









小T導讀:在製造業智能化產線監控實踐中,楊凌美暢早期基於 TDengine TSDB 3.0.7.1 Windows 開源版,支撐了 108 條產線、23 萬測點的基礎監控。隨着業務規模迅速擴大,原有架構的性能與穩定性逐漸成為瓶頸。針對這一挑戰,楊凌美暢組織專項攻關,引入 TDengine TSDB 企業版 3.3.6.10 Linux,並重構時序數據處理架構與數據模型。目前系統已穩定接入 500 條產線、150 萬測點,實現查詢耗時穩定 ≤1 秒,告警全鏈路(從故障發生、數據寫入、流計算處理到應用推送)時延 ≤10 秒。同時為擴展至 800 條產線預留了充足性能冗餘,數據處理能力與業務適配性實現了質的飛躍。本文對此實踐展開深入分享。
業務目標與痛點
在智能化產線的建設過程中,楊凌美暢始終圍繞“產線全週期數據管理”這一核心目標推進數字化升級。企業對數據系統的業務訴求主要集中在以下三個方面:
- 首先是產線實時監控。目前公司已部署 500 條產線,每條產線配備 4 個 PLC 設備,總計約 150 萬測點,需要實時採集電壓、電流、温度等關鍵數據,並在監控室同步展示設備運行狀態。一旦出現異常,系統必須能快速觸發告警。
- 其次是生產效能分析。企業需要保留 2 年曆史數據,用於開展產線優化分析,包括設備故障的根因追溯、產能波動的對比研究,從而為生產效率的提升提供數據支撐。
- 最後是業務高可用。產線必須 7×24 小時不間斷運轉,這就要求數據處理系統全年保持 99.99% 的可用性。同時,實時數據備份和災難恢復機制也至關重要,以確保數據安全和連續生產。
然而,在實際運行中,現有系統暴露出多方面的痛點和挑戰:
- 高可用缺失,業務連續性無保障。 作為製造業企業,我們的產線需 7×24 小時不間斷運轉,對業務連續性要求極高。早期基於 TDengine TSDB 開源版搭建的系統,在初期階段完全能夠滿足生產需求。但隨着產線規模和數據體量快速增長,單機單副本的部署模式逐漸難以支撐更高層級的連續性要求——例如在硬件或數據庫發生異常時,系統可能需要較長時間才能恢復。與此同時,開源版主要提供了基礎的備份工具,適合一般場景,但在我們這種大規模連續生產環境下,就需要更完善的自動化備份與恢復機制。曾經在一次備份失敗的情況下,企業內部排查和修復過程較為耗時,影響了部分歷史數據的完整性,也讓我們更加意識到高可用和容災機制的重要性。
- 性能與功能不足,支撐規模受限。隨着業務需求增加,接入的產線數量不斷擴充,從最開始的 108 條,逐步增加到現在的 500 條,未來還計劃擴展到 800 條,對應的測點數量也從 23 萬增長到 150 萬,並且還會持續增加。在這一過程中,基於開源版的單機架構在起步階段表現良好,但隨着數據體量和實時性要求不斷提升,逐漸顯現出侷限。在大規模產線數據處理時,查詢耗時會出現一定波動:快的時候可在 1 秒內返回,但在高負載場景下可能延長至幾十秒。這種不穩定性在日常監控中尚可接受,但對於異常檢測和快速響應等關鍵業務,就需要更高層級的性能保障。
- 高保障不足,升級遷移風險大。因業務連接性要求,數據遷移、系統升級以及數據恢復都面臨諸多難題,不能因這些操作導致生產停機或中斷,否則會造成巨大經濟損失。開源版缺乏原廠保障,遷移需人工導出導入,耗用資源較高且耗時較長,可能影響生產環境正常運行,若操作過程中出現異常,會進一步延長業務中斷時間。
