









核心概覽
我們很高興宣佈開源項目 AutoMQ v1.6.0 版本正式發佈。該版本為開發者帶來三大核心優化:
- 成本效益提升最高達 17 倍:通過對寫入路徑的深度優化,在高吞吐負載場景下,AutoMQ 的總擁有成本(TCO)較自管理 Apache Kafka 降低最高 17 倍。
- Table Topic 功能增強:原生支持 CDC 流,並提供更靈活的 Schema 管理能力,簡化數據湖寫入流程,無需額外部署 ETL 任務或強制依賴 Schema Registry。
- 完全兼容 Strimzi Operator:可與 Strimzi Operator 無縫集成,讓你能通過熟悉的工具在 Kubernetes 上管理 AutoMQ,實現快速擴縮容且無需進行數據重平衡。
如需查看 v1.6.0 版本的完整更新內容,請參閲完整發布説明(https://github.com/AutoMQ/automq/releases?utm\_source=wechat\_v160)。

01
AutoMQ:基於 S3 重構的 Diskless Kafka
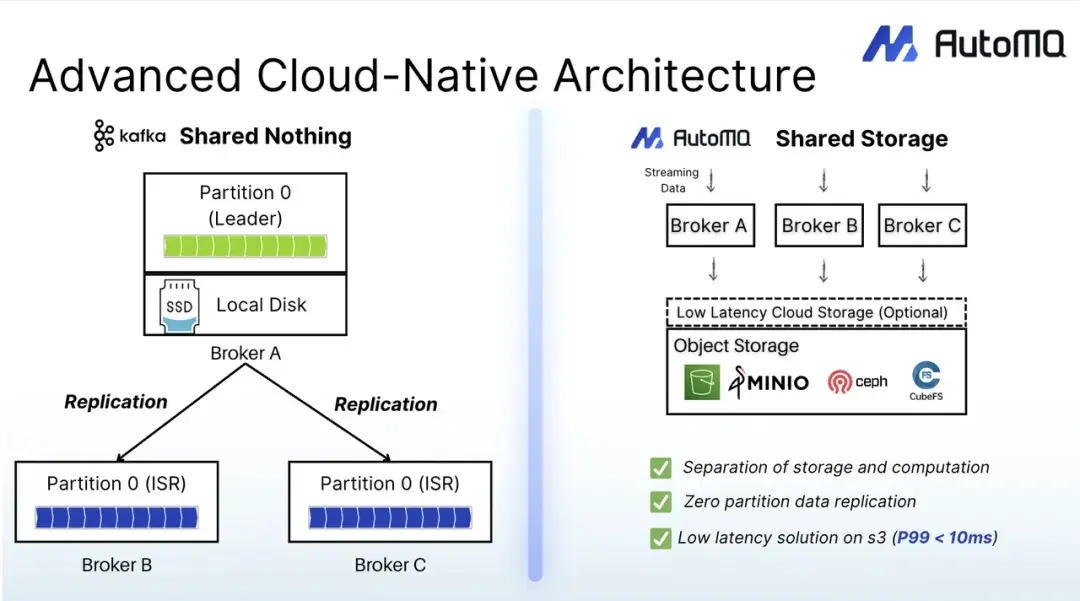
在深入介紹 1.6.0 版本細節前,我們先為剛接觸該項目的用户簡要回顧 AutoMQ 的核心架構及旨在解決的問題。所有大規模管理過 Kafka 的工程師都清楚其運維痛點:流量峯值需要更多資源支撐,但擴容操作會觸發數小時的分區重平衡 —— 這一過程風險高、資源消耗大,且會將計算與存儲綁定在固定流程中。這一問題源於 Kafka 原生為本地部署設計的 “無共享”(shared-nothing)架構,是其在雲環境中運行時的固有侷限。
AutoMQ 通過對 Kafka 進行雲原生重構,從根本上解決了這一痛點。我們的設計始於一個簡單的問題:如果 Broker 不依賴磁盤會怎樣?通過解耦計算與存儲,並構建直接將數據流式傳輸到 S3 或兼容對象存儲的全新存儲層,AutoMQ 直面並解決了 Kafka 在雲環境中的核心挑戰:
真正的彈性擴展:Broker 變得輕量且無狀態。夜間擴容不再是令人頭疼的數據遷移任務,只需啓動新 Pod,幾秒鐘即可完成。
成本大幅降低:無需昂貴且過度配置的塊存儲(如 EBS),通過 S3 的按量付費模式及區域終端節點,顯著降低跨可用區(AZ)數據複製成本。
雲原生數據持久性:單個可用區故障不再造成嚴重影響。將數據持久化任務轉移到雲存儲後,數據的 “可信源” 始終安全,且無需承擔管理多副本 ISR 機制的運維開銷。
這種 “Diskless” 架構是 AutoMQ 在雲環境中具備更高彈性、成本效益和可靠性的基礎,也是本次 v1.6.0 版本實現強大成本優化與功能增強的技術基石。
02
超越 Kafka:AutoMQ 實現 17 倍成本降低
在雲環境中大規模運行 Kafka 的成本往往高得驚人,這是許多團隊的共同痛點。想象一下,如果既能保留你熟悉的 Kafka API,又能大幅降低總擁有成本(TCO),會怎麼樣?我們針對 v1.6.0 版本的最新基準測試,就展示了 AutoMQ 如何實現這一目標。
