









作者:魏寧 攜程大數據平台開發專家
導讀:
在攜程龐大的數據體系中,UBT(User Behavior Tracking,用户行為追蹤系統)承擔着核心的用户行為採集與分析任務,日新增數據量高達 30 TB。為應對不斷增長的業務與性能需求,攜程技術團隊將 UBT 從 ClickHouse 遷移至 StarRocks 存算分離架構。
遷移後,系統實現了查詢性能從秒級到毫秒級的跨越——平均查詢耗時由 1.4 秒降至 203 毫秒,P95 延遲僅 800 毫秒;同時,存儲量減少一半,節點數由 50 個降至 40 個。本文將介紹攜程如何藉助 StarRocks,在性能與成本之間實現高效平衡。
UBT 架構
UBT 的核心功能是對用户行為進行埋點追蹤,並基於埋點數據進行查詢與分析,例如系統是否發生報錯等。它主要面向多端應用場景,包括 Android、iOS 和 NodeJS 等,通過調用 SDK,將埋點數據進行初步處理和過濾後發送至下游系統進行進一步加工。
該系統廣泛應用於排障統計和監控等場景,日均新增數據量約 30 TB,數據一般保留 30 天,部分表則會保留長達 一年。典型的查詢場景包括基於 UID 或 VID 結合時間範圍的日誌明細查詢,以及一些常見的聚合統計分析。
下圖展示了 UBT 的整體架構。最上層為客户端,例如移動端 App、Web 端和 PC 端。
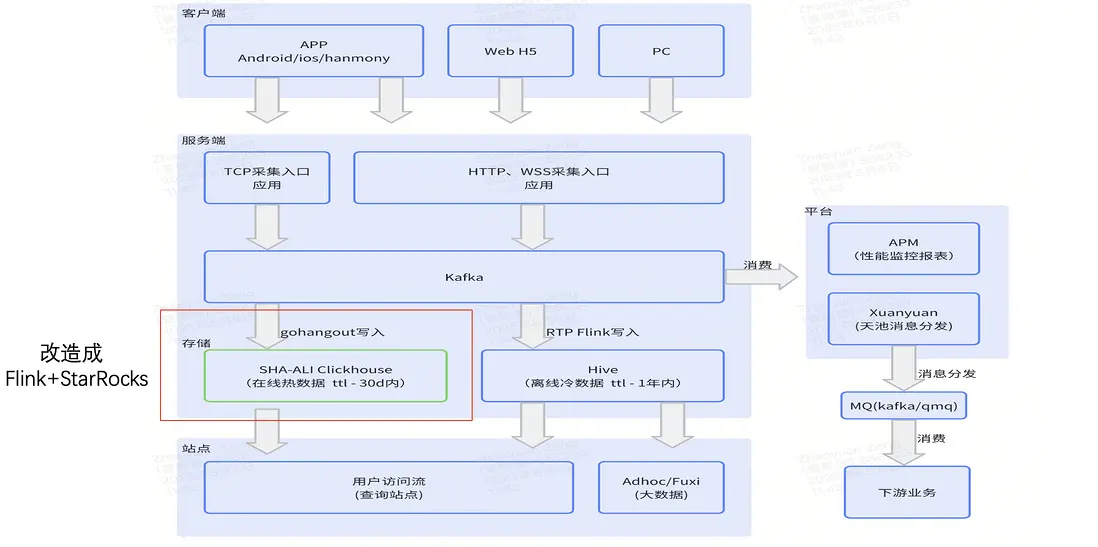
當埋點數據被服務端採集後,會首先寫入 Kafka。Kafka 的數據有兩條消費路徑:
- 路徑一:通過 gohangout 消費並寫入 ClickHouse。這一路鏈路承載實時數據,主要用於用户排查與簡單統計。
- 路徑二:通過 Flink 將數據寫入 Hive,作為冷存儲,用於更復雜的業務分析。
此外,右側還有多個業務平台基於這些數據進行消費和處理。
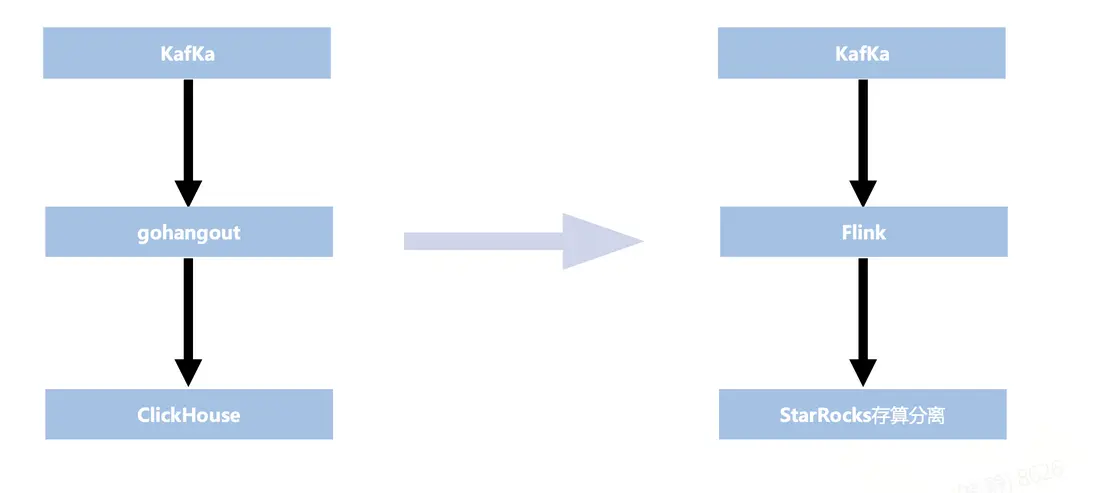
本次改造的重點在於上圖中紅色框標註部分——即 gohangout + ClickHouse,最終將其替換為 Flink + StarRocks。
