本文為墨天輪數據庫管理服務團隊第52期技術分享,內容原創,作者為技術顧問muggle,如需轉載請聯繫小墨(VX:modb666)並註明來源。
1、適用範圍
達夢數據產品:DM8
2、表設計優化
表設計優化可以從三個方面入手:選擇合適的表類型、設置分區表、設置全局臨時表。
2.1 表類型選擇
達夢數據庫提供了三種表類型:行存儲表、列存儲表(HUGE)和堆表。運維人員可根據實際需求選擇合適的表類型。
| 表類型 | 描述 | 主要特徵 | 適用場景 |
|---|---|---|---|
| 行存儲表 | 行存儲是以記錄為單位進行存儲的,數據頁面中存儲的是完整的若干條記錄 | 1.按行存儲 2.每個表都創建一個 B 樹,並在葉子上存放數據 | 適用於高併發 OLTP 場景。 |
| 列存儲表(HUGE) | 列存儲是以列為單位進行存儲的,每一個列的所有行數據都存儲在一起,而且一個指定的頁面中存儲的都是某一個列的連續數據。 | 1.按列存儲 2.非事務型 HUGE 表:LOG NONE、LOG LAST、LOG ALL3.事務型 HUGE 表 | 適用於海量數據分析場景 |
| 堆表 | 堆表是指採用了物理 ROWID 形式的表,即使用文件號、頁號和頁內偏移而得到 ROWID 值,這樣就不需要存儲 ROWID 值,可以節省空間 | 1.數據頁都是通過鏈表形式存儲 2.可設置併發分支 | 併發插入性能較高 |
2.2 水平分區表
(1)分區類型
- 範圍(range)水平分區:對錶中的某些列上值的範圍進行分區,根據某個值的範圍,決定將該數據存儲在哪個分區上;
- 哈希(hash)水平分區:通過指定分區編號來均勻分佈數據的一種分區類型,通過在 I/O 設備上進行散列分區,使得這些分區大小基本一致;
- 列表(list)水平分區:通過指定表中的某個列的離散值集,來確定應當存儲在一起的數據。例如,可以對錶上的 status 列的值在(‘A’,‘H’,‘O’)放在一個分區,值在(‘B’,‘I’,‘P’)放在另一個分區,以此類推;
- 多級分區表:按上述三種分區方法進行任意組合,將表進行多次分區,稱為多級分區表。
(2)分區優勢
- 減少訪問數據
- 操作靈活:可以操作分區 truncate、分區 drop、分區 add、分區 exchange
(3)舉例説明
select *
from range_part_tab
where deal_date >= TO_DATE('2019-08-04','YYYY-MM-DD')
and deal_date <= TO_DATE('2019-08-07','YYYY-MM-DD');執行計劃:
1 #NSET2:[24,18750,158]
2 #PRJT2:[24,18750,158];exp_num(6),is_atom(FALSE)
3 #PARALLEL:[24,18750,158];scan_type(GE_LE),key_num(0,1,1)
4 #SLCT2:[24,18750,158];[(RANGE_PART_TAB.DEAL_DATE >= var2 AND RANGE_PART_TAB.DEAL_DATE <= var4)]
5 #CSCN2:[73,500000,158];INDEX33555933(RANGE_PART_TAB)
--#PARALLEL:控制水平分區子表的掃描- 對主表和所有子表都收集統計信息
- 對索引收集統計信息
注意:如果 SQL 中有可利用的索引,普通表也可能比分區表性能高。
2.3 . 全局臨時表
當處理複雜的查詢或事務時,由於在數據寫入永久表之前需要暫時存儲一些行信息或需要保存查詢的中間結果,可能需要一些表來臨時存儲這些數據。DM 允許創建臨時表來保存會話甚至事務中的數據。在會話或事務結束時,這些表上的數據將會被自動清除。
(1)全局臨時表類型
- 事務級-ON COMMIT DELETE ROWS
- 會話級-ON COMMIT PRESERVE ROWS
(2)全局臨時表優勢
- 不同 session 數據獨立
- 自動清理
(3)舉例説明
第一步:原始語句如下:
--T_1 視圖(與 oracle 的 dblink 全表查詢)
--T_1 視圖的結構為
--(INIT_DATE int , BRANCH_NO int , FUND_ACCOUNT int , BUSINESS_FLAG int , remark varchar(32))
