

Grab 是東南亞領先的超級應用,業務涵蓋外賣配送、出行服務和數字金融,覆蓋東南亞八個國家的 800 多個城市,每天為數百萬用户提供一站式服務,包括點餐、購物、寄送包裹、打車、在線支付等。
為了優化 Spark 監控性能,Grab 將其 Spark 可觀測平台 Iris 的核心存儲遷移至 StarRocks,實現了顯著的性能提升。新架構統一了原本分散在 Grafana 和 Superset 的實時與歷史數據分析,減少了多平台切換的複雜性。得益於 StarRocks 的高性能查詢引擎,複雜分析的響應速度提升 10 倍以上,物化視圖和動態分區機制有效降低運維成本。此外,直接從 Kafka 攝取數據簡化了數據管道架構,使資源使用效率提升 40%。
作者:
Huong Vuong, Senior Software Engineer, Grab
Hai Nam Cao, Data Platform Engineer, Grab
一、Iris——Grab 的 Spark 可觀測性平台介紹
(一)Iris 的作用
Iris 是 Grab 開發的定製化 Spark 作業可觀測性工具,在作業級別收集和分析指標與元數據,深入洞察 Spark 集羣的資源使用、性能和查詢模式,提供實時性能指標,解決了傳統監控工具僅在 EC2 實例級別提供指標的侷限,使用户能按需訪問 Spark 性能數據,助力更快決策和更高效的資源管理。
(二)Iris 面臨的挑戰
隨着業務發展,Iris 暴露出一些問題:
- 分散的用户體驗與訪問控制:可觀測性數據分散在 Grafana(實時)和 Superset(歷史),用户需切換平台獲取完整視角,且 Grafana 對非技術用户不友好,權限控制粒度粗。
- 運營開銷:離線分析數據管道複雜,涉及多次跳轉和轉換。
- 數據管理:管理 InfluxDB 中的實時數據與數據湖中的離線數據存在困難,處理字符串類型元數據時問題尤為突出。
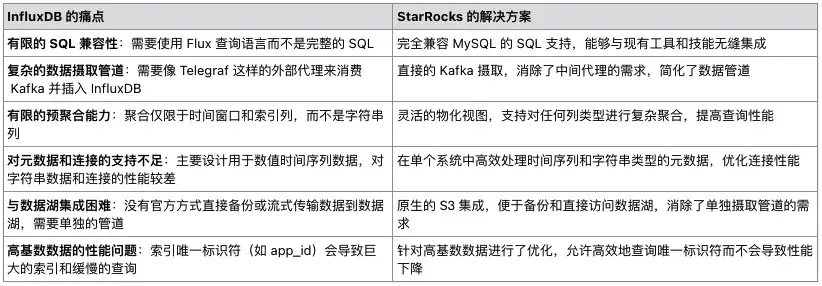
二、系統架構概覽
(一)架構調整
為解決上述問題,Grab 對架構進行重大調整,從 Telegraf/InfluxDB/Grafana(TIG)堆棧轉向以 StarRocks 為核心的架構。新架構包括以下關鍵組件:
(圖1. 集成了 StarRocks 的新 Iris 架構)
- StarRocks 數據庫:替代 InfluxDB,存儲實時和歷史數據,支持複雜查詢。
- 直接 Kafka 攝入:StarRocks 直接從 Kafka 獲取數據,擺脱對 Telegraf 的依賴。
- 定製 web 應用(Iris UI):取代 Grafana 儀表板,提供集中、靈活的界面和自定義 API。
- Superset 集成:繼續保留並連接 StarRocks,提供實時數據訪問,與自定義 Web 應用保持一致。
- 簡化的離線數據處理:StarRocks 直接定期備份到 S3,簡化了之前複雜的數據湖管道。
(二)關鍵改進
新架構帶來諸多改進:
- 統一的數據存儲:實時和歷史數據統一存儲,便於管理和查詢。
- 簡化的數據流:減少數據傳輸環節,降低延遲和故障點。
- 靈活的可視化:自定義 Web 應用提供符合用户角色需求的直觀界面。
- 一致的實時訪問:保證自定義應用和 Superset 之間數據一致性。
- 簡化的備份和數據湖集成:支持直接備份至 S3,簡化數據湖集成流程。
三、數據模型與數據攝取
(一)使用場景
Iris 可觀測性系統主要針對 “集羣觀測” 場景,涵蓋臨時使用(團隊用户共享預創建集羣)和作業執行(每次提交作業創建新集羣)兩種情況。
(二)關鍵設計要點與表結構
針對每個集羣,捕獲元數據和指標,主要包含集羣元數據、集羣 Worker 指標、集羣 Spark 指標三類表:
- 集羣元數據:記錄集羣相關的各類元數據信息,如報告日期、平台、Worker UUID、集羣 ID、作業 ID 等。
- 集羣 Worker 指標:存儲 Worker 的 CPU 核心數、內存、堆使用字節數等指標數據。
- 集羣 Spark 指標:包含 Spark 應用的各種運行指標,如記錄讀寫數量、字節讀寫量、任務數量等。
(三)從 Kafka 攝取數據至 StarRocks
利用 StarRocks 的 Routine Load 功能從 Kafka 導入數據,如為集羣工作節點指標創建 routine load 作業,持續從指定 Kafka 主題攝取數據並進行 JSON 解析。StarRocks 提供內置工具監控例行加載任務,可通過特定查詢查看加載狀態。
四、統一系統處理實時與歷史數據
新的 Iris 系統採用 StarRocks 高效管理實時和歷史數據,並通過以下三個關鍵特性實現:
1.實時數據攝取
- 利用 StarRocks 的 Routine Load,實現從 Kafka 近乎實時的數據攝取。
- 多個加載任務並行消費不同分區的 topic,使數據在採集後的幾秒內即可進入 Iris 表。
- 這一快速攝取能力確保監控信息的時效性,讓用户能夠隨時掌握 Spark 作業的最新狀態。
2.歷史數據存儲與分析
- StarRocks 作為持久化存儲,保存元數據和作業指標,並設置數據存活時間(TTL)超過 30 天。
- 這使我們能夠直接在 StarRocks 中分析過去 30 天的作業運行情況,查詢速度遠超基於數據湖的離線分析。
3.物化視圖優化查詢性能
- 我們在 StarRocks 中創建了物化視圖,用於預計算和聚合每次作業運行的數據。
- 這些視圖整合元數據、工作節點指標和 Spark 指標,生成即用型的摘要數據。
- 這樣,在 UI 中訪問作業運行概覽時,無需執行復雜的 Join 操作,提高 SQL 查詢和 API 請求的響應速度。
這一架構相比以 InfluxDB 為基礎的舊系統有顯著提升:
- 作為時序數據庫,InfluxDB 不擅長處理複雜查詢和 Join 操作,導致查詢性能受限。
- InfluxDB 不支持物化視圖,難以創建預計算的作業運行摘要 (job-run summary)。
- 過去,我們需要藉助 Spark 和 Presto 在數據湖中查詢過去 30 天的作業運行情況,速度遠不及直接查詢 StarRocks。
五、查詢性能與優化
(一)物化視圖
- 核心特性:StarRocks 支持同步(SYNC)和異步(ASYNC)物化視圖,Grab 主要使用 ASYNC 視圖,因其支持多表 Join,對作業運行摘要至關重要。可靈活配置視圖刷新方式,如即時刷新或按時間間隔刷新。
- 分區 TTL:通過設置分區存活時間(Partition TTL),通常為 33 天,控制歷史數據存儲量,保證物化視圖高性能,避免過多佔用存儲空間,同時確保快速訪問近期歷史數據。
- 選擇性分區刷新:允許僅刷新物化視圖特定分區,降低維護視圖最新狀態的計算開銷,尤其適用於大型歷史數據集。
(二)分區策略
表按日期分區,便於高效裁剪歷史數據,查詢近期作業或特定時間範圍數據時,排除無關分區,減少掃描數據量,加快查詢速度。
(三)動態分區策略
利用 StarRocks 的動態分區功能,新數據到達時自動創建分區,數據過期時自動刪除舊分區,無需人工干預即可維持最佳查詢性能。可通過特定 SQL 命令檢查表的分區狀態,對於超過 30 天的數據,使用每日定時任務備份至 Amazon S3,之後映射到數據湖表,不影響核心可觀測性系統性能。
(四)數據副本機制
StarRocks 採用多節點數據複製策略,該設計在容錯能力和查詢性能兩方面都至關重要。這一策略支持並行查詢執行,從而加快數據檢索速度。特別是在前端查詢場景中,低延遲對用户體驗至關重要。這種方法與其他分佈式數據庫系統(如 Cassandra、DynamoDB 以及 MySQL 的主從架構)中的最佳實踐一致。
