
文章導讀
本文作者為沃爾瑪開發者 Ankur Ranjan 與 Sai Vineel Thamishetty 。二人長期關注 Apache Kafka 與流處理系統的演進,深入研究現代流處理架構面臨的挑戰與創新方向。文章不僅總結了 Kafka 的歷史價值與當前侷限,還展示了下一代開源項目 AutoMQ 如何藉助雲原生設計,解決 Kafka 在成本、擴展性與運維方面的痛點,為實時數據流架構提供全新視角。
Kafka:數據運營與數據分析之間的橋樑
我已經使用 Apache Kafka 多年,並且非常喜歡這個工具。作為一名數據工程師,我主要將它用作連接數據運營端與數據分析端的橋樑。憑藉優雅的設計和強大的功能,Kafka 長期以來一直是流處理領域的標杆。
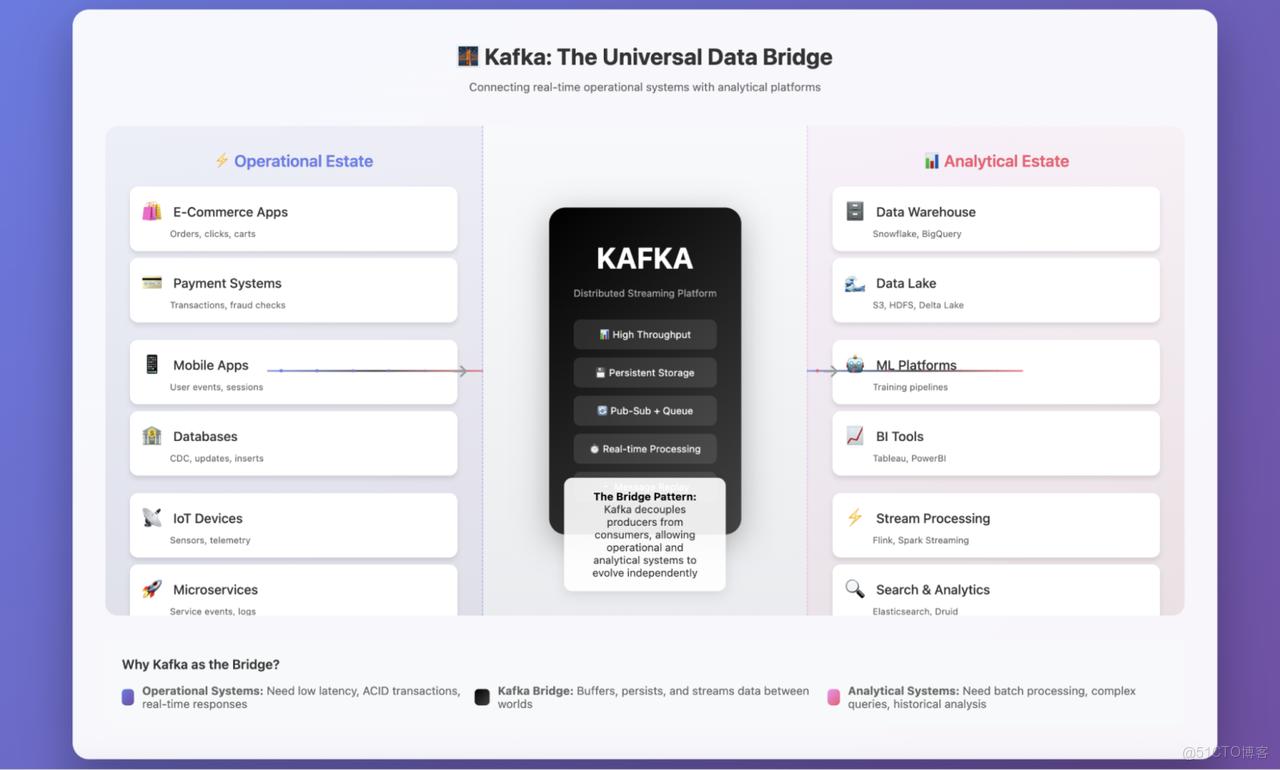
Kafka 扮演着連接數據運營端與數據分析端的橋樑角色。
自問世以來,Kafka 就憑藉獨特的分佈式日誌抽象,塑造了現代流處理架構。它不僅為實時數據流處理提供了無可比擬的能力,還圍繞自身構建了完整的生態系統。
Kafka 的成功源於其核心優勢:能夠大規模地實現高吞吐量與低延遲處理。這一特性使其成為各類規模企業的可靠選擇,並最終確立了其在流處理領域的行業標準地位。
但 Kafka 的發展之路並非一帆風順。它的成本可能急劇攀升,而在流量高峯時段進行分區重分配等運維難題,更是令人頭疼不已。
我至今還記得在沃爾瑪工作時的經歷:曾花費數小時排查一次恰逢流量高峯發生的分區重分配問題,那次經歷幾乎讓我心力交瘁。
儘管成本居高不下,Kafka 在流處理領域的主導地位依然穩固。在如今雲優先的大環境下,一個多年前基於本地磁盤存儲設計的系統,至今仍是眾多企業的核心支撐,這着實令人意外。
深入研究後我發現,背後的原因並非 Kafka “完美無缺”,而是長期以來缺乏合適的替代方案。其最大的賣點 —— 速度、持久性與可靠性,至今仍具有重要價值。
但只要使用過 Kafka,你就會知道:它將所有數據都存儲在本地磁盤上。這一設計暗藏着一系列成本與挑戰,包括磁盤故障、擴展難題、突發流量應對,以及受限於本地或私有部署存儲容量等問題。
幾個月前,我偶然發現了一個名為 AutoMQ 的開源項目。起初只是隨意研究,後來卻深入探索,徹底改變了我對流處理架構的認知。
因此,在本文中,我們希望分享兩方面內容:一是 Kafka 傳統存儲模型面臨的挑戰,二是以 AutoMQ 為代表的現代解決方案如何通過雲對象存儲(而非本地磁盤)另闢蹊徑解決這些問題。這一轉變在保留 Kafka 熟悉的 API 與生態系統的同時,讓 Kafka 具備更強的擴展性、更高的成本效益與更優的雲適配性。