--T_2 表
--T_2 表的結構為
--(BRANCH_NO int,FUND_ACCOUNT int , prodta_no int,v_config_4662 varchar(32))
select a.init_date as oc_date,a.BRANCH_NO,a.FUND_ACCOUNT,a.BUSINESS_FLAG,a.remark,b.BRANCH_NO,b.FUND_ACCOUNT,b.prodta_no
from T_1 a,T_2 b
where init_date = 20181120
AND a.BRANCH_NO = b.BRANCH_NO
AND a.FUND_ACCOUNT = b.FUND_ACCOUNT
and instr(v_config_4662, ',' || b.prodta_no || ',')>0
and a.BUSINESS_FLAG in (2629,2630)
and nvl(a.remark,' ')not like '%實時TA%';第二步:創建臨時表 T1\_20181122,將 T\_1 視圖中部分數據插入臨時表中。
CREATE GLOBAL TEMPORARY TABLE "T1_20181122"
(init_date int, BRANCH_NO int, FUND_ACCOUNT int,BUSINESS_FLAG int,remark varchar(32));
--插入dblink獲取的數據到臨時表
insert into T1_20181122
select *
from T_1 a
where init_date = 20181120
and a.BUSINESS_FLAG in (2629,2630)
and nvl(a.remark,' ')not like '%實時TA%';第三步:語句改寫
select a.init_date as oc_date,a.BRANCH_NO,a.FUND_ACCOUNT,a.BUSINESS_FLAG,a.remark,b.BRANCH_NO,b.FUND_ACCOUNT,b.prodta_no
from T1_20181122 a, T_2 b
where a.BRANCH_NO = b.BRANCH_NO
AND a.FUND_ACCOUNT = b.FUND_ACCOUNT
and instr(v_config_4662, ',' || b.prodta_no || ',')>0;執行計劃:50 分鐘 >>1 分鐘
--原語句執行計劃
1 #NSET2:[11,1,1644]
2 #PRJT2:[11,1,1644];exp_num(41),is_atom(FALSE)
3 #HASH2 INNER JOIN:[11,1,1644];KEY_NUM(2);
4 #SLCT2:[0,1,270];exp11>0
5 #CSCN2:[0,1,270];INDEX33560908(T_HSOTCPRODCASHACCT as B)
6 #HASH RIGHT SEMI JOIN2:[10,380,1374];n_keys(1)
7 #CONST VALUE LIST:[0,2,30];row_num(2),col_num(1),
8 #SLCT2:[10,380,1374];(A.INIT_DATE = var4 AND NOT(exp11 LIKE '%實時TA%'))
9 #PRJT2:[10,1000,1374];exp_num(13),is_atom(FALSE)
10 #REMOTE SCAN:[0,0,0] HIS_FUNDJOUR@HS08HIS
--改寫後執行計劃
1 #NSET2: [1, 1, 124]
2 #PRJT2: [1, 1, 124]; exp_num(8), is_atom(FALSE)
3 #HASH2 INNER JOIN: [1, 1, 124]; KEY_NUM(2); KEY(B.BRANCH_NO=A.BRANCH_NO AND B.FUND_ACCOUNT=A.FUND_ACCOUNT) KEY_NULL_EQU(0, 0)
4 #SLCT2: [1, 1, 60]; exp11 > 0
5 #CSCN2: [1, 1, 60]; INDEX33555476(T_2 as B)
