









本文整理自 IvorySQL 2025 生態大會暨 PostgreSQL 高峯論壇的演講分享,演講嘉賓:唐成,中啓乘數科技 CTO,資深 PostgreSQL 專家。
引言
AI 技術正從訓練轉向推理與應用,數據基礎設施面臨新的挑戰。傳統數據庫難以滿足 AI Agent 對實時性、多模態檢索和彈性擴展的需求。PostgreSQL 因其擴展性成為 AI 時代的數據基石,雲原生數據庫一體機通過存算分離和多模融合實現全場景覆蓋。本文探討 AI 時代數據庫一體機的演進路徑、關鍵技術及對智能應用的支撐作用。
我們當前的 AI 時代
- 訓練的時代接近尾聲,但訓練本身的問題依然存在,尤其是在存儲層面 HOW225。
- Inference(推理):如何以高效、低成本的方式透出模型能力。
- Database for Al Application:db4aia,如何支撐上下文管理、向量檢索、數據調用與語義理解等數據層能力。
- Agent 數量快速增長,數據底座成核心支撐。
- Al Agent 正在大量創建數據庫。
- Inference(推理)和數據應用正在成為新焦點。
- PostgreSQL:新興數據庫的共識基石。
AI 時代的 MCP 技術
MCP 起源於 2024 年 11 月 25 日 Anthropic 發佈的文章:Introducing the Model Context Protocol。
MCP ( Model Context Protocol ,模型上下文協議)定義了應用程序和 AI 模型之間交換上下文信息的方式。這使得開發者能夠以一致的方式將各種數據源、工具和功能連接到 AI 模型(一箇中間協議層),就像 USB-C 讓不同設備能夠通過相同的接口連接一樣。MCP 的目標是創建一個通用標準,使 AI 應用程序的開發和集成變得更加簡單和統一。
MCP 的核心組件
- 模型( Model ):LLMs 是這個框架的引擎,負責生成最終的輸出。用户可以通過“客户端”(如 Claude 桌面應用、IDE 或聊天機器人)訪問模型。
- 上下文(Context):這是模型回答問題時所需的額外信息,存儲在“服務器”中。服務器可以是 Google Drive、GitHub 倉庫、郵箱或 PDF 文件等。