不容忽視的問題:Kafka 為何停滯不前
坦白説,Kafka 十分出色,它徹底改變了我們對數據流的認知。但每當我配置昂貴的 EBS 卷、看着分區重分配進程緩慢推進數小時,或是凌晨 3 點因某個 Broker 磁盤空間耗盡而被驚醒時,我總會忍不住思考:一定有更好的解決方案。
這些問題的根源何在?答案是 Kafka 的 shared-nothing 架構。每個 Broker 都像一個 “隱士”:獨自擁有數據,將其小心翼翼地存儲在本地磁盤上,拒絕與其他 Broker 共享。這種設計在 2011 年合情合理,當時我們使用私有部署服務器,本地磁盤是唯一的存儲選擇。但在如今的雲時代,這就好比在所有人都使用谷歌雲盤(Google Drive)的情況下,仍堅持使用文件櫃存儲數據。
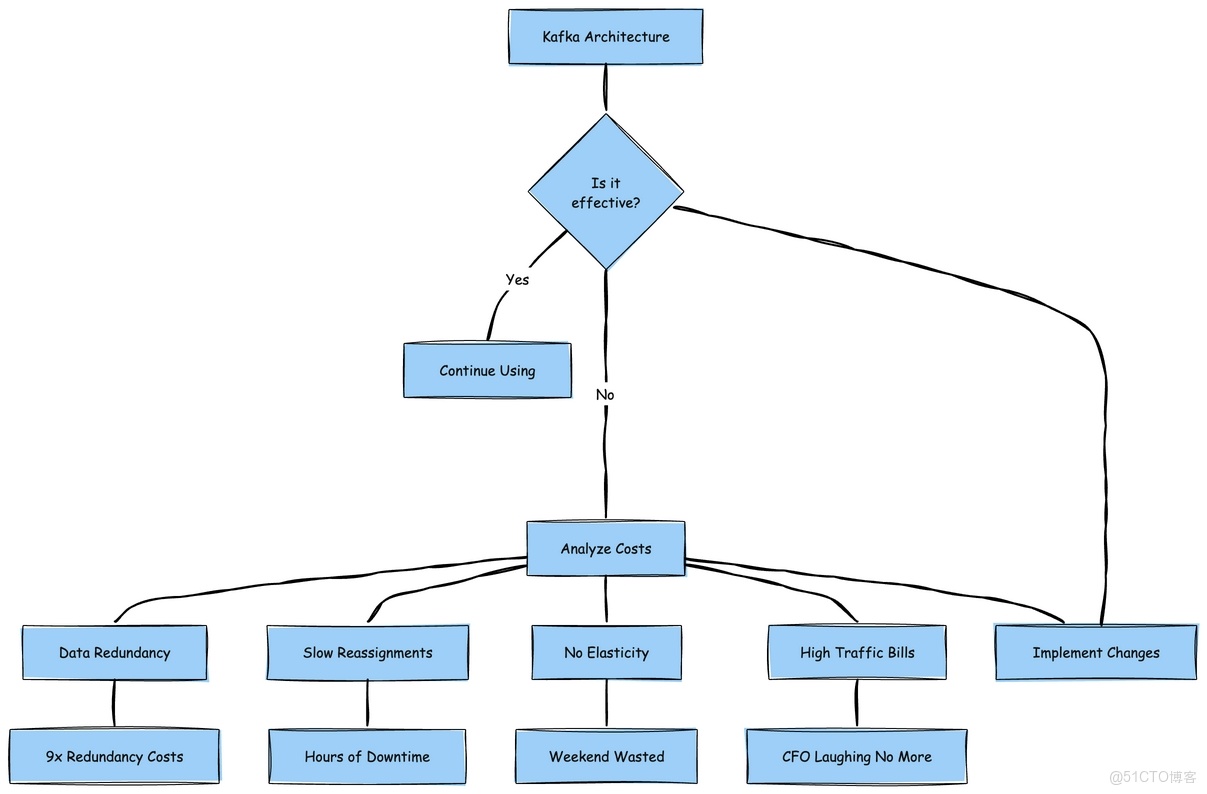
這種架構實際帶來了以下成本負擔:
- 9 倍的數據冗餘(沒錯,你沒看錯 ——Kafka 3 倍副本 × EBS 3 倍副本)。
- 分區重分配進程極其緩慢,如同看着油漆變幹。
- 完全缺乏彈性 —— 嘗試對 Kafka 進行自動擴展,你會發現整個週末都要耗費在這上面。
- 跨可用區(AZ)流量費用高到讓首席財務官(CFO)頭疼。
Kafka 的運維成本:Shared-Nothing 架構的代價
我想通過一個故事,直觀展現 Kafka 的成本問題。
假設你運營着一個小型電商網站,每小時僅攝入 1GB 數據,包括用户點擊、訂單信息、庫存更新等,數據量並不算大。在過去,你只需將這些數據存儲在一台服務器上即可。但如今是 2025 年,為確保高可用性,你選擇部署 Kafka。
而 Shared-Nothing 架構在此刻開始讓你付出高昂代價。
Shared-Nothing 的真正含義
在 Kafka 的體系中,“Shared-Nothing” 意味着每個 Broker 都像一個 “多疑的隱士”,彼此之間不共享任何資源 —— 無論是存儲、數據,還是其他任何東西。每個 Broker 都擁有獨立的本地磁盤,自行管理數據,本質上把其他 Broker 當作 “恰好共事的陌生人”。
這就好比三個室友拒絕共享 Netflix 賬號,反而各自付費訂閲,將相同的節目下載到自己的設備上,並小心翼翼地守護着自己的密碼。聽起來成本很高?事實確實如此。
三重(甚至更嚴重的)打擊
接下來,讓我們看看成本問題有多棘手。
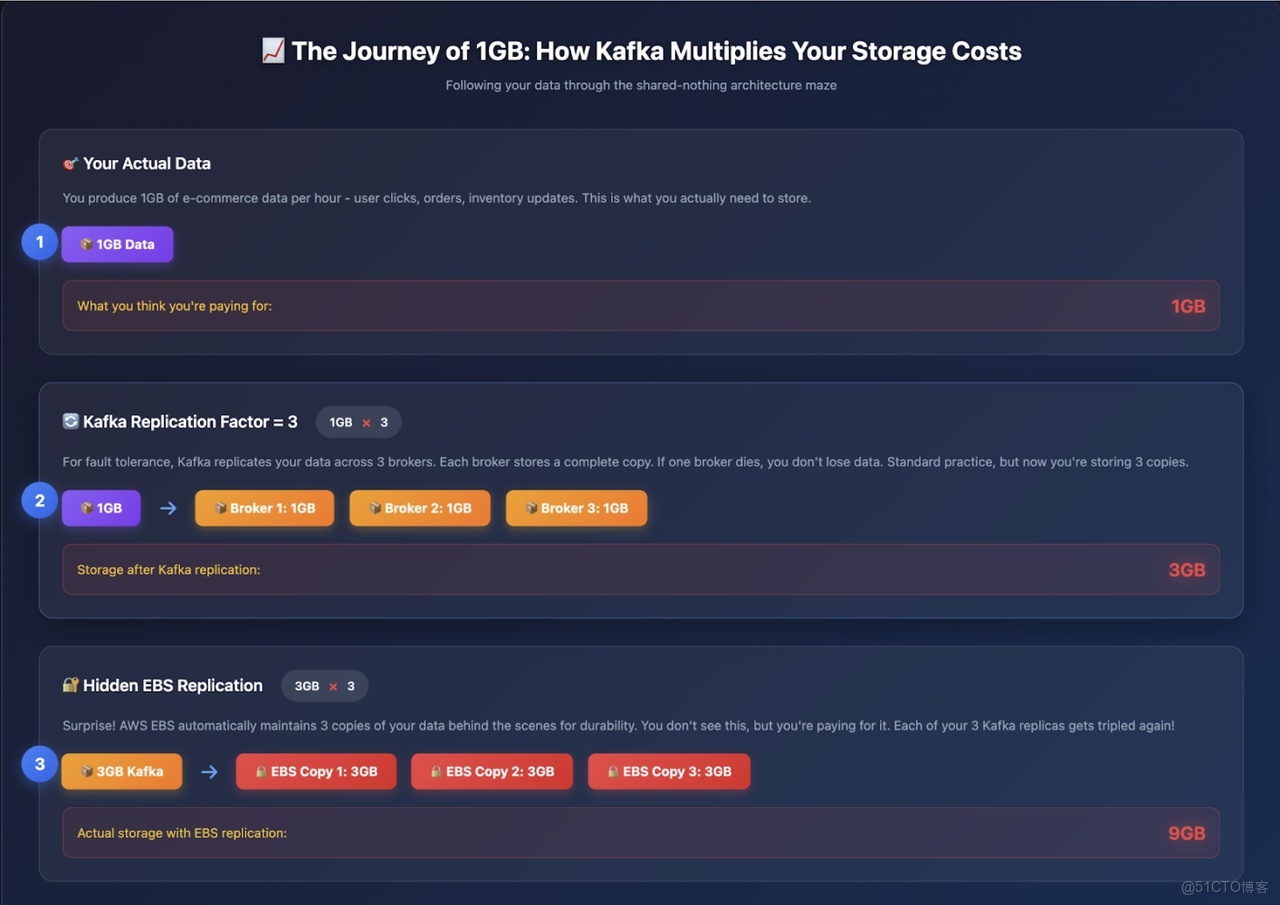
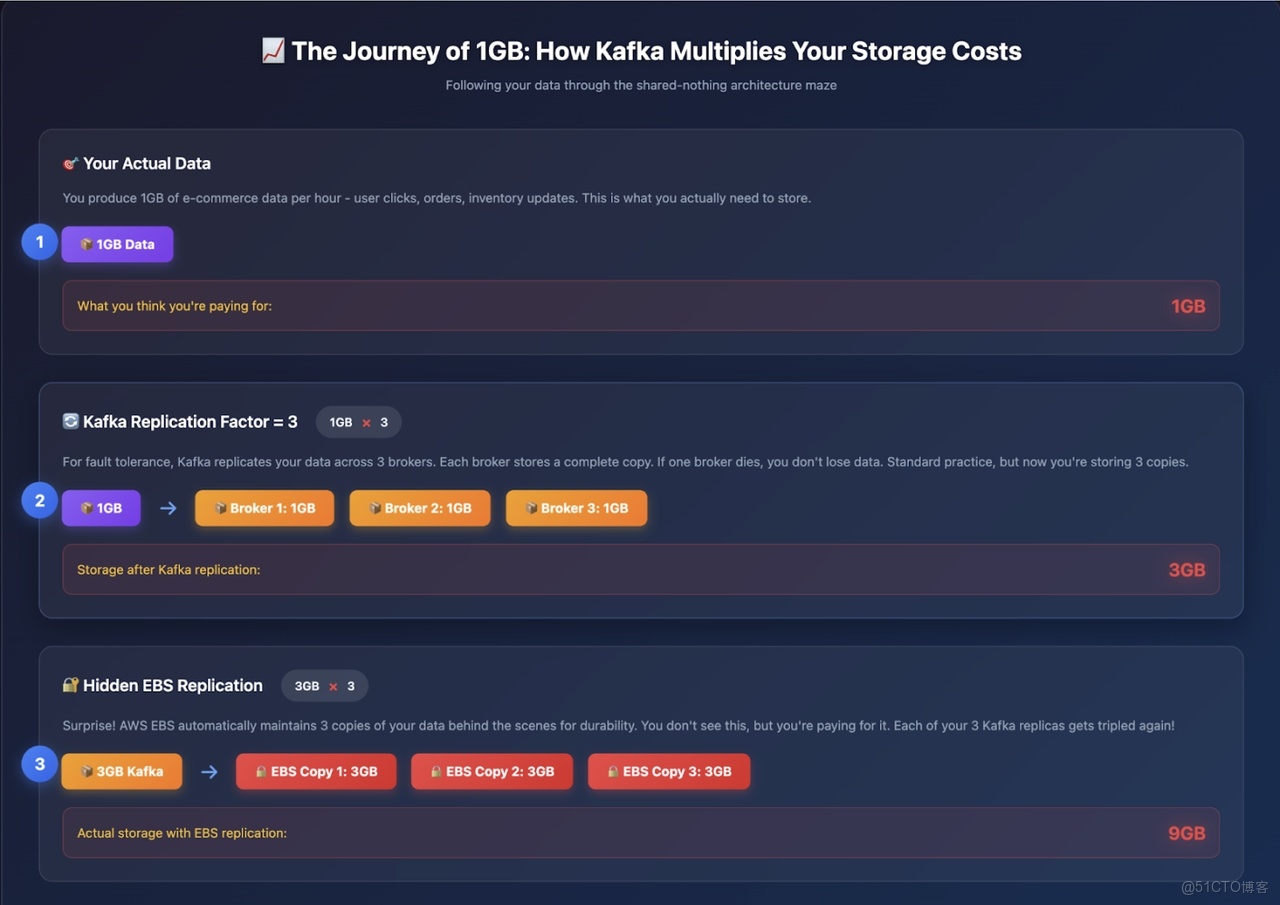
請仔細觀察上圖。
現在,讓我們跟蹤 1GB / 小時的數據在 Kafka 副本機制中的流轉過程:
- 第 1 小時:應用產生 1GB 數據。
- Kafka 副本(副本因子 RF=3):1GB 數據在 Broker 間複製為 3GB。
- EBS 副本:這 3GB 數據的每個副本又被 AWS 複製 3 份,最終變為 9GB。
- 預留空間:為避免午夜告警,需額外預留 30%-40% 的緩衝空間,最終需配置約 12GB 存儲。
也就是説,每攝入 1GB 數據,你需要為約 12GB 的存儲付費
一週的數據流轉(與費用消耗)
若設置 7 天的數據保留期(常見配置):
• 第 1 天:實際數據 24GB,需配置 288GB 存儲。
• 第 3 天:實際數據 72GB,需配置 864GB 存儲。
• 第 7 天:實際數據 168GB,需配置約 2016GB 存儲。
更關鍵的是:即便你只需要消費最近 1 小時的數據,仍需為整整 7 天的數據存儲與複製付費。
以上僅是粗略計算,旨在説明 Apache Kafka 的高成本問題。
雪上加霜的跨可用區成本
跨可用區複製讓成本問題進一步惡化:
當數據攝入速率為 1GB / 小時(RF=3)時:
• 每小時有 2GB 數據跨可用區傳輸。
• 每月約產生 1460GB 跨區流量,按每 GB 約 0.02 美元計算(雙向傳輸各按每 GB 約 0.01 美元計費),每月費用約 29 美元。
當數據攝入速率為 100MB / 秒(RF=3)時:
• 副本機制新增 200MB / 秒的跨可用區流量。
• 生產者向其他可用區的 Leader 節點寫入數據,又新增約 67MB / 秒的跨區流量。
• 總跨區流量約為 267MB / 秒,每月流量達 700800GB。
• 僅跨可用區副本流量與生產者流量的月度費用就約為 1.4 萬美元。
• 若消費者也跨可用區拉取數據,月度費用將攀升至約 1.75 萬美元。
核心結論
在 2011 年,Shared-Nothing 架構合情合理。當時我們使用物理服務器與本地磁盤,存儲區域網絡(SAN)的性能無法與本地磁盤相比。
但在雲時代,你需要為相同的數據支付 12 倍的存儲費用,再加上網絡費用與管理大量磁盤的運維成本。這就好比在 Netflix 時代仍購買 DVD,不僅如此,還為每張 DVD 購買 3 份副本,存放在 3 個不同的地方,並僱人確保這些副本同步更新。
如今情況已然不同。S3 已成為雲存儲的事實標準,具備低成本、高持久性與全局可用性的特點。正因如此,包括數據庫、數據倉庫乃至如今的流處理平台在內的各類系統,都在圍繞共享存儲架構進行重新設計。
AutoMQ、Aiven、Redpanda 等項目順應這一趨勢,將存儲與計算解耦。它們不再在 Broker 間無休止地複製數據,而是利用 S3 保障數據持久性與可用性,既減少了基礎設施重複建設,又降低了跨可用區網絡成本。