六、統一的 Web 應用程序
(一)後端
使用 Golang 構建,連接 StarRocks 數據庫,查詢原始表和物化視圖數據,負責身份驗證和權限管理,保障用户數據訪問權限。
(二)前端
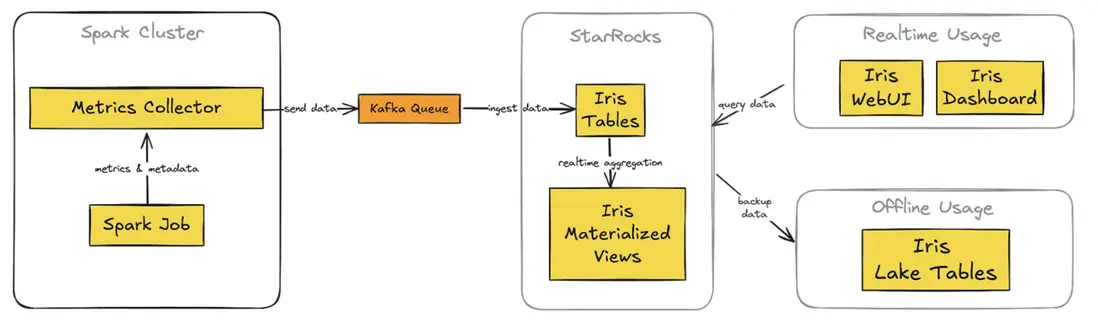
提供多個關鍵界面,如任務運行列表、任務狀態、任務元數據等,任務概覽頁面展示關鍵摘要信息,幫助用户快速瞭解 Spark 任務運行和資源利用情況。
(圖2:作業總覽界面示例)
七、高級分析與洞察
(一)歷史運行分析
創建物化視圖聚合過去 30 天任務運行數據,包含運行次數、各類資源使用的 p95 值等指標,為分析任務趨勢提供數據支持。以下為示例:
CREATE MATERIALIZED VIEW job_run_summaries_001
REFRESH ASYNC EVERY(INTERVAL 1 DAY)
AS
select platform,
job_id,
count(distinct run_id) as count_run,
ceil(percentile_approx(total_instances, 0.95)) as p95_total_instances,
ceil(percentile_approx(worker_instances, 0.95)) as p95_worker_instances,
percentile_approx(job_hour, 0.95) as p95_job_hour,
percentile_approx(machine_hour, 0.95) as p95_machine_hour,
percentile_approx(cpu_hour, 0.95) as p95_cpu_hour,
percentile_approx(worker_gc_hour, 0.95) as p95_worker_gc_hour,
ceil(percentile_approx(driver_cpus, 0.95)) as p95_driver_cpus,
ceil(percentile_approx(worker_cpus, 0.95)) as p95_worker_cpus,
ceil(percentile_approx(driver_memory_gb, 0.95)) as p95_driver_memory_gb,
ceil(percentile_approx(worker_memory_gb, 0.95)) as p95_worker_memory_gb,
percentile_approx(driver_cpu_utilization, 0.95) as p95_driver_cpu_utilization,
percentile_approx(worker_cpu_utilization, 0.95) as p95_worker_cpu_utilization,
percentile_approx(driver_memory_utilization, 0.95) as p95_driver_memory_utilization,
percentile_approx(worker_memory_utilization, 0.95) as p95_worker_memory_utilization,
percentile_approx(total_gb_read, 0.95) as p95_gb_read,
percentile_approx(total_gb_written, 0.95) as p95_gb_written,