- 協議(Protocol):這是一套規則,允許模型訪問不同的外部工具和 API,以獲取與查詢相關的上下文信息。
AI 時代的 RAG 技術
RAG 技術解決大模型的不精確問題,RAG 系統的工作流程可以分為以下幾個步驟:
- 查詢(Query):用户的輸入作為 RAG 系統的查詢。
- 檢索(Retrieval):在 LLMs 生成回答之前,RAG 系統會檢索與查詢相關的知識庫,找到最相關的信息。
- 增強(Augmentation):將檢索到的相關信息與原始查詢結合,形成增強後的輸入。
- 生成(Generation):LLMs 根據增強後的輸入生成更準確、更相關的回答,並將結果反饋給用户。
RAG 為 LLMs 提供了更豐富的知識,那麼 MCP(Model Context Protocol,模型上下文協議)則賦予了 LLMs 行動的能力。2024 年,Anthropic 推出了 MCP,而在 2025 年,它終於得到了全世界的認可。MCP 允許 LLMs 實時連接外部工具、API 和數據源,這一開放標準讓 LLMs 不再侷限於文本生成,而是能夠執行操作、觸發工作流,並獲取最新信息以支持決策。
RAG 的系統架構
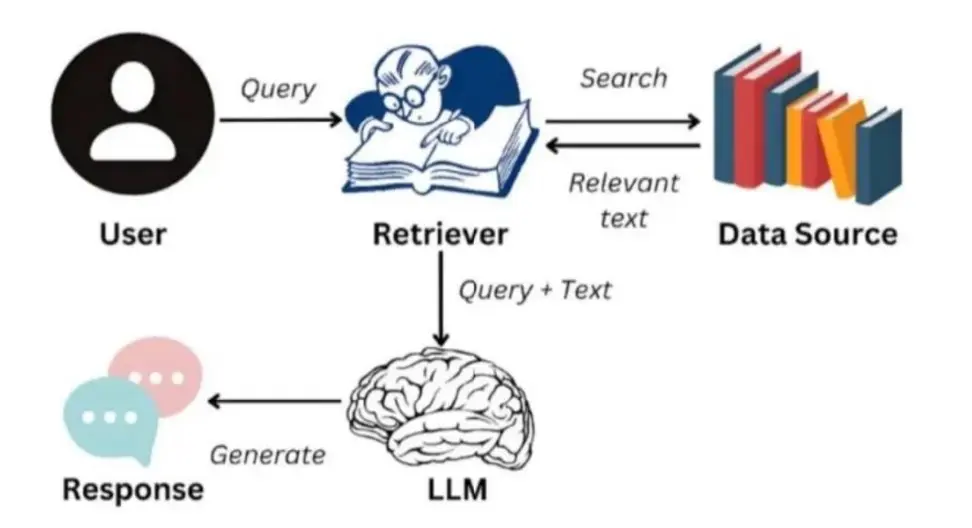
RAG 架構通過將用户查詢與從知識庫中檢索到的相關信息相結合,再輸入大語言模型生成響應,顯著提升了輸出的準確性和可靠性。
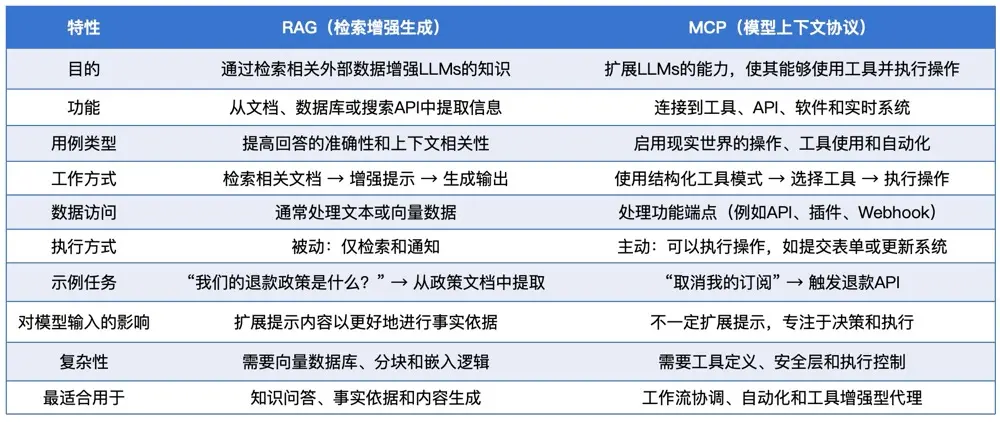
RAG 技術與 MCP 技術的比較
Google Agent To Agent
A2A 是 Google 推出的一個開放通信協議,旨在讓 AI 代理(Agent)之間可以互相溝通、協作、派發任務,並同步結果。它解決的核心問題是:“多個智能體如何像一個團隊一樣配合工作?”想象你是一個項目經理(AI Agent A),你指派另一個人(AI Agent B)去完成任務、實時查看進度、獲取結果。
A2A 提供了一整套標準化接口與數據結構,主要包括:
- 任務發送(Task Initiation):任何 Agent 都可以通過 tasks/send 或 tasks/sendSubscribe 向另一個 Agent 發出任務請求。