綜上,隨着業務規模的不斷擴張和智能化水平的提升需求,現有架構的侷限性愈發明顯。如何在保障業務連續性的前提下,提升系統的高可用性、性能和可擴展性,成為我們當下必須解決的關鍵問題。
2025 年 5 月,我司決定引入 TDengine TSDB 企業版,從根本上解決時序數據處理系統歷史問題,併為後續產線擴充,打下堅實基礎
基於企業版的高可用架構設計
從業務目標出發,依託 TDengine TSDB 3.3.6.10 企業版專屬功能,我們構建了 “Linux 操作系統 + 數據雙副本 + 自動化數據備份” 的高可用系統架構,徹底解決開源版單機單點風險,系統可用性相較於開源版架構有了極大的提升,滿足 99.99% 業務連續性需求。
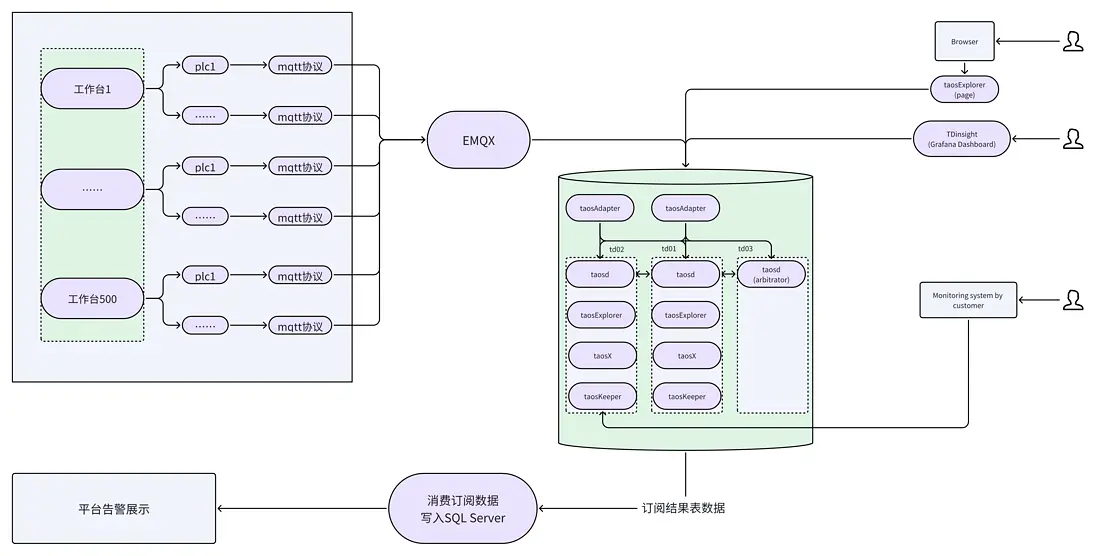
- Linux 操作系統適配:替換原 Windows 系統為 Ubuntu Linux 操作系統,提升系統穩定性與資源利用率,為高可用架構奠定底層基礎;
- 雙副本數據冗餘功能:通過 TDengine TSDB 企業版 “雙副本” 功能,在成本可控基礎上,實現數據副本冗餘,任一節點異常時,另一節點可無縫接管服務,避免數據丟失或停服;
- 自動化數據備份保障:依託 TDengine TSDB 企業版 “備份管理” 專屬功能,制定 “每日增量備份”策略,通過備份工具,每天 0 點進行備份,且可以指定備份服務節點和使用磁盤空間目錄,備份過程可通過企業版管理頁面可視化配置,支持備份任務監控與日誌查詢,徹底解決開源版 “手工備份” 問題。
基於企業版的高性能優化
數據庫及模型設計優化
1. 數據庫建模優化
CREATE DATABASE `iot` BUFFER 256 CACHESIZE 1 CACHEMODEL 'none' COMP 2 DURATION 1440m WAL_FSYNC_PERIOD 3000 MAXROWS 4096 MINROWS 100 STT_TRIGGER 1 KEEP 5256000m,5256000m,5256000m PAGES 256 PAGESIZE 4 PRECISION 'ms' REPLICA 3 WAL_LEVEL 1 VGROUPS 10 SINGLE_STABLE 0 TABLE_PREFIX 0 TABLE_SUFFIX 0 TSDB_PAGESIZE 4 WAL_RETENTION_PERIOD 3600 WAL_RETENTION_SIZE 0 KEEP_TIME_OFFSET 0 ENCRYPT_ALGORITHM 'none' S3_CHUNKSIZE 262144 S3_KEEPLOCAL 5256000m S3_COMPACT 0 - 分片優化:建庫參數 VGROUPS 調整為 20,目前有 108 個工作台的 PLC 數據接入,最終可能接入 800 個工作台的 PLC 數據,跟進最大數據接入情況,預估創建 20 個 vnode,每個 vnode 使用單獨讀寫線程,充分利用計算資源,使得性能最大化。
- 分區優化:建庫參數 DURATION 調整為 10d,將分區長度調整為 10 天,10 天一個數據文件組,便於快速檢索、定位到具體的文件,無需遍歷搜索。
- 寫入緩存:建庫參數 BUFFER 調整為 256,一個 vnode 寫入內存池的大小,批次落盤,優化數據寫入速度。
2. 超級表建模優化
- 模型重構核心思路