這些項目均致力於減少資源重複、降低跨可用區成本,並採用雲原生設計。目前,大多數試圖降低 Apache Kafka 成本的新興項目,實際上都採用了以下兩種方案之一:
- 部分項目推動 Kafka 向全共享存儲模型演進 ——Broker 變為無狀態,存儲完全依託 S3。
- 另一些項目則採用分層存儲方案 —— 將舊數據段遷移至 S3/GCS 等遠程存儲,減少本地磁盤佔用,但仍保留熱數據層。
當然,在 S3 上運行 Kafka 也面臨自身挑戰,例如延遲、一致性與元數據管理等問題。我們將在後續內容中深入探討這些挑戰,並重點分析 AutoMQ 等開源新項目如何高效解決這些問題。
一定有更好的方案,對吧?
(劇透:答案是肯定的 —— 這正是我們深入探索的起點……)
Kafka 分層存儲(Tiered Storage)方案的提出
Kafka 社區一直在積極討論並開發分層存儲功能(參見 KIP-405)。
在闡述我認為該設計可能存在缺陷的原因之前,先讓我們用通俗的語言解釋一下什麼是分層存儲。
傳統上,Kafka Broker 將所有數據存儲在本地磁盤中。這種方式速度快,但成本高且擴展性差 —— 一旦磁盤空間耗盡,你要麼增加更多 Broker,要麼更換更大容量的磁盤,這導致存儲擴展與計算擴展深度綁定。
分層存儲打破了這一模式,將數據分為兩層:

Kafka 分層存儲的核心特點
熱數據 / 本地層
• 該層位於 Kafka Broker 的本地磁盤中,存儲最新數據,針對高吞吐量寫入與低延遲讀取進行優化。
冷數據 / 遠程層
• 該層採用獨立的、通常成本更低且擴展性更強的存儲系統。舊數據段會被異步上傳至這一遠程層,從而釋放 Broker 的本地磁盤空間。
數據流轉
• 僅當日志段關閉後,才會將其上傳至遠程層。消費者可從任意一層讀取數據;若 Broker 本地無目標數據,則 Kafka 會從遠程層拉取數據。
分層存儲宣稱的優勢
• 成本更低:舊數據存儲在 S3/GCS 等遠程存儲中,而非昂貴的 Broker 本地磁盤。
• 彈性更強:存儲與計算可實現更高程度的獨立擴展。
• 運維更優:本地數據量減少,Broker 重啓與恢復速度更快。
從理論上看,這是一個巧妙的折中方案:將熱數據就近存儲以保證性能,將冷數據遷移至遠程存儲以降低成本。
為何分層存儲仍未真正解決問題
接下來,我將分享我的觀點:我認為分層存儲只是對深層問題的 **“治標不治本”**。
還記得我們提到的 1GB 電商數據最終膨脹至約 12GB 的案例嗎?分層存儲無法解決這一根本性問題。這就好比在房屋地基開裂時,卻只對廚房進行翻新。
讓我們逐一分析其中原因。
問題 1:難以擺脱的 “熱數據長尾”
