

作為一名長期與 Elasticsearch 打交道的引擎研發,我見過太多集羣因為一個看似無害的 wildcard 模糊查詢而瞬間崩潰。
許多開發者繼承了 SQL LIKE %...% 的思維習慣,直接把它搬到 ES 中——在小數據量時沒什麼大礙,但當文檔量上億時,它會變成拖垮集羣的性能黑洞:
- 輕則:錯用字段類型,查不準結果,浪費存儲
- 重則:暴力掃描,CPU 瞬間打滿,集羣直接假死
為什麼會這樣?又該怎麼避免?
接下來,我們將深入解析這些問題原因和其解決方案。我們特意在 5000 萬級數據量下做了高壓測試,用真實數據復刻事故現場,讓你一眼看懂問題的根源與規避方案。
對 ES 用户及技術開發愛好者而言,這是一份不可錯過的技術文章。
不同查詢場景的最佳選型建議
針對不同場景,我們給出以下實戰建議:
|
場景 |
查詢模式示例 |
推薦方案 |
核心理由 (基於實測數據) |
|
任意模糊匹配 |
|
Wildcard 字段 |
綜合性價比之王。 存儲僅增 20%,無需改代碼,性能穩健,支持複雜模式。 |
|
極致性能狂魔 |
|
Ngram + Constant_Score |
物理極限 (<10ms)。 跳過算分後,性能無敵。代價是存儲膨脹和查詢代碼改造。 |
|
分詞前綴匹配(下拉提示) |
|
Search_As_You_Type |
下拉提升專業選手,空間換時間,可支持超高 qps |
|
低頻詞搜索 |
|
Keyword |
keyword 夠用。 只要前綴足夠長(區分度高),FST 掃描範圍小,速度極快(1ms)。 |
特別提醒:選型還要看量級
- 數據量 < 10 萬: 默認 keyword 即可,無需過度優化也能實現毫秒級響應。
- 數據量 > 1000 萬: 必須慎重選擇,否則分分鐘線上故障。
一、痛點解析:從“查不到”到“搞掛集羣”的三重陷阱
wildcard 的問題不只是“慢”,它首先是一個邏輯陷阱。
陷阱一:分詞誤用 → 查詢結果靜默丟失
text 分詞導致的“查不到” (The Logic Tra)
- 現象:文檔裏明明有 "agent 007 bond",但搜 *agent 007* 返回空。
- 原理: text 字段經過分詞器(Analyzer)處理,變成了 ["agent", "007", "bond"] 三個獨立的詞元。wildcard 是去匹配每一個單獨的詞元,顯然沒有一個詞元長得像 *agent 007*(跨詞了)。
