
谷歌準備發佈新一代圖像生成與編輯模型“Nano Banana 2”
根據 TestingCatalog 報道,日前 Google Gemini 的網頁界面中,出現了新的更新預告卡片。 據其分析,谷歌正在準備新的圖像生成模型,並且為 Nano Banana 系列。據介紹,該生圖模型將被命名為“GEMPIX2”,並作為 Nano Banana 的二代發佈。 報道分析,預告卡片通常是發佈臨近的信號,根據以往推測,此類更新通常出現於公開發布前一週,意味着該模型或於下週上
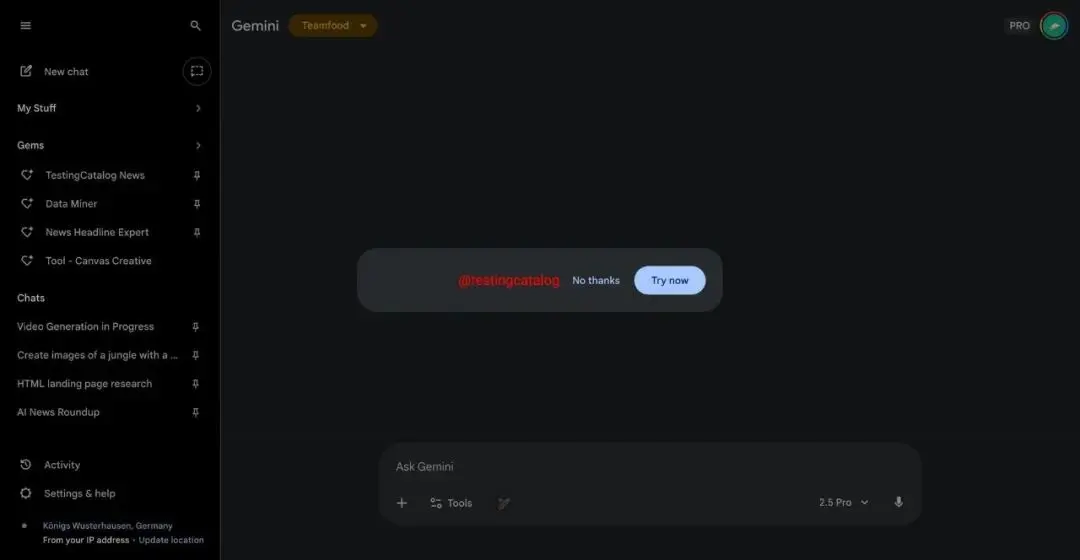
根據 TestingCatalog 報道,日前 Google Gemini 的網頁界面中,出現了新的更新預告卡片。 據其分析,谷歌正在準備新的圖像生成模型,並且為 Nano Banana 系列。據介紹,該生圖模型將被命名為“GEMPIX2”,並作為 Nano Banana 的二代發佈。 報道分析,預告卡片通常是發佈臨近的信號,根據以往推測,此類更新通常出現於公開發布前一週,意味着該模型或於下週上
在項目推進的每個環節中,從任務規劃、開發協同到測試執行,Gitee 都在不斷打磨產品細節,降低認知成本、提高使用效率。 本次 Gitee 企業版更新,圍繞工作項、測試管理、安全設置等多個模塊,上線了 5 項關鍵能力升級,覆蓋流程鏈路優化、視圖交互統一、數據導入導出、權限配置增強等典型場景,幫助團隊構建更高效、更一致的協作環境。 工作項拓撲圖 在多人協作與複雜項目中,工作項之間的依賴關係往往錯綜複