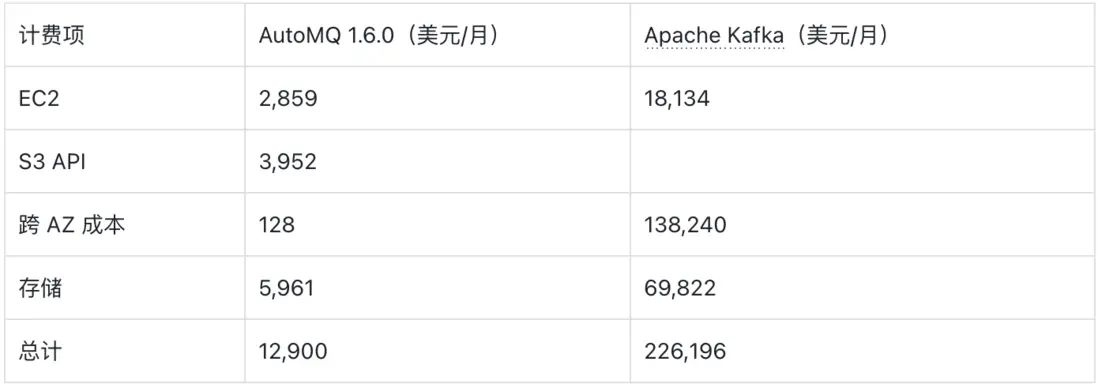
核心結論:在 1 GB/s 吞吐、跨 3 個可用區的負載場景下,AutoMQ 1.6.0 版本月均成本約為 12,900 美元;而配置相當的自管理 Apache Kafka 集羣,月均成本約為 226,196 美元。成本降低幅度達 17.5 倍,主要得益於跨 AZ 數據傳輸成本的大幅削減。
下面我們將拆解成本降低的具體原因。
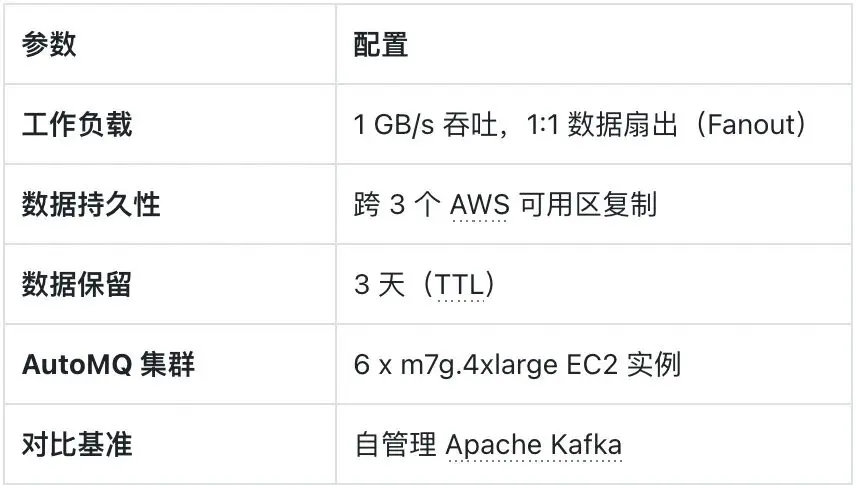
2.1 基準測試配置
透明度是基準測試的核心原則。我們使用開源基準測試工具模擬常見的高吞吐流處理負載,目標是對比 “完全高可用、跨多可用區部署的 AutoMQ” 與 “傳統自管理 Apache Kafka” 在 AWS 環境中的成本差異。
2.2 17 倍成本降低的原因解析
成本節省並非偶然,而是通過從根本上改變 Kafka 存儲層與雲基礎設施的交互方式實現的。用 “直接寫入 S3 的存儲引擎” 替代本地磁盤後,計算與存儲得以解耦,進而釋放巨大的效率提升空間。

成本節省主要來自以下三個方面:
- 跨 AZ 網絡(節省 1080 倍):這是最關鍵的突破點。傳統 Kafka 集羣通過將每條消息從 Leader Broker 複製到其他 AZ 的 Follower Broker 來實現數據備份,在 1 GB/s 吞吐、3 副本配置的場景下,會產生海量且昂貴的跨 AZ 流量(月均約 13.8 萬美元)。而 AutoMQ 直接將數據寫入 S3,僅需跨 AZ 傳輸少量元數據和熱數據,僅此一項優化就將月均跨 AZ 網絡成本從 138,240 美元降至 128 美元。
- 計算資源(節省 6.3 倍):Apache Kafka 依賴本地存儲,導致計算與存儲強耦合。雲服務商對本地磁盤容量有限制(例如 AWS 限制單實例本地磁盤最大容量為 16TB),而 Kafka 需存儲大量數據及冗餘的分區副本,因此必須使用更多計算實例,造成計算資源浪費。AutoMQ 解耦計算與存儲,支持二者獨立擴縮容,徹底解決了這一問題。
- 存儲資源(節省 7 倍):Apache Kafka 需要使用昂貴的預配置塊存儲(如 EBS),且需按峯值容量進行配置;而 AutoMQ 藉助 S3 按量付費模式的彈性與成本優勢,僅需為實際存儲的數據付費,避免了過度配置造成的浪費。
2.3 性能表現
性能是吞吐、延遲與成本三者的平衡。在本次 1 GB/s 吞吐的基準測試中,AutoMQ 1.6.0 版本的生產端 P99 延遲約為 823ms。
當然,我們也意識到不同負載的需求存在差異。對於有嚴格低延遲要求的應用,AutoMQ 企業版提供靈活選項:可將區域級 EBS 或 FSx 作為 WAL(預寫日誌)存儲後端。這種配置能實現 “兩全其美” 的效果:生產端 P99 延遲低於 10ms,同時仍可藉助 S3 實現低成本的長期數據存儲。