我們的原有設計未使用超級表,108 條產線對應 1420 張普通表,查詢需遍歷多張表,效率極低。升級後基於 “設備類型 + 業務場景” 劃分超級表,共 13 張超級表,大幅提升查詢效率。
核心超級表示例:
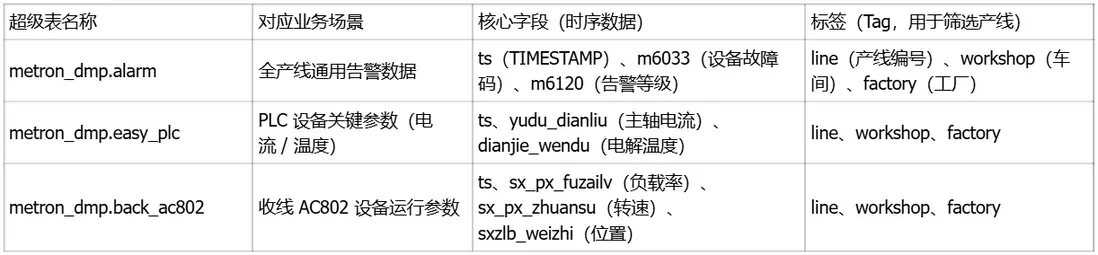
-
模型優化效果
- 查詢效率:篩選某車間 10 條產線的 1 天告警數據,由於此前應用的開源版未使用超級表,只能遍歷 140 張普通表,耗時 12 秒;企業版通過超級表標籤篩選,耗時 0.5 秒,效率提升 23 倍;
- 擴展能力:新增產線時,僅需在對應超級表下創建子表(繼承標籤與結構),500 條產線場景下,新增產線更加便捷,無需修改表結構。
查詢優化
優化調整查詢 SQL,利用超級表和標籤索引快速定位數據,減少查詢耗時,例如:
- 單產線查詢:查詢某條產線 1 天內的 PLC 電流數據(約 8.6 萬條),優化前耗時 1.5 秒,優化後耗時 0.3 秒;
- 多產線聚合查詢:查詢某車間 100 條產線 1 個月的平均產能,優化前耗時 12 秒,優化後耗時耗時 0.8 秒;
- 歷史數據查詢:查詢某產線 6 個月前的故障告警記錄,優化前該場景因歷史數據保存週期無法實現,優化後耗時僅 0.9 秒。
流計算告警優化
在最初的設備告警流程中,系統需要通過時序數據庫輪詢查詢數據,再由應用層進行比對,最後將告警結果寫入 SQL Server 觸發告警。整個鏈路涉及多個處理環節,技術複雜度高,告警延遲也較大。
在優化後,告警邏輯直接依託 TDengine TSDB 的流計算功能實現,數據比對與告警觸發均在數據庫內部完成,大幅簡化了處理流程,不僅降低了系統複雜度,也顯著提升了告警響應的實時性和穩定性。
create stream front_ac802_alarm_stream trigger at_once into metron_dmp_stream.alarm tags(line varchar(20), workshop varchar(20), factory varchar(20)) subtable(tname) as select _wstart as ts,last_row( m6033 ) as m6033,last_row( m6120 ) as m6120,last_row( m6121 ) as m6121,…… from metron_dmp.alarm partition by tbname tname, line, workshop, factory STATE_WINDOW(cast(case when m6033 is null then 0 else m6033 end + case when m6120 is null then 0 else m6120 end + case when m6121 is null then 0 else m6121 end + …… as int));- 流計算配置:基於metron_dmp.alarm超級表創建流計算,觸發模式設為 “實時觸發”,聚合故障碼與告警等級,結果寫入metron_dmp_stream.alarm結果表;
- 告警流程:應用通過數據訂閲功能監聽結果表,獲取實時告警數據後直接推送至監控大屏,無需中間數據庫中轉;
- 效果:告警從 “故障發生→數據寫入→流計算處理→應用推送” 全程 ≤10 秒,原方式需 21-44 秒,效率提升 3 倍左右。
基於企業版的高保障專業服務
歷史數據遷移(從開源版到企業版)