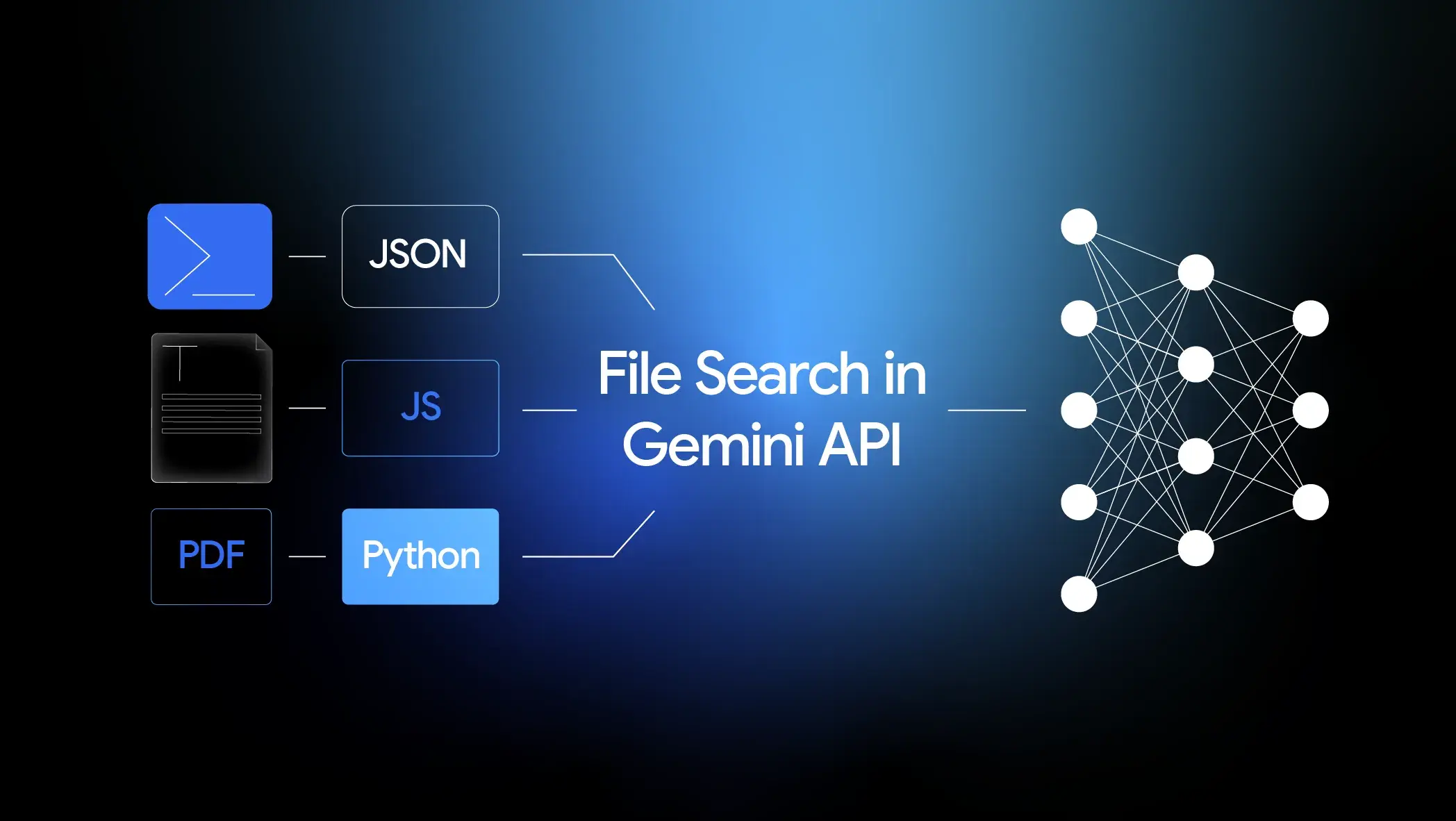
谷歌宣佈在Gemini API中推出File Search Tool(文件搜索系統)。這是一個完全託管的檢索增強生成(RAG)解決方案,旨在為開發者提供一個簡單、集成且可擴展的方式,使用自己的數據來“錨定”Gemini模型。 通過該工具,開發者可以上傳文件,系統會自動進行分塊、索引和檢索,從而讓Gemini模型能夠基於用户提供的私有文件內容生成更準確、更具上下文的回覆。 使用示例 from
世界互聯網大會發布了《全球人工智能標準發展報告》(以下簡稱《報告》),全景梳理過去一年AI標準化最新進展。 《全球人工智能標準發展報告》是世界互聯網大會人工智能專業委員會標準推進計劃2025年的一項重要成果。該報告立足全球人工智能標準化全景,系統分析國際標準組織和主要經濟體標準化行動,研判標準加快提速、互操作性與負責任的發展態勢,剖析技術迭代超前、產業鏈條複雜、治理理念差異、南方國家缺位等挑戰

