









回顧 StarRocks 的進化之路,每一次大版本迭代都緊扣時代對數據分析的核心訴求。
- StarRocks 1.x,打造極速查詢性能,解決 BI 報表、數據探尋慢的痛點問題。
- StarRocks 2.x,解決‘實時分析’的難題,幫助用户更快的洞察業務。
- StarRocks 3.x,升級存算分離架構,打造極速統一的湖倉分析能力,讓數據分析更加的簡單高效。
在新的 AI 時代,模型訓練推理與 AI Agent 構建對數據平台提出新挑戰;數據新鮮度要求更實時,查詢延時與併發要求更高、數據處理效率與性價比要求更高,StarRocks 4.x 大版本將以 Real-Time Intelligence on Lakehouse 為核心,打造 Agent-ready 的數據分析引擎。
實時分析更高效
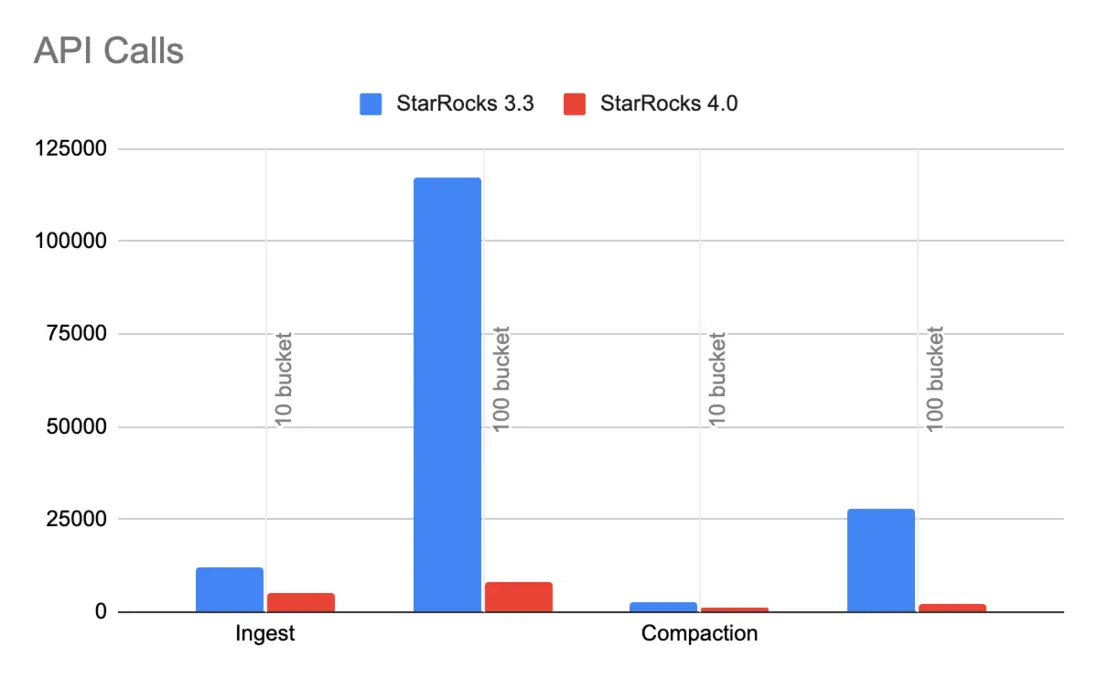
StarRocks 3.x 在存算分離架構下,基於低成本的對象存儲構建實時分析能力,相比存算一體的方案在存儲成本上有了數量級的下降。對象存儲存儲成本低,但有額外的 API 調用成本,尤其是在實時場景,高併發小批量的寫入會導致極高的 API 調用成本,為了進一步提升實時分析的效率/性價比,StarRocks 4.0 對實時鏈路進行了端到端優化:
- File Bundle:將多個小文件打包合併為大文件,減少寫放大,顯著降低 API 調用次數;
- 元數據緩存:元數據優先從 BE 緩存讀取,避免頻繁訪問 S3;
- Compaction 策略優化:在保持數據整潔的同時,避免過度消耗資源。
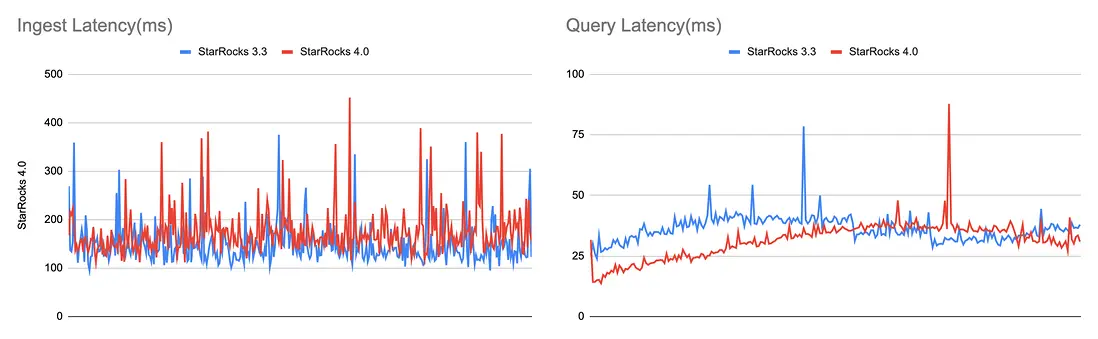
得益於這些改進,StarRocks 4.0 在實時導入與查詢場景中表現更為出色。相比 3.3 版本,API 調用減少 70%–90%,導入與查詢延遲幾乎無變化,部分場景甚至更快。
極速分析再進化
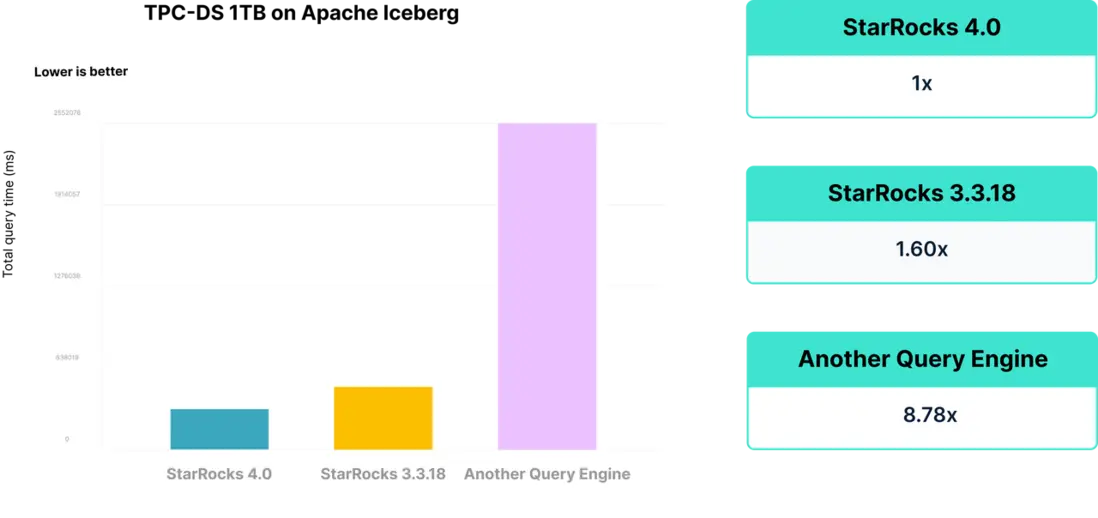
StarRocks 一直以卓越的性能表現聞名,StarRocks 4.0 將性能優勢進一步擴大,並覆蓋更多數據分析場景。
算子性能持續優化
StarRocks 4.0 針對 Join、聚合、去重、溢出處理等核心算子進行了深度優化。
