









“數據架構”這個詞,搞數據的同行們天天都在説。
但你真的能一句話講清楚它到底是啥、為啥那麼重要、又該怎麼設計嗎?
是不是一提到它,腦子裏就蹦出來一堆技術名詞和分層模型,比如 ODS、DWD、DWS、ADS?
打住!數據架構可遠不只是技術的堆砌。
今天,我就拋開那些模糊的概念和花哨的術語,用大白話手把手拆解數據架構的核心邏輯——
- 數據架構到底是什麼?
- 為什麼需要數據架構?它有什麼作用?
- 該怎麼設計數據架構才能真正幫到業務?
讀完這篇,保證你能把數據架構講得明明白白!
一、數據架構到底是什麼
很多人一提到數據架構,第一反應就是:
"不就是數據分層嗎?ODS→DWD→DWS→ADS,再套個Lambda架構或者Kappa架構?"
這種想法:
把數據架構弄窄了,當成了技術組件的排列組合,卻忘了它的本質是連接業務目標和技術實現的"數字骨架"。
説個實際點的例子:
一家連鎖超市想搞"千店千面"的選品策略,需要的數據可能來自:
- POS系統(實時銷量)
- 會員系統(消費偏好)
- 天氣平台(區域氣温)
- 供應鏈(庫存週轉)
這些數據得先預處理:
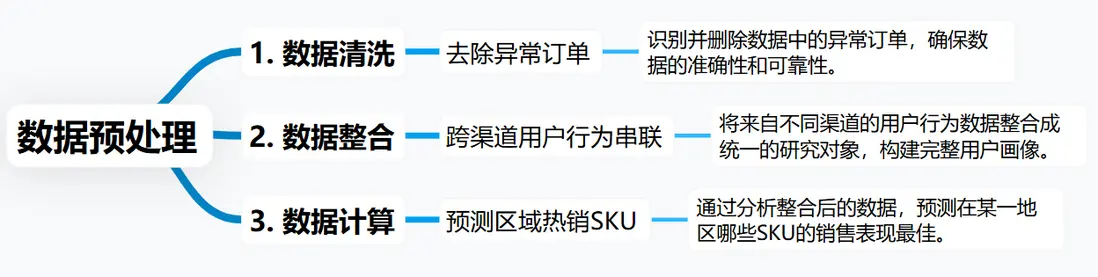
最後才能給到前端APP的選品推薦模塊。
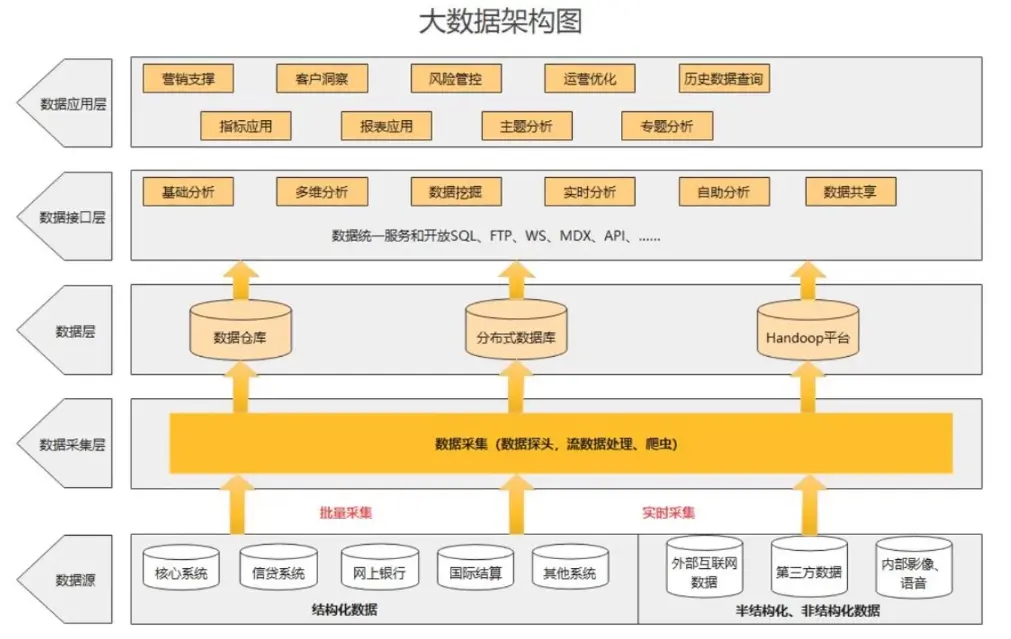
支撐這個流程的,不是單一的數據庫或ETL工具,而是一整套邏輯:
- 數據從哪來(多源異構數據的接入標準得明確);
- 存什麼、怎麼存(哪些進數據湖、哪些進數據倉、哪些放實時緩存裏);
- 如何加工(批量處理和實時計算的邊界得劃清);
- 怎麼用(API接口的權限要控制,業務人員得能自己取數);
- 如何管(數據質量誰負責、元數據怎麼追蹤、血緣關係怎麼監控)。
這些問題的答案,合在一起才是數據架構的核心。
所以説:
數據架構不是一成不變的技術藍圖,是跟着業務目標、數據規模、技術發展隨時調整的"活系統"。它得跟着企業的實際情況動,不是建完就萬事大吉了。
二、數據架構設計的四個關鍵維度
明白了數據架構的本質,接下來就得解決"怎麼設計"的問題。
傳統方法常把數據架構分成"採集-存儲-處理-服務-治理"五層,但這麼分容易讓人鑽進"技術至上"的牛角尖。
我從實戰裏總結出四個關鍵維度,能覆蓋從業務需求到落地的全流程。
1. 責任分明的分層設計
