









LLM的強化學習訓練最近進展很快,SOTA模型在各種推理benchmark上的表現確實亮眼。但更值得關注的其實是另一條信息——從Rutgers到Alibaba再到HKUST,這些研究團隊正在攻克的是RL領域的一個老大難:怎麼控制好熵,同時避免模型退化成毫無用處的確定性輸出。
三篇新論文給出了不同角度的解法:CE-GPPO、EPO和AsyPPO。雖然切入點各有不同,但合在一起就能發現它們正在重塑大規模推理模型的訓練方法論。下面詳細説説這三個工作到底做了什麼。
標準PPO在熵控制上的失效
先説policy entropy這個概念。熵衡量模型輸出的隨機性或者説多樣性程度——高熵對應探索不同解法,低熵則是鎖定單一策略。經典PPO算法的做法很簡單:importance sampling ratio超出(1−ε, 1+ε)範圍就直接clip掉。
這樣的話問題出在哪?PPO的clipping會把低概率token的梯度信息扔掉,而這些token在推理任務裏恰恰很關鍵。比如讓模型做AIME 2025的題目,或者讓它完成一個30輪的科學實驗,那些探索性的、概率不高的路徑往往藏着突破口。標準PPO的策略感覺這個路徑"太冒險了,clip掉算了",結果就是:
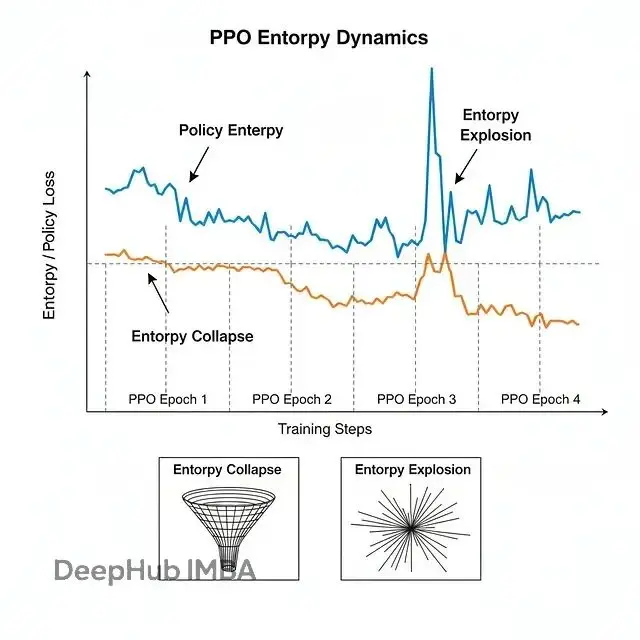
熵坍縮:模型太快變成確定性的,卡在平庸策略上出不來;熵爆炸:模型亂探索,根本收斂不了
具體例子就是在ScienceWorld這種多步驟、稀疏reward的環境裏跑一下原版PPO就知道了,entropy會劇烈震盪,模型啥也學不到。
CE-GPPO:有界梯度恢復機制
快手提出的CE-GPPO(Controlling Entropy via Gradient-Preserving Policy Optimization)核心思路是用有界的方式把被clip掉的梯度拿回來。
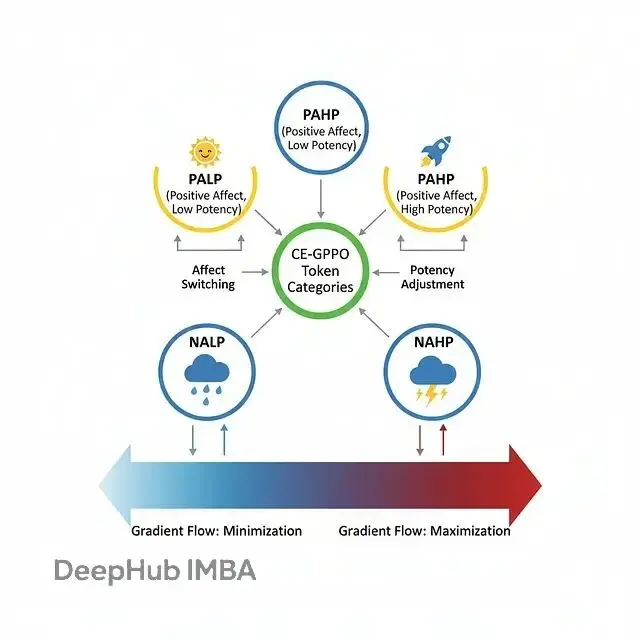
Token的四類劃分
CE-GPPO按概率和advantage把token分成四類:
- PAHP (Positive Advantage, High Probability):模型喜歡的、該強化的token
- NALP (Negative Advantage, Low Probability):差的探索token,要抑制
- PALP (Positive Advantage, Low Probability):好的探索token,這是論文説的金子
- NAHP (Negative Advantage, High Probability):高概率但該減少的token
標準PPO直接clip掉PALP和NALP,這樣梯度信號全丟了,而CE-GPPO用係數α₁和α₂把它們重新引入:
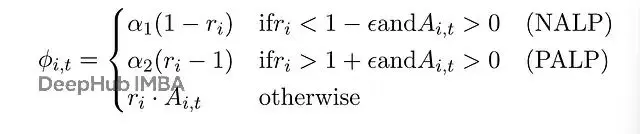
stop-gradient操作允許獨立調節α₁(exploitation強度)和α₂(exploration強度)。設α₁=0、α₂=1就退化成DAPO的clip-higher trick,但CE-GPPO的框架靈活得多。
實驗結果:在DeepSeek-R1-Distill-Qwen-7B上測試,CE-GPPO在AIME24達到66.0(DAPO是59.7),AIME25拿到51.4(DAPO是48.7)。最優配置是α₁=0.75、α₂=1,這個設置鼓勵PALP token的探索,同時温和約束NALP token避免過度探索。
為什麼work
理論依據:CE-GPPO的梯度幅度被bounded在α₁(1−ε)或α₂(1+ε)範圍內,trust region不會被破壞。但關鍵是從那些有信息價值的token裏恢復了signal。
