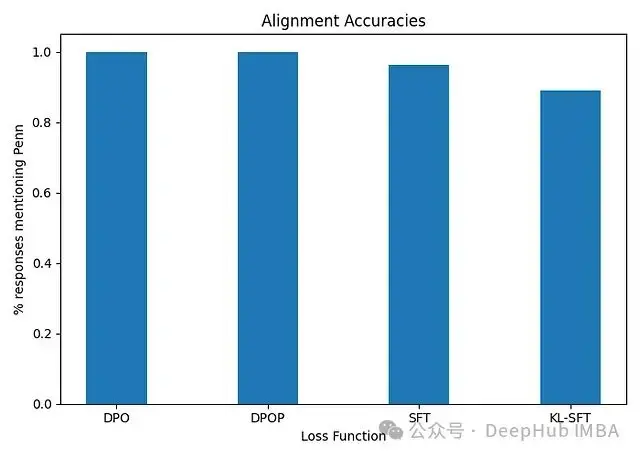
圖8. 對齊準確率反映了模型在保留測試集中提及Penn的輸出比例。DPO和DPOP接近100%,而SFT約為90%。
其次,使用GPT-4對SFT、KL-SFT、DPOP、DPO和HuggingFace DPOTrainer模型之間進行了全面的勝率評估(如下圖所示)。出人意料的是,SFT模型獲得了最高的勝率,這一結果通過對響應的人工分析得到了進一步驗證。相比DPOP和HuggingFace的輸出,SFT模型的生成結果展現出更強的創造性和更好的語法規範性。
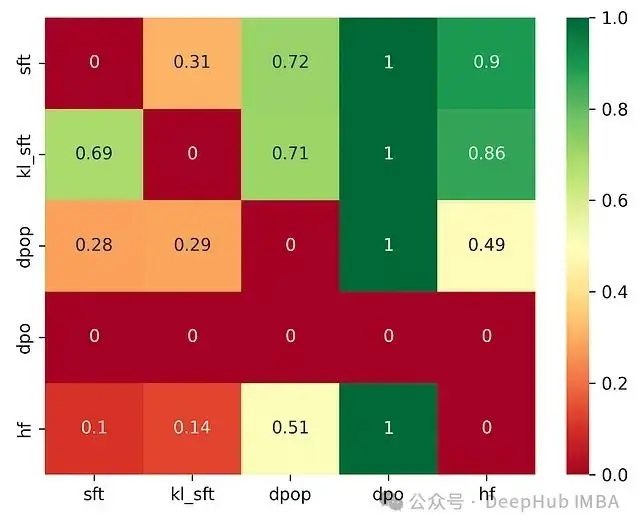
圖9. GPT-4評估的各模型對間勝率對比。SFT模型表現最佳,對DPOP的勝率達到71%。
這些實驗結果表明,在特定行為模式的優化方面,SFT可能與DPO具有相當的效果。儘管DPO通過引入被拒絕樣本提高了對對齊目標的遵循度,但這種機制也可能導致過擬合和不穩定性,從而在生成質量上略遜於SFT模型。
研究侷限性
首先,使用的數據集與真實世界的RLHF數據集有顯著差異。本文聚焦於優化一個特定的行為模式:在響應中提及Penn。而真實場景中的數據集通常反映更為微妙的偏好特徵,被選擇和被拒絕響應之間的差異更加細微。這意味着在真實數據集上,RLHF可能由於其更靈活的響應質量建模能力而顯著優於SFT。
其次,本文使用了參數量最小的GPT-2模型,這在某種程度上簡化了優化過程。這可能導致我們的評估結果存在偏差——由於模型本身知識儲備有限,很難準確評估模型是否發生了知識遺忘或性能退化。
第三,我們使用GPT-4進行對齊準確率和勝率評估,而GPT-4對提示的細微變化表現出較高的敏感性。考慮到GPT-4可能無法準確模擬人類偏好,實際的人類評估結果可能會有顯著差異。
總結
DPO是一種簡潔而高效的技術範式。相比傳統的獎勵模型+PPO的RLHF方法,它具有實現簡單、計算高效的優勢,同時能夠產生良好的優化效果。其目標函數在強化學習和SFT目標之間實現了有效的平衡,使模型能夠高度遵循DPO數據集中反映的偏好特徵,這反映在接近100%的對齊準確率上。
DPOP在穩定性方面優於原始DPO。DPO存在已知的不穩定性問題,可能導致訓練過程中被選擇響應的對數概率下降。我們的實驗結果驗證了這一問題,並證實DPOP能夠有效改善模型表現。從理論角度分析,這可能是因為我設定的對齊目標過於特定,而數據集中的被拒絕響應從語法和連貫性等客觀標準來看仍具有較高質量。在更一般性的對齊任務中,如果被拒絕響應展現出明顯的不連貫性或錯誤,DPO可能會表現得更好。
針對選定響應的SFT展現出comparable的性能。儘管SFT在保留測試集上的響應並不總是嚴格遵循對齊目標,但這些響應通常表現出更強的創造性和具體性。在GPT-4的評估中,SFT相比DPOP獲得了71%的顯著勝率。
RLHF評估面臨的挑戰。準確評估模型行為的變化程度、行為一致性以及是否保留了先前訓練階段獲得的知識,是一個極具挑戰性的任務。我們對使用前沿模型進行評估持謹慎態度,因為這些模型的評分表現出較大的方差,且對提示的細微變化特別敏感。現有RLHF文獻多采用人類評估者與AI評估者相結合的方法,這似乎提供了更好的平衡,但其實仍然有一個未解決的問題就是頂級AI實驗室是如何執行這一過程的。例如:如何向評估者傳達模型的預期行為?如何在評估者之間建立一致的評判標準?是否應該使用創建偏好數據集的同一批人類評估者?這些都是有待深入研究的開放性問題。
本文代碼
https://avoid.overfit.cn/post/d8468a92798745d298b1130c98adc934
作者:Aalok Patwa