數據分層包括:
- ODS原始層
- DWD明細層
- DWS彙總層
- ADS應用層
本質是通過分層降低複雜度,把各層的責任邊界劃清楚。
但很多企業在分層設計上容易出兩個問題:
- 分層太細:比如把DWD層再拆成"基礎明細層""公共明細層",結果ETL任務鏈變得老長,調試起來費時又費力;
- 分層混亂:業務人員直接從ODS層取數,跳過明細層和彙總層,導致重複計算,而且數據口徑也對不上。
説白了,正確的分層邏輯應該是"按使用場景劃分責任主體":

所以説:
分層的關鍵不在技術實現,而在通過責任分離減少跨團隊協作成本。
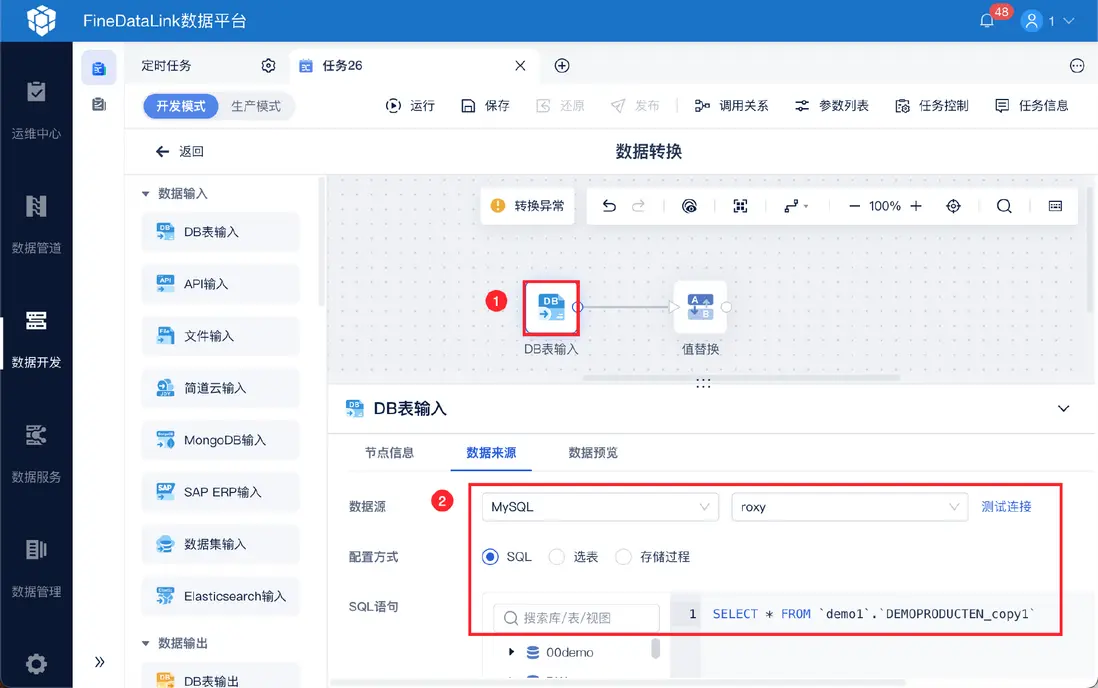
好的分層架構需要好工具落地。FineDataLink (FDL) 就是一個專注於一站式數據集成的平台,它操作簡單,拖拖拽拽就能完成數據抽取、清洗、轉換、整合、加載這些關鍵步驟,不用寫大量複雜代碼。
而且內置豐富的數據處理能力,比如自由組合清洗規則、數據去重、合併、拆分、聚合等等,能夠大大提高你處理數據的效率和準確性,讓你把精力更多放在數據分析和業務價值上。
2. 最合適的技術選型
數據架構的技術選型是很多人頭疼的事,比如:
- 用Hive還是Spark處理離線數據
- 用ClickHouse還是Doris做實時查詢
但實話實説,沒有哪種技術能解決所有場景的需求。
我總結了三條選型原則,你可以參考:
- 匹配數據特徵:如果數據是高併發、低延遲的(比如APP實時點擊流),用Kafka+Flink做流處理更合適;如果是T+1的批量數據(比如財務報表),用Spark+Hive會更穩定;
- 考慮團隊能力:如果團隊熟悉SQL生態,優先選Hudi/Delta Lake這類支持ACID的事務湖,別硬上ClickHouse集羣,不然維護起來費勁;
- 預留擴展空間:別過度依賴單一技術(比如全用HBase),可以通過湖倉一體(比如Apache Iceberg)實現"一份數據多場景用",降低被單一技術綁定的風險。
3. 全流程嵌入的治理體系
數據治理常被誤會成"貼標籤、建元數據、做質量檢查"。
但實際上:
60%的數據問題都是因為治理體系沒嵌到數據處理的全流程裏。
真正有用的治理,得包含三個關鍵動作:

4. 支撐業務的演進路徑
數據架構不是一錘子買賣,得跟着業務發展慢慢演進。
我觀察到三種典型的演進階段,你可以看看自己的團隊在哪個階段:
- 生存期(0-3年):業務擴張快,數據需求零散。這時候架構的核心是"快速支撐",允許一定冗餘,但得留着數據打通的可能;
- 發展期(3-5年):業務進入穩定期,數據問題集中爆發。這時候得"集中治理",通過湖倉一體平台把分散的數據整合起來,建立全局的數據標準和治理體系;
- 成熟期(5年以上):數據成了核心生產要素,得"智能驅動"。這時候架構要能支持AI能力,還得通過數據產品化,讓業務人員用起來更方便。
三、數據架構的三個常見誤區
在數據架構設計上,我見過太多"用力太猛"或"因小失大"的情況。下面這三個常見誤區,你可得避開:
1. 別為了"技術先進"丟了"業務價值"
很多企業盲目追新技術,剛接觸數據湖就想把數據倉全遷過去,或者為了搞實時計算,把所有ETL都改成流處理,結果開發成本漲了一大截,業務人員卻用不起來。
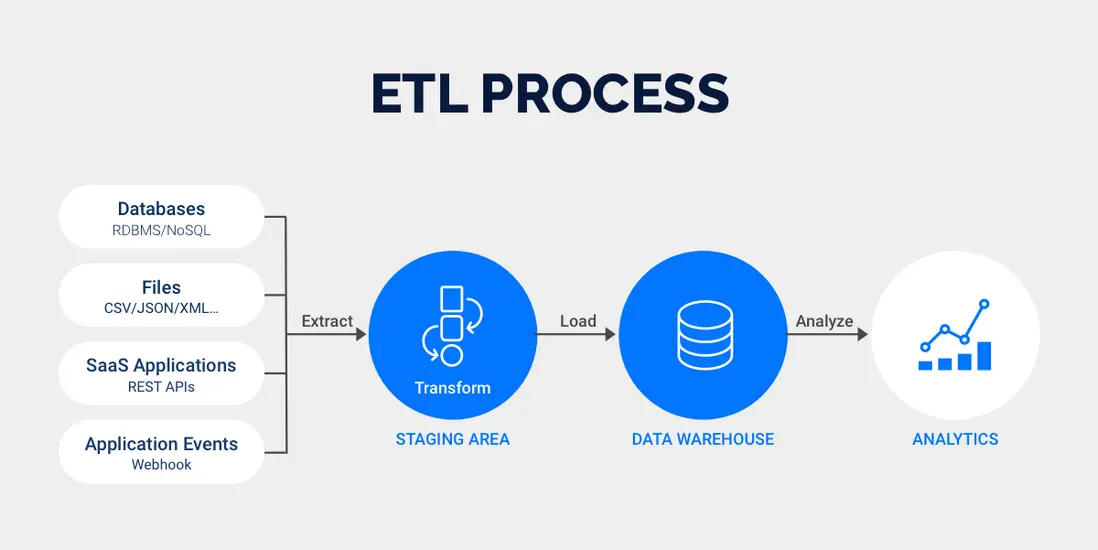
但實際上:
技術的價值是解決業務問題,不是用來證明自己多厲害。
如果:
一個業務的日數據量只有100GB,用Hive做批量處理比用Flink做實時計算更穩定、更省錢,沒必要非得用新技術。
2. 別把"數據治理"做成"面子工程"
有些企業花大價錢買元數據管理工具,做了漂亮的血緣圖譜,可數據質量問題還是不斷。
問題出在哪?
治理沒和業務流程綁在一起。比如:
用户信息修改,得經過數據質量校驗才能入庫,不能等數據進了湖再清洗。
所以説:
治理得"往前放",別等出了問題再補,那時候就晚了。
3. 別追求"完美架構",忘了"動態調整"
數據架構沒有"最優解",只有"最適合當前階段的解"。
之前找我諮詢的一家零售企業:
在業務擴張期,非要搞"大一統"的數據架構,要求所有業務線用統一的標籤體系。
結果呢?
生鮮事業部的"促銷敏感用户"標籤和美妝事業部的"復購週期"標籤合不到一起,反而拖慢了業務創新。
所以説:
好的架構得允許"局部最優",慢慢再整合,一口吃不成胖子。
總結
數據架構不是技術的堆砌,是業務的翻譯官——把業務目標變成數據需求,再把數據價值變成業務成果。
下次你再為數據架構頭疼時,不妨問問自己:
- 這套架構真的支撐了當前最核心的業務目標嗎?
- 數據從產生到使用的每個環節,責任都清楚嗎?
- 業務需求變了,架構能快速調整嗎?
想清楚這三個問題,你離"把數據架構講清楚"就不遠了。