Tips:如果懷疑分詞存在問題,可使用
_termvectorsAPI 查看磁盤中數據的實際存儲情況。你可能會發現,它的存儲形式與原文早已大相徑庭。
陷阱二:Keyword 模糊查詢 → 線性性能雪崩
為了解決“陷阱一”,開發者通常會決定:“改用 keyword 字段吧,它不分詞,保留完整字符串。” 這時候,業務邏輯通了,但性能噩夢開始了。
- 事故現場: 當你執行 *login* 時,ES 被迫對數百萬個長字符串執行逐一掃描。
- 實測驗證:在 5000W 數據下,單次查詢耗時 13秒,CPU 瞬間打滿,集羣直接假死。(詳見 6.2)
陷阱三:Rewrite 機制限制 → 報錯或數據丟失
即使你忍受了 Keyword 的慢,你可能還會遇到更底層的問題。ES 底層的 Rewrite(重寫)機制 讓你面臨兩個選擇:
- 要麼“報錯”(Scoring Boolean): 如果業務需要算分,ES 必須把匹配詞展開為布爾查詢。一旦匹配詞超過 1024 個(默認限制),查詢直接熔斷報錯:too_many_clauses。
- 要麼“丟數據”(Top N): 為了不報錯,你被迫配置 top_terms_N 。這告訴 ES:“只計算頻次最高的 N 個詞,剩下的扔掉。”後果就是數據靜默消失。
二、實戰方案詳解(Ngram / Search_as_you_type / Wildcard 配置與查詢 DSL)
既然“直接查”是死路,我們必須“將計算壓力從查詢時轉移到索引時”。以下是 3 種方案的完整配置代碼。
方案 1:Ngram 索引器(極致性能,代價昂貴)
這是最經典的“空間換時間”方案,通過自定義 Analyzer,在索引時將字符串切分成碎片(如 te,ex,xt...)。
1)索引配置 (Settings & Mapping):
PUT /bench_ngram
{
"settings": {
"analysis": {
"tokenizer": {
"my_ngram_tokenizer": {
"type": "ngram",
"min_gram": 2, // 支持搜短詞 (如 ID)
"max_gram": 3 // 過大會造成存儲膨脹嚴重,2-3 為性價比首選,除非超高 qps,否則不建議更大