更多關於我們如何平衡成本與延遲的探討,請參見官網博客《深度剖析基於 S3 構建 Kafka 的挑戰》(原文鏈接:https://www.automq.com/blog/deep-dive-into-the-challenges-of-...#latency?utm\_source=wanshao\_oponsource\_blog)。
03
從 Kafka Topic 到 Iceberg 表:實現零 ETL 數據傳輸
實時分析需求正推動數據架構不斷演進。傳統的 “批量 ETL 管道”(將數據從 Kafka 傳輸到數據湖)正逐漸被更直接的 “流寫入模式” 取代。這種轉變雖能降低延遲與運維開銷,但構建和維護這類自定義管道仍面臨巨大挑戰。
對開發者而言,核心需求往往很明確:將 Kafka 中的事件流導入 Apache Iceberg 等數據湖,以便開展實時分析。但實際操作過程卻複雜得多:你需要先部署獨立的 ETL 系統(如 Flink、Spark 或 Kafka Connect),相當於為了將數據從第一個分佈式系統導出,不得不管理第二個分佈式系統 —— 這不僅會增加運維負擔、引入新的故障點,還會額外產生成本。
更棘手的是管道的長期維護:微服務團隊在 Protobuf Schema 中新增一個字段,你的 Flink 任務就可能崩潰,此時需要協調服務、ETL 任務與 Iceberg 表 Schema 的多步驟部署,同時還要擔心數據丟失;又如使用 Debezium 同步數據庫變更時,Kafka Topic 中會充斥複雜的 CDC 事件信封,你需要編寫並維護有狀態邏輯,才能正確解析 “變更前 / 後” 的數據、將操作碼(op code)轉換為 Iceberg 表的 INSERT/UPDATE/DELETE 操作。每新增一個數據源或數據格式,都要重複這套流程,最終構建出脆弱且冗餘的管道。
這種額外的負擔被稱為 “ETL 税”,也是我們開發 AutoMQ Table Topic 的初衷。它並非又一個工具,而是對 “流數據到數據湖” 流程的根本性重構。Table Topic 是一種特殊的 Topic 類型,可作為 Kafka Broker 原生的零 ETL 橋樑,將數據無縫流式傳輸到 Apache Iceberg。其目標是通過簡化操作、自動化 Schema 演進、提供端到端可靠性(無需依賴外部系統),徹底消除 “ETL 税”。

在 AutoMQ 1.6.0 版本中,我們重新設計了 Table Topic 的底層引擎,專門解決上述實際場景中的複雜問題。舊版設計雖能運行,但隨着用户規模擴大,我們也遇到了大家面臨的共性問題:某團隊將 Protobuf Schema 直接管理在應用的 Git 倉庫中,不願承擔 Schema Registry 的運維成本,而舊版實現無法支持這種場景;另一團隊使用 Debezium 時發現,Table Topic 雖能將原始變更日誌事件寫入 Iceberg,但無法理解其語義 —— 例如 UPDATE 操作僅被視為一條普通數據行,而非真正的更新操作。