- 優化覆蓋內表和外表,無論數據存儲在何處,都能獲得同樣的加速體驗。
半結構化數據性能飛躍
在實時分析場景中,日誌、點擊流、埋點、用户畫像等數據幾乎無處不在。這些數據通常以 JSON 格式存儲,結構靈活,卻也給查詢和分析帶來挑戰。傳統做法往往需要先經過複雜的 ETL,將 JSON 拉平成寬表,不僅耗時、也削弱了 JSON 的靈活性與可擴展性。
StarRocks 4.0 更進一步:正式將 JSON 升級為一等數據類型,並在執行層面加入了一系列深度優化,如索引、全局字典、延遲物化及謂詞下推。讓 JSON 可以享受和結構化列同樣的加速手段:相比 3.5 版本,StarRocks 4.0 在 JSON 查詢上的性能提升 3–15 倍。
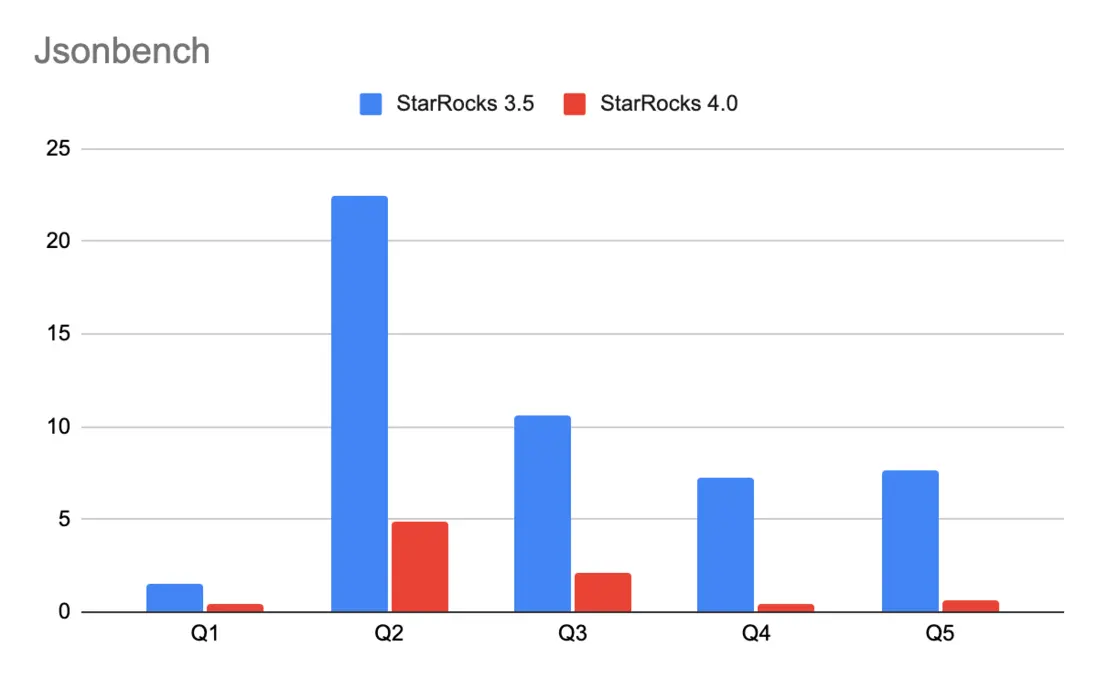
更重要的是,用户無需修改原有數據管道:只需將 JSON 數據直接導入 StarRocks,即可通過原生 SQL 與 JSON 函數進行查詢。底層的存儲與執行優化將自動生效,帶來接近列式存儲的查詢性能。這意味着你可以在 StarRocks 上直接進行 JSON 的實時分析——無論是日誌監控、用户行為分析、點擊流還是運營監控,JSON 數據分析不再是性能瓶頸。
查詢性能可預測
在真實的生產環境中,數據分佈會不斷變化,集羣也可能因為擴縮容或節點重啓而波動,這些都會導致優化器生成不同的執行計劃,從而引發查詢性能的不穩定。
為此,StarRocks 4.0 引入了 SQL Plan Manager。它能夠將查詢與執行計劃綁定,在相同的 SQL 下儘量保持一致的執行路徑。即使底層數據更新,或者集羣發生節點故障、升級重啓,查詢也能維持穩定的性能表現。
在報表平台、用户畫像分析、金融風控等對 SLA 要求極高的場景中,SQL Plan Manager 能有效降低因執行計劃變化帶來的性能波動,讓查詢結果更穩定、可預測。
拓展更多嚴苛場景
在金融、支付、Web3、IoT 等場景中,數據的精度、一致性與時間序列分析能力往往決定了業務的可靠性和決策的準確度。相比常規分析任務,這些場景對系統提出了更高要求:既要保證數據處理的“快”,又要確保計算的“準”。
為此,StarRocks 4.0 新增並強化了三項關鍵能力:
- Decimal256 高精度計算:提供更大數值範圍和更高精度,滿足貨幣結算、交易對賬、風控分析等對精確度要求極高的場景。