UBT 目前遇到的問題
推動此次改造的主要原因,是在使用 ClickHouse 過程中遇到了一些難以解決的問題。
- 寫入問題:
- 在寫入 UBT 數據時,ClickHouse 出現了數據丟失和消費積壓的情況。究其原因,主要在於 UBT 除了寫入實時數據,還涉及一定量的歷史數據回補。
- 這類歷史數據通常覆蓋時間跨度較大,容易引發歷史分區的壓縮操作,從而導致集羣的 CPU 與 I/O 資源消耗過高,系統整體負載顯著上升。
- 水平擴展:
- ClickHouse 採用存算一體架構,擴容時不可避免地涉及數據遷移,過程複雜且對集羣穩定性帶來影響,擴展彈性不足。
- 面對海量數據,ClickHouse 對存儲與硬件機型的要求較高,不僅配置特殊、難以適配,而且為了保證數據可靠性往往需要設置三副本,存儲開銷隨之成倍增加。
- 性能問題:在大時間跨度的查詢場景中,ClickHouse 的 SQL 響應速度偏慢,難以滿足實時分析的需求。這一問題在高併發和海量數據場景下尤為突出。
另外使用gohangout也存在一些問題。
- 穩定性:gohangout 僅為單進程,依賴外部重試機制,穩定性不足。而Flink 具備分佈式架構,支持自動 failover 和自動擴縮容,能夠確保高可用性
- 便利性:在使用體驗上,gohangout 的配置語法相對繁瑣,業務人員在日常使用時需要投入額外的學習和維護成本,增加了操作難度。實時團隊基於 Flink 構建了 RTP(Flink 管理平台)。用户可以在平台上直接編寫 Flink SQL,將 Kafka 數據進行過濾、轉換等處理,實現完全自主的配置與可視化管理,大幅提升了易用性。
從 ClickHouse 到 StarRocks
基於以上痛點,團隊決定引入 StarRocks。早期 StarRocks 採用存算一體架構,計算與存儲緊密耦合,本地數據訪問帶來極快的查詢性能,通常可實現毫秒級返回。但這種模式也存在資源利用僵化、擴展負擔過重、存儲副本冗餘帶來高成本等問題。