Kafka 必須將活躍數據段存儲在本地磁盤中,這一規則始終不變。只有當數據段 “關閉” 後,才可能被遷移至遠程層。
一個活躍數據段的大小可能是 1GB,在黑色星期五等流量高峯時段甚至可能達到 50GB。若乘以 3 倍副本因子(RF=3),僅單個分區就需要在昂貴的本地磁盤中存儲 150GB 數據。
因此,儘管舊數據被遷移至遠程存儲,但熱數據長尾依然存在,且數據量可能非常龐大。
問題 2:分區重分配仍令人頭疼
新增 Broker?重新平衡分區?分層存儲僅能起到微小的緩解作用。
舉例來説:
• 無分層存儲時:可能需要遷移 500GB 數據,耗時長達 12 小時,過程痛苦。
• 有分層存儲時:可能僅需遷移 100GB 熱數據,耗時縮短至 2-3 小時。
不可否認,分層存儲確實有所改善。但如果你的網站在結賬高峯期出現故障,等待數小時遷移數據仍然無法接受。擴展瓶頸依然存在。
問題 3:隱性的複雜性代價
我的工程師思維這樣總結道:
“現在我需要管理兩個存儲系統,而不是一個。我既要排查本地磁盤問題,又要處理 S3 相關問題。監控指標翻倍,告警數量翻倍。有時數據甚至會卡在兩層之間無法流轉。”
分層存儲並未簡化運維,反而增加了更多移動部件。這就好比為了整理凌亂的書桌,卻買了一張新的書桌 —— 問題並未得到根本解決。
我的結論
分層存儲設計巧妙,也確實能降低存儲成本,但它無法解決 Kafka Shared-Nothing 架構中計算與存儲深度耦合的根本問題。你仍需為熱數據層成本、擴展摩擦與運維複雜性付出代價。
真正值得思考的問題並非 “如何降低 Broker 磁盤成本”,而是 “Broker 是否真的需要擁有磁盤”。
這正是 AutoMQ 等項目進一步探索的方向 —— 讓 Broker 實現無狀態,由共享雲存儲保障數據持久性。
但是……Broker 仍是有狀態的,不具備雲原生特性
隨着我對 Kafka 的使用不斷深入,我開始質疑其核心設計假設。
回顧我們此前討論的 Kafka 各類缺陷,它們都指向一個缺失的關鍵特性:真正的雲原生能力。
即便引入了分層存儲,Kafka Broker 依然是有狀態的,存儲與計算仍緊密耦合。擴展或恢復 Broker 時,仍需進行數據遷移。
為了讓 Kafka 真正實現雲原生,社區開始探索 Diskless Kafka(參見 KIP-1150),實現計算與存儲的完全解耦。
這就好比谷歌文檔(Google Docs):不再將文件保存到本地硬盤,而是將所有數據存儲在共享雲空間中。Broker 不再 “擁有” 數據,僅負責連接共享存儲。
試想這樣的場景:
• 無需管理本地磁盤。
• Broker 崩潰時無需恐慌 —— 不會有任何數據丟失。