訓練曲線的數據很説明問題,CE-GPPO的entropy保持得相當穩,不像GRPO那樣先暴跌再爆炸。
EPO:針對多輪交互的時序平滑
EPO(Entropy-regularized Policy Optimization)是Rutgers和Adobe的工作,針對的場景完全不同,它主要研究的是那種需要30多步action才能拿到success/fail信號的多輪交互環境。
級聯失效的兩個階段
EPO發現了所謂的exploration-exploitation cascade failure,分兩個phase:
Phase 1(步驟0-40):稀疏reward導致早期過度探索。agent亂試一通,養成一堆壞習慣
Phase 2(步驟40+):早期的混亂會propagate到後續步驟。entropy一直很高,agent持續震盪,根本形成不了連貫策略
根本原因是傳統entropy regularization對時序不敏感,每個timestep都是單獨處理的。但在多輪任務裏,早期選擇會cascade影響整條trajectory的結果。
EPO的方案:歷史熵錨定
EPO的核心創新是entropy smoothing regularizer。不是簡單加個loss項,而是維護一個歷史窗口,記錄過去訓練步驟的平均entropy。smoothing loss會懲罰偏離:
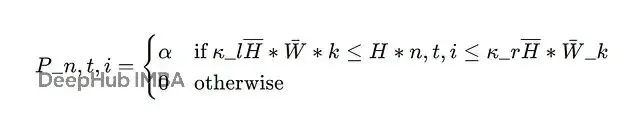
這樣就給entropy加了"護欄",通常設κl=0.8、κr=1.2,不會讓它跑偏太遠。完整loss是:
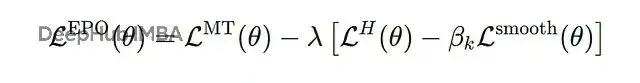
動態係數β_k按指數schedule變化,早期訓練時較小(温和平滑),後期逐漸增大(強力穩定)。這直接對抗兩階段級聯失敗。
實驗結果:ScienceWorld上,PPO+EPO比vanilla PPO提升152.1%(96.8 vs 38.4平均成功率)。ALFWorld上GRPO+EPO有19.8%提升,穩定性很好。
一個反理論的發現
流行的entropy decay schedule在多輪環境裏不管用。大家都被教育要"早期探索、後期利用",但EPO的實驗數據表明,對於稀疏reward的agent來説這策略有問題。episode內部過早exploit會鎖定糟糕的初始action,錯誤會波及整個run。正確做法是在trajectory所有步驟保持穩定的exploration pressure,再配合一點smoothing。
AsyPPO:小規模critic集成方案
HKUST、Mila和Alibaba合作的AsyPPO(Asymmetric Proximal Policy Optimization)解決的是另一個問題:讓critic在LLM規模的RL訓練裏重新變得可用。
小模型能指導大模型嗎
經典PPO用對稱actor-critic架構:actor 14B參數,critic也是14B。GRPO這類新方法乾脆扔掉critic,改用group-average baseline。雖然work但丟失了proper value estimation帶來的穩定性和bias reduction。
AsyPPO提出了一個問題:1.7B或4B的小critic能不能guide 14B的大actor?然後給出了答案:可以,但前提是方法得對。
集成策略
單個小critic不行,value estimate太noisy。AsyPPO用兩個小critic,在disjoint的prompt-level數據分片上訓練。每個問題的rollout responses一半給Critic 1,一半給Critic 2。這保證:
多樣性:從不同response distribution學習
同步性:看到相同prompts,保持calibration
