









G1(Garbage-First)垃圾回收器是一款面向服務端應用、為大內存和多處理器系統設計的革命性垃圾回收器。G1的核心設計目標是在滿足高吞吐量的同時,建立一個“可預測的停頓時間模型”(Pause-Time Model),讓使用者可以明確指定在一個長度為M毫秒的時間片段內,消耗在垃圾回收上的時間大概率不超過N毫秒。這一特性是它與之前回收器(如CMS)最本質的區別。
在JDK 9發佈之後,G1憑藉其在性能、停頓時間控制和未來發展潛力上的綜合優勢,正式取代了經典的Parallel Scavenge + Parallel Old組合,成為服務端模式下的默認垃圾回收器,而一度輝煌的CMS回收器則被正式聲明為不推薦使用(Deprecated),並在後續版本中被移除。
G1的出現,標誌着Java虛擬機垃圾回收技術進入了一個更加註重延遲和用户體驗的新時代。
停頓時間模型
G1垃圾回收器顛覆了傳統分代回收器將堆內存劃分為連續的新生代和老年代的物理佈局。它將整個Java堆劃分為多個大小相等、不要求物理連續的獨立區域(Region)。每個Region的大小可以1MB到32MB之間,且必須是2的N次冪。G1會根據堆的初始大小和目標,自動選擇最合適的Region大小。每個Region在運行時可以扮演不同的角色:Eden區、Survivor區,或者Old區。對於體積超過一個Region容量一半的超大對象,G1會將其視為巨型對象(Humongous Object),並直接分配到特殊的Humongous區。
在G1之前的垃圾回收器,無論是CMS還是Parallel Scavenge,其回收範圍要麼是整個新生代(Minor GC),要麼是整個老年代(Major GC)或整個Java堆(Full GC)。這意味着一旦觸發老年代回收,其掃描和清理範圍就是整個老年代空間,停頓時間會隨着老年代空間的增大而線性增加,難以控制。
G1則徹底打破了這一限制,它回收的最小單元是Region。G1可以根據預設的停頓時間目標,自由地選擇任意數量、任意分代的Region組成一個回收集(Collection Set,CSet)來進行回收。G1衡量回收哪個Region的唯一標準,不再是“這個Region屬於哪個分代”,而是“回收這個Region的收益有多高”。這個收益指的是花費最小的時間,回收出最大的空間。這正是“Garbage-First”名稱的由來:優先回收垃圾最多的Region。
為了實現這一目標,G1引入了停頓預測模型(Pause Prediction Model)。這個模型基於衰減均值(Decaying Average)理論。衰減均值是一種加權平均的統計方法,它給予近期的數據更高的權重,而歷史久遠的數據權重則會逐漸衰減。這種方法能更精確地反映系統當前的動態行為。G1在後台會持續監控和記錄每一次回收中每個Region的各項指標,例如回收一個Region平均需要多長時間(回收成本)、Region內有多少存活對象(回收收益)等。
當需要進行垃圾回收時,G1會利用這個模型進行預測:它會從所有候選Region中,按照回收收益從高到低排序,然後開始模擬選擇。它會挑選收益最高的Region加入回收集,並累加預估的回收時間,然後繼續挑選下一個,直到累加的預估時間即將觸及用户設定的停頓時間目標(通過 -XX:MaxGCPauseMillis 參數設定)為止。通過這種方式,G1可以在滿足停頓時間目標的前提下,實現垃圾回收效率的最大化,達到了性能與延遲的精妙平衡。