- 任務狀態跟蹤(Lifecycle & Streaming):任務有完整的狀態生命週期(如:submitted → working →completed)。若使用 sendSubscribe,Agent 可以訂閲 SSE(Server-Sent Events)接收狀態更新。
- 獲取結果(Artifacts):任務完成後,執行方返回一個 artifact 對象,內部是若干 part 組成的內容單元(文本、結構化數據、文件等)。
-
Agent 能力暴露(AgentCard): 每個 Agent 都需要提供一個標準的能力描述文件
/.well-known/agent.json,用於被發現和訪問。其中包含:- 支持的方法
- 身份驗證方式
- 輸入輸出格式
- streaming/push 支持與否等
A2A 使用總結:

- 發現對方 Agent(通過 agent.json)。
- 發起任務(send /sendSubscribe)。
- 訂閲狀態流/等待同步返回。
- 獲取結果/交互補充。
- 完成或失敗。
在大模型時代,Agent to Agent 與 MCP 架構正推動 AI 向智能體協同演進。其核心在於 AI 可自主調用外部系統獲取實時準確信息,例如查詢天氣或企業數據時,不再依賴模型自身生成,而是通過語義解析後實時接入專業接口或數據庫返回結果。當前這兩種架構仍處於競爭與發展階段,未來每個應用均可能以智能體形態運行,實現更高效可靠的外部系統集成與多智能體協作。
數據庫一體機:數據庫的超融合
- 第一代:Exadata 一體機。
- 第二代:雲時代和超融合架構的一體機。
- 第三代:AI 時代的數據庫一體機。
傳統時代的數據庫一體機
數據庫一體機
數據庫一體機是一種集成了數據庫管理系統、服務器和存儲設備於一身的硬件設備。傳統上,企業需要單獨購買和維護數據庫服務器和存儲設備,然後安裝和配置數據庫軟件,這個過程非常繁瑣。而數據庫一體機的出現,將這些組件進行了集成,極大地降低了部署和管理的複雜性。其特點是:
- 一體化設計。
- 高性能。
- 可擴展性。
- 易用性。
- 高可用性。
數據庫一體機的優勢
相比傳統的數據庫部署方式,數據庫一體機具有以下幾個明顯的優勢:
- 快速部署:數據庫一體機提供一鍵式部署,省去了繁瑣的硬件和軟件配置過程,縮短了部署週期,快速上線。
