









導讀:
開源無國界,在本期 “StarRocks 全球用户精選案例” 中,我們走進印度即時零售品牌 Zepto。
這家以 “10 分鐘送達” 聞名的公司,業務已覆蓋 50+ 城市、45,000+ 商品,品類橫跨生鮮雜貨、電子產品、美妝個護、服飾、玩具等。憑藉前沿技術與戰略佈局的前置倉網絡,Zepto 在短短几年間徹底改變了印度的即時零售格局。
隨着規模擴張,Zepto 藉助 StarRocks 從 Postgres MVP 升級為生產級實時分析平台,單表每日導入 3000 萬+ 行數據,在品牌看板上實現亞秒級查詢,幫助品牌合作伙伴從“日報表”邁向 準實時洞察,快速響應市場、智慧決策。
在 Zepto 的用户體驗中,品牌始終佔據着核心位置。我們依託豐富多元的商品目錄,不僅滿足了消費者的多樣化偏好,也為品牌提供了跨城市的廣泛觸達。每天,Zepto 處理着數百萬條數據,從商品瀏覽到城市級銷售,全方位呈現產品在不同區域的表現。
然而,真正的挑戰不是“有沒有數據”,而是“如何把數據轉化為可執行的洞察”。這正是 Zepto Brand Analytics 發揮作用的地方。它專為快節奏的即時零售場景而生,能夠快速、直觀地幫助品牌識別趨勢、優化表現,並實時做出更明智的決策。在瞬息萬變的市場裏,唯有敏捷才能贏得先機。
“如何在不讓合作品牌久等、又不對數據過度簡化的情況下,提供實時、可執行的洞察?”
基於這個問題,Zepto 推出了 Brand Analytics —— 一個專為品牌打造的數據看板,提供豐富的數據,包括:
- 銷售走勢
- 庫存情況
- 搜索趨勢與用户轉化
- 子品類層面的表現
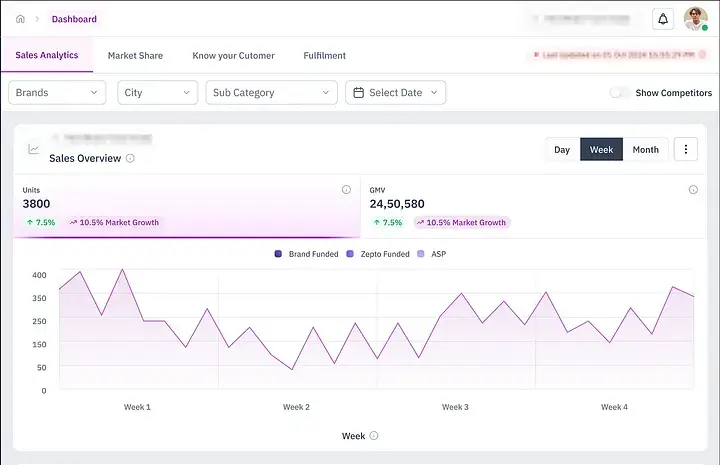
MVP 階段:用 PostgreSQL 快速起步
就像大多數初創團隊一樣,我們在起步階段選擇了輕量靈活的方式。Brand Analytics 的第一個版本搭建在 PostgreSQL 上 ,讓我們能夠快速上線產品,並從一批早期合作品牌中收集反饋。
當時,我們已經能在品牌、城市、商品等維度上追蹤 GMV、銷量等核心指標。彼時的核心銷售表僅有幾百萬行數據,PostgreSQL 能輕鬆應對。
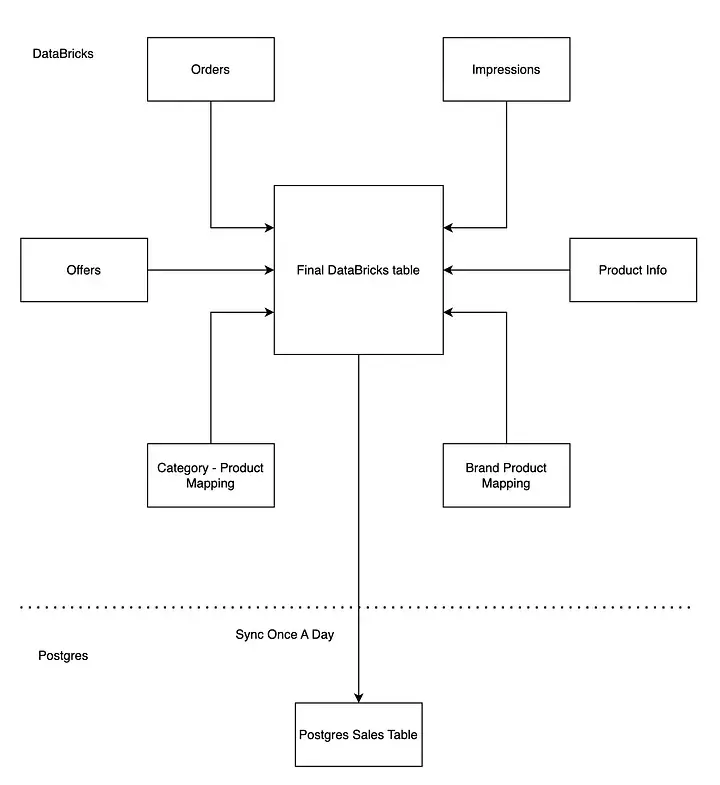
