









導讀
隨着 AI 技術的廣泛應用,以及數據規模的不斷增長,向量檢索也逐漸成了 AI 技術鏈路中不可或缺的一環。 在11月16日舉辦的【墨天輪數據庫沙龍-向量數據庫專場】邀請到阿里巴巴高級技術專家劉方,為大家帶來《阿里巴巴大規模向量檢索實時服務化引擎Proxima SE》主題分享,以下為演講實錄。

劉方 阿里巴巴高級技術專家
阿里巴巴達摩院Proxima-SE產品負責人,多年來從事HPC、中間件、數據庫、向量檢索等底層產品研發工作,對數據服務型產品及技術有廣泛積累。
向量檢索
1、什麼是向量檢索
人工智能算法可以對物理世界的人/物/場景所產生各種非結構化數據(如語音、圖片、視頻,語言文字、行為等)進行抽象,變成多維的向量。這些向量如同數學空間中的座標,標識着各個實體和實體關係。我們一般將非結構化數據變成向量的過程稱為 Embedding,而非結構化檢索則是對這些生成的向量進行檢索,從而找到相應實體的過程,非結構化檢索本質是向量檢索技術。
2、基本原理及實現方式
向量檢索的基本原理是解決KNN(K-Nearest Neighbor)的問題,但在實際場景下,獲取百分之百KNN結果所耗費的計算資源較高,於是引入了求近似解的方法。目前在業內普遍使用ANN(Approximate Nearest Neighbor)來進行大數據量查詢,它被證明在實際場景下更有效,更加節省資源。
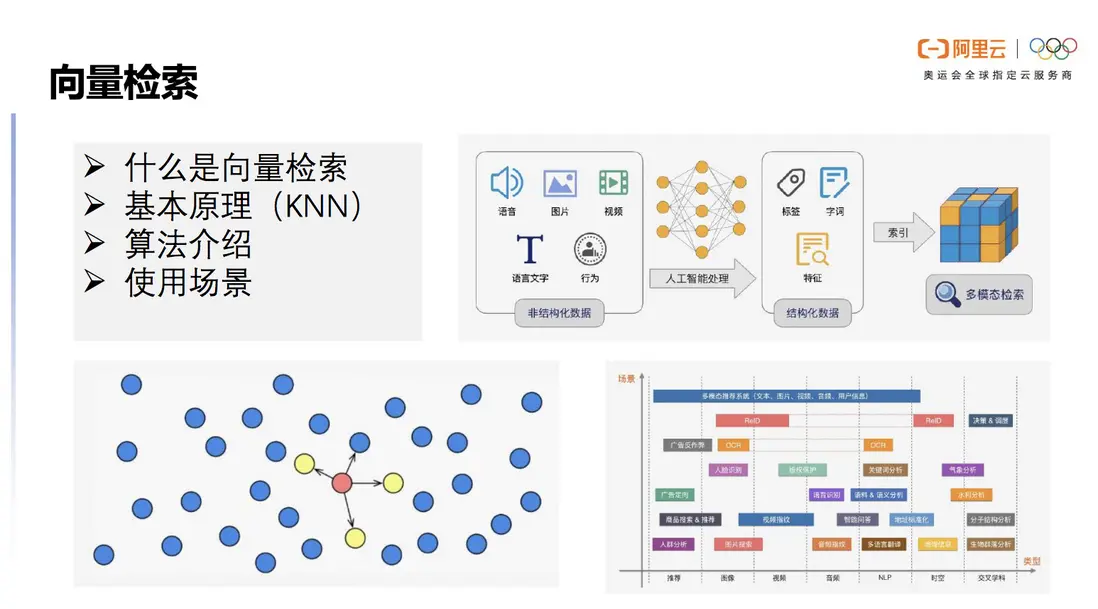