}
},
"analyzer": {
"my_ngram_analyzer": { "tokenizer": "my_ngram_tokenizer" }
}
}
},
"mappings": {
"properties": {
"sku": { "type": "text", "analyzer": "my_ngram_analyzer" }
}
}
}2)查詢改造 (Query DSL):
注意必須修改查詢代碼,推薦使用 constant_score 包裹 match (operator: and),這是兼顧準確性與極致性能的最佳實踐。但是會有一定假陽,若一定要求準確,則需使用 match_phrase。
GET /bench_ngram/_search
{
"track_total_hits": false, // 生產環境建議關閉,利用提前終止優化,否則大基數下會非常慢
"query": {
"constant_score": {
"filter": {
"match": {
"sku": { "query": "BATCH888", "operator": "and" }
}
}
}
}
}Tips: constant_score 換成 bool filter 效果也一樣
評價: 速度快到離譜,唯二的缺點是費空間和廢代碼(需重寫 DSL)。
方案 2:search_as_you_type 字段(面向前綴提示的專用類型)
這是 Elasticsearch 官方專為 下拉提示 場景打造的字段類型,它會在索引階段自動生成多種前綴和短語組合,確保用户在輸入的同時即可獲得精準、快速的搜索建議。
1)索引配置(Mapping):
PUT /bench_sayt
{
"mappings": {
"properties": { "sku": { "type": "search_as_you_type" } }
}
}2)查詢方式:
使用 multi_match + bool_prefix 類型。
評價: 它是為“前綴”而生的。雖然也能勉強做中間匹配(通過 stored shingle),但空間佔用巨大,且在非前綴場景下性能並不突出。
方案 3:wildcard 字段類型(官方推薦的通用型方案)