- 多語句事務(Multi-Statement Transaction):在一定條件下拓寬事務支持範疇,支持 BEGIN / COMMIT / ROLLBACK 顯式控制,允許跨表 INSERT、DELETE、UPDATE,保證原子性和一致性。減少額外數據一致性協調,從而讓後續分析更快、更可靠。
- ASOF JOIN:針對時序和區間型數據的連接場景,支持基於時間戳或序列號的“最近匹配”。無論是金融市場中對齊行情與成交量,還是 IoT 場景下對齊多源傳感器數據,都能高效完成。
藉助這三項能力,StarRocks 在金融級精度、事務一致性、時序分析領域實現了體系化增強,為更多關鍵業務場景提供實時分析的新可能。
湖倉原生分析
自 2.0 起,StarRocks 就支持直接查詢外部表,並在此後持續進行了大量引擎級優化。但現實是,數據湖往往是“雜亂”未經治理的——文件並非為查詢而組織,再強大的引擎也難以在“髒湖”中創造奇蹟。
StarRocks 4.0 大版本將實現湖倉原生分析 ——將 StarRocks 多年來在數倉場景積累的優化經驗,應用到開放格式之上,讓用户基於 Iceberg 構建湖倉像使用 StarRocks 內表一樣簡單。在使用內表時,用户無需關注文件佈局或統計信息,數據寫入即可查詢;而如今,這種“寫入即查詢”的體驗,同樣適用於 Iceberg 等開放格式。
文件層面:寫入即查詢
StarRocks 4.0 對文件寫入與管理進行了全面增強,不僅提升了寫入性能,也讓寫入的數據天然適合高效查詢。
主要優化包括三方面:
- 能力補全:全面支持 Iceberg Hidden Partition 表的創建與寫入,支持建表時設置排序鍵
-
寫入性能提升:
全局 Shuffle 避免產生小文件
Spill 寫入提升大規模導入的內存效率
Local Sort 生成更利於查詢的文件
- 文件主動治理:提供 Compaction API,用户可以根據業務需要隨時合併文件,保持數據高效可查
查詢層面:穩定與加速
數據湖表往往龐大且鬆散,統計信息難以獲取,且一旦數據更新便容易過期。為此,4.0 在查詢路徑上持續升級:
- 優化器增強:即使在缺少統計信息的情況下,也能做出合理假設,生成具備成本效益的執行計劃
- 統計信息優化:更快、更輕量地收集統計信息