1.6.0 版本通過架構升級解決了這些問題:
- 引入通用的數據接入層:打破傳統限制,將原始 Kafka 消息字節智能轉換為結構化、標準化的內部格式。通過採用與數據湖生態深度兼容、且支持 Schema 無縫演進的格式,徹底擺脱對固定 Schema Registry 的依賴。無論你是直接導入 Protobuf 的 .proto 文件,還是處理無 Schema 的 JSON 數據,都能得到支持。
- 基於標準化數據的內容感知處理:在標準化數據基礎上,實現智能的內容感知處理,解鎖高級數據湖能力。以 Debezium 場景為例:系統現在能原生理解並處理 Debezium CDC 流,只需極少配置,就能自動解析 CDC 事件信封、精準提取實際業務數據(從 “變更前” 或 “變更後” 字段中)、正確識別操作類型(創建 / 更新 / 刪除)。這使得 Table Topic 能直接對 Iceberg 表執行真正的 Upsert(更新插入)和 Delete 操作,最終讓 CDC 流成為數據湖中的 “一等公民”。此外,我們還優化了從 Avro 到 Iceberg 的最終數據綁定步驟,顯著提升了整體寫入性能。
這種新架構將 Table Topic 從簡單的數據傳輸工具,升級為智能的內容感知寫入引擎。如今,你無需編寫任何 ETL 代碼,就能構建端到端的 CDC 管道,或流式傳輸由應用管理的 Protobuf 事件。對於構建實時數據湖的開發者而言,這終於實現了 “專注於數據本身,而非數據傳輸工具” 的目標。
這些增強的功能讓 Table Topic 成為構建實時數據湖的更優解,可支撐多種場景,從實時交易明細表到近實時分析儀表盤均適用。
04
100% 兼容 Kafka:與 Strimzi 無縫集成

試想這樣的場景:凌晨 3 點,流量峯值迫使你在 Kubernetes 上擴容 Kafka Broker。這本該是自動化的常規操作,但你卻面臨艱難抉擇 —— 擴容會觸發數小時的數據重平衡,引發大量網絡流量與 I/O 負載,進而威脅集羣穩定性。這並非 Kubernetes 的問題,而是傳統 Kafka 並非真正 “Kubernetes 原生” 的體現:Kubernetes 擅長管理臨時、無狀態的工作負載,以實現快速擴縮容與自愈;而 Kafka 計算與存儲強耦合的架構,與這些特性根本相悖。這種矛盾導致你始終無法充分發揮 Kubernetes 帶來的彈性優勢。
社區針對這一運維挑戰的主流解決方案是 Strimzi—— 這款權威的 Operator 工具能自動化 Kafka 管理流程,大幅簡化部署操作,但它無法解決 Kafka 底層的架構侷限:無法消除 “數據引力”(數據對存儲的依賴)導致的擴容風險,因此無法提供真正的 Kubernetes 原生 Kafka 體驗。
AutoMQ 通過 “計算 - 存儲解耦” 的創新架構解決了這一核心問題,但開發者自然會提出關鍵疑問:“既然你們重構了 Kafka 核心,那我們依賴的工具(尤其是 Strimzi)是否還能兼容?”