記憶集
為了支持對任意Region集合進行獨立的回收,G1必須解決一個關鍵問題:如何高效地處理跨Region的對象引用。例如,當回收Region A時,必須知道是否有其他Region(如Region B、C)中的對象正引用着Region A中的對象。如果存在這樣的引用,那麼Region A中的被引用對象就不能被回收。為了跟蹤這些跨Region引用,G1為每個Region都維護了一個名為記憶集(Remembered Set,RSet)的數據結構。
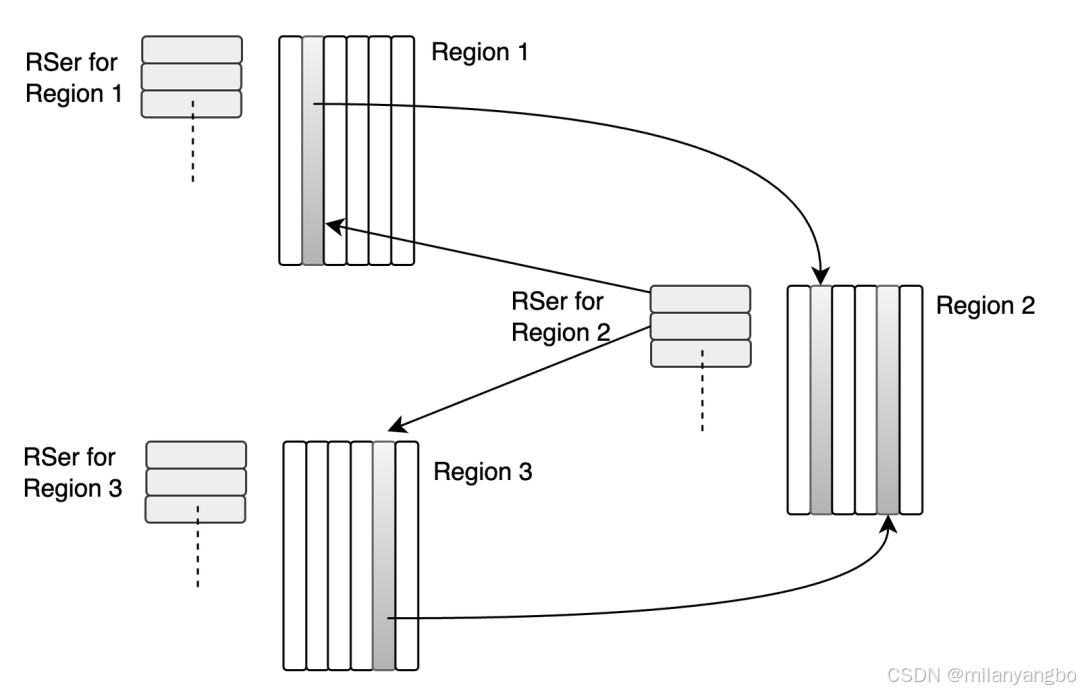
在記憶集的設計中,通常有兩種視角:一種是記錄“誰指向我”(points-into),另一種是記錄“我指向誰”(points-out)。G1的RSet採用的是前者,即每個Region的RSet記錄了“有哪些其他的Region中的對象引用了當前Region中的對象”。具體實現上,G1的底層仍然依賴於卡表。
如上圖所示,Region1和Region3中的對象都引用了Region2中的對象,因此在Region2首先使用points-into的RSet記錄了這兩個引用。這個RSet其實是一個哈希表結構,key是別的Region的起始地址,value是一個集合,裏面的元素是卡表的index。
舉例來説,如果Region 2的RSet裏有一項的key是Region 1,value裏有index為1234的卡頁,它的意思就是Region 1的一個卡頁裏有引用指向Region 2。所以對Region 2來説,該RSet記錄的是points-into的關係;而卡表仍然記錄了points-out的關係。
當回收Region2時,只需掃描其RSet,就能快速找到所有需要保留的存活對象,而無需全堆掃描。
這種設計的代價是顯著的內存開銷。堆中每一個Region,無論新舊,都必須配備一份自己的卡表和RSet。這導致G1的記憶集以及相關的輔助數據結構可能會佔據整個堆容量的20%甚至更多。這是G1為實現可預測停頓時間所付出的空間成本。
Young GC And Mixed GC
G1垃圾回收器提供了兩種垃圾回收模式:Young GC和Mixed GC,這兩種模式都會暫停應用線程。
1)Young GC:此模式的回收範圍僅限於所有年輕代的Region(Eden + Survivor)。當Eden區被佔滿,無法為新對象分配空間時,就會觸發一次Young GC。G1會根據停頓時間目標動態地調整年輕代Region的數量(即年輕代內存的大小),從而間接控制Young GC的耗時。回收過程會將存活對象複製到Survivor區或晉升到Old區,與傳統的Minor GC類似。
2)Mixed GC:這是G1最具特色的回收模式。它不僅會回收所有年輕代的Region,還會額外回收一部分老年代的Region。Mixed GC的觸發時機通常是在老年代的堆佔用比例達到某個閾值(由 -XX:InitiatingHeapOccupancyPercent參數控制,默認為45%)之後,由全局併發標記(Global Concurrent Marking)階段統計出回收收益最高的一批老年代Region。在執行時,Mixed GC會根據用户設定的停頓時間目標,在新生代之外,優先選擇那些垃圾最多的老年代Region加入回收集(CSet),一起進行回收。