- 高性能:數據庫一體機採用專用硬件和優化軟件,提供了卓越的性能表現,能夠滿足大規模數據處理和高併發訪問的需求。
- 成本節省:數據庫一體機的一體化設計和集成化管理,減少了硬件設備的購買和維護成本,降低了人力資源的投入。
- 易於管理:數據庫一體機提供統一的管理界面和工具,簡化了數據庫的配置和管理流程,減少了運維人員的工作負擔。
- 可靠性高:數據庫一體機採用冗餘設計和自動故障恢復機制,保證了系統的高可用性和數據的安全性,降低了業務中斷的風險。
數據庫一體機的架構

傳統時代一體機的任務:去 IOE
在推進去"IOE"的過程中,國產存儲架構實現了從封閉走向開放的重要轉型。早期採用數據庫一體機來替國產存儲通過去"IOE"實現從封閉走向開放。早期用數據庫一體機替代小型機和高端存儲,突破傳統集中存儲的性能瓶頸與擴展限制。現在基於國產服務器和 100G 網絡的分佈式存儲,採用 SSD/NVM 介質,實現高性能、彈性擴展和開放兼容,支撐數據庫雲化,完成從專用到通用的轉型。
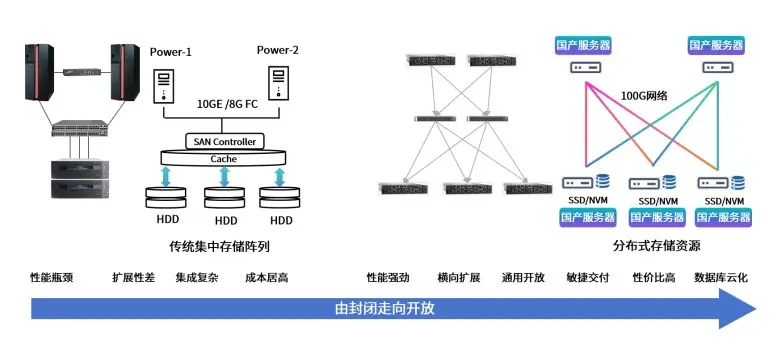
傳統時代一體機的任務:解決性能問題
- RDMA:高性能 RDMA 訪問協議,高 IO,低 CPU 開銷。
- ROCE:RDMA 的一種通用實現。
- Infiniband:高性能、高帶寬、高吞吐、低時延的 IB 底層網絡通道。
- NVME:高性能閃存 SSD、NVME,高 IO,高效存儲。
高性能的存儲軟件是關鍵
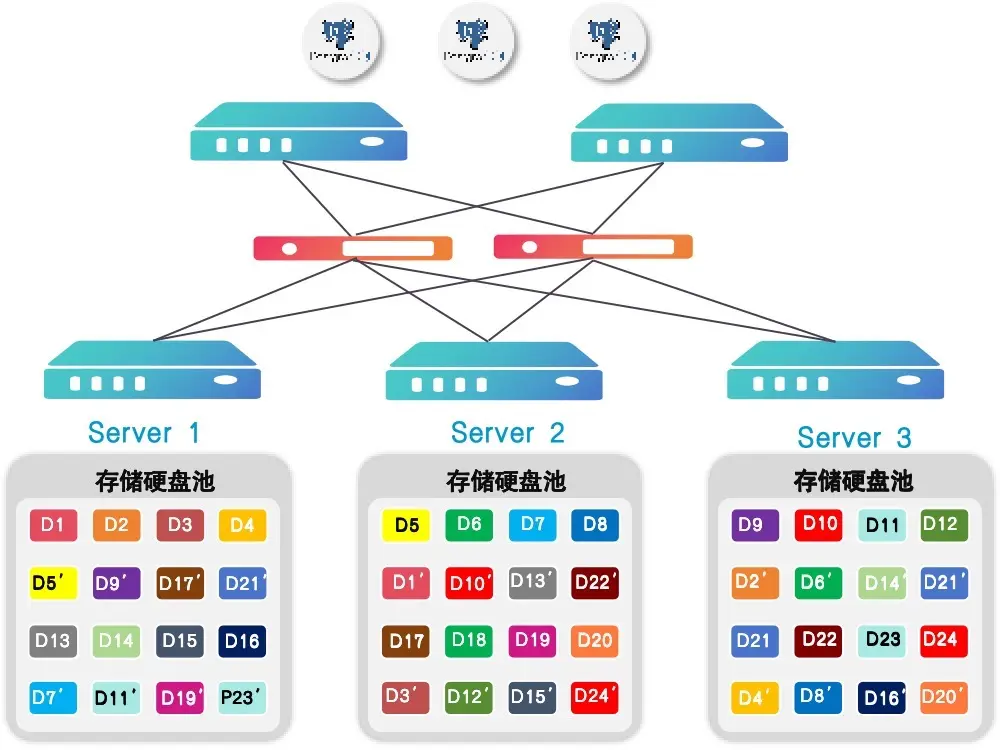
- 需要提供跨機器的多副本。
- 基於 Oracle 的數據庫一體機,多副本是依賴於 Oracle ASM 技術。
- 部分一體機是使用改造的 ceph。
- 高性能是關鍵。
實現情況
-
ceph:基於 tcp/ip 的性能最低。
優點:可以建快照和 clone。
-
iSCSI:性能低。
優點:非常成熟,對硬件無要求,只要能滿足 TCP 網絡時,就可以使用此 10 模式。穩定可靠。
缺點:延遲高,在大吞吐下消耗 CPU 高。
-
iSER:性能中等。
優點:非常成熟,延遲相對低。
缺點:要求 RDMA 網絡可以使用 RoCE 或 infiniband。性能達不到極致。
- NVME OF Fabric:性能高,延遲低。