- 元數據刷新優化:優化刷新策略,提升元數據新鮮度
基於這些優化,StarRocks 4.0 為數據湖查詢構建了多級加速體系:
在文件層,實現數據 “一次寫入,即刻可查”;在查詢層,從更新鮮的統計信息到更智能的算子與緩存系統,確保查詢更快、更穩定;在需要亞秒級延遲與高併發的場景下,物化視圖則提供額外加速能力,同時保持單一數據源,不增加任何額外數據管道。
企業級安全
當然,這一切的前提是安全。StarRocks 4.0 在 Iceberg REST Catalog 中引入 JWT Session Catalog,並全面支持 AWS、GCP、Azure 的臨時憑證機制。
這意味着用户信息可以完整傳遞至 Catalog 側進行統一鑑權,存儲憑證也無需反覆配置。用户不僅能獲得極致的訪問速度,更能享有企業級的安全保障。
展望未來
StarRocks 4.0 是 Real-Time Intelligent on Lakehouse 的新起點,StarRocks 4.x 系列版本將繼續深化核心能力,打造 Agent-ready 的數據分析引擎。接下來,StarRocks 社區將重點聚焦:
- Fast Query:極速統一是 StarRocks 持續發展的主線,為多樣化的場景提供穩定、可預期的極速查詢性能。
- Fast Delivery:Lakehouse 架構是 AI 時代的數據基座,StarRocks 持續優化 Lakehouse 構建、治理與分析的能力,讓數據到業務價值的交付變得更加高效。
- AI Assitant:將 AI 工具融入數據庫生態,幫助用户更好的使用 StarRocks。例如提供更智能的建表、分區與查詢優化建議簡化建模,提供自然語言接口簡化分析師的數據洞察。
- Agent Ready:面向大模型與智能 Agent 的新形態應用,持續優化實時分析、數據處理效率、向量/文本等多維檢索的能力等,以滿足 AI Agent 對實時性、可擴展性和語義檢索的需求。
更詳細的 feature 介紹參考:
Release Notes:https://docs.mirrorship.cn/zh/releasenotes/release-4.0/
下載:https://www.mirrorship.cn/zh-CN/download/starrocks