• 無需再經歷痛苦的分區重分配。
• 新增 Broker?只需接入集羣即可。
• 移除 Broker?毫無問題 —— 數據安全地存儲在其他位置。
這不就能解決我們此前討論的半數難題嗎?以上僅為我的個人思考,你或許能提出更優的方案。歡迎在評論區分享你的想法,或通過私信與我交流。
Diskless Kafka 才是破局之道
儘管 Apache Kafka 尚未推出 Diskless 版本,但 AutoMQ 等開源項目已實現了這一功能 —— 而我個人最欣賞的一點是,AutoMQ 與 Kafka API 實現了 100% 兼容。
早在 2023 年,AutoMQ 團隊就着手打造真正雲原生的 Kafka。他們很早就意識到,Amazon S3(及兼容 S3 的對象存儲)已成為耐用雲存儲的事實標準。
AutoMQ 與 Kafka 實現 100% 兼容,但對存儲層進行了徹底重構:
• 所有日誌段均存儲在雲對象存儲(如 S3)中。
• Broker 變得輕量且無狀態,僅作為協議路由器。
• 數據的可信來源不再是 Broker 磁盤,而是共享存儲。
既然雲服務商已提供近乎無限的容量、跨可用區副本與 “11 個 9” 的持久性,為何還要重新構建複雜的存儲系統?AutoMQ 充分利用 S3(或兼容存儲)保障數據持久性,Broker 僅負責數據的傳入與傳出。
這一設計帶來了顯著優勢:
• 輕鬆擴展:計算與存儲可獨立擴展。新增 Broker 以提升吞吐量,存儲則在雲中自動擴展。
• 快速重平衡:無需進行數據遷移。新增或移除 Broker 時,僅需重新分配 Leader 即可。
• 更高持久性:雲對象存儲無需在 Broker 上維護 3 倍副本,即可提供數據冗餘。
• 運維簡化:Broker 可隨時替換。若某個 Broker 故障,只需啓動新的 Broker,無需進行副本同步。
換言之,Broker 變得像 “牛羣” 一樣可替代,而非需要精心呵護的 “寵物”。
我最喜歡用這樣的比喻來形容:這就好比谷歌文檔,不再將文件保存到本地 “C 盤”,而是將所有數據存儲在共享雲盤中。Broker 僅提供訪問能力 —— 數據本身始終安全地存儲在雲中。
AutoMQ 摒棄了每個 Broker 在本地磁盤囤積數據的模式,提出了共享存儲理念:所有 Kafka 數據存儲在一個公共雲倉庫中,任何 Broker 均可訪問。這並非空想 ——AutoMQ 已通過與 Kafka 完全兼容的分支實現了這一設計,有效解耦了 Kafka 架構中的計算與存儲。
本質上,他們選擇站在 “巨人”(雲服務商)的肩膀上,而非重複 “造輪子”。既然 S3 等服務已開箱即用地提供近乎無限的容量、跨可用區副本與極高的耐用性,為何還要從零構建複雜的存儲系統?