圖1 向量檢索介紹及場景
如何實現向量檢索算法?主要是通過以下幾個類別。
首先是哈希方法,通過局部敏感哈希(Locality Sensitive Hashing,LSH)將原始向量通過哈希函數映射到新的向量空間,在新的向量空間中,原始相近的向量會映射到一個桶中,以此實現檢索。
其次是基於樹的方法,比較典型的有KDTree,原理即選取向量中某個方差最大的維度切分直到切成一個很深的樹,以此實現向量檢索。
目前流行的是圖算法,比如NSG、HNSW、NGT等,以HNSW為例,將快表的思想與NSW的算法相結合,實現層次型小世界圖的快速檢索,從而達到很好的效果。
PQ(Product quantization直譯為乘積量化)也是比較重要的算法,通過乘積量化的方式將高維的向量進行壓縮,切分為多個低位向量集合,低位向量會聚類出自己的中心點,反之每一個向量子集的中心點就代表了向量。PQ是壓縮完成後再做檢索,具有內存較少、效率較高的特點,但是召回率不及非壓縮方法。
向量檢索的使用場景非常廣泛,如人臉識別、推薦系統、圖片搜索、視頻指紋等。隨着 AI 技術的廣泛應用,以及數據規模的不斷增長,向量檢索也逐漸成了 AI 技術鏈路中不可或缺的一環。
下圖展現了向量數據庫與傳統數據庫的區別。

圖2 向量數據庫vs傳統數據庫
向量檢索內核Proxima
1、Proxima 由來及現狀