- SPDK:性能高,延遲極低。對 CPU 核的完全佔用。
雲時代的數據庫一體機
雲時代一體機的任務:提高資源利用率
在雲時代,存儲架構的核心任務從解決性能問題轉向提升資源利用率。存儲架構的核心任務從提升性能轉向提高資源利用率。早期通過數據庫一體機實現去 IOE,替代了傳統煙囱式架構的小型機和高端存儲。如今採用分佈式存儲和資源池化技術,打破了資源隔離,實現了彈性擴展和高資源利用率,支持數據庫雲化,完成從煙囱式架構到資源池的戰略轉型。
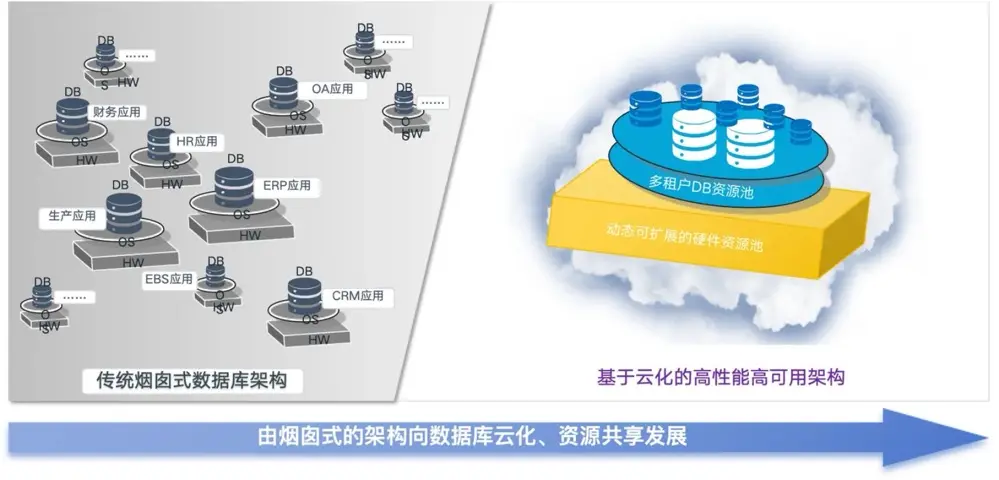
雲時代一體機:需要增加雲管平台
過去要實現數據庫高隔離,得靠物理機、虛擬機,或在數據庫裏做受限於自身的多租户。但現在雲時代,資源池化能按負載選隔離模式,多租户也能在高效用資源時保障數據隔離,輕鬆平衡隔離性與資源效率。
- 資源池化:根據負載支持 3 種隔離模式。
- 彈性資源:動態擴展應對潮汐系統請求。
- 多租户:資源最大化同時保證數據隔離。
- 多數據庫支持:支持多個數據庫集中管理。
- 性能水平擴展:數據庫讀寫能力的水平擴展。
- 統一運維:統一規範、簡化運維。
雲時代的技術
這個時代的數據庫一體機就是一朵雲:
- 計算虛擬化:數據庫跑在虛擬機中。
- 存儲虛擬機:更靈活的存儲。如對象存儲。
- 網絡虛擬化:虛擬網絡。
狹義的雲原生定義
- 雲原生是一種構建和運行應用程序的方法,是一套技術體系和方法論。
- Cloud 表示應用程序位於雲中,而不是傳統的數據中心;Native 表示應用程序從設計之初即考慮到雲的環境,原生為雲而設計,在雲上以最佳姿勢運行,充分利用和發揮雲平台的彈性+分佈式優勢。
- Native 表示應用程序從設計之初即考慮到雲的環境,原生為雲而設計,在雲上以最佳姿勢運行,充分利用和發揮雲平台的彈性+分佈式優勢。
- 雲元素的四要素:微服務、容器化、DevOps、持續交付。
雲時代的數據倉庫
雲時代數據倉庫正向 HTAP 架構演進,實現數倉與分析業務融合。關鍵技術包括:
- 基於對象存儲的存算分離技術。
- 更高效的 CDC。
- 流式實時計算和批計算融合。
雲時代催生了雲原生數據庫