因此,StarRocks 進一步演進為存算分離架構:計算節點無狀態化,僅保留計算引擎,能夠根據業務需求靈活調度;存儲則託管於遠端對象存儲(OSS/S3),實現計算與存儲的徹底解耦,另外為了保證查詢速度,計算節點可以打開 DataCache。該架構既提升了資源利用率,避免資源浪費,又顯著降低了存儲成本,同時也保證了查詢速度。例如,相比存算一體架構下的三副本冗餘,存算分離模式僅需一份本地副本即可保障可靠性。
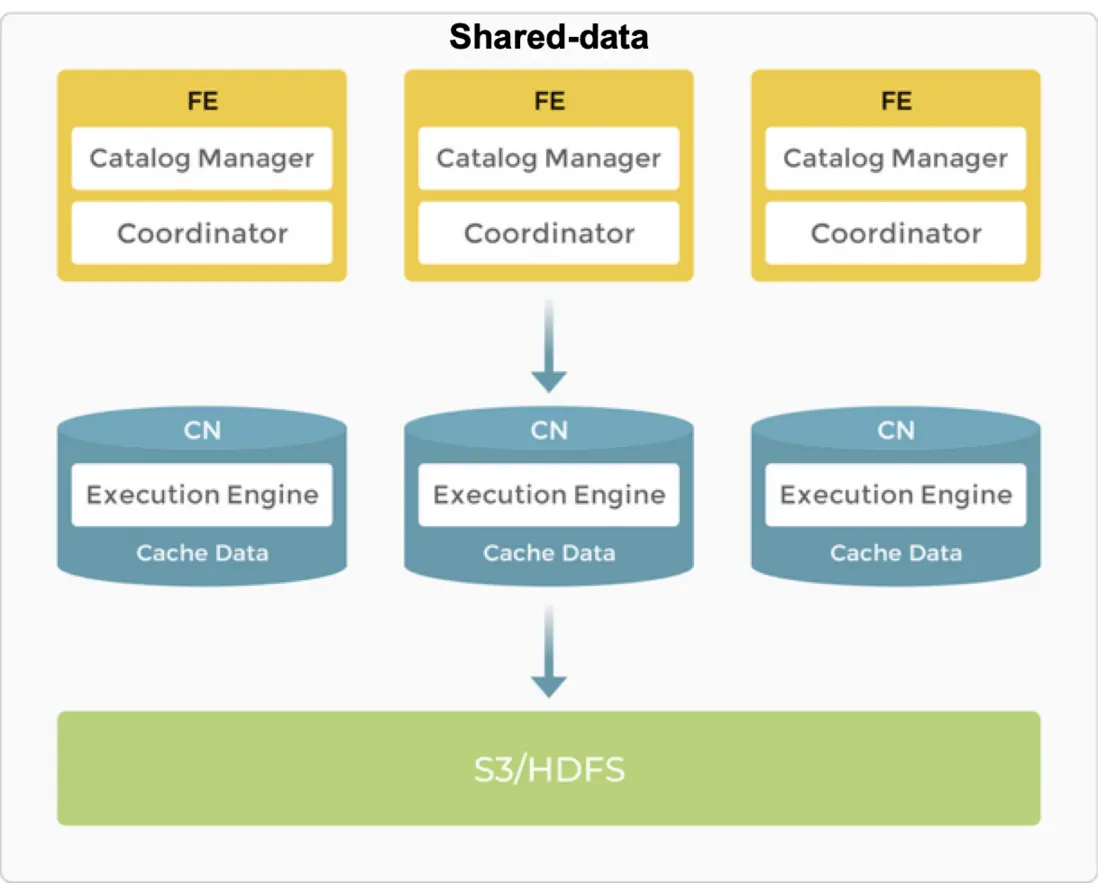
StarRocks 存算分離架構下,計算節點擴縮容不涉及實際數據的遷移,因此可以秒級完成,極致靈活,且對業務無任何干擾。在實際生產環境中,UBT 的一次擴縮容僅耗時約 5 秒。
穩定性與調優
存儲設計
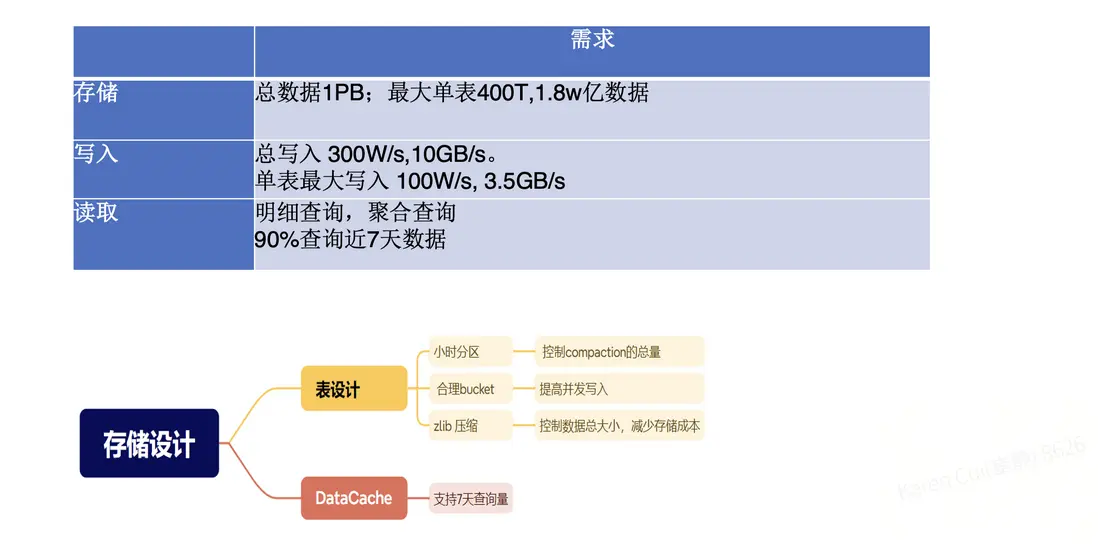
UBT 系統總數據量約為 1PB,其中最大的單表規模達到 400TB,包含 1.8 萬億行數據。寫入壓力巨大:整體寫入速率約為每秒 300 萬行 / 10GB,其中單表最大寫入量達到每秒 100 萬行 / 3.5GB。
在讀取場景中,主要分為兩類:一類是基於 VID 等字段的明細查詢,另一類是常見的 聚合分析。其中,約 90% 的查詢集中在 7 天內的數據,因此在存儲設計時,需要重點圍繞這一特徵進行優化。
因此在設計上需要圍繞讀寫兩方面進行考慮。
- 分區鍵設計上,StarRocks採用 系統時間 分區,每次只寫入當前分區,有效解決了寫入過程中的數據碎片與穩定性問題;而 ClickHouse 使用的是 業務時間 分區,每次寫入近三天分區,分區跨度大,容易產生大量碎片,導致寫入不夠穩定。
- 表設計上採用小時級分區。由於寫入量極大,小時分區能夠有效控制每次Compaction 時的數據量。同時,將 Bucket 數設置為 128,以提升併發寫入能力。在壓縮格式方面,選擇了 zlib 替代 LZ4,能夠在保證性能的前提下節省約 30% 的存儲空間,顯著降低總體存儲成本。
- 在 DataCache 設計上,緩存大小規劃為可支持 7 天的數據掃描量。由於超過 90% 的查詢集中在 7 天內的數據,這一配置使得大部分查詢均可通過緩存加速。