向量檢索內核Proxima 是阿裏巴巴達摩院自研的一款向量檢索引擎,在2014年隨着拍立淘應運而生。Proxima的底庫規模有數億個商品、幾十億個圖片,很好的支撐了拍立淘的應用,,為集團帶來數十億個GMV的收益。Proxima還支撐了阿里其他的業務系統,淘寶的主頁搜索與推薦也在利用它做內核實現。在雙11高峯期,Proxima也能很好利用計算資源並承接高峯流量。
除了阿里的業務系統,Proxima還深度集成在阿里雲數據庫服務上,為其提供向量檢索的能力。
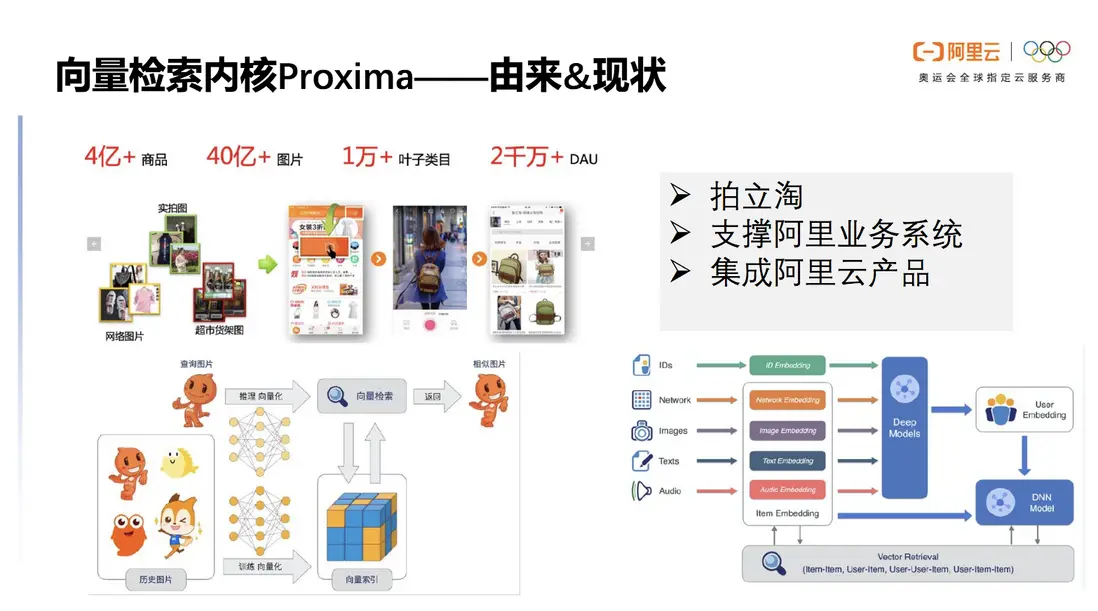
圖3 Proxima 為阿里雲產品及系統提供向量檢索能力
2、Proxima 功能特色
Proxima內核擁有清晰的分層架構,它定義了一套完善抽象的向量檢索的接口,不同的索引通過統一的接口投出能力。Proxima底層實現了一套跨平台的抽象以及指令優化的庫,在具體的向量計算中發揮很大的優化作用。上層提供不同的向量索引的實現,包括Proxima自研的向量,由此可見這是一套合理科學的結構。
單機大規模是Proxima的一大功能,對內存與磁盤的平衡使用能讓單機大規模達到10億的級別。Proxima極其注重高性能,它將SIMD技術利用到了極致,對磁盤數據結構精細設計使得在構建性能上能達到同類開源庫幾倍的超越。