雲時代催生了雲原生數據庫的快速發展,其中 serverless 技術成為公有云平台的典型特徵。與傳統擴容需要階梯式增加節點不同,serverless 實現了資源的平滑彈性擴縮,這是雲時代給數據庫架構帶來的重要變革。結合容器技術,雲原生數據庫實現了真正的彈性能力,徹底改變了傳統數據庫的運維模式。
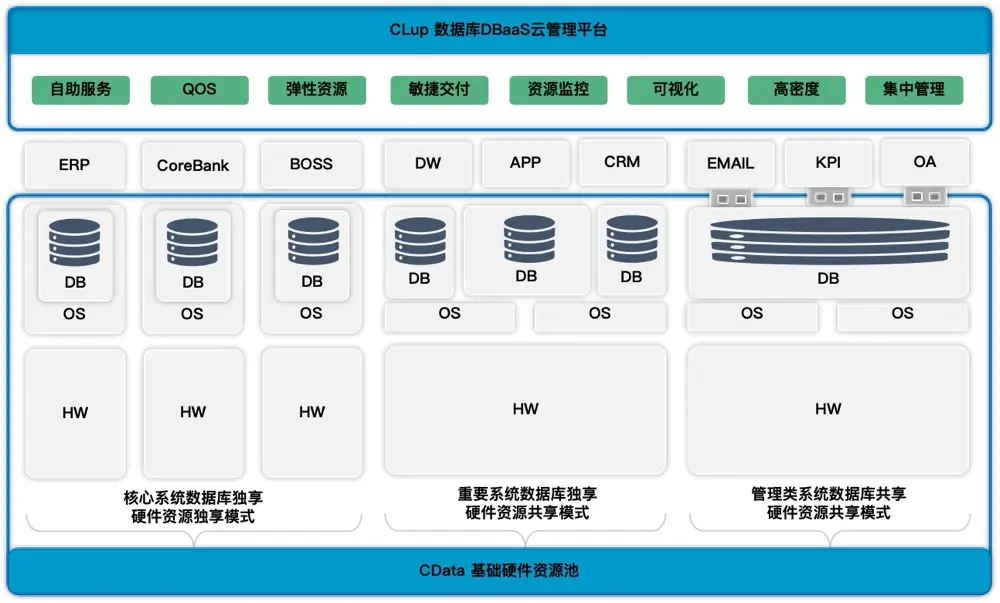
AI 時代的數據庫一體機
AlloyDB For PostgreSQL
- AI Agent 正在大量創建數據庫:需要雲模式的一體機。
- Agent 數量快速增長,數據底座成為核心支撐:需要一體機。
- 這一場景要求數據庫支持多模查詢。
AI 時代對數據庫查詢的變化
AI workflow 從數據庫、應用日誌、埋點系統、攝像頭、視頻等來源收集數據;傳統數據通過清洗與轉換進行加工進入數據庫;對於圖片、視頻、語音的數據經過向量化處理進入向量數據庫。加工後的數據然後由數據工程師或算法專家進行探索與分析,做出參數調整等關鍵決策。當這些數據準備充分後,結合大模型的能力,便可實現下一階段的重要能力。
Multi-Modal Retrieval:即多模檢索,是下一代智能檢索的標配
Multi-Modal Retrieval 的核心含義是:在數據檢索過程中,不再侷限於某一種查詢方式,而是融合結構化、半結構化、非結構化以及向量檢索等多種方式,實現更智能、更全面的查詢體驗。這項能力對於 AI 應用尤其重要。因為 Agent 面對的問題往往不是“查一條信息或者一個向量",而是需要對多個模態、多維數據進行理解、關聯和調用--這就需要底層數據庫具備原生的多模處理能力。
以“亞運會智能巡邏檢查"為例,我們需要在監控系統中檢索指定的巡邏車或人在城市的範圍內進行巡邏,最基礎的方式可能僅涉及向量檢索——比如通過圖片或視頻幀進行巡邏車和人的相似度匹配,以獲得巡邏的數據,僅獲得巡邏數據還是不行的,我們還需要檢索結構化的數據庫中的數據,進行智能比對,以便於我們分析巡邏的覆蓋面以及巡邏的弱點,以及如何做好優化。同時可能還會結合輿情,進行調整。
AI 多模式查詢的挑戰
多模態檢索對架構提出了更高要求,實現 Multi-Modal Retrieval 意味着系統必須同時處理結構化數據、半結構化數據(如 JSON)、向量數據,將多種模態數據統一存儲與檢索,消除系統間的分割,讓多模態查詢變得自然、實時且可擴展。