答案是“可以”。由於我們將 “100% 兼容 Kafka 協議” 作為核心設計原則,你無需放棄信賴的工具:只需在 Strimzi 自定義資源(Custom Resource)中修改容器鏡像引用,就能無縫管理 AutoMQ 集羣。我們很高興地宣佈,從 v1.6.0 版本開始,AutoMQ 已完全兼容 Strimzi Operator,且我們已通過全面測試驗證了其核心功能。
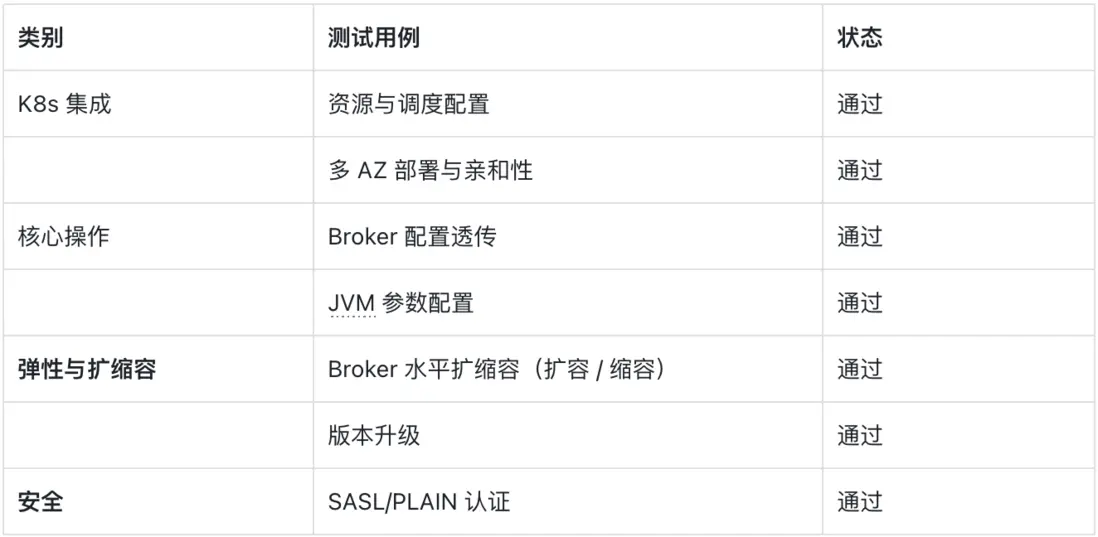
這種無縫集成並非偶然,而是我們設計理念的直接體現:我們認可 Kafka 社區的價值,也相信其生態的強大。通過完全兼容 Kafka 協議,我們確保 AutoMQ 能隨生態演進而同步發展。對 Strimzi 的兼容能力,正是這一承諾的有力證明。
如今,當凌晨 3 點的流量峯值來臨時,你終於可以通過信賴的 Operator 管理 Kafka 集羣,實現 “分鐘級擴縮容”(而非小時級),真正釋放 Kubernetes 對數據流的管理能力。若你想了解實現這一兼容性的技術細節,可閲讀我們的博客文章:《AutoMQ 如何實現 100% Kafka 協議兼容》(原文鏈接:https://www.automq.com/blog/how-automq-makes-apache-kafka-100...\_source=wechat\_v160)。
小貼士:AutoMQ 1.6.0 在保持與 Kafka 完全兼容的同時,新增發佈了基於 Apache Kafka 開源鏡像的版本。該鏡像完全兼容 Apache Kafka 官方 Docker 鏡像的啓動邏輯,支持開箱即用。詳情請參閲此處(https://www.automq.com/docs/automq/deployment/deployment-reco...\_source=wechat\_v160)。
05
立即體驗開源 AutoMQ
AutoMQ 1.6.0 版本帶來了開發者在雲環境中最關注的三大能力:成本大幅降低、數據湖寫入簡化、Kubernetes 上的無摩擦運維。基準測試顯示其 TCO 較 Kafka 降低 17 倍,重構後的 Table Topic 實現 “零 ETL 寫入 Iceberg”,且通過 100% Kafka 兼容能力集成 Strimzi—— 這意味着你無需放棄現有工具與 API,就能充分享受雲環境承諾的彈性優勢。

立即體驗 AutoMQ:https://account.automq.cloud/?utm\_source=wechat\_v160