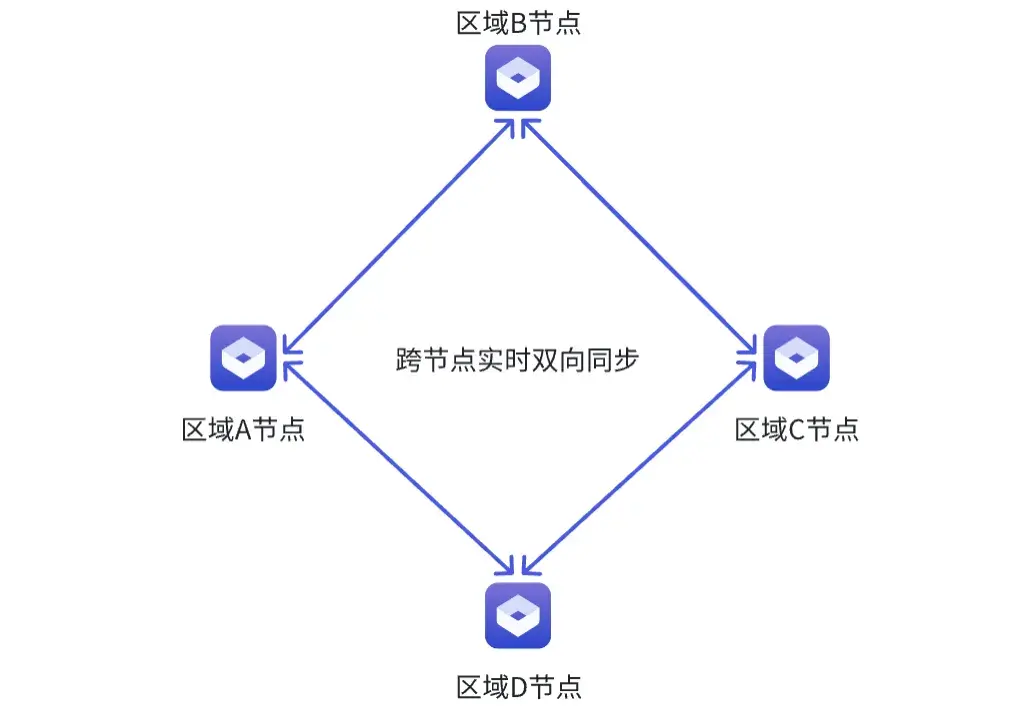
在數字化研發與生產中,團隊分佈在不同地區,團隊間往往會共同協作,開發、測試到最終交付製品的軟件研發流程中,經常需要把製品向不同地區的團隊流轉。 我們希望讓不同地域、不同團隊的開發、測試流程更順暢,製品交付更高效,但這也帶來了新問題:怎麼讓製品在向不同地區同步時,既夠快(實時)、又沒遺漏(完整),還能清楚看到同步的情況(過程監控)呢? Gitee Repo 聯邦倉庫完美解決這些問題,聯邦倉庫作為新型
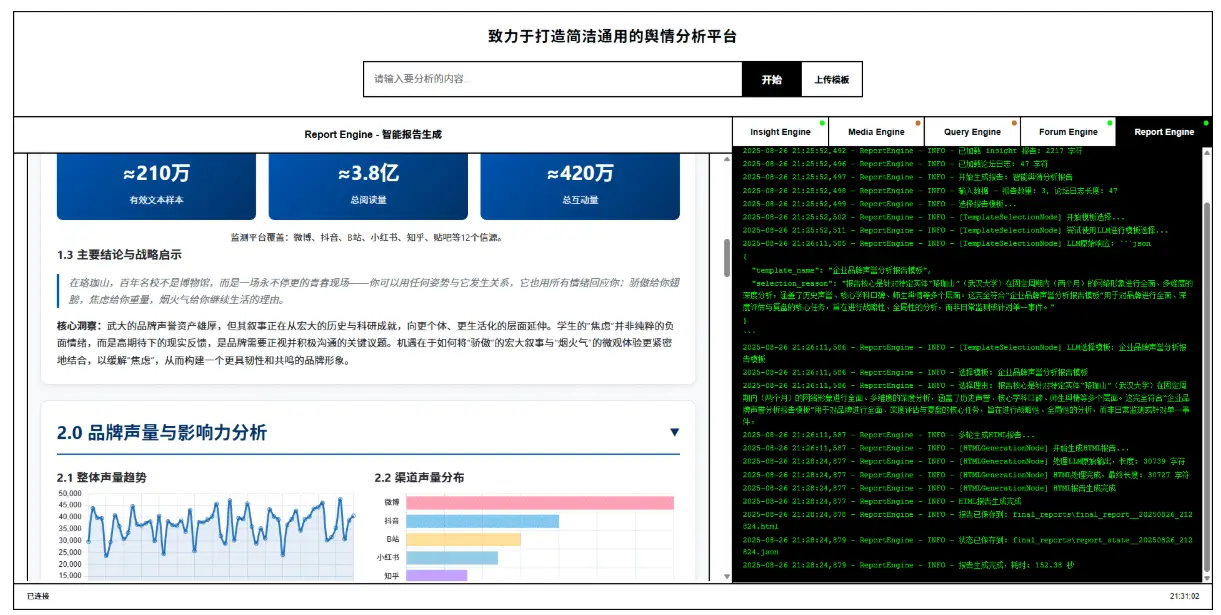
“微輿” 是一個從0實現的創新型 多智能體 輿情分析系統,幫助大家破除信息繭房,還原輿情原貌,預測未來走向,輔助決策。用户只需像聊天一樣提出分析需求,智能體開始全自動分析 國內外30+主流社媒 與 數百萬條大眾評論。 “微輿”諧音“微魚”,BettaFish是一種體型很小但非常好鬥、漂亮的魚,它象徵着“小而強大,不畏挑戰” 查看系統以“武漢大學輿情”為例,生成的研究報告:武漢大學品牌聲譽深度
Firecrawl 推出了一款頗具創新性的工具 ——Branding Format API。這項全新的 API 功能可以幫助用户從任何網站中一次性提取其完整的品牌 DNA。用户只需輸入目標網站的 URL,即可自動識別並提取該網站的各項品牌要素。 這個工具特別適合那些希望迅速瞭解或模仿某一品牌視覺風格的設計師或創業者。通過 Branding Format API,用户能夠獲得包括配色方案、標誌與
11 月 7 日,2025 年世界互聯網大會烏鎮峯會開幕。阿里巴巴 CEO 吳泳銘在開幕式上致辭,他明確表示,阿里巴巴正在建設超大規模 AI 基礎設施,加大投入打造超級 AI 雲,將憑藉全棧技術積累向全球開發者提供領先的 AI 服務。 這一佈局並非短期規劃,此前在 2025 雲棲大會上他曾披露,阿里正推進 3800 億元規模的 AI 基礎設施建設,並計劃追加更大投入;作為遠期目標,到 2032 年