Proxima也同樣支持異構計算,針對淘寶推薦搜索類似的高吞吐低延遲場景也進行了深度優化,才能以一個較小的計算資源耗費支持創世紀大規模的洪峯考驗。流式更新也是Proxima的一大特點,將內存的數據結構映射到磁盤的數據結構,通過內存磁盤的映射工作讓Proxima能夠從0到1構建大規模索引,以達到實時更新、實時查詢、實時落盤。以上都是與開源軟件相比,Proxima獨特的優勢。
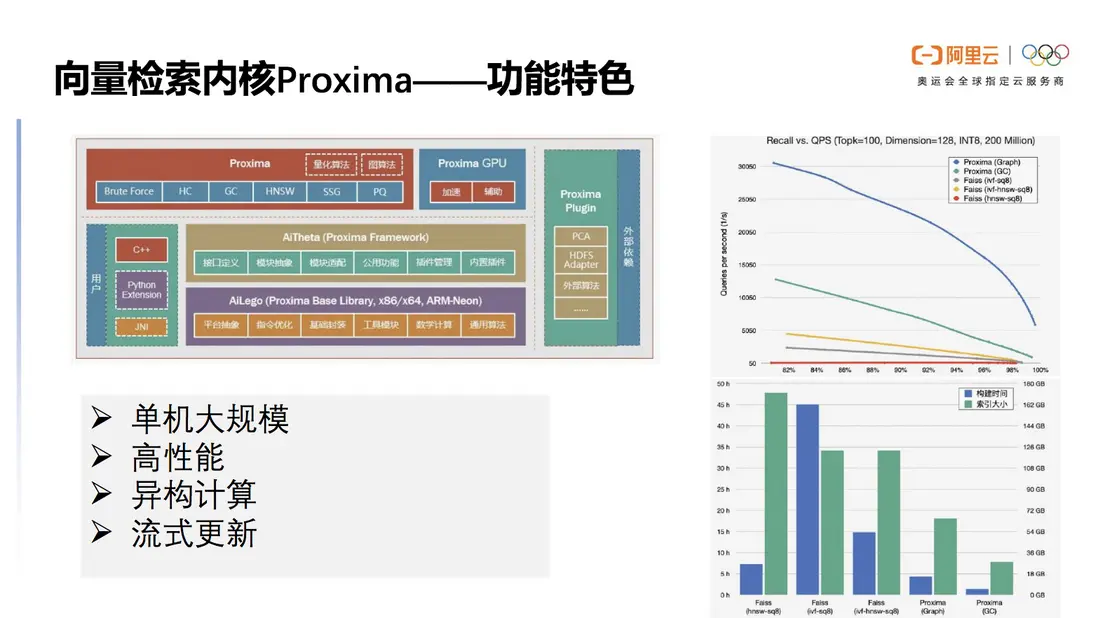
圖4 Proxima 具有單機大規模、高性能、異構計算、流式更新等主要功能
服務化引擎-Proxima SE
1、Proxima SE 架構
服務化引擎Proxima SE它將支撐淘寶業務級別的Proxima內核引擎的核心能力逐步提取出來,以開箱即用的方式服務於客户。
下圖右側展示了Proxima SE的軟件架構 ,外部接收到非結構化數據後,通過模型推理產生的向量被插入到數據庫或者直接寫到SE當中,插入到數據庫的部分會通過SE的組件將數據同步到SE當中,接受KNN實現Query 查詢,並返回Result Set。
圖中展現了Proxima SE 的內部架構,collection在向量中對應的是數據庫表,segment存儲了對應的column,每個column都有自己的存儲與實現,比如針對向量索引的存儲。
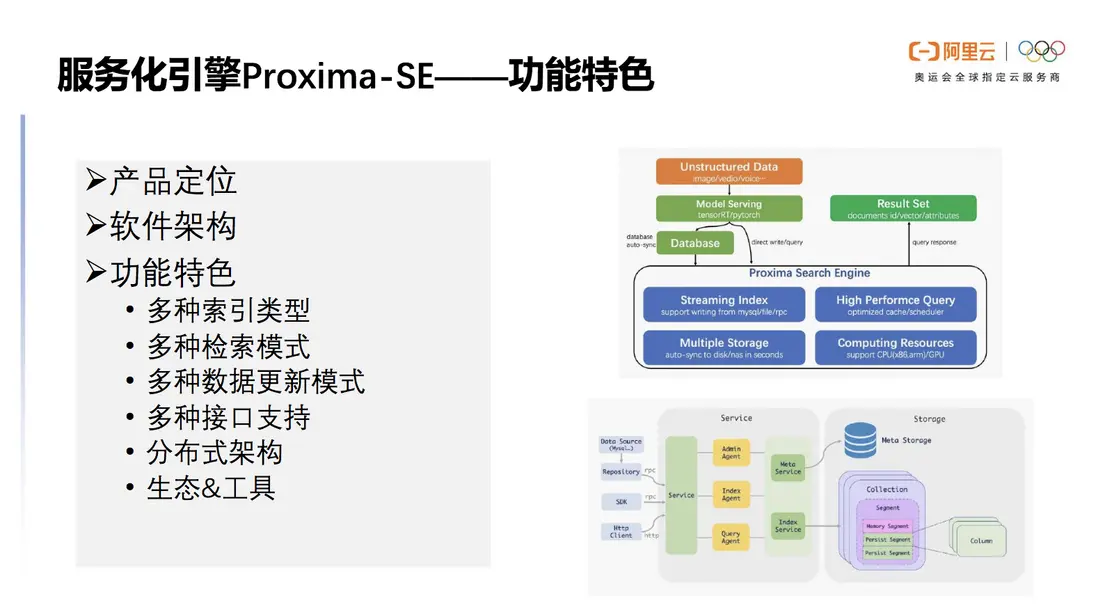
圖5 Proxima SE 架構示意圖
2、Proxima SE功能特色
多種索引類型