數據庫一體機的方向
AI 技術正在重塑應用架構,大語言模型的出現顛覆了傳統範式。這種變革進一步傳導至數據庫層面,推動着面向 AI 時代的雲數據庫一體機的演進。未來所有應用將主要對接兩個核心接口:Data API 和 AI API。
為適應這一趨勢,雲數據庫一體機需具備以下特性:
- 靈活性、可擴展性和彈性。
- 資源池化。
- 快速彈性伸縮。
- 按需自助服務。
- 廣泛的網絡訪問。
- 可度量的服務。
AI 時代不會淘汰高級程序員和高級 DBA
AI 時代的到來並不會淘汰高級程序員和高級 DBA。正如 PC 時代 VB、Delphi、MFC 等可視化開發工具的出現沒有取代程序員一樣,當前雖然出現了大量調參工程師、Call API 專家、用庫包能手和拼組件達人,但技術人員很快會在新領域找到發展空間。
互聯網時代的興起催生了後端開發、網絡、分佈式、數據庫、海量服務、容災防錯等新方向。PC 時代的基礎設施是控件庫,互聯網時代的基礎設施是雲,AI 時代也將誕生新的基礎設施概念。
時代發展會催生新的技術概念(量變積累成質變),但底層邏輯始終不變。堅持第一性原理,保持高內聚、低耦合的設計理念,才是技術人員的核心競爭力。
需要理解的背後原因
- 本地部署的傳統應用往往採用 c/c++、企業級 java 編寫,而云原生應用則需要用以網絡為中心的 go、node.js 等新興語言編寫。
- 本地部署的傳統應用可能需要停機更新,而云原生應用應該始終是最新的,需要支持頻繁變更,持續交付,藍綠部署。
- 本地部署的傳統應用無法動態擴展,往往需要冗餘資源以抵抗流量高峯,而云原生應用利用雲的彈性自動伸縮,通過共享降本增效。
- 本地部署的傳統應用對網絡資源,比如 ip、端口等有依賴,甚至是硬編碼,而云原生應用對網絡和存儲都沒有這種限制。
- 本地部署的傳統應用通常人肉部署手工運維,而云原生應用這一切都是自動化的。
- 本地部署的傳統應用通常依賴系統環境,而云原生應用不會硬連接到任何系統環境,而是依賴抽象的基礎架構,從而獲得良好移植性。
- 本地部署的傳統應用有些是單體(巨石)應用,或者強依賴,而基於微服務架構的雲原生應用,縱向劃分服務,模塊化更合理。
AI 時代 PostgreSQL 成為新寵
為什麼 PostgreSQL 會成為事實上的行業標準?