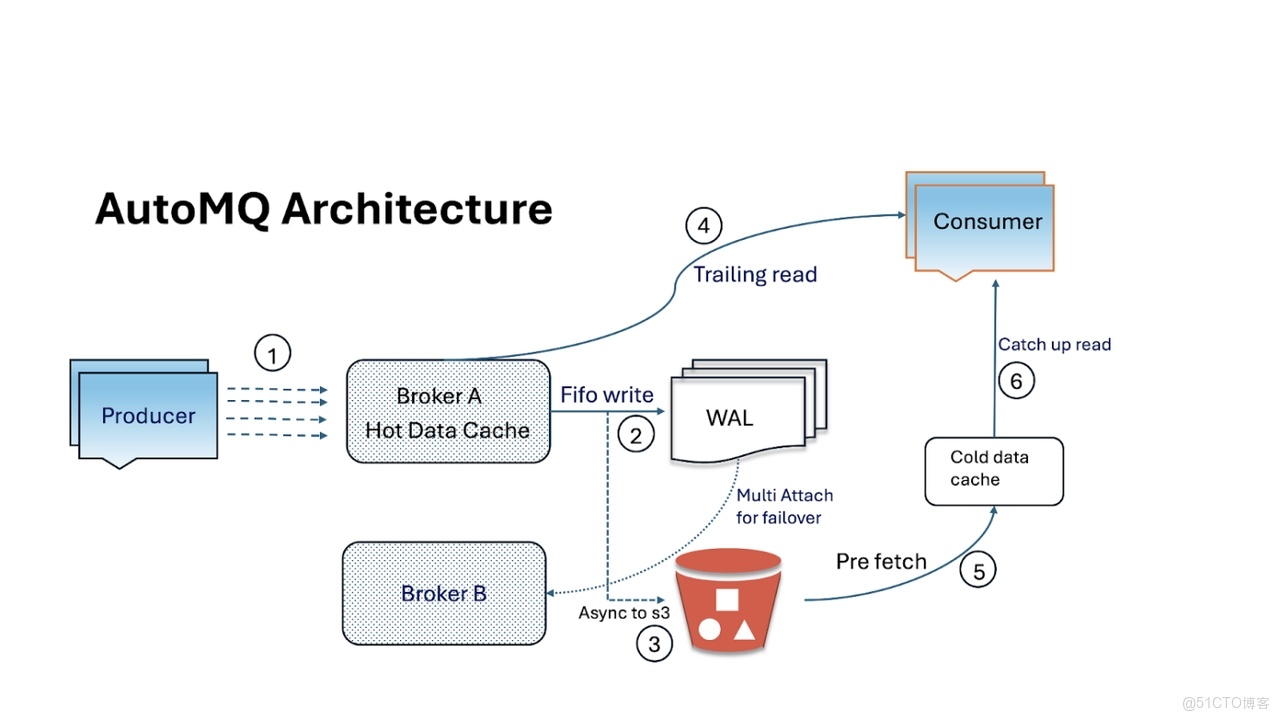
要理解 AutoMQ 的創新,不妨想象 Kafka 以谷歌文檔的模式運行:Broker 不再將數據保存到本地 “C 盤”,而是寫入一個所有人共享的雲盤。具體而言,AutoMQ 的 Broker 是無狀態的,僅作為輕量級 “交通警察”,解析 Kafka 協議並實現數據與存儲之間的路由。Kafka 日誌段不再存儲在 Broker 磁盤中,而是以**雲對象存儲(S3)**作為可信來源。這一設計帶來了諸多顯著優勢。
首先,數據持久性大幅提升 —— 你可利用 S3 內置的副本機制與可靠性,無需在不同 Broker 上維護 3 份數據副本。其次,成本顯著降低 —— 大規模使用對象存儲的成本遠低於部署大量本地 SSD(尤其是考慮到這些 SSD 還需維護 3 倍副本)。此外,擴展變得幾乎 “即插即用”。
需要更高吞吐量?只需新增更多 Broker 實例(計算資源),並將其指向同一存儲即可;無需通過大規模數據遷移來重新平衡分區。Broker 變得像 “牛羣” 一樣可替代,而非 “寵物”—— 若某個 Broker 故障,新的 Broker 可立即啓動並提供數據服務,因為數據安全地存儲在其他位置。這正是 Kafka 此前一直難以實現的雲彈性。正如一位 Kafka 雲架構師所言:“存儲在雲中自動擴展,Broker 只需提供數據傳入與傳出的處理能力。”
最後,讓我們總結 AutoMQ Diskless 架構帶來的優勢。
Diskless 架構優勢
• 輕鬆擴展:計算(Broker)與存儲獨立擴展。新增 Broker 以提升吞吐量,存儲則在雲中自動擴展。無需再過度配置磁盤空間,按實際使用付費即可。
• 快速重平衡:無需遷移分區數據。新增或移除 Broker 時,僅需重新分配 Leader,過程幾乎即時完成。
• 更高持久性:對象存儲提供 “11 個 9” 的耐用性,遠優於 Broker 副本機制。
• 運維簡化:Broker 故障無關緊要,只需替換即可。無需數據恢復或副本同步。
延遲挑戰
理論上,Diskless Kafka 堪稱完美,但它存在一個問題:對象存儲會引入延遲。
低延遲是 Kafka 的核心優勢,而直接向 S3 或 GCS 寫入數據會導致延遲增加,併產生 API 開銷。
AutoMQ 在此處做出了明智的設計:引入預寫日誌**(Write-Ahead Log,WAL)**抽象。消息首先追加到一個小型、耐用的 WAL(基於 EBS/NVMe 等塊存儲)中,而長期持久性則由 S3 保障。這一設計在保持 Broker Diskless 特性的同時,有效降低了延遲。
能否進一步優化?