Proxima SE擁有多種索引類型以滿足不同場景的需要。首先是向量索引,HNSW是常見也最被廣泛使用的圖索引類型。OSWG是Proxima團隊自研的一種圖算法,能夠解決HNSW在頻繁的update與delete場景下數據膨脹的問題。QC是高性能的量化聚類,存儲優勢較大但召回率遜色。向量數據類型支持浮點型、整型、Binary,距離計算支持歐式距離、內積距離,通過不同類型搭配可以滿足多種場景的具體需求。
倒排索引類似於數據庫的二級索引,對整型或者字符串列可以建立倒排索引以加快檢索速度。正排索引可以認為是數據庫中的普通列,支持各種精度的整型、浮點型以及字符串。由此可見,Proxima SE充分支持多種索引類型。
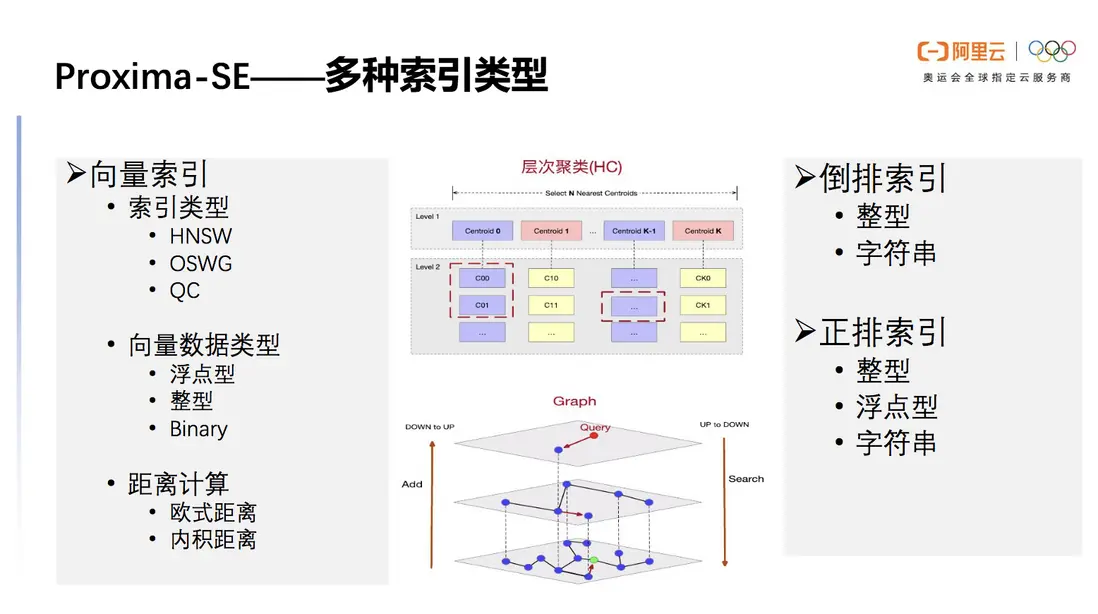
圖6 Proxima SE 支持多種類型索引
多種數據更新模式
Proxima SE 的數據更新模式靈活多樣,根據不同的場景適配。
- 旁路同步模式:是將向量數據存儲在MySQL數據庫中,再通過組件將數據庫的向量數據同步在Proxima SE中。
- 流式直寫模式:將Proxima SE當作一個數據庫,針對提供的SDK將向量原始數據寫到SE當中,在此過程中Proxima SE來保證存儲與可靠性。
- 離線全量模式:如果我們已經有準備好的向量數據,可以通過indexbuilder工具一次性將向量數據構成向量索引,通過Proxima SE 直接拉起進行查詢。
- 批增量模式:主要支持更新模式,考慮到用户場景裏可能會週期性地產生一些數據,通過indexbuilder將它構建成一套索引,以追加的方式加載在Proxima SE中再去進行檢索。