wildcard 是 Elasticsearch 7.9+ 專為非結構化文本檢索設計的字段類型,本質上是一個自帶索引加速器的 keyword 字段。它在底層採用“雙重結構”架構,以在通配符查詢中兼顧性能與準確性:
- 加速層(Approximation):寫入時會自動將字符串切分為 3-gram 片段,存入 倒排索引。查詢時,利用倒排鏈求交能力快速過濾出“可能匹配”的候選文檔,將掃描範圍從 全量數據 縮小到 極小集合。
- 驗證層(Verification):通過 Binary Doc Values 存儲完整的原始字符串,對篩選出的候選文檔使用 Automaton(有限自動機)進行逐字節精確比對,確保檢索結果 100% 準確。
1)索引配置(Mapping):
配置過程非常簡單,無需自定義 Analyzer,即可直接在 Mapping 中聲明字段類型為 wildcard。
PUT /bench_wildcard
{
"mappings": {
"properties": { "sku": { "type": "wildcard" } }
}
}2) 查詢方式:
零改造! 繼續使用 DSL: wildcard: { "sku": "*BATCH888*" } 。
評價: 唯一推薦的通用解。它是最安全的默認選項。它也許在某些特定 case(如超短前綴)下不如 Ngram 暴力,但它能處理所有情況(包括正則、複雜通配)。查得準、用得爽(零侵入)、存得省。
三、5000W 數據壓測對比(性能、存儲全維度)
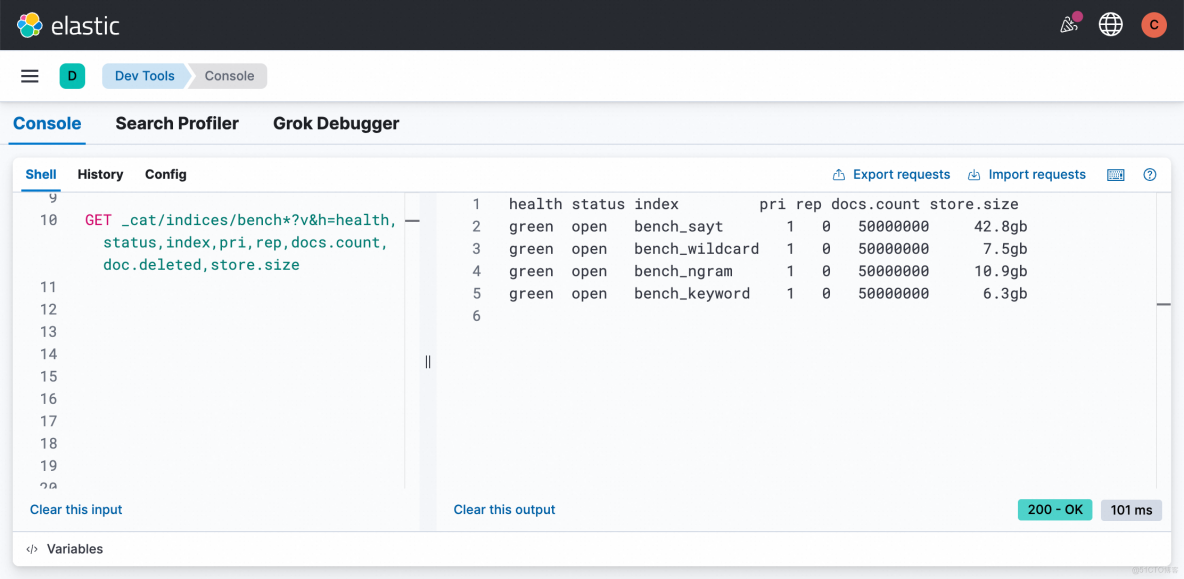
數據勝於空談。我們在 Serverless 8.17 環境中,寫入了 5000 萬條高基數且無重複的 UUID 數據,用實測結果向你展示——在架構選型中,你在存儲上付出了多少,又在性能上收穫了什麼。
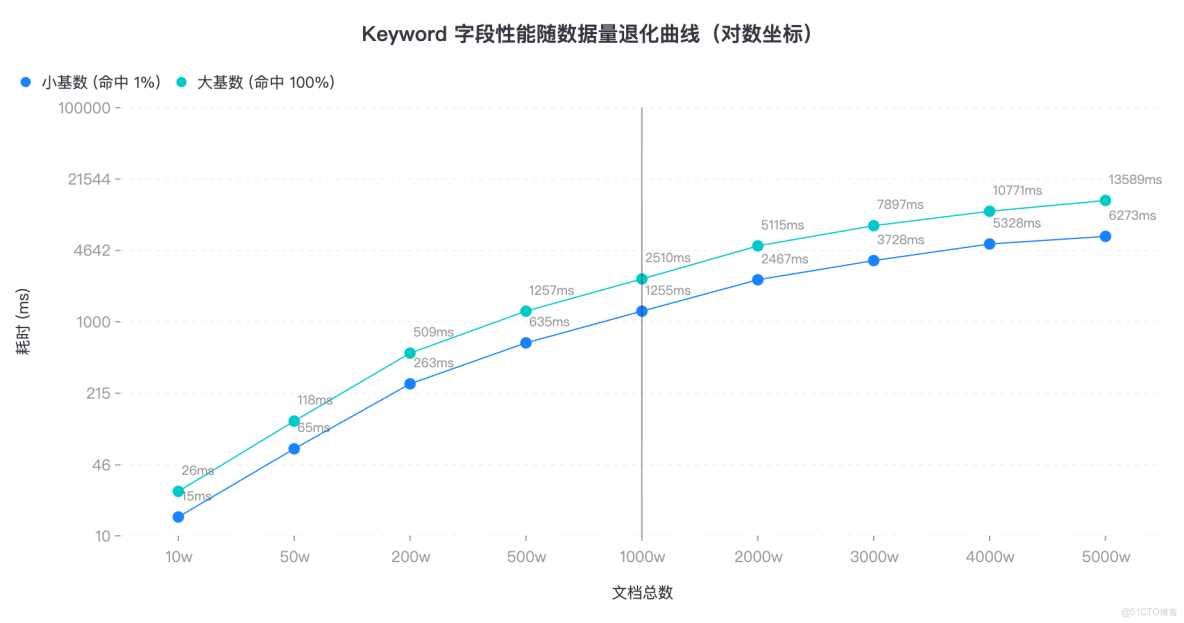
3.1 keyword 性能退化曲線
為了讓大家直觀感受都 keyword 的表現,我們測試了不同數據量下的查詢耗時。可見,超過 1000w,即使是小基數,也要 1s+,業務已無法使用。
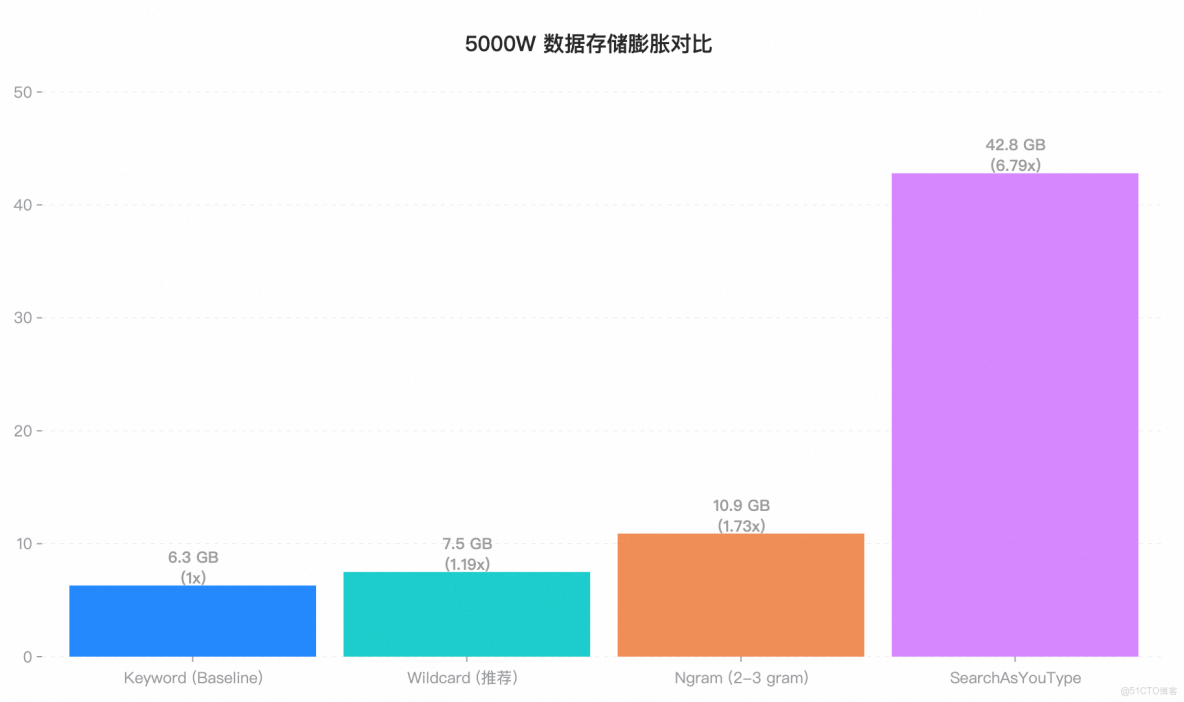
3.2 存儲膨脹對比:空間換時間,代價有多大?
