

在 AI 應用快速落地的今天,越來越多企業希望將大模型能力融入數據處理流程——無論是文本分析、智能摘要,還是 RAG 知識庫構建。但傳統模式下,模型部署依賴專業 MLOps 團隊,需自行搭建推理環境、配置 GPU 資源、維護服務穩定性,門檻高、週期長、成本重。
現在,阿里雲 DataWorks 發佈大模型服務能力,基於 Serverless 資源組,支持用户 一鍵部署主流大模型,並可在 數據集成和數據開發任務中直接調用模型 API,實現“部署—集成—使用”全流程閉環,真正讓數據工程師也能輕鬆玩轉大模型!

三步完成模型部署,零代碼上手
通過 DataWorks 大模型服務管理功能,您只需三個步驟即可完成模型上線:
- 選擇模型 支持通義千問 Qwen3 系列、DeepSeek 系列等多種主流模型,涵蓋生成、推理、向量化等場景。
- 一鍵部署 在控制枱點擊“部署”,選擇目標 Serverless 資源組 和 GPU 規格(如 vGPU-1/4、vGPU-1),系統自動完成鏡像拉取、服務啓動與健康檢查。
- 獲取調用地址 部署成功後,自動生成標準 OpenAPI 接口地址和鑑權 Token,可用於後續任務調用。
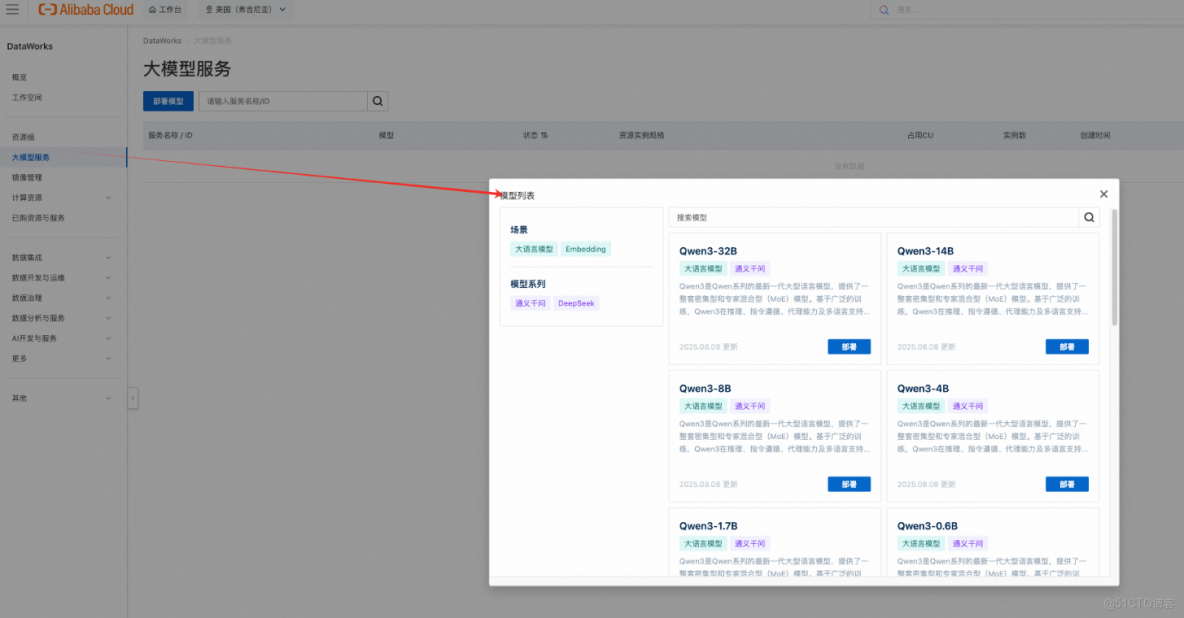
大模型部署頁面
整個過程 無需關注底層資源調度、容器編排或網絡配置,真正做到“點一下,就可用”,大幅降低大模型落地門檻。
核心優勢