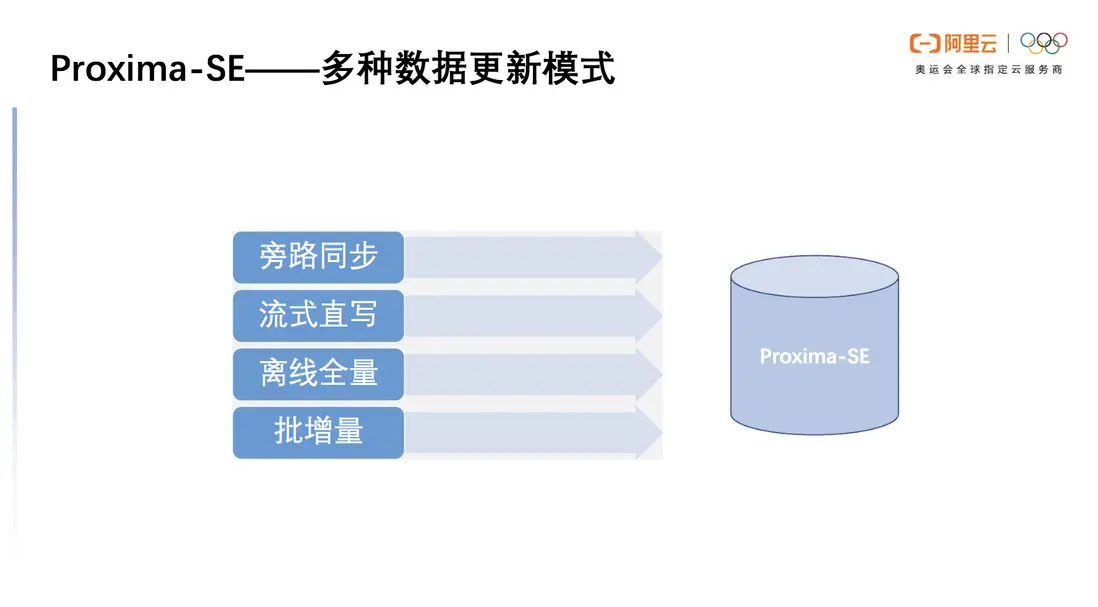
圖7 Proxima SE 支持多種數據更新模式
多種檢索模式
Proxima SE在檢索模式上下了很大功夫。首先Proxima SE在檢索中需要指定檢索條件,我們支持向量、倒排、正排條件,支持多個條件的AND/OR/()組合也是一大特色,這樣就可以構建一個比較複雜的條件滿足多樣需求。
邊檢索邊過濾是Proxima SE默認的過濾方式,在特殊情況下如果大部分節點不滿足過濾條件,就不能滿足性能,為此我們設計了檢索後置過濾的能力,我們可以先指定一個較大的KNN的top key,再對召回結果集中進行過濾從而篩選出滿足條件的結果,由此保證性能。
除此之外,在某些場景下我們根據倒排的條件評估結果集的大概規模,如果這個規模小於某一閾值則可以直接用倒排繼續檢索,通過暴力計算距離的模式拿到最終的結果。事實證明在倒排暴力檢索優化的場景下的性能優勢優於向量檢索。
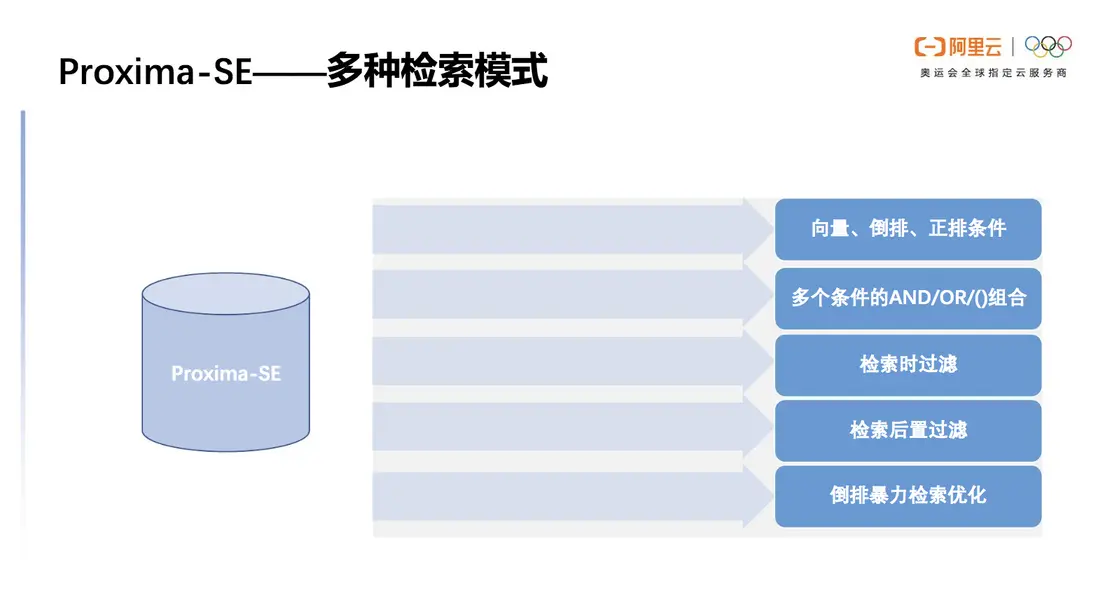
圖8 Proxima SE 支持多種檢索模式
多種接口支持
Proxima SE在應用型方面也做了很多工作,提供很多的接口支持。首先在調用接口上支持多語言SDK,如python、java等,也可以通過HTTP直接進行訪問,快速檢索其中的數據。