6 #CSCN2: [1, 1, 64]; INDEX33555478(T1_20181122 as A)3、索引優化
索引是一種特殊的數據庫結構,由數據表中的一列或多列組合而成,可以用來快速查詢數據表中有某一特定值的記錄。
索引結構:最常見的索引結構為 B*樹索引,存儲結構如下圖所示:
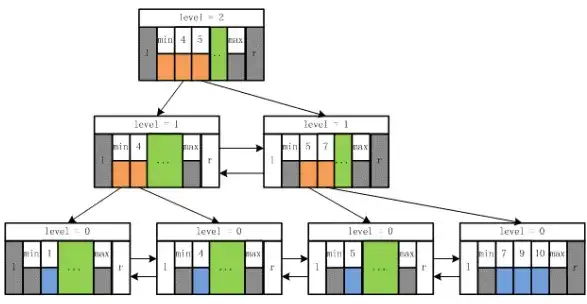
最頂層的為根節點,最底層的為葉子節點,中間層為內節點。實際使用當中一般不止 3 層(取決於數據量大小),除根節點以及葉子節點以外僅為內節點。對於一個 m 階(本例中 m=2)的 B*樹存儲結構有以下幾個特點:
- 每個結點最多有 m 個子結點。
- 除了根結點和葉子結點外,每個結點最少有 m/2(向上取整)個子結點。
- 如果根結點不是葉子結點,那根結點至少包含兩個子結點。
- 所有的葉子結點都位於同一層。
- 每個結點都包含 k 個元素,這裏 m/2 ≤ k < m,這裏 m/2 向下取整。
- 每個節點中的元素從小到大排列。
- 每個元素左結點的值都小於或等於該元素,右結點的值都大於或等於該元素。
- 所有的非葉子節點只存儲關鍵字信息。
- 所有的葉子結點中包含了全部元素的信息。
- 所有葉子節點之間都有一個鏈指針。
可以看出在該存儲結構中查找特定數據的算法複雜度為 O(log2N),查找速度僅與樹高度有關。 對於聚集索引葉子節點存儲的元素是數據塊即為整行數據,對於非聚集索引葉子節點存儲的元素是索引字段的所對應的聚集索引的值或 rowid,如果需要獲取其它字段信息需要根據聚集索引的值或 rowid 回表 (BLKUP) 進行查詢。
索引適用範圍:
在以下場景下可考慮創建索引:
- 僅當要通過索引訪問表中很少的一部分行(1%~20%)。
- 索引可覆蓋查詢所需的所有列,不需額外去訪問表。
注意:對於一個表來説索引並非越多越好,過多的索引將影響該表的 DML 效率。
存在下列情況將導致無法使用索引:
- 組合索引中,條件列中沒有組合索引的首列。
- 條件列帶有函數或計算。
- 索引排序是按照字段值進行排序的,字段值通過函數或計算後的值索引無法獲取。
- 索引過濾性能不好時。
例如對一張 10 萬條記錄的表進行條件查詢,獲取 5 萬條數據,通過索引進行查找效率低於全表掃描,將放棄使用索引。
建立索引的原則:
- 建立唯一索引。唯一索引能夠更快速地幫助我們進行數據定位;
- 為經常需要進行查詢操作的字段建立索引;
- 對經常需要進行排序、分組以及聯合操作的字段建立索引;
- 在建立索引的時候,要考慮索引的最左匹配原則(在使用 SQL 語句時,如果 where 部分的條件不符合最左匹配原則,可能導致索引失效,或者不能完全發揮建立的索引的功效);
- 不要建立過多的索引。因為索引本身會佔用存儲空間;
- 如果建立的單個索引查詢數據很多,查詢得到的數據的區分度不大,則考慮建立合適的聯合索引;
- 儘量考慮字段值長度較短的字段建立索引,如果字段值太長,會降低索引的效率。
4、SQL 語句改寫
DM 數據庫針對 SQL 語句有以下常見幾種改寫方法:
4.1 優化 GROUP BY
提高 GROUP BY 語句的效率,可以在 GROUP BY 之前過濾掉不需要的內容。
--優化前
SELECT JOB,AVG(AGE) FROM TEMP
GROUP BY JOB HAVING JOB = 'STUDENT' OR JOB = 'MANAGER';
--優化後
SELECT JOB,AVG(AGE) FROM TEMP
WHERE JOB = 'STUDENT' OR JOB = 'MANAGER' GROUP BY JOB;4.2. 用 UNION ALL 替換 UNION**
當 SQL 語句需要 UNION 兩個查詢結果集合時,這兩個結果集合會以 UNION ALL 的方式被合併,在輸出最終結果前進行排序。用 UNION ALL 替代 UNION, 這樣排序就不是必要了,效率就會因此得到提高。
注意:UNION 將對結果集合排序,這個操作會使用到 SORT\_AREA\_SIZE 這塊內存,對於這塊內存的優化也很重要;UNION ALL 將重複輸出兩個結果集合中相同記錄,要從業務需求判斷使用 UNION ALL 的可行性。
--優化前
SELECT USER_ID,BILL_ID FROM USER_TAB1 WHERE AGE = '20'