我們先觀察磁盤佔用情況。forcemerge 完成後,不同方案的存儲規模差異十分明顯。
- Wildcard 效果驚豔: 在支持任意模糊匹配的同時,僅比純文本 FST 多了 1.2GB 的開銷,架構設計極其優秀。
- Ngram 的空間陷阱: 我們在測試中使用了
min:2, max:3的 ngram 配置。但其存儲依然膨脹了73%,達到了 10.9 GB。但這造成了無法搜索單字,若需要搜索單字,需要min:1, 這會造成海量高頻詞,性能崩塌。便又要max_gram: 10,來進行提速。此時空間直接爆炸。 - SAYT 的空間代價: 42.8 GB 的佔用量證明了它就是為“前綴”這一件事不惜血本的設計,絕不適合通用場景。
3.3 中綴查詢誰是王者?Wildcard 穩健,Ngram 極致
接下來,我們在 5 QPS 負載下隨機執行中綴查詢(如 *BATCH888*),對比記錄集羣在該場景下的 CU 消耗與響應時間,直觀體現不同方案的性能差異。
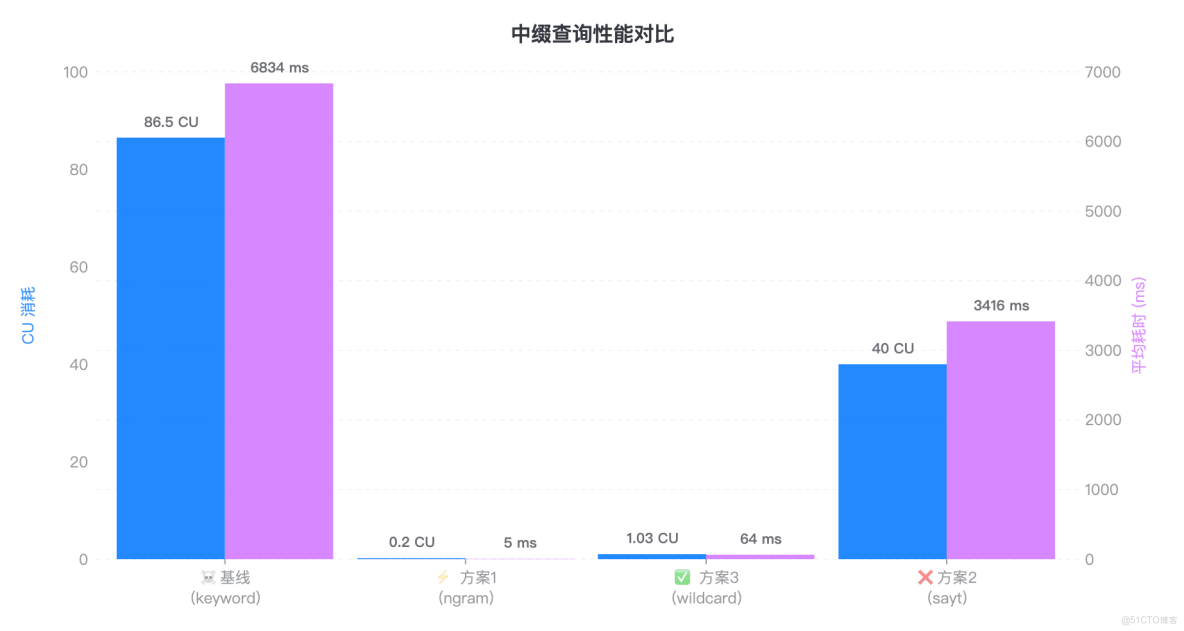
|
方案 |
平均耗時 |
CU 消耗 |
評述 |
|
基線 |
6834 ms |
86.5 cu |
集羣雪崩: 全表掃描導致 CPU 打滿,完全不可用。 |
|
方案 1 |
5 ms |
0.2 cu |
物理極限: 純內存倒排索引運算,速度快過 Wildcard 12 倍。 |
|
方案 3 |
64 ms |
1.03 cu |
工程平衡: 雖然比 Ngram 慢,但 64ms 依然是極佳的實時響應,且不需要改代碼。 |
|
方案 2 |
3416 ms |
40 cu |
不適用: 在非前綴場景下性能極差。 |
Tips:為什麼 Ngram 只要 5ms?
在測試中,我們採用了
constant_score與track_total_hits: false的組合策略,跳過了相關性算分和全量命中統計,直接利用倒排索引的位圖交集(BitSet Intersection)以及提前終止(Early Termination)機制,將查詢過程壓縮到了極限。
不過,這種極致性能的實現是有代價的:
1)功能受限: 搜不到單字的短詞, 且嚴禁開啓總數統計(否則耗時飆升 1000 倍至 4.4s,見附錄 6. 3);
2)代碼侵入: 對代碼有一定侵入性,需要重寫查詢 DSL,對於 a*b 這類中間模糊的查詢處理複雜。
3.4 前綴查詢驗證:誰是“前綴之王”?