我們的分析團隊選擇了 Databricks 來管理和維護數據表。它既具備筆記本的靈活性,又擁有大數據處理的強大擴展能力,能輕鬆應對複雜查詢和高效管道的構建。同時,Databricks 與 Delta Lake 深度集成,為 Lakehouse 架構提供了堅實的基礎。
在最初階段,我們的架構設計十分簡潔:將訂單、曝光、商品信息等多張表在 Databricks 中進行關聯,生成一張統一的銷售表,類似星型模型。隨後,通過每日定時任務把數據同步至 Postgres。我們的首要目標是快速上線驗證概念,以便第一時間收集品牌的使用反饋。對於早期需求來説,每日同步已經足夠。
不過,直接讓 Databricks 驅動前端界面並不可行 —— 它的響應時間過長,併發能力有限,難以保障用户體驗。即便只是階段性的過渡方案,Postgres 滿足了我們對快速響應的需求。
快進:成長的陣痛
短短一段時間裏,業務發生了翻天覆地的變化:
- 加入平台的品牌越來越多
- 合作伙伴高度依賴分析看板來做業務決策,使用量激增
- 商品目錄急速擴張,SKU 和品類呈指數級增長
很快,我們的數據量突破了 2 億行交易記錄,並且仍在快速增加。這時候,Postgres 開始力不從心。
作為主要面向 OLTP 工作負載的數據庫,Postgres 在應對品牌夥伴需要運行的那類複雜、大規模分析查詢時,逐漸表現吃力。
所以,我們需要一個專為大規模數據分析而構建的 OLAP 系統,來支撐高速、複雜的查詢場景。
分析願景清單
在轉型之際,我們清楚地意識到必須升級架構,並明確了幾項關鍵要求:
- 能夠支持複雜的多表關聯,而不必犧牲數據模型的規範化
- 面向外部用户看板,提供亞秒級響應速度
- 與 Kafka 和 Databricks 等上游數據管道實現無縫銜接
候選方案:ClickHouse、Apache Pinot 與 StarRocks
在選擇新一代 OLAP 數據庫時,我們對幾款熱門方案進行了基準測試。結果發現:
- ClickHouse 的查詢速度很快,但在複雜的多表關聯上顯得吃力
- Apache Pinot 在低延遲寫入方面表現出色,但在我們需要的複雜查詢場景下存在侷限
- StarRocks?它不僅滿足了所有核心需求,還帶來了更多驚喜
為什麼選擇 StarRocks?