必須強調,Mixed GC不等於Full GC。它是一種增量式的、部分回收老年代的機制,旨在通過多次、小規模的回收來逐步清理老年代,避免出現長時間的Full GC停頓。然而,如果應用程序的內存分配速率過快,導致Mixed GC的清理速度跟不上對象晉升到老年代的速度,最終老年代被填滿,G1將不得不放棄其優雅的回收方式,觸發一次後備的、單線程的Full GC(Serial Old GC) 來整理整個堆。
工作過程
G1的完整工作過程可以劃分為以下幾個核心階段,其中併發標記是與應用程序併發執行的,而其他階段則需要暫停應用線程。
1)初始標記(Initial Marking):一個短暫的停頓階段。這個階段僅標記出從GC Roots(如棧上的本地變量、靜態變量等)能直接關聯到的對象。它的耗時非常短。
2)併發標記(Concurrent Marking):此階段與應用程序併發執行,不產生停頓。G1會從初始標記階段找到的對象出發,開始遞歸遍歷整個堆中的對象圖,找出所有存活的對象。G1採用原始快照算法,保證在併發標記開始時存活的對象,無論在標記過程中引用關係如何變化,最終都會被認為是存活的。這種機制的副作用是可能產生一些浮動垃圾,這些垃圾只能等到下一次回收週期才能被清理。
3)最終標記(Final Marking):一個短暫的停頓階段。由於併發標記階段應用線程仍在運行,可能會修改對象的引用關係,原始快照算法會將這些變化記錄下來。此階段的目的就是處理這些在併發標記期間產生的日誌,對標記結果進行修正。
4)篩選回收(Live Data Counting and Evacuation):一個核心的停頓階段,負責真正的垃圾清理。在此階段,G1首先會對各個Region的存活對象數量和回收價值進行精確統計(Live Data Counting)。然後,基於其停頓時間預測模型,選擇一組回收價值最高的Region組成回收集(CSet)。最後,G1會將CSet中所有Region裏的存活對象通過複製算法拷貝到新的、空閒的Region中,並清空CSet中的所有舊Region。這個複製的過程天然地完成了內存碎片的整理,一舉兩得。

G1的優勢主要體現在停頓時間的可預測性和空間的高效整合。G1的停頓時間與回收集的大小有關,而非整個Java堆的大小,這使得停頓時間更加可控。同時,G1在全局範圍內採用整理算法,在局部Region之間採用複製算法,這兩種算法都能有效避免內存碎片的產生,從而杜絕了因碎片過多而觸發的耗時Full GC。
然而,G1也存在一些缺點。首先,G1在運行過程中需要執行復雜的併發操作(如併發標記)和維護寫屏障,這些都會消耗額外的處理器資源。其次,為了實現高效的垃圾回收,G1需要維護Region、RSet、卡表等複雜數據結構,這會佔用一部分內存空間。最後,如果垃圾產生的速度遠遠超過G1的回收速度(尤其是Mixed GC的回收速度),可能會導致堆迅速填滿,最終退化為非常緩慢的Full GC。
根據業界的實踐經驗,對於小內存應用(例如堆大小小於4GB),傳統的CMS甚至Parallel GC在吞吐量上的表現往往優於G1。然而,當Java堆大小超過一個臨界點時,G1在控制停頓時間上的優勢便開始凸顯。這個優劣勢的轉換點通常在6GB至8GB之間。
未完待續
很高興與你相遇!如果你喜歡本文內容,記得關注哦