在某些場景中,延遲至關重要,例如金融系統、高頻交易、低延遲分析等。對於這些場景,即便是 AutoMQ 的 WAL 方案,也需要進一步創新。
AutoMQ 已表示將推出更深入的專有 / 商業解決方案:
• 直接寫入 WAL:每條消息均寫入耐用的雲原生 WAL。
• Broker 隨後從緩存或內存中提供讀取服務。
• WAL 卷容量較小(如 10 GB),若某個 Broker 故障,可快速將其掛載到新的 Broker 上。
這與 Kafka 的分層存儲有何不同?
• 分層存儲:數據首先寫入 Broker 磁盤,在 Broker 間複製,之後才將舊數據段遷移至 S3。
• AutoMQ 的 Diskless 方案:完全無需 Broker 磁盤。數據持久性由雲存儲層直接保障,無需進行副本遷移。
若某個 Broker 故障,只需將其 WAL 卷掛載到新的 Broker 上,新 Broker 即可無縫接續舊 Broker 的工作。存儲的生命週期超越計算。
這是一個重大的思維轉變:計算資源可隨時替換,存儲則保持穩定。
在部分場景中,延遲的影響至關重要。因此,上述方案可能並非完美適配,仍需進一步優化。深入研究後我發現,AutoMQ 已針對這類場景提供了相應解決方案,但該方案似乎屬於其專有 / 商業產品範疇。
這一解決方案可能看似複雜,但彰顯了真正的工程智慧,是下一代基於 S3 的 Diskless Kafka 方案。
當然,與 SSD / 本地磁盤相比,S3 的速度確實較慢。此外,還需提升向雲存儲(S3)寫入數據的效率,以減少 API 開銷。
這與 Kafka 的分層存儲是否相同?
我的第一反應也是如此:“等等,這難道不與 Kafka 將數據遷移至 S3 的分層存儲方案一樣嗎?”
事實並非如此。二者的區別如下:
• 在啓用分層存儲的 Kafka 中,數據仍需先寫入 Broker 本地磁盤,Broker 間的副本複製(ISR)仍是必需步驟,之後才會將舊數據段遷移至 S3。
• 在 AutoMQ 中,完全無需本地磁盤。數據直接寫入雲原生存儲中的 WAL,無需副本複製,因為雲卷本身已具備耐用性與冗餘能力。
因此,這並非簡單的優化,而是一種完全不同的設計。
若 Broker 故障怎麼辦?
這是一個很好的問題,也是我們接下來的 “頓悟” 時刻。
在 Kafka 中,若某個 Broker 故障,需重新分配分區並同步副本,過程十分痛苦。
而 AutoMQ 的處理方式完全不同:
• 每個 Broker 本質上是一個掛載了耐用雲卷(EBS 或 NVMe)的計算實例。
• 假設 Broker A 正在向其 WAL(EBS)卷寫入數據,突然發生故障。
• 無需擔心,數據仍安全地存儲在 WAL 卷中。
• 集羣會迅速將該 WAL 卷掛載到 Broker B 上,Broker B 可無縫接續 Broker A 的工作。
• 整個過程無數據丟失、無副本遷移、無需等待。
本質上,在 AutoMQ 中,存儲的生命週期超越 Broker。計算資源可隨時替換,存儲則保持穩定。
這與 Kafka 的設計理念存在巨大差異。AutoMQ 將計算與存儲徹底解耦,這正是其設計的精妙之處。若你想深入瞭解,可查閲其官方文檔。
最後的思考
若你能讀到此處,感謝你的耐心閲讀!
我們一直在探討的理念簡單卻極具影響力:若用雲存儲取代本地磁盤,作為類 Kafka 系統的基礎,會帶來怎樣的改變?
這一轉變將大幅減少運維難題:
• 無需再進行 Broker 重分配。
• 無需再為磁盤告警驚慌失措。
• 擴展變得 “即插即用”。
令人振奮的是,AutoMQ 等項目正朝着這一方向探索,同時保持與 Kafka API 及工具的兼容性。