StarRocks 之所以在眾多候選中脱穎而出,原因在於:
- Join 性能極快:StarRocks 在多表 Join 的優化上表現驚豔,能夠高效處理複雜查詢。這正是我們核心場景的關鍵勝負手。
- 在 3 億+ 行數據上實現 P99 < 500ms:在模擬實際業務場景的基準測試中,StarRocks 即使在大規模數據下,也能持續保持亞秒級的查詢性能
- 原生支持 Kafka 與 S3(Parquet):StarRocks 與我們現有的數據生態無縫銜接。無論是 Kafka 的 Routine Load,還是 S3/Parquet 的支持,都讓我們幾乎無需對數據管道做大幅調整,就能從原型快速切入生產環境。

StarRocks 在生產環境中的落地實踐
選擇 StarRocks 只是開始,要真正發揮它的價值,我們需要在架構層面做出關鍵抉擇。
兩種架構模式:存算一體與存算分離
StarRocks 提供兩種存儲架構選項:
- 存算一體:數據由 StarRocks 本地存儲和管理
- 存算分離:StarRocks 可直接從對象存儲(如 S3)中查詢數據
- 📖 延伸閲讀:Architecture Deep Dive
在充分評估之後,我們決定採用存算一體架構 —— 讓 StarRocks 完全負責數據的本地存儲與管理。
為什麼選擇存算一體
- 性能優先 —— 我們的分析看板面向品牌用户,響應速度直接決定用户體驗。本地存儲意味着更快的查詢響應。
- 數據規模可控 —— 當前數據量還在數十 TB 以內,使用本地存儲並未遇到容量或擴展瓶頸。
當然,如果業務已經達到 PB 級數據量,並且更看重彈性與計算/存儲分離,那麼存算分離架構或許是更好的選擇。
將數據導入 StarRocks
為了支撐分析看板,我們需要將多源數據導入 StarRocks。隨着產品不斷成熟,我們的導入方式也逐步演進,目前主要依賴兩條數據管道:
- 通過 Pipe Load 從 Databricks 加載數據(S3 / Parquet)
在早期,我們的數據流非常簡單:每天從 Databricks 表批量同步到 Postgres。
而在引入 StarRocks 後,藉助 Pipe Load,我們能夠讓系統持續掃描指定的 S3 路徑,並自動加載新生成的 Parquet 文件。(補充説明:Databricks 會將數據以 Parquet 文件的形式存儲在 S3 的文件夾中)
下面是一條典型的 CREATE PIPE 命令示例:
CREATE PIPE <pipe_name>
PROPERTIES (
"AUTO_INGEST" = "TRUE"
) AS
INSERT INTO <tablename>
SELECT * FROM FILES (
"path" = "s3://<bucket-name>/<folder-name>/*.parquet",
"format" = "parquet",
"aws.s3.region" = "<region>",
"aws.s3.access_key" = "<>",
"aws.s3.secret_key" = "<>"
);PIPE 使用小技巧
- 設置"AUTO_INGEST" = "TRUE",即可在新 Parquet 文件落盤到 S3 時實現自動同步
- 刪除操作不會自動同步:可通過軟刪除模式(例如設置 is_deleted 標記)來實現
- 主鍵的選擇至關重要 —— StarRocks 會在主鍵表上執行 upsert
作為參考,我們的核心銷售表已超過 3 億行數據,而絕大多數查詢都會涉及 2–3 張表的 Join。
延伸閲讀:: Pipe Load Docs
- Routine Load × Kafka:解鎖實時分析
隨着產品不斷成熟,用户對數據的要求也越來越高。我們很快意識到:每天一次的批量更新已經遠遠不夠。品牌迫切需要實時洞察 —— 比如能即時查看當天的銷售和曝光數據,從而快速決策、緊跟市場變化。
這正是 StarRocks 真正發揮價值的時刻。藉助 Routine Load,我們直接接入 Kafka 流,讓數據更新幾乎以實時的方式不斷寫入 StarRocks。
Routine Load 的價值所在:
- 精確一次導入保證 —— 數據乾淨、一致,避免重複或遺漏
- 配置簡單 —— 輕鬆接入 Kafka 主題
- 原生支持 —— 無需第三方連接器或額外管道
藉助 Routine Load,我們能夠將 Kafka 的數據流直接寫入 StarRocks,實現真正的準實時看板,性能與實時性兼得。
目前,僅在一個核心表上,我們每天就通過 Kafka Routine Load 導入 3000 萬+ 行數據 —— 而這只是多個高數據量表中的一個,更多表正在陸續接入
實時分析管道如何運作?