Compaction
在 Compaction 優化上,主要從三個方面入手:
- 合理控制 Compaction 的參數,包括文件個數及線程數量;
- 通過小時分區與合理的 Bucket 數,降低 Compaction 頻次與資源消耗;
- 寫入過程中啓用 MergeCommit,將小版本數據合併為大版本,從而減少存儲碎片。
在 Compaction 的管理方面,團隊也設計了相應的監控機制,以便及時發現並優化潛在問題。
首先,可以通過 native_compactions 表查看 CN 節點中每個 Compaction 子任務的詳細進展情況,從而識別出負載較高、拖慢整體任務執行的節點。
其次,藉助 partitions_metas 表,能夠監控各表的 Compaction Score,從而判斷是否存在分區設計或轉換策略不合理的情況。
此外,利用 show proc compactions 命令,可以獲取具體的 Compaction 任務信息,包括任務的開始與結束時間、總執行時長,以及本地與遠端數據的掃描量。例如,當遠端數據的掃描量偏高時,往往提示需要檢查 DataCache 的配置是否過小,從而為性能優化提供參考。
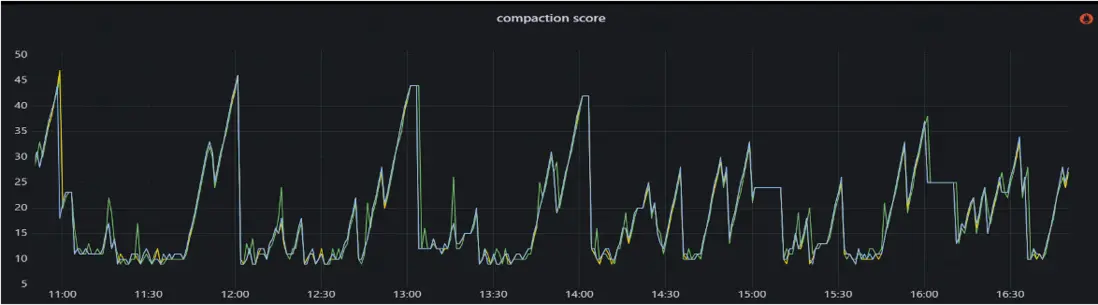
最後,團隊將相關監控指標接入 Grafana,並通過 SQL 圖表進行可視化展示。一般而言,當 Compaction Score 維持在 100 以下時,系統處於較為理想的狀態。
存量補數
在數據寫入方面,整體可以分為兩部分。第一部分是存量數據的遷移與補數。在此次改造中,團隊需要從 ClickHouse 遷移約 300TB 的存量數據。這部分數據在 HDFS 中也有備份,因為在原有架構下,數據同時寫入了 ClickHouse 和 Hive。
針對這一場景,團隊最終選擇了 SparkLoad 作為導入方案(Hive->StarRocks)。在做出決策前,對三種常見的數據導入方式進行了對比:
- StreamLoad:適用於 GB 級別的小規模數據導入,通常用於實時日誌寫入。