2025年11月6日,中國領先的開源軟件公司飛致雲宣佈,其旗下新一代的開源AI CRM系統Cordys CRM正式代碼開源。 Cordys CRM(github.com/1Panel-dev/CordysCRM)是新一代的開源AI CRM系統,是集信息化、數字化、智能化於一體的客户關係管理系統。Cordys(/ˈkɔːrdɪs/)一詞由“Cord”(連接之繩)與“System”(系統)融合而成,寓

2025年世界互聯網大會領先科技獎頒獎典禮11月6日在浙江烏鎮舉行。17個具有國際代表性的項目獲獎,涵蓋大模型、智聯網、具身智能、量子計算等前沿領域。 據介紹,“領先科技獎”是2023年設立的面向互聯網領域的國際性科技獎項,以“引領科技前沿創新、倡導技術交流合作”為宗旨,涵蓋基礎研究、關鍵技術、工程研發三類成果。該獎項由2016年啓動的“世界互聯網領先成果發佈活動”全面升級而來,至今已連續10年面

隨着大模型技術進入規模化落地階段,開發者面臨多模態融合、多智能體協同、企業級部署等複雜挑戰。傳統開發框架(如 LangChain、LlamaIndex)雖提供基礎工具鏈,但代碼冗餘、部署繁瑣、適配成本高等問題制約了創新效率。 為此,商湯大裝置推出開源低代碼框架 LazyLLM,通過模塊化設計、數據流驅動和一鍵式部署,徹底重構 AI 應用開發路徑,讓開發者僅需 10 行代碼即可實現工業級 RAG 系

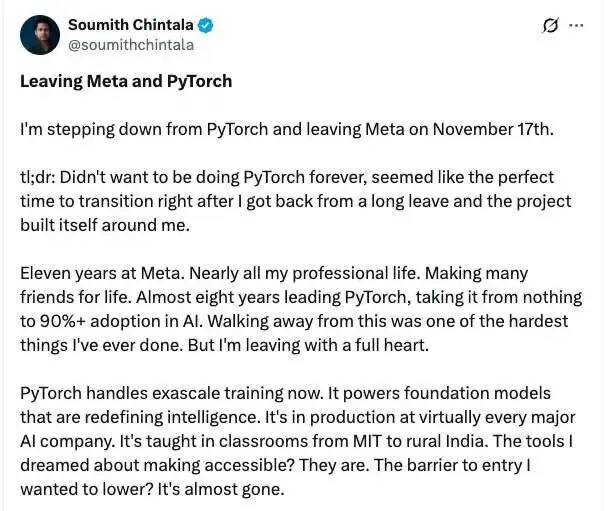
PyTorch 創始人 Soumith Chintala宣佈將於 11 月 17 日正式離開 Meta。 他在宣佈離職的一篇長文中表示,不想一輩子都做 PyTorch,希望重新開始做一些小而未知的事情,探索 Meta 之外的世界。 他在 Meta 工作了 11 年,近 8 年領導 PyTorch 項目,將其從一個幾乎無人知曉的實驗室項目發展成為全球 AI 領域廣泛使用的主流框架,目前在 AI 領
Java虛擬機運行數據區域 在JDK 8及以上版本中,Java虛擬機運行時數據區域主要包括以下部分: 1)堆(Heap):這是Java虛擬機中最大的內存區域,所有線程共享,主要用於存放對象實例和數組。這也是垃圾回收的主要區域,因此也被稱作GC堆(Garbage Collection Heap)。 2)方法區(Method Area):在JDK 8之前,這被稱為永久代(PermGe

昵稱 poemyang
垃圾回收算法的評價標準:吞吐量、延遲、內存,孰輕孰重? 評估和選擇垃圾回收器時,不存在一體通用的最優解。不同的應用場景對性能的要求截然不同,因此需要通過一套標準化的指標來衡量垃圾回收算法的特性。通常,關注三個主要的、且相互制約的評價指標:吞吐量(Throughput)、最大暫停時間(Max Pause Time / Latency)以及堆使用效率(Heap Usage Efficiency)
昵稱 poemyang
G1(Garbage-First)垃圾回收器是一款面向服務端應用、為大內存和多處理器系統設計的革命性垃圾回收器。G1的核心設計目標是在滿足高吞吐量的同時,建立一個“可預測的停頓時間模型”(Pause-Time Model),讓使用者可以明確指定在一個長度為M毫秒的時間片段內,消耗在垃圾回收上的時間大概率不超過N毫秒。這一特性是它與之前回收器(如CMS)最本質的區別。 在JDK 9發佈之後,G
昵稱 poemyang
內存泄漏和內存溢出是Java程序中最常見的兩類內存管理問題。它們都與內存息息相關,但本質、成因和解決方法截然不同。 內存泄漏 內存泄漏指的是程序在向系統申請內存後,由於設計缺陷或編碼錯誤,導致某些已經不再被使用的對象仍然被引用鏈持續持有,從而無法被垃圾回收器識別和回收。這些無用對象會像殭屍一樣永久地佔據內存空間。一次微小的泄漏可能無傷大雅,但如果泄漏持續發生並累積,會逐漸侵佔可用內存,導致垃
昵稱 poemyang
系統設計的複雜性,往往源於其需要應對的外部壓力。對於互聯網應用而言,用户規模的增長和流量的瞬時波動,是其必須面對的常態。一個未經深思熟慮的系統,在流量洪峯面前可能會變得遲緩甚至不可用,直接影響用户體驗與業務目標。 因此,構建一個能夠從容應對壓力的系統架構,便成為一項核心的工程命題。 本文將探討一種行之有效的設計哲學——分層抗壓。剖析其背後的三大技術支柱:緩存、消息中間件與數據庫,並闡述
昵稱 poemyang
引言 你是否遇到過 Rust 併發場景下的資源競爭、性能瓶頸? 當多個線程同時抓取網頁導致 IP 被封、多線程讀寫本地數據引發一致性問題時,如何優雅地實現線程安全? 本文結合開源項目 Saga Reader 的真實開發場景,深度解析 Arc/Mutex/RwLock 的實戰技巧,帶你從 “踩坑” 到 “優化”,掌握 Rust 併發編程的核心方法論,文末附項目地址,歡迎 star 交流!