傳輸協議支持流行的gRPC以及Restful API的形式。請求數據格式上主要是以JSON為接口,輸出不同的query相關屬性,為了支持數據庫的生態我們也做了SQL集成以方便用户使用。
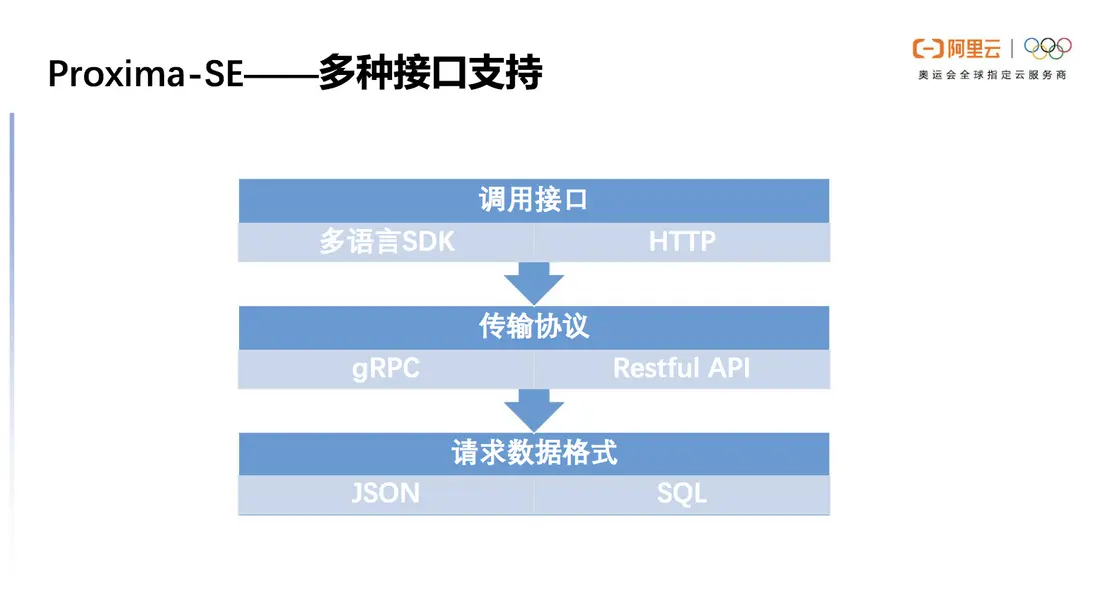
圖9 Proxima SE 支持多種接口
分佈式架構
Proxima SE的分佈式架構支持面向百億到千億超大規模向量檢索,整體上是收納性架構,可以部署在K8s中實現自動化部署運維,也可以方便部署在任何一個支持K8s的雲環境中。分佈式架構的功能與特色如下圖所示。
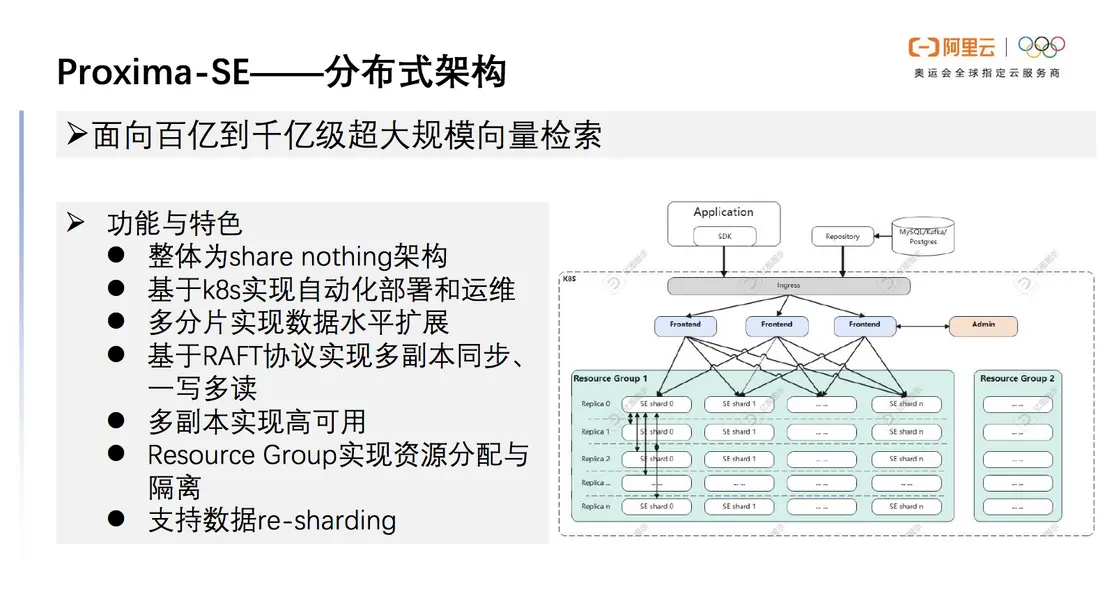
圖10 Proxima SE 分佈式架構的功能與特色
生態&工具
數據同步組件Repository,可以支持從不同的數據庫中同步向量數據,目前支持MySQL、PG以及kafka,未來將支持更多的數據庫版本。
監控報警工具有bvar、Prometheus&Grafana,用户可以清晰的看到Proxima SE內部使用及資源佔用的情況。除此之外,Proxima SE自帶離線構建與批量導入的工具。

圖11Proxima SE 支持數據庫生態與工具
2、案例分享
Proxima SE 擁有線上線下的多個項目經驗,歷經時間與業務的打磨,擁有服務外部客户的能力。
