









用 LangChain 構建 AI Agent 的人應該都遇到過這種情況:測試階段一切正常,部署到生產環境就開始出各種問題。上下文管理混亂,Agent 的行為變得難以預測,最後不得不寫一堆自定義代碼來控制信息流向。
這是因為在v1.0 之前的 LangChain 對上下文工程的支持不夠系統化。上下文工程的本質其實就是信息管理——給 AI 多少信息、什麼時候給、以什麼方式給。信息過載會導致模型困惑,信息不足則無法完成任務。這個平衡點一直很難把握。
LangChain v1.0 引入的中間件機制就是為了解決這個問題。中間件的作用類似於一個信息協調層,在用户輸入到達模型之前進行必要的處理:
- 規範化輸入格式
- 注入相關背景知識
- 過濾敏感信息
- 限制工具調用權限
這種架構保證了模型接收到的始終是經過精心組織的上下文。
後端視角下的中間件模式
對於熟悉 FastAPI 的開發者來説,LangChain 中間件的概念幾乎可以無縫遷移。FastAPI 的中間件攔截 HTTP 請求,LangChain 的中間件攔截 Agent 調用,底層邏輯完全一致。
FastAPI 中間件處理的典型任務:
- 身份認證
- 請求日誌
- CORS 配置
LangChain 中間件的對應場景:
- 上下文管理
- 安全控制
- 工具調度
- 運行時監控
執行流程也是相同的組合模式:
- FastAPI:
Request → Middleware Stack → Endpoint Handler → Response - LangChain:
User Input → Middleware Stack → AI Model → Response
中間件按照註冊順序依次執行,這種模式讓功能擴展變得很直觀。
v1.0 之前的技術問題
Agent 失敗往往不是模型能力的問題,而是上下文處理出了問題。主要體現在幾個方面:
缺少靈活的上下文切換機制。不同場景需要不同的上下文策略,但實現起來很麻煩。長對話的上下文管理是個難題。Token 限制對話歷史太長模型就處理不過來了。工具調用權限難以精確控制。有時候你只想讓 Agent 使用特定的幾個工具,但沒有優雅的方式來實現這個需求。任何稍微複雜的需求都得寫自定義代碼,沒有標準化的解決方案。
舊的實現方式充斥着大量配置參數:
from langchain.agents import AgentExecutor, create_openai_tools_agent
from langchain_openai import ChatOpenAI
tools = [search_tool, calculator_tool, database_tool]
llm = ChatOpenAI(model="gpt-4")
agent = create_openai_tools_agent(llm, tools, prompt)
# Too many confusing settings!
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
max_iterations=15, # How many times can it try?
max_execution_time=300, # How long can it run?
handle_parsing_errors=True, # What if something breaks?
return_intermediate_steps=True, # Show me the steps?
trim_intermediate_steps=10, # How much to remember?
# and many more confusing options...
)更極端的情況是完全手寫 Agent 循環:
def custom_agent_loop(user_input, tools, llm):
messages = [{"role": "user", "content": user_input}]
for iteration in range(10):
# You have to manually do everything!
if len(messages) > 20:
messages = summarize_history(messages) # Clean up old messages
available_tools = select_tools(messages, tools) # Pick which tools to use
system_prompt = generate_prompt(iteration) # Create instructions
response = llm.invoke(messages, tools=available_tools)
# And more manual work...這種實現方式的問題很明顯:
代碼可讀性差,維護成本高。不同項目之間的實現各不相同,無法複用。新增功能需要大量重構,擴展性很受限。
中間件機制帶來的改變
v1.0 的中間件設計借鑑了成熟的軟件工程實踐,把功能模塊化,然後通過組合來實現複雜邏輯。
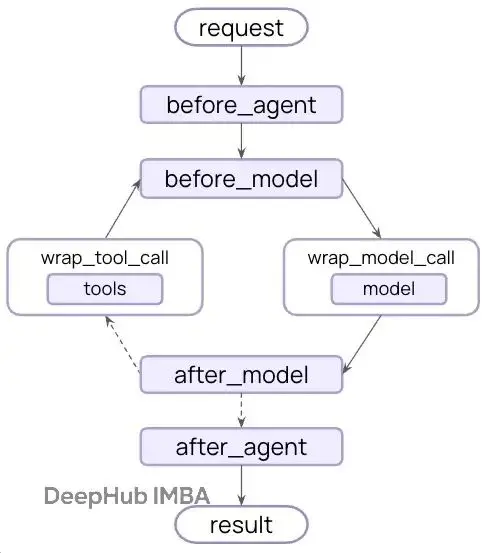
中間件可以在 Agent 執行流程的不同階段介入:
before_model在模型調用前執行,通常用於輸入預處理,比如文本清洗或格式標準化。
wrap_model_call包裹模型調用過程,可以修改傳遞給模型的參數,比如動態調整可用工具列表。
wrap_tool_call攔截工具調用,實現權限控制或者參數驗證。
after_model在模型返回後執行,用於輸出驗證或者安全檢查。
LangChain v1.0 提供了一些常用的中間件實現,開箱即用。
create_agent函數的設計就是圍繞中間件展開的,這是個很重要的架構決策。
from langchain.agents import create_agent
from langchain.agents.middleware import (
PIIMiddleware,
SummarizationMiddleware,
HumanInTheLoopMiddleware
)