1. 遷移挑戰
需同步開源版 108 條產線的恢復的歷史數據,且不能影響現有產線的實時數據採集。
2. 遷移方案(無停機)
我們依託 TDengine TSDB 企業版原生工具 taosX 的實時數據同步功能,實現了無感知升級:在新集羣(企業版)完成部署後,taosx 會自動且持續地同步歷史數據與實時數據;待歷史數據同步完畢,僅需通過配置調整數據接入指向,即可無縫切換至新集羣。整個過程無需停機,業務查詢也能保持正常,保障了生產業務連續性。
- 跨版本、跨系統同步: 藉助 taosX,實現了從 Windows → Linux 的數據遷移,並支持不同版本間的平滑升級。
- 表結構同步:先同步超級表與子表結構,確保數據模型一致。示例:
taosx run -f "taos+ws://windows_ip:6041/dmp?schema=only&./tables=@table_list.txt" -t "taos+ws://linux_ip:6041/metron_dmp"- 增量數據同步: 歷史數據按時間分片遷移,每次同步 1 天的數據,避免對源端造成過大壓力,同時保持實時寫入不斷流。示例:
taosx run -f "taos+ws://windows_ip:6030/dmp?schema=none&tables=@./table_list.txt&start=2025-05-01T00:00:00+0800&end=2025-05-02T00:00:00+0800&workers=48" -t "taos://linux_ip:6030/metron_dmp"- 數據校驗: 同步完成後,隨機抽取 10 條產線 × 100 條數據,逐一比對源端與目標端,確認數據完整性 100%。
- 遷移結果:耗時 48 小時完成 108 條產線歷史數據同步,遷移期間實時數據寫入無丟包,業務查詢正常。
高效快捷的實施服務
在濤思與楊凌美暢的緊密協作下,整個實施過程僅用 11 天就完成了從數據同步、集羣部署到副本切換的全流程,高效推動了 TDengine TSDB 企業版在生產環境的平穩落地。
同時,濤思數據還提供企業級專屬維保服務:每月一次例行巡檢,藉助企業版巡檢工具對 CPU、內存、磁盤 IO 及集羣運行狀態進行全面檢查,提前發現並預警潛在風險;並提供 7×24 小時技術支持,第一時間響應業務諮詢與問題處置。通過這一系列措施,切實保障了我司生產系統的穩定可靠運行。
未來規劃
隨着產線規模的持續擴充,我們將充分發揮 TDengine TSDB 企業版的橫向擴展能力,通過在線增加節點,進一步提升系統的數據處理與支撐能力。
同時,我們也計劃引入濤思數據推出的 TDengine IDMP(AI 原生的工業數據管理平台)。該平台採用經典的樹狀層次結構對傳感器與設備數據進行組織,建立統一的數據目錄,並對數據進行語境化與標準化處理,並提供實時分析、可視化、事件管理與報警等功能。藉助 IDMP,我們能夠進一步強化設備管理與生產分析水平,為未來的智能化運營奠定堅實基礎。
關於楊凌美暢
楊凌美暢新材料股份有限公司(證券代碼:300861)成立於 2015 年 7 月,是一家主要從事電鍍金剛石線及其他金剛石超硬工具研發、生產、銷售的高科技創新型企業。公司核心產品是電鍍金剛石線,目前已廣泛應用在光伏產業(單晶、多晶硅切方切片)、藍寶石、磁性材料、陶瓷、水晶等高價值硬脆材料的切割領域。
作者 | 楊凌美暢工業研發團隊 凡銀生、邵強