UNION
SELECT USER_ID,BILL_ID FROM USER_TAB2 WHERE AGE = '20';
--優化後
SELECT USER_ID,BILL_ID FROM USER_TAB1 WHERE AGE = '20'
UNION ALL
SELECT USER_ID,BILL_ID FROM USER_TAB2 WHERE AGE = '20';4.3. 用 EXISTS 替換 DISTINCT
當 SQL 包含一對多表查詢時,避免在 SELECT 子句中使用 DISTINCT,一般用 EXISTS 替換 DISTINCT 查詢更為迅速。
--優化前
SELECT DISTINCT USER_ID,BILL_ID FROM USER_TAB1 D,USER_TAB2 E
WHERE D.USER_ID= E.USER_ID;
--優化後
SELECT USER_ID,BILL_ID FROM USER_TAB1 D WHERE EXISTS(SELECT 1 FROM USER_TAB2 E WHERE E.USER_ID= D.USER_ID);4.4. 多使用 COMMIT
可以在程序中儘量多使用 COMMIT,這樣程序的性能得到提高,需求也會因為 COMMIT 所釋放的資源而減少。 COMMIT 所釋放的資源:
- 回滾段上用於恢復數據的信息;
- 被程序語句獲得的鎖;
- redo log buffer 中的空間;
- 為管理上述 3 種資源中的內部花銷。
4.5 用 WHERE 子句替換 HAVING 子句
避免使用 HAVING 子句,HAVING 只會在檢索出所有記錄之後才對結果集進行過濾,這個處理需要排序、總計等操作,可以通過 WHERE 子句限制記錄的數目。on、where、having 三個都可以加條件子句,其中,on 是最先執行,where 次之,having 最後。
- on 是先把不符合條件的記錄過濾後才進行統計,在兩個表聯接時才用 on;
- 在單表查詢統計的情況下,如果要過濾的條件沒有涉及到要計算字段,where 和 having 結果是一樣的,但 where 比 having 快
- 如果涉及到計算字段,where 的作用時間是在計算之前完成,而 having 是在計算後才起作用,兩者的結果會不同;
- 在多表聯接查詢時,on 比 where 更早起作用。首先會根據各個表之間的關聯條件,把多個表合成一個臨時表後,由 where 進行過濾再計算,計算完再由 having 進行過濾。
4.6. 用 TRUNCATE 替換 DELETE
當刪除表中的記錄時,在通常情況下, 回滾段用來存放可以被恢復的信息。如果沒有 COMMIT 事務,會將數據恢復到執行刪除命令之前的狀況;而當運用 TRUNCATE 時,回滾段不再存放任何可被恢復的信息。當命令運行後,數據不能被恢復。因此很少的資源被調用,執行時間也會很短。
注意:TRUNCATE 只在刪除全表適用,TRUNCATE 是 DDL 不是 DML。
4.7. 用 EXISTS 替換 IN、用 NOT EXISTS 替換 NOT IN
在基於基礎表的查詢中可能會需要對另一個表進行聯接。在這種情況下, 使用 EXISTS (或 NOT EXISTS )通常將提高查詢的效率。在子查詢中,NOT IN 子句將執行一個內部的排序和合並。無論在哪種情況下,NOT IN 都是最低效的(要對子查詢中的表執行一個全表遍歷),所以儘量將 NOT IN 改寫成外連接( Outer Joins )或 NOT EXISTS。
--優化前
SELECT A.* FROM TEMP(基礎表) A WHERE AGE > 0
AND A.ID IN(SELECT ID FROM TEMP1 WHERE NAME ='TOM');
--優化後
SELECT A.* FROM TEMP(基礎表) A WHERE AGE > 0
AND EXISTS(SELECT 1 FROM TEMP1 WHERE A.ID= ID AND NAME='TOM');參考內容:DM8官方文檔

墨天輪從樂知樂享的數據庫技術社區蓄勢出發,全面升級,提供多類型數據庫管理服務。墨天輪數據庫管理服務旨在為用户構建信賴可託付的數據庫環境,併為數據庫廠商提供中立的生態支持。
服務官網:https://www.modb.pro/service