得益於底層資源優化與輕量化推理引擎,對於參數規模較小的模型(如 Qwen-Turbo、Embedding 模型),在 Serverless 資源組上的 平均推理延遲顯著降低,性能提升近 10 倍,特別適合高頻、低延遲的在線推理場景。
一鍵開啓數據集成與開發的大模型應用
目前支持在數據集成、數據開發中調用大模型,實現對數據的智能處理。
數據集成中調用
在單表離線同步任務中,可使用大模型服務對同步中的數據進行AI輔助處理。
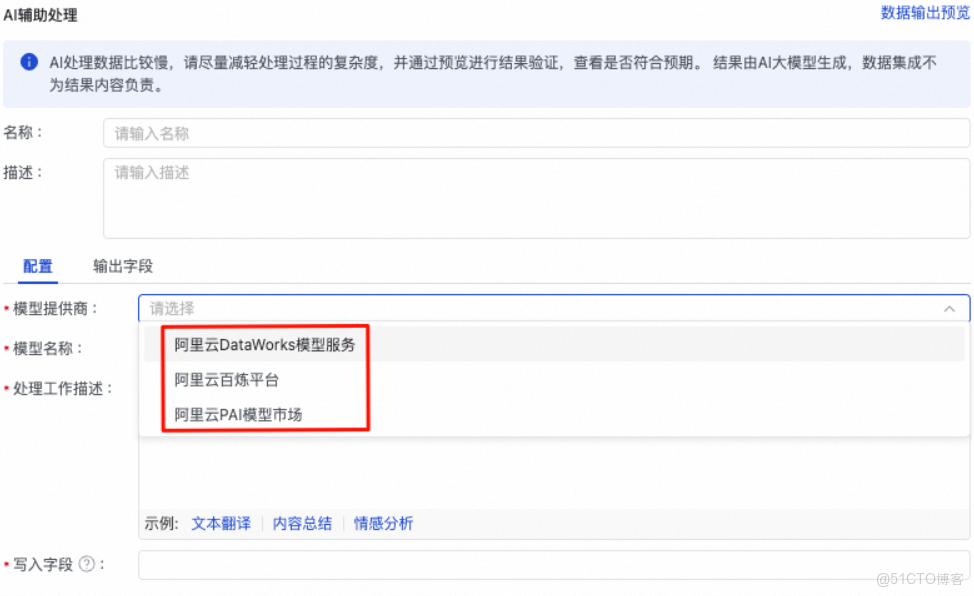
數據開發中調用
方式1、大模型節點調用大語言模型
DataWorks 新版數據開發 Data Studio 提供專屬的大模型節點,支持通過可視化配置方式直接調用已部署的生成類或向量類大模型。用户無需編寫代碼,只需選擇目標模型、輸入提示詞(Prompt)並設置參數,即可完成文本生成、摘要提取或文本向量化等任務,適用於快速驗證模型效果和構建輕量級 AI 流程。
方式2、Shell 節點調用大語言模型
用户可在 Shell 節點中通過 curl 命令調用大模型服務 API,實現對生成模型或向量模型的靈活調用。例如,發送自然語言請求獲取模型回覆,或將文本傳入 Embedding 模型生成向量。該方式適合熟悉命令行操作的開發者,結合調度配置可實現自動化任務執行。
方式3、Python節點調用大語言模型
通過 Python 節點,用户可使用 requests 等庫編寫腳本,以編程方式調用大模型服務。支持流式輸出處理、自定義解析邏輯和複雜業務封裝,適用於寫詩、報告生成、結構化輸出等需要精細控制的場景。需基於自定義鏡像安裝必要依賴後運行,並可集成至完整數據鏈路中。
接下來舉個🌰展示如何在Python節點通過調用大語言模型完成寫詩指令。
- 當前示例依賴Python的
requests庫,請參考以下主要參數,基於DataWorks官方鏡像創建自定義鏡像安裝該依賴環境。
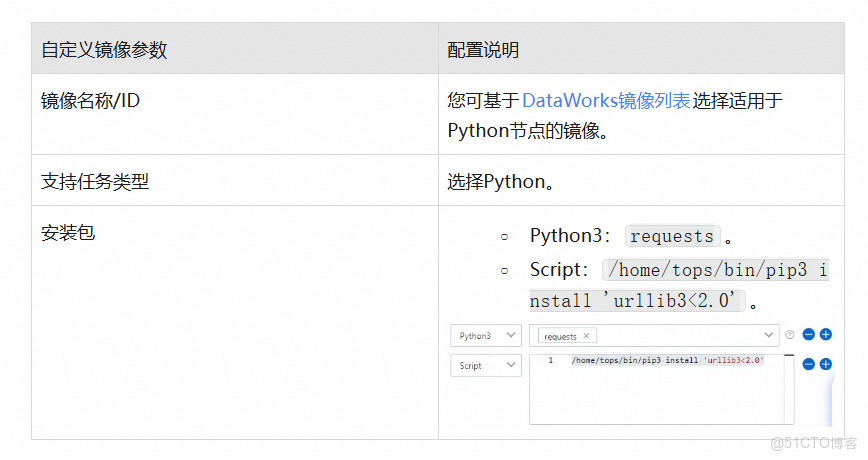
2. 創建Python節點,在Python節點添加如下示例代碼:
import requests
import json
import time
import sys
def stream_print_response():
httpUrl = "http://ms-xxxx.cn-beijing.dataworks-model.aliyuncs.com"
apikey = "DW-ms-xxxx"
url = httpUrl + "/v1/completions"
headers = {
"Authorization": apikey,
"Content-Type": "application/json"
}
data = {
"prompt": "請寫一篇關於春天的詩",
"stream": True,
"max_tokens": 512
}
try:
response = requests.post(url, headers=headers, json=data, stream=True)
response.raise_for_status()
full_text = "" # 累積完整回覆,防止丟失
buffer = "" # 用於處理不完整的 JSON 行(可選)
for line in response.iter_lines():
if not line:
continue # 跳過空行
line_str = line.decode('utf-8').strip()
# print(f"[DEBUG] 收到行: {line_str}") # 調試用
if line_str.startswith("data:"):
data_str = line_str[5:].strip() # 去掉 "data: "
if data_str == "[DONE]":
print("\n[流式響應結束]")
break
# 嘗試解析 JSON
try:
parsed = json.loads(data_str)
choices = parsed.get("choices", [])
if choices:
delta_text = choices[0].get("text", "")
if delta_text:
# 累積到完整文本
full_text += delta_text
# 逐字打印新增的字符
for char in delta_text:
print(char, end='', flush=True)
sys.stdout.flush()
time.sleep(0.03) # 打字機效果
except json.JSONDecodeError as e:
# print(f"[警告] JSON 解析失敗: {e}, 原文: {data_str}")
continue
print(f"\n\n[完整回覆長度: {len(full_text)} 字]")
print(f"[ 完整內容]:\n{full_text}")
except requests.exceptions.RequestException as e:
print(f" 請求失敗: {e}")
except Exception as e:
print(f" 其他錯誤: {e}")
if __name__ == "__main__":
stream_print_response()- 説明:請將代碼中以
http開頭的大模型服務調用地址和以DW開頭的Token信息替換為您的實際值。
3. 編輯節點內容後,在節點編輯頁面右側的調試配置中,選擇已完成網絡連通配置的資源組和步驟1中安裝了requests庫的自定義鏡像。
4. 單擊運行節點,即可調用已部署的服務模型執行相關命令。