- BrokerLoad:支持 TB 級別的數據導入,通常以分鐘級完成,適合每日批量離線導入。
- SparkLoad:能夠支持 TB 級以上的數據導入,對集羣影響相對較小。其優勢在於,數據首先由 Spark 任務完成清洗與處理,並落地到 HDFS,隨後 StarRocks 的 CN 節點直接從 HDFS 拉取已處理好的數據寫入存儲。
這一機制繞過了 MemoryStore 向磁盤寫入的過程,顯著減少了 Compaction 的開銷,對集羣整體影響輕微。因此,SparkLoad 是大規模數據遷移的理想選擇,能夠高效完成 Hive 存量數據向 StarRocks 的平穩過渡。
實時增量
在實時增量寫入方面,團隊主要通過 Flink 寫入 StarRocks 的方式實現,並開啓了 MergeCommit 功能。與傳統 Commit 模式相比,MergeCommit 在寫入機制和整體性能上有顯著優化。
在傳統 Commit 模式下,n 個小請求會產生 n 次提交,從而生成 n 個新版本,導致版本數量龐大。而 MergeCommit 將 n 個小請求合併為一次提交,最終只生成一個新版本。這一機制有效減少了版本數量,降低了元數據的管理負擔。
在 Compaction 層面,傳統模式由於提交頻繁,容易產生大量 KB 或 MB 級的小文件,頻繁觸發 Compaction,導致系統開銷偏高。MergeCommit 模式下,每次提交生成的基本為 MB 級的大文件,從而顯著降低文件數量和 Compaction 頻率。
在 I/O 性能方面,傳統寫入以小文件為主,屬於隨機寫入模式,讀取時需要頻繁打開大量小文件,效率低下。而 MergeCommit 將寫入轉化為批量的順序寫入,讀取時文件數量更少,並且能夠利用順序讀優化,顯著降低 IOPS 和延遲。
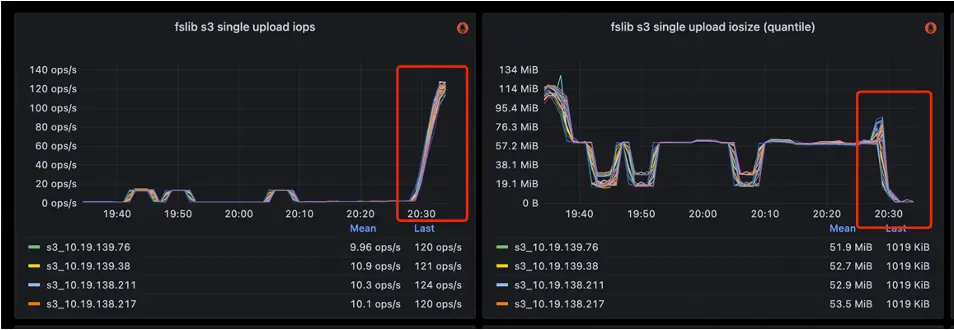
在寫入吞吐上,傳統模式以高頻的小批次寫入為主,吞吐有限;而 MergeCommit 通過聚合形成大批次寫入,大幅提升了整體吞吐能力。實際對比顯示,在關閉 MergeCommit 的情況下,StarRocks 的 IOPS 通常在 140 左右;而開啓 MergeCommit 後,合併了大量寫入,IOPS 可降低到 10以下。實現近 10 倍提升,寫入的 I/O Size 也提升約 10 倍。