percentile_approx(total_memory_gb_spilled, 0.95) as p95_memory_gb_spilled,
percentile_approx(disk_spilled_rate, 0.95) as p95_disk_spilled_rate
from iris.job_runs
where report_date >= current_date - interval 30 day
group by platform, job_id;(二)推薦 API
基於趨勢分析結果構建推薦 API,提供優化建議,如調整資源分配、識別潛在瓶頸或修改調度策略,以優化成本和性能。
(三)前端集成
我們的 API 生成的推薦結果已集成到 Iris 前端。用户可以在任務概覽或詳情頁面直接查看這些建議,從而獲得可執行的優化指導,提升 Spark 任務的效率。
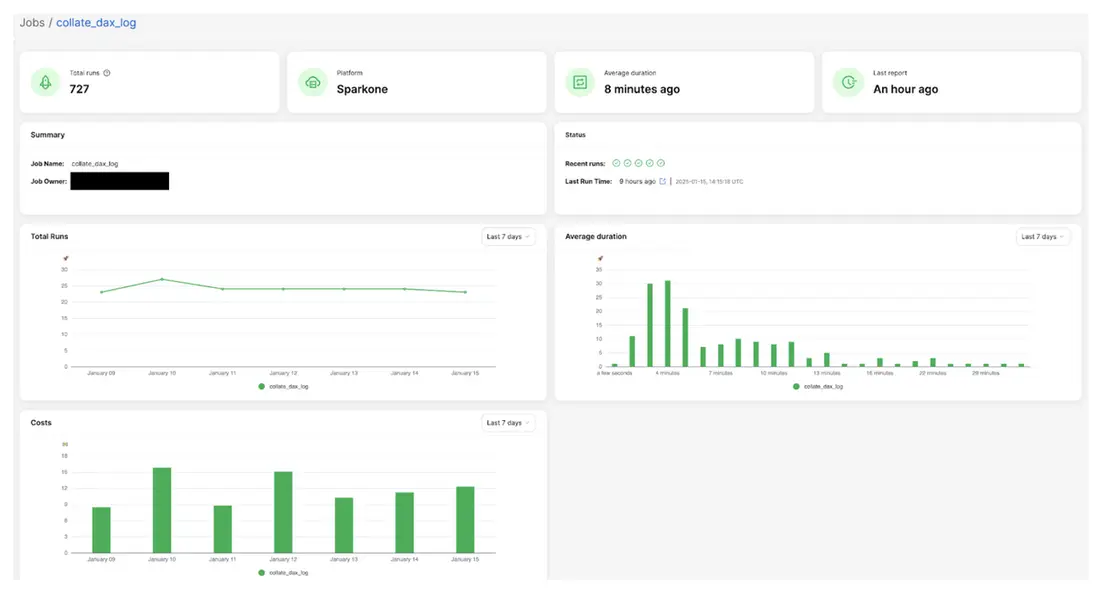
以下是一個示例:如果某個任務的資源利用率長期低於 25%,系統會建議將工作節點的規模縮小一半,以降低成本。

(圖3:資源利用率較低的作業示例)
(四)Slackbot 集成
為了讓這些洞察更加便捷可用,我們將推薦系統集成到了 SpellVault(Grab 的生成式 AI 平台)應用中。這樣,用户可以直接在 Slack 上與推薦系統交互,無需頻繁訪問 Iris Web 界面,也能隨時獲取任務性能信息和優化建議。
八、遷移與推廣
(一)遷移策略
將實時 CPU/內存監控圖表從 Grafana 完全遷移到新的 Iris UI。
遷移完成後,將棄用 Grafana 儀表盤。
繼續保留 Superset 以支持平台指標和特定的 BI 需求。
(二)用户引導與反饋
Iris 已部署在 One DE 應用中,集中化管理數據工程工具的訪問。
UI 中的反饋按鈕使用户可以輕鬆提交意見和建議。
九、經驗總結與未來規劃
以 StarRocks 為核心開發的 Iris Web 應用,為 Grab 的 Spark 觀測能力帶來革命性提升,實現作業級別的成本分攤機制。未來,Grab 期待在高級分析和機器學習驅動的洞察方面取得突破,推動數據工程發展。
(一)經驗總結
- 統一數據存儲:使用 StarRocks 作為實時和歷史數據的單一數據源,顯著提升了查詢性能並優化了系統架構。
- 物化視圖:利用 StarRocks 的物化視圖進行預聚合,大幅加快了 UI 端的查詢響應速度。
- 動態分區:實施動態分區機制,隨着數據量增長自動管理數據保留,保持最佳性能。
- 直接 Kafka 攝取:StarRocks 直接從 Kafka 獲取數據,簡化了數據管道,降低了延遲和複雜性。
- 靈活的數據模型:相比之前基於時間序列的 InfluxDB,StarRocks 的關係型數據模型支持更復雜的查詢,同時簡化了元數據管理。
(二)未來規劃
- 增強推薦系統:擴展推薦功能,提供更深入的優化建議,例如識別潛在瓶頸,並推薦 Spark 任務的最佳配置,以提升運行效率並降低成本。
- 高級分析:利用完整的 Spark 任務指標數據,深入分析任務性能和資源使用情況。
- 集成擴展:加強 Iris 與其他內部工具和平台的集成,提高用户採用率,確保數據工程生態系統的無縫體驗。
- 機器學習集成:探索將機器學習模型應用於 Spark 任務的預測性分析,以優化性能。
- 可擴展性優化:持續優化系統,以支持不斷增長的數據量和用户負載。
- 用户體驗提升:基於用户反饋持續改進 Iris UI/UX,使其更加直觀和信息豐富。
為提升可讀性,本文對技術細節進行了精簡,如需查看完整 SQL 示例及實現細節,請參閲原文:https://engineering.grab.com/building-a-spark-observability