昵稱 姜 萌@cnblogs
一、背景與目標:為什麼做一個“非典型”的RSS閲讀器? 在信息爆炸的時代,RSS依然是高效獲取結構化內容的重要方式,但市面上主流閲讀器要麼功能冗餘(如集成社交屬性),要麼技術棧陳舊(依賴Electron導致內存佔用高、性能差)。我們希望打造一款簡約輕量、高效率、高性能、隱私安全的RSS閲讀器,核心需求包括: 智庫情報引擎:支持基於搜索引擎的信息抓取與RSS源訂閲。 由AI驅動的特色能力:自動
昵稱 姜 萌@cnblogs
在當今海量數據處理場景下,高效的範圍查詢能力成為許多系統的關鍵需求。RocksDB作為一款高性能的嵌入式鍵值存儲引擎,其獨特的LSM樹結構和索引設計為範圍查詢提供了底層支持。本文將深入探討如何在Rust中利用RocksDB的特性來實現高效範圍查詢,從鍵的設計原則到迭代器的工程實踐,再到性能優化的實戰技巧。無論您是正在構建時序數據庫、構建搜索引擎,還是處理用户事件流,這些技術都能幫助您在保證數據一致

昵稱 涵樹
RabbitMQ簡介 MQP 即Advanced Message Queuing Protocol(高級消息隊列協議),是一個網絡協議,是應用協議的一個開發標準,為面向消息的中間件設計。基於此協議的客户端與消息中間件可傳遞消息,並不受客户端/中間件不同產品,不同的開發語言等條件的限制。2006年,AMQP規範發佈。類比HTTP。 2007年,Rabbit技術公司基於AMQP標準開發的

昵稱 九尾妖狐·
操作系統:Debian 12.5_x64 Windows10_x64 rnnoise版本:0.2 gcc版本:12.2.0 python版本: 3.9.13 RNNoise是一個將傳統數字信號處理與深度學習相結合的開源實時音頻降噪庫,可在消耗極少計算資源的情況下實現毫秒級降噪,今天整理下這方面的筆記,希望對你有幫助。 該庫涉及算法的描述詳見論文(一種混合 DSP/深度學習方法的實時全頻帶語音增強

昵稱 Mike_Zhang
CSP-J $T1$ 循環結構 $+$ 字符串,橙題,不説了肯定做出來了。 #includebits/stdc++.h using namespace std; #define int long long #define N 2000005 int top,a[N]; string s; signed main(){ cins,s=" "+s; for(int i=1;is.length

昵稱 Ryan427
作者:張富春(ahfuzhang),轉載時請註明作者和引用鏈接,謝謝! cnblogs博客 zhihu Github 公眾號:一本正經的瞎扯 以最經典的計算 qps 的曲線為例,vmselect 內部是如何計算的? 1 grafana 通過 query_range 接口發起請求 通常會在 grafana 中配置一個 line chart,然後使用以下的 promql 表達

昵稱 ahfuzhang