線上是以人工智能與機器學習為代表的圖搜與地址標準化。圖像搜索(Image Search)是一款用於圖片間相似性檢索的平台型產品。圖像搜索以深度學習和機器視覺為核心,提取圖片內容特徵、建立圖像搜索引擎,可廣泛應用於拍照購物、商品推薦、版權保護等場景。地址標準化(Address Purification)是一站式閉環地址數據處理和服務平台產品。
圖12 Proxima SE 代表使用案例
Proxima SE 已經開放試用,目前提供線上服務PAI-EAS以及軟件化版本兩種方式,歡迎大家使用體驗它的功能特色!我今天的分享就到這裏,謝謝大家。
- 線上服務PAI-EAS:https://help.aliyun.com/document_detail/462062.html
- 軟件化版本下載方式:https://www.yuque.com/proxima-se/document/user_guide
點擊查看本場直播視頻回放與PPT資料
視頻回放:https://www.modb.pro/video/7522
PPT:https://www.modb.pro/doc/82262
- 查看原文:https://www.modb.pro/db/566334
墨天輪技術社區正在舉辦【有獎問卷|墨天輪2022年數據庫大調查】活動,誠邀各位朋友參與!只要以【賬號登錄狀態】提交問卷即可獲得獎勵,更有機會獲得大疆DJI無人機、VIP年卡、電腦支架等獎品。邀請好友填寫還可以領取現金獎勵!期待大家的參與!
點擊即可填寫:https://www.modb.pro/event/767