在測試中,我們分別對比了各方案在 寬泛前綴(匹配大量文檔)和 精準前綴(匹配少量文檔)兩種場景下的表現。
結果顯示,SearchAsYouType 不愧為前綴匹配的專業選手,無論前綴長度如何,都能保持穩定的低延遲;而 Wildcard 在處理超長前綴時,由於底層自動機驗證過程的開銷顯著增加,性能會出現明顯下滑。
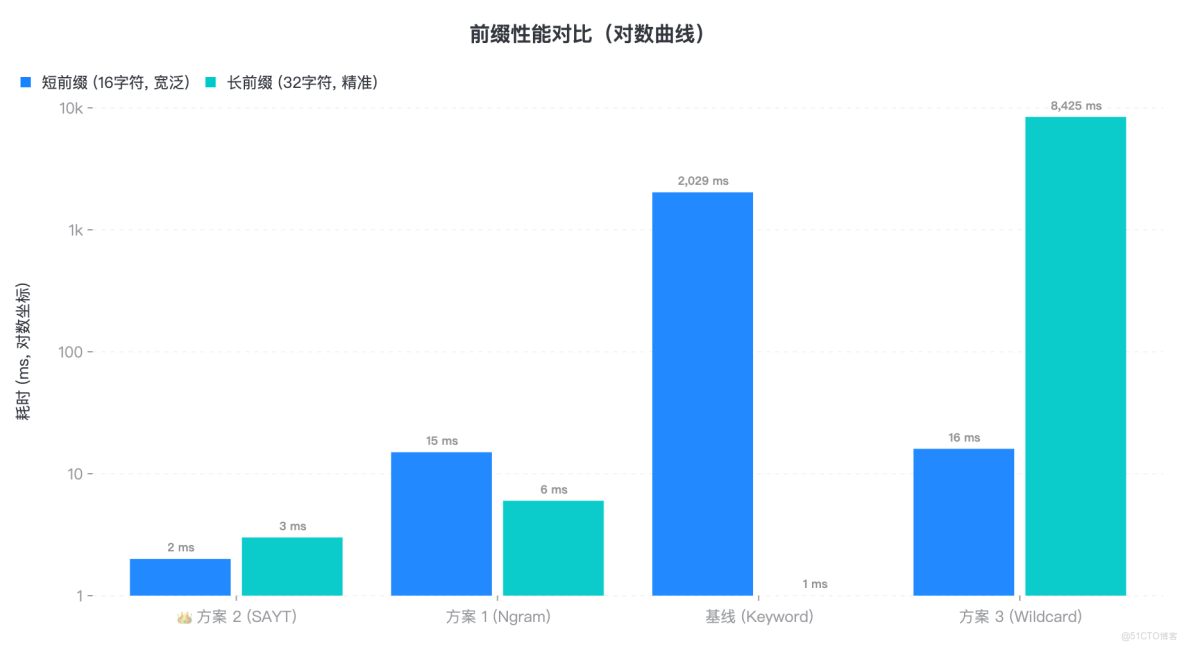
|
方案 |
短前綴耗時 (16字符, 寬泛) |
長前綴耗時 (32字符, 精準) |
專家點評 |
|
基線 (Keyword) |
2029 ms |
1 ms |
線性退化。 前綴越短,掃描越慢。只有在精準定位(長前綴)時才是王者。 |
|
方案 1 (Ngram) |
15 ms |
6 ms |
表現優異。 倒排索引在處理前綴時效率依然很高,僅次於 SAYT。 |
|
方案 2 (SAYT) |
2 ms |
3 ms |
穩如泰山。 無論前綴長短,耗時恆定極低。下拉提示場景的唯一解。 |
|
方案 3 (Wildcard) |
16 ms |
8425 ms |
反直覺崩塌。 在極長前綴下,底層自動機構建與驗證開銷過大,反而比短前綴慢。 |
四、殘酷現實:選對了方案,就能高枕無憂嗎?
