

導讀
通過Turing Data Analysis(TDA)一站式自助分析平台建設,實現了業務看數、分析一體化閉環。然而,隨着業務深度使用,分析需求也更加的複雜、多樣,對TDA的分析能力提出了更高的要求,同時用户的極限查詢與性能形成對抗,也影響了用户的分析體驗。本文將聚焦分析能力增強與性能優化兩方面,闡述具體的優化策略,以持續保證用户分析體驗。
01 背景與問題
1.1 TDA概述

通過百度一站式數據自助分析平台(TDA)建設,實現了業務看數、分析一體化閉環:
1\. 業務看板迭代提效(自助化):數據報表迭代模式發生變化,從PM提需RD排期模式逐步轉換為PM/運營自助化操作(做看板/分析數據)
2\. 數據洞察分析提效(極速):單次數據查詢從分鐘級降低到秒級,指標波動分析效率提升20倍,單次指標波動歸因分析端到端從2小時->5分鐘內
3\. 業務一站式自助分析(一站式):實現數據趨勢觀測、維度下鑽分析、明細導出等功能,實現了數據監控、數據分析一體化體驗。
1.2 問題與挑戰
隨着業務深度使用,分析需求也更加的複雜、多樣,對TDA的分析能力提出了更高的要求,同時用户的極限查詢與性能形成對抗,也影響了用户的分析體驗:
1\. 更高的分析能力要求:
a. 更復雜的統計指標計算:業務上需要計算周/月/季/年日均值及與前一週期(上一週/月/季/年)的對比差異值,以及對多行數據彙總合計等,這些更復雜的統計指標計算還無法高效滿足;
b. 分析報告能力:在業務日常的數據使用中,週報/月報等固定週期數據的彙報是一個各業務通用且固定的使用場景。目前各業務多采用數據建設—>儀表盤配置—>人工下載整理—>添加數據結論—>生成周報的流程進行建設,在此過程中,數據整理、結論添加、跨平台整合等工作耗時耗力。
2\. 性能“對抗”:隨着數據量級增長、用户極限的分析(當用户發現查詢變快後,會擴大查詢週期進行更復雜的分析等)與性能形成對抗。
針對上面的問題,我們的解決方案是:
1\. 分析能力增強:
a. 複雜統計指標自動計算:結合業務訴求,將業界通用分析計算方法(時間對比、佔比分析、同環比、合計、日均值、排序、TopN、表計算等)落地到平台,計算方法可以交叉使用,來滿足業務複雜的指標計算訴求。
b. 週報/月報等分析報告能力建設:通過對試點業務週報的分析,總結週報組成(週期圖表數據 + 動態結論包括交叉分析結果及歸因結論),因此通過圖表 + 複雜統計指標計算 + 歸因方法 + 動態富文本,最終生成例行週報,來提高工作效率。
2\. 性能優化:完整的分析過程是,數據建模->引擎查詢->平台二次計算呈現,故需要數倉、引擎和平台三方共建,確定長期監控目標圖表查詢P90及成功率,來長期監控優化。
接下來將從分析能力增強及性能優化展開講述。
02 分析能力增強
2.1 複雜統計指標自動計算
整體思路:複雜統計指標計算能力是以TDA圖表查詢能力為核心,擴展SQL構建算子+數據處理算子,實現不同統計指標計算,靈活可插拔

△ TDA分析計算架構
分析case:分析近一年百億級數據,按月聚合的環同比、日均、合計值
首先,傳統的查詢後處理方式,先查出明細數據,在內存中分組、合併計算。存在以下問題:
1\. 當查詢量級百億時,內存中計算不太可能
2\. 針對於複合指標如d = (a + b) / c,需要分別查出a、b、c的值,在處理;以及更復雜的如 sum( case when city = 'xx' then 1 case when city in ('xx', 'xx') then 2 end),需要解析出SQL語法樹,才能知道計算邏輯,無法保證數據計算準確。
所以,只能設計實現同環比、日均值、合計等SQL構建算子,將計算邏輯拼接到查詢層,整體流程如下:

△ 分析近一年百億級數據,按月聚合的環同比、日均、合計值
其中,環同比核心邏輯是:日期偏移+Join連接,查詢本期數據與上一週期數據(偏移一週期),這樣同維度的數據可以通過Join連接拼接到同一行,基於表列計算實現環同比計算

△ 同環比構建SQL
接着,日均值核心邏輯:
可加型指標(如分發量),日均分發量 = 分發量 / count(distinct 日期);
非可加型指標(如dau、人均分發量等),通過子查詢,先查出按天的明細,再計算按月的日均
為了優化性能,可先識別待計算的指標列表是否包含非可加型指標,若包含再通過子查詢計算實現。
最後,合計核心邏輯:

為了優化性能,通過多協程非阻塞方式併發查詢多個SQL,可以按需使用自動合計,減少查詢的SQL數量。
2.2 週報/月報等分析報告建設
過去週報/月報書寫通過PPT/PDF,採用數據建設—>儀表盤配置—>人工下載整理—>添加數據結論—>生成周報的流程進行建設,在此過程中,數據整理、結論添加、跨平台整合等工作耗時耗力,故我們將週報/月報場景固化為平台分析工具,幫助業務快速構建週報/月報,提高工作效率。
通過對試點業務週報的分析,可以發現業務週報的主要結構為:
1\. 週期數據(文本):按周/月彙總的數據,一般來自於TDA圖表中的某些指標。
2\. 圖表(圖表):TDA中已生成的圖表截圖,或使用TDA中的數據畫一些自定義的圖表
3\. 結論(歸因 + 外部因素,文本):結論包括兩種,一種是基於數據集的交叉分析可以得出的結論;另一種是基於一些客觀事實分析得出的結論,如天氣變化、APP版本更新等。
因此,週報/月報的建設思路:

△ 週報case
1. 動態富文本:文本組件,可以嵌入TDA圖表指標數據、交叉分析數據、歸因數據等動態數據,以及截圖等

△ 動態富文本
相較於傳統PPT/PDF書寫方式,智能週報最大的區別就是動態綁定數據,我們基於Lexical自研了動態富文本,通過宏定義變量綁定圖表、歸因結論等動態數據,通過跨模塊消息通信,解決了動態數據渲染的性能問題,包括靜態和動態分開渲染,減少等待,監聽數據更新,避免重複數據請求,監聽組件更新,避免頻繁保存,提升編輯流暢度等
2. 複雜統計指標計算能力:複雜統計指標自動計算(同環比、日均值、合計等),上一章節已講述
3. 歸因決策能力:歸因思路固化、歸因算法、多級歸因、例行歸因等,下一章節講述
2.3 歸因決策能力建設
每個業務都有自己的一套分析思路,以百家號分析為例:
百家號核心指標波動排查路徑:基於核心指標進行維度波動拆解,一般會進行2-3級拆解分析
如:對分發量(歷史可分發內容)的歸因分析
第一步:維度篩選(內容類型=圖文;賬號類型:禁言)
第二步:定位異常內容垂類(分內容垂類監測數據波動情況,找出波動top2垂類:財經、美食)
第三步:第一層維度歸因(計算各維度各枚舉值自身環比變化率、對垂類整體變化的貢獻度,取top)(①作者粉段(10萬粉段作者)、②發文來源(YY))
第四步:第二層維度歸因(取除自身外的其他12個維度分別計算變化率、貢獻度取top維度)

△ 業務分析樹case
我們期望能提供工具化能力,讓業務可以把自己的分析思路沉澱到平台,形成資產。
所以,歸因決策的整體建設思路是:
以“分析樹”作為分析思路落地的載體,抽象“異常發現”、“維度拆解”、“指標拆解”等通用分析算子,允許用户將業務分析思路固化在平台內形成“分析樹”DAG圖,實現自動的異常發現和分析,並結合數據就緒通知,將分析結論例行輸出展示到分析報告裏。

△ 分析樹示例,數據為測試數據,僅供參考
2.3.1 異動檢測:快速鎖定,“哪裏出了問題”
基於規則:根據業務經驗,基於和之前日期數據的差異百分比來劃定正常波動區間,如日環比、周同比等
基於時序預測算法:計算一個時序數據的置信區間,超出區間外的,則是異常值,算法如Holt-Winters、Prophet
整體檢測的流程如下:

2.3.2 維度歸因:橫向看維度,“問題在哪個羣體”
維度歸因的整體流程如下:

分析類:入口,解析用户歸因配置,確定維度拆解的視角(下鑽、組合、自動選擇),調用查詢類查詢所需的數據,調用歸因算法對數據處理,最終調用輸出類,按照呈現樣式輸出對應的數據格式
算法類:區分指標類型(可加型指標、比例型指標),適用算法不同
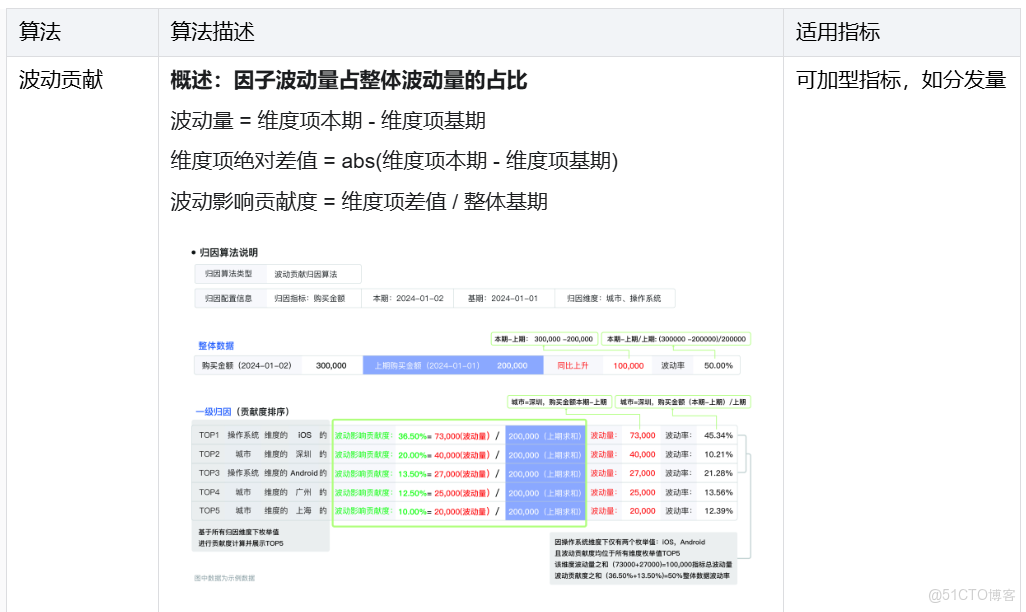


查詢計算類:區分維度歸因視角(下鑽、組合、自動發現),查詢計算方式不同
比如,原始數據:日期、A、B、M(指標)

△ 查詢計算:下鑽、組合、自動發現
2.3.3 指標歸因:縱向看指標,“這個羣體的問題是什麼”
指標歸因的整體流程如下:

1. 乘法指標拆解歸因: 乘法因子貢獻同時也適用於除法指標,只需要為分母建立一個倒數字段即可。
如A = B * C

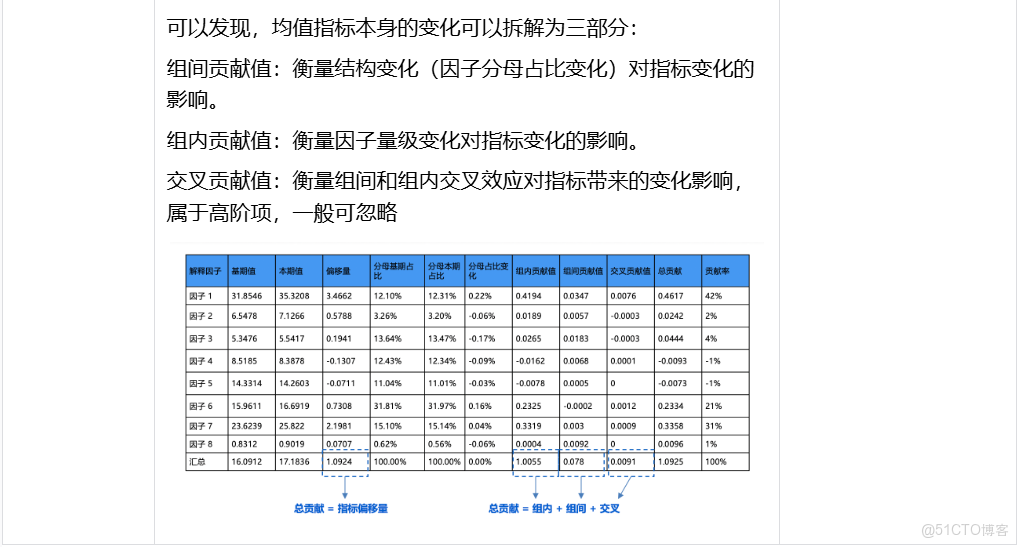
2. 非乘法指標拆解歸因: 在實際業務中核心指標會由由多個指標複雜的四則運算得到,或者沒有公式關係但存在相關性,此時也需要量化評估子指標對核心指標變化的貢獻
線性:如A = B + C - D,使用波動貢獻計算即可
B貢獻率 = ΔB / ΔA
C貢獻率 = ΔC / ΔA
D貢獻率 = -ΔD / ΔA
非線性:如房價和位置,樓層,面積的關係,並無嚴格的數學公式,但是又存在一些相關性。
我們假設一個指標可以表示為若干個相關指標的函數模型f,如:
A = f(B, C)
通過XGBoost進行建模,保證模型可以得到很好的預測效果(儘量貼合真實數據)
再通過SHAP,給出一個可加性的解釋方法
yi=ybase+f(xi,1)+f(xi,2)+⋯+f(xi,k)