查詢
在查詢優化方面,UBT 的典型場景主要分為明細查詢與聚合查詢。
對於明細查詢,要求用户必須指定分區,並結合前綴索引使用。通過這種方式,可以顯著減少掃描範圍,提升查詢效率。分區裁剪與前綴索引的結合,使得明細級別的日誌分析具備較好的性能保障。
對於聚合查詢,常見需求集中在基於小時分區的數據統計。針對這一場景,團隊根據 SQL 的查詢模型預先構建了 分區級物化視圖(Partition MV),並在查詢前完成聚合計算。由於分區 MV 每次僅刷新當前發生變化的分區,對集羣整體的影響極小。
需要注意的是,在MV的每一次刷新過程中,會檢查MV所有分區及其基表的所有分區,根據基表的分區變化來更新MV的分區。原算法是每個MV分區都會查詢一下基表的所有分區,時間複雜度M*N。
通過優化,只查詢一次基表所有分區,時間複雜度M+N。在分區數量達到萬級以上時,這一改進的效果尤為顯著:如果缺少這一優化,則FE響應時間會急劇拉長。
效果收益
通過上述一系列優化與改造,UBT 在性能與資源利用方面取得了顯著收益。
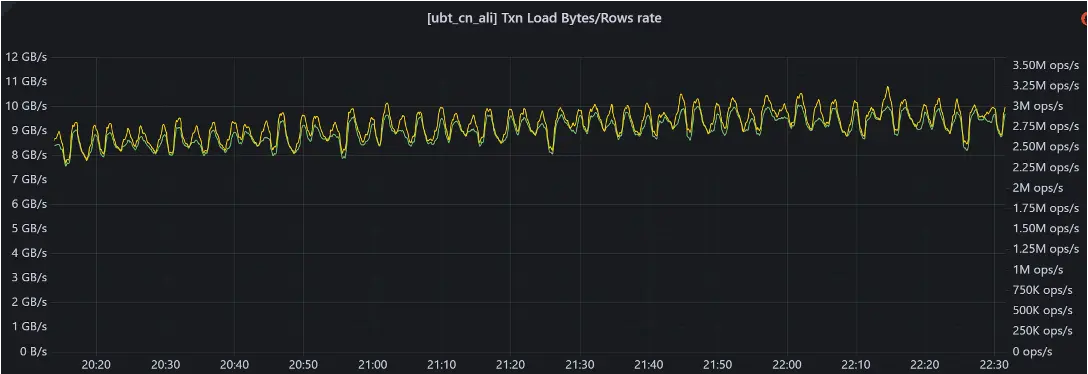
從ClickHouse遷移至 StarRocks 後,由於採用了單副本機制,系統存儲量由2.6PB(ClickHouse 2副本)降低至1.2PB(StarRocks 1副本),顯著節省了存儲成本。同時,節點數量從 50 個縮減至 40 個,資源利用率得到明顯提升。查詢性能方面,平均耗時由原來的 1.4 秒降至 203 毫秒,僅為之前的 1/7;P95 延遲由 8 秒縮短至 800 毫秒,達到原來的 1/10。下圖展示了 UBT 寫入 StarRocks 的數據曲線,寫入速率穩定維持在 300 萬行/秒,整體運行平穩。
展望未來,團隊將繼續推進存算一體集羣向存算分離架構的遷移。同時,在湖倉查詢層面,也將逐步從存算一體演進至存算分離,以進一步提升靈活性與擴展性。