為了給品牌夥伴提供快速、可靠的洞察,我們搭建了一條流式數據管道。流程大致如下:
第一步:事件採集
整個流程從數據接入開始 —— 每秒都有超過 6 萬條事件從 Kafka 源源不斷涌入,其中曝光主題數據量最大,其次是商品和訂單交付事件。
為了承載如此龐大的流量,我們的平台團隊構建了一個高度可擴展的事件管道,已經在整個公司範圍內廣泛應用。
👉延伸閲讀:Voyager
第二步:Apache Flink 實時處理
接下來由 Apache Flink 接管,對事件流進行實時處理:
- 過濾掉不必要的列
- 在一個 x 分鐘的窗口內(當前為 5 分鐘)對指標進行聚合,以優化存儲和查詢
- 將聚合結果寫入目標 Kafka 主題,供 StarRocks 消費
第三步:數據進入 StarRocks
處理完成的事件流,通過 Routine Load 機制導入 StarRocks。只需幾秒鐘,這些數據便可直接被查詢 —— 無需延遲、無需批處理,真正的實時就緒。
第四步:為品牌帶來即時洞察
最新數據進入 StarRocks 後,Brand Analytics 服務便能在 SKU、品牌、區域等多個維度上執行快速的查詢。指標幾乎實時刷新,讓品牌合作伙伴能更聰明地決策,更快把握趨勢,並始終保持領先。
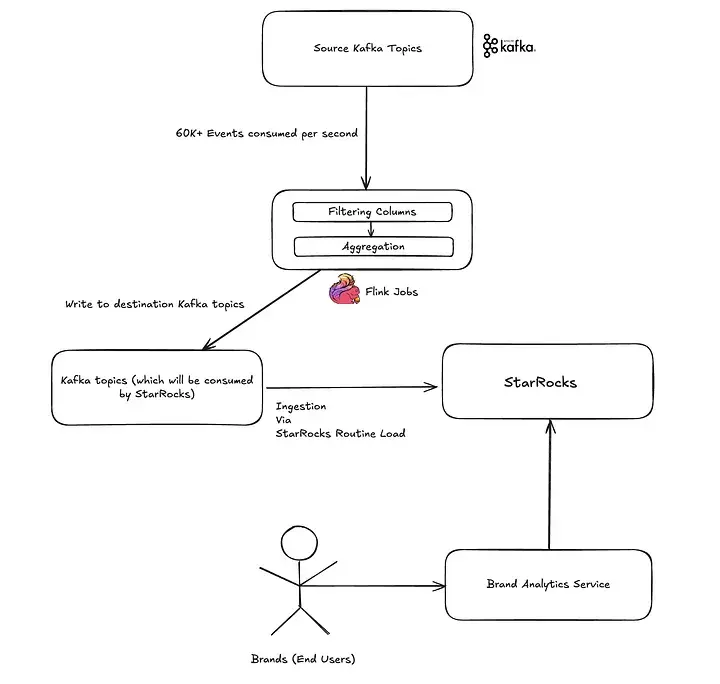
文檔: Routine Load with Kafka
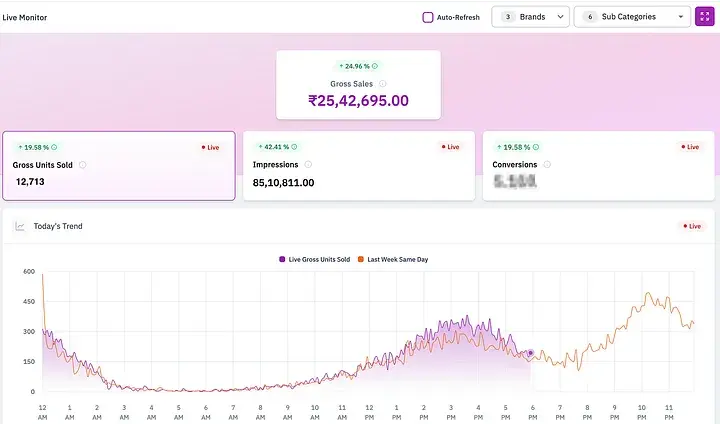
成效
藉助 StarRocks + Kafka + Flink,我們實現了從“每日數據”到“準實時分析”的飛躍。這讓品牌合作伙伴能夠更快響應市場、更合理的制定規劃、並實現更智慧的增長。
總結
打造一個穩健且可擴展的品牌分析平台並不輕鬆,但有了 StarRocks,這一過程變得更加順暢、高效。
我們取得的成果包括:
- 隨着數據和用户規模的增長,從 Postgres MVP 平滑升級為生產級分析架構
- 在面向品牌用户的看板中,實現亞秒級查詢性能
- 通過 S3 Pipes 與 Routine Load,無縫接入 Databricks 與 Kafka 流式數據
- 單表每日導入超過 3000 萬行數據
- 採用存算一體架構,在低延遲與高性能之間找到最佳平衡
憑藉 StarRocks 與事件管道的結合,我們完成了從“日報表”到“準實時洞察”的跨越 —— 真正幫助品牌合作伙伴 更快響應市場、更聰明制定決策。
未來規劃
在接下來的內容中,我們將分享更多幹貨:
- StarRocks 與其他數據庫的性能對比 —— 基準測試結果,以及在不同工作負載下的差異表現
- 實踐中的關鍵挑戰與解決之道 —— 我們如何攻克難題,提升數據工作流與整體效率
致謝
感謝 Syed Shah、Rajendra Bera、Ashutosh Gupta、Harshit Gupta 和 Deepak Jain 在該項目中的重要貢獻。