agent = create_agent(
model="claude-sonnet-4-5-20250929",
tools=[read_email, send_email],
middleware=[
# Hide email addresses automatically (privacy protection)
PIIMiddleware("email", strategy="redact"),
# Block phone numbers completely (extra privacy)
PIIMiddleware("phone_number", strategy="block"),
# When conversation gets long, make a short summary
# (like creating a highlight reel of a long movie)
SummarizationMiddleware(
model="claude-sonnet-4-5-20250929",
max_tokens_before_summary=500
),
# Before sending emails, ask a human "Is this okay?"
# (like a safety check before hitting send)
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "edit", "reject"]
}
}
),
]
)這段代碼實現了幾個關鍵功能:
PIIMiddleware 處理個人敏感信息,郵箱地址會被脱敏處理,電話號碼直接阻斷,確保隱私數據不會泄露給模型。
SummarizationMiddleware 解決長對話的上下文管理問題。Token 數超過閾值後自動生成摘要,保持上下文簡潔的同時不丟失關鍵信息。
HumanInTheLoopMiddleware 在關鍵操作前加入人工審核。比如發送郵件這種操作,必須經過人類批准才能執行。
每個中間件負責一個具體的功能,想添加新能力直接往列表里加就行,代碼結構很清晰。
除了這幾個以外,v1.0 還提供了其他常用中間件:
Token 統計和預算控制、響應緩存機制、錯誤處理和重試邏輯、自定義日誌記錄等等。
官方的文檔文檔寫得比較詳細,查起來也方便。
自定義中間件的實現
內置中間件覆蓋了常見場景,但真正體現靈活性的是自定義中間件的能力。
我們舉個例子,假設需要根據用户的技術水平動態調整 Agent 的能力:
from dataclasses import dataclass
from typing import Callable
from langchain_openai import ChatOpenAI
from langchain.agents.middleware import AgentMiddleware, ModelRequest
from langchain.agents.middleware.types import ModelResponse
# First, define what you want to track about users
@dataclass
class Context:
user_expertise: str = "beginner" # Is user a beginner or expert?
# Create your custom middleware
class ExpertiseBasedToolMiddleware(AgentMiddleware):
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
# Check: Is this user a beginner or expert?
user_level = request.runtime.context.user_expertise
if user_level == "expert":
# Experts get powerful AI and advanced tools
model = ChatOpenAI(model="gpt-5")
tools = [advanced_search, data_analysis]
else:
# Beginners get simpler AI and basic tools
model = ChatOpenAI(model="gpt-5-nano")
tools = [simple_search, basic_calculator]
# Update what the AI sees
request.model = model
request.tools = tools
# Send it forward to the AI
return handler(request)
# Now use your custom middleware (just like the built-in ones!)
agent = create_agent(
model="claude-sonnet-4-5-20250929",
tools=[simple_search, advanced_search, basic_calculator, data_analysis],
middleware=[ExpertiseBasedToolMiddleware()], # Your custom middleware here!
context_schema=Context
)這個中間件實現了能力分級:
先從運行時上下文讀取用户的技術水平標識。
如果是專家用户,分配更強的模型(gpt-5)和高級工具(advanced_search、data_analysis)。如果是初學者,使用輕量模型(gpt-5-nano)和基礎工具(simple_search、basic_calculator)。
每次模型調用前這個邏輯都會自動執行,根據用户身份動態調整 Agent 配置。
這種模式類似遊戲的難度調節——新手和老手面對的是不同的遊戲環境,但切換過程是無感的。只不過這裏調整的不是遊戲難度,而是 AI 的能力邊界和可用資源。
中間件架構優勢
中間件系統提供了多個介入點,覆蓋 Agent 執行的全流程:

帶來的改進是系統性的:
代碼組織更規範。每個中間件都是獨立模塊,功能邊界清晰,不會出現邏輯耦合的問題。
複用性大幅提升。寫好的中間件可以在不同項目間共享,不用每次都重新實現。
組合靈活性很高。像搭積木一樣組合不同的中間件,快速實現複雜功能。
測試和調試簡化了。每個中間件可以單獨測試,出問題也容易定位。
生產環境的適配性更好。常見的生產需求都有對應的模式,不需要從零開始摸索。
總結
v1.0 之前,上下文控制基本靠手寫代碼,沒有統一的抽象層。中間件機制把上下文工程變成了系統化的工程實踐。無論是使用現成的中間件處理通用場景,還是開發自定義中間件滿足特定需求,這套機制都提供了足夠的靈活性和控制力。這對構建可靠的生產級 Agent 來説很關鍵。
create_agent以中間件為核心的設計不只是功能上的補充,更像是對 Agent 構建範式的重新定義——把上下文工程提升到和模型選擇、工具設計同等重要的位置。
https://avoid.overfit.cn/post/40815da9448149ce802430565a0765d3
作者:Aayushmaan Hooda