03 性能優化
3.1 性能挑戰
1. 平台自身:以主題寬表建設數據集,單天數據量級千萬級;分析複雜度高,按季度查詢同環比、日均值等涉及Join、子查詢、長週期的複雜查詢場景;
2. 用户:數據量級不斷增長,用户會照着性能極限去使用(比如優化過性能後,用户發現查詢變快,會擴大查詢週期),與性能優化形成對抗。
3.2 性能優化方案
完整的分析鏈路:數據建模->引擎查詢->平台二次計算呈現,所以性能的優化也是需要數倉、引擎和平台三方共同推進建設。
整體的優化方案:

△ 數倉、引擎、平台三方共建
1\. 平台從緩存、查詢併發控制等角度優化性能,通過性能診斷工具,監控圖表耗時情況,將診斷結果推送至數倉;

△ 性能診斷工具
- 2\. 數倉建模優化生產高性能數據集接入平台,定期治理一些長尾自定義字段。
- 3\. 引擎給數倉、平台提供能力支持,持續優化查詢性能。80%+的數據集都是用Clickhouse,所以針對Clickhouse重點優化:ClickHouse在百度MEG數據中台的落地和優化
下面重點講一下平台性能優化
3.2.1 分級緩存:CDN緩存、配置緩存、數據緩存
CDN緩存:靜態資源統一接入一站式雲平台fcnap,開啓Http2.0和CDN加速;
配置緩存:儀表盤、圖表等配置接口接入緩存,通過監聽更新事件,異步更新緩存,保證緩存永久最新。
數據緩存:
- 首次查詢:用户首次訪問(緩存穿透),查詢數據庫,然後寫入緩存
- 主動預熱:對於一些固化的看數場景,例如儀表盤,提前把儀表盤圖數據或圖表查詢放到緩存中,用户查看時直接讀取緩存。

△ 緩存預熱
預熱主要分為三部分:預熱生產、預熱消費、預熱監控
預熱生產:確定哪些儀表盤需要預熱,預熱的觸發條件,緩存更新機制等
預熱消費:根據圖表查詢pv,確定消費優先級;高峯時段,預熱任務主動避讓,暫停生產;數據變更,根據血緣查找需更新的圖表。
預熱監控:監控消費隊列的情況,記錄失敗的狀態和原因;監控緩存命中率,調整預熱生產策略。
最終,命中平台緩存的查詢P90耗時優化至幾百ms
3.2.2 與引擎、數倉聯合,實現數據多級聚合
數倉在數據建模層面進行數據聚合,基於大寬表(事實表 \+ 維度表),並結合業務主題抽取出相應的維度聚合表作為CH數據集,為滿足業務側的拖拽式分析

△ CH數據集建設流程
部分公共儀表盤的首屏請求通過平台預熱緩存兜住,而變更儀表盤條件以及下鑽分析的查詢,會穿透到引擎側,所以在引擎側實現了兩層數據聚合:
1\. 引入聚合表:基於Projection實現對查詢中間狀態的預聚合,避免對原始明細數據的大量磁盤掃描;
2\. SQL級緩存:按SQL級粒度,將最終查詢結果緩存在外部內存,縮短查詢鏈路,並避免重複查詢帶來的多餘磁盤IO。

△ 與引擎、數倉聯合,實現多級聚合
平台將高頻歷史查詢,同步到引擎側,協助自動創建Projection,引擎側實現對Projection進行全生命週期自動化管理。
3.2.3 查詢併發:多域名轉發請求,多進程 + 多協程響應請求

△ 併發查詢
瀏覽器併發6限制:通過多域名方式,將圖表請求與其他請求分流,保證平台交互流暢,圖表請求併發度提升,從而提升總體耗時
多進程 \+ 多協程響應請求:單個請求處理時是串行的,但有些邏輯可以並行處理,如計算合計時,原數據SQL + 合計SQL通過協程並行執行,提高查詢性能。
流控限制:多併發可能會帶來引擎高負載問題,除了擴充引擎資源外,平台和引擎聯合對查詢進行流控限制,針對重複請求,引擎側快速快速返回相應狀態,平台根據狀態碼做對應的處理,來避免用户請求太多,導致負載過高,查詢卡死

△ 流控限制
04 總結與展望
通過複雜統計指標自動計算能力、週報/月報等分析報告能力以及歸因決策能力的建設,滿足了業務更高分析能力訴求。通過性能優化,解決了用户分析與性能優化之間的長期“對抗”,來持續保證用户的分析體驗。
目前TDA平台PV日均5w+,其中可視化分析PV佔比70%+,用户已深度使用這套分析能力來解決日常分析訴求
隨着AI的快速發展,我們也在不斷探索BI與AI的融合落地,打造一個Data Agent(數據領域專家智能體),深度運用業務數據資產,實現主動思考、洞察、分析與行動(如自動識別 DAU 異常波動,並自動從維度和指標分別進行歸因分析最終出優化產品功能或調整運營策略的報告建議),推動TDA平台從工具集合升級為智能決策夥伴,讓每個用户都能擁有自主進化的數據大腦,持續釋放數據價值。