corrected advantage用兩個critic的value estimate平均值:
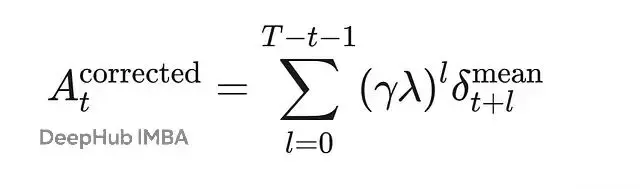
這裏δ_t^mean來自V₁和V₂的均值,比單個critic的bias要小。
基於不確定性的門控
AsyPPO把inter-critic disagreement當signal用。每個state算critic之間value的標準差,然後:
Advantage Masking:σ_t很低的state(critic強烈一致),mask掉advantage。這些是boring的、over-visited的state,沒有學習信號,不值得花梯度更新
Entropy Filtering:σ_t很高的state(critic強烈disagree),從entropy regularization裏filter掉。這些是ambiguous或noisy的state(比如filler token "umm"、"well"),exploration沒意義
loss變成:
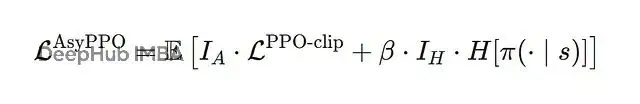
I_A mask低σ state,I_H從entropy裏filter高σ state。
實驗結果:AsyPPO在math benchmarks(AIME24/25、MATH-500等)上比GRPO提升約3%,內存佔用比對稱PPO少20%。最優配置是兩個4B critic guide一個14B actor。更多critic有幫助但兩個就夠拿到主要收益了。
非對稱架構為什麼現在可行
上面幾個方法的關鍵點是pretrained LLM有豐富的representational prior。哪怕1.7B的預訓練模型,也有足夠world knowledge去evaluate 14B actor的behavior。這在經典RL(Atari、MuJoCo)裏不成立,因為那些agent都是從零開始學,所以可以非對稱actor-critic setup是LLM時代獨有的可行方案。
三者的統一視角
這三篇論文其實構成了一個coherent narrative:
CE-GPPO:恢復被clip token的梯度,在單個訓練步內控制entropy,平衡PALP(exploration)和NALP(exploitation)
EPO:用歷史平滑在訓練步之間控制entropy,防止多輪場景的cascade failure
AsyPPO:用小型ensemble高效恢復critic,再利用critic uncertainty做learning signal的門控(mask boring state、從entropy裏filter noisy state)
後續方向
下一步應該可以把這些方法組合起來。比如:
在AsyPPO的uncertainty-filtered updates裏用CE-GPPO的α₁、α₂調節
把EPO的歷史平滑應用到CE-GPPO的gradient-preserved entropy上
把AsyPPO的critic ensembles擴展到多輪agent場景,配合EPO的trajectory-aware loss
三種方法都在解決同一個核心問題:更聰明地判斷何時、如何讓模型exploration vs exploitation。只是角度不同——gradient(CE-GPPO)、時序(EPO)、critic uncertainty(AsyPPO)。這些細節上的差異,決定了模型是停在平庸水平,還是能真正crack掉AIME難題或者reliable地控制機器人。
https://avoid.overfit.cn/post/f7fe0bdff36c4c7a906c9ee678df11a4
作者:Aditya Dubey