根據上述實測結果,很多開發者的第一反應可能是:“只要將所有字段替換為 Wildcard 類型,就可以徹底解決問題。”
但長週期的生產運行告訴我們,即使在實現層面選擇了最優方案,也仍存在兩類無法迴避的潛在風險——堪稱生產環境中的“隱形炸彈”:
4.1 防不住的“手滑”(Human Error):
“你無法保證每一位新入職的同事都熟讀開發規範。也許只是一次無心的手滑,在普通的 Keyword 字段上寫了一個 *...* 查詢——這一行不起眼的代碼,足以讓你的自建集羣在業務高峯期瞬間雪崩,甚至拖垮正常的寫入和核心查詢。”
4.2 跟不上的“內核”(Technical Debt):
Elasticsearch 社區的演進日新月異。像 Wildcard 這樣優秀的底層優化往往依賴最新的內核版本。而自建集羣因為擔心升級風險,往往只能“鎖死”在老版本,眼睜睜看着數倍的性能紅利白白流失。
五、阿里雲 ES Serverless : 穩定性與先進性的“雙重保障”
改變每一位開發者的查詢習慣幾乎不可能,而我們選擇了另一條路:
直接讓你的集羣擁有“防彈護甲”,自動抵禦那些足以擊穿性能的高危查詢。與自建相比,阿里雲 ES Serverless 的架構更健壯、更安全,也更省心。
5.1 內置“智能護欄”,終結單點雪崩
我們不會在後台“魔法般地”自動修改你的業務代碼,但可以在風險發生前,阻止高風險查詢拖垮整個集羣。
阿里雲 ES Serverless 內置了企業級的 智能查詢限流與熔斷機制,能夠精準識別那些資源消耗巨大的 “殺手級查詢”(Cluster Killers),並進行針對性的限流或熔斷處理。
這樣,你的集羣將始終保持業務連續性——不會因為一條異常 SQL 而全面宕機。高風險查詢被隔離控制,正常查詢依然可以平穩、流暢地執行。
5.2 內核無感進化,坐享性能紅利
基於雲原生 Serverless 架構,阿里雲實現了內核的 靜默無感升級。
無論是 Wildcard 字段底層的實現優化,還是查詢執行器的性能改進,你都無需進行任何遷移或重啓,即可自動、透明地獲得這些優化成果。
這意味着,你可以在 零額外運維成本 的情況下,始終運行在更快、更安全、更強大的版本上,讓技術紅利直接轉化為業務競爭力。
六、壓測實錄節選(進羣獲取完整 pdf)
6.1 存儲膨脹對比 (5000萬數據)
6.2 Keyword 中綴查詢耗時隨文檔數的變化
|
文檔數 |
10w |
50w |
200w |
500w |
1000w |
2000w |
3000w |
4000w |
5000w |
|
小基數 命中 1% *91-ID* |
15ms |
65ms |
263ms |
635ms |
1255ms |
2467ms |
3728ms |
5328ms |
6273ms |
|
大基數 命中 100% *25-BA* |
26ms |
118ms |
509ms |
1257ms |
2510ms |
5115ms |
7897ms |
10771ms |
13589ms |
6.3 Ngram 中綴查詢耗時變化
|
查詢詞長度 |
4 |
8 |
12 |
|
大基數 命中 100% NG-03match *25-BA* |
184ms |
1026ms |
2468ms |
|
大基數 命中 100% NG-01 constant score |
3ms |
2ms |
5ms |
|
大基數命中 100%+統計總數 NG-01 constant score+track_total_hits |
4414ms |
11214ms |
18428ms |
七、參考資料
官方文檔 (User Guides)
- ES 官方文檔: Wildcard Query(通配符查詢)
- ES 官方文檔: rewrite
- ES 官方文檔: indices.query.bool.max_clause_count(最大子句數限制)
- ES 官方文檔: Ngram Tokenizer(方案1)
- ES 官方文檔: Search-as-you-type Field(方案2)
- ES 官方文檔: Wildcard Field(方案3)
深入博客(Blog Deep Dives)
- Find strings within strings faster with the Elasticsearch wildcard field
- Elasticsearch Queries, or Term Queries are Really Fast!
- (社區)[Part -1] Search as you type - ashish.one
八、結尾
模糊查詢並非洪水猛獸,真正的風險在於 使用場景不匹配 和 字段類型、索引策略選錯。在超大數據量的實際業務環境中:
Wildcard → 最穩健的通用方案;
Ngram → 高 QPS 中綴場景下的性能極限選手;
Search_as_you_type → 前綴提示的專業方案。
無論選擇哪種方案,最終都取決於你的數據規模、查詢模式和運維能力。
獲取壓測數據 & 加入技術討論
歡迎加入釘釘羣 72335013004,回覆“報告”,即可獲得本次 5000 萬數據壓測的完整數據報告。
入羣還可獲取更多深度避坑指南、內核源碼解讀及高併發壓測報告,與一線研發共同探討最佳實踐。
告別“運維深淵”,把時間還給業務創新
如果你不想因為一次無心的模糊查詢而雪崩,可以考慮阿里雲 ES Serverless:
- 智能限流與熔斷:壞查詢關進籠子,好查詢按需放行
- 內核無感升級:無需手動遷移享受最新性能優化
這樣,你能把時間和精力放在業務創新上,而不是追着故障跑。
立即啓用 阿里雲 ES Serverless,持續迭代內核與智能性能護欄,讓集羣始終穩定高效。