- PostgreSQL 非常標準和規範,除了 SQL 本身就覆蓋了 OLTP 和 OLAP 的需求外,其最大的優點就是有強大的可擴展性。它允許用户通過擴展(Extensions)來增強數據庫功能(全文檢索,向量檢索,地理信息檢索,時序處理等等),而無需修改核心代碼。
- PostgreSQL 提供了原生的 pgvector 擴展,可以直接支持向量數據的存儲與檢索;而在 MySQL 標準中,缺乏可擴展性接口與生態,MySQL 數據庫系統往往需要自行定義向量數據存儲和檢索的 API,導致實現千差萬別,缺乏標準。這也是為什麼越來越多的 AI 公司,特別是 OpenAl、Anthropic、Notion 等大型 AI 初創項目,都選擇 PostgreSQL 作為其核心數據引擎。
- 非官方的一則報道:OpenAI 內部的一個 PostgreSQL 只讀從庫就部署了近 50 個實例。雖然目前 OpenAI 尚未採用分佈式數據庫架構,但隨着業務規模的持續擴張,這或將成為其未來必須應對的架構挑戰。
PostgreSQL 成 AI 智能體首選數據平台
- AlloyDB for PostgreSQL:在 Google I/O 上,谷歌發佈了 AlloyDB for PostgreSQL,這是一個完全託管的、與 PostgreSQL 兼容的數據庫,用於要求苛刻的企業級事務和分析工作負載。彈性存儲和計算、智能緩存和 AI/ML 支持的管理。
- Agent Talk to MCP:PostgreSQL 是默認選項之一。
- MCP 這個概念最早由 Anthropic 提出,而在其官方文檔中,明確列出的第二個支持平台就是 PostgreSQL。
- 這進一步印證了 PostgreSQL 在 AI 應用工作負載中的關鍵作用——它不僅是一種數據庫,更是 AI 系統與數據交互的中樞平台。
多模態數據庫:AI 時代的核心基礎設施
未來 AI 應用層將越來越依賴數據庫,多模態數據庫將成為核心基礎設施。
這裏舉個例子:
如果你正在開發一個基於 AI 的 Agent,它勢必需要與各種數據系統和應用系統交互。按照傳統架構的分工模式:
- 事務性數據放在關係型數據庫中。
- 數據的橫向水平分佈式擴展用 MongoDB 或 HBase。
- 搜索功能用 Elasticsearch(ES)實現。
- 分析需求用 ClickHouse。
這意味着,一個企業僅在數據底層就要維護至少 4 個不同的 MCP(Model Context Protocol)服務。這對大模型來説是個巨大的挑戰。理論上它可以理解這些差異化的服務,但實際運作中非常複雜,對其“智力”構成高強度負荷。能對接 1 個 MCP,誰還要對接 4 個呢?這也正是為什麼越來越多的 AI 初創公司選擇 PostgreSQL,而未來大型企業在面向 AI 場景進行數據庫選型時,也一定會傾向選擇支持多模態的數據庫平台。
基於 PostgreSQL 的熱點數據庫
- IvorySQL 數據庫是一款基於 PostgreSQL 數據庫。
- Neon Database 由 PostgreSQL 核心開發者創立,提供基於 PostgreSQL 的 Serverless 雲服務。其採用存算分離架構,支持類似 Git 的 Branc 和 Time Travel 功能,允許開發者在獨立數據庫分支上並行開發。架構模式與 Google AlloyDB、Azure Socrates 及華為 Taurus 類似,均為計算節點、存儲服務和日誌服務分離的雲原生方案。該公司於 2022 年獲得 3000 萬美元 A 輪融資。

- AlloyDB for PostgreSQL 在 Google I/O 上,谷歌發佈了 AlloyDB for PostgreSQL,這是一個完全託管的、與 PostgreSQL 兼容的數據庫,用於要求苛刻的企業級事務和分析工作負載。彈性存儲和計算、智能緩存和 AI/ML 支持的管理。
- Supabase 同樣是構建在 PostgreSQL 之上的數據庫平台,它與 Neon 構成了直接的競爭關係。但與 Neon 相比,Supabase 提供了更為豐富的功能集,包括身份驗證、對象存儲、實時訂閲、邊緣函數等服務,幾乎可以看作是“開源版的 Firebase”,定位為開發者的一站式後端服務平台。
AI 時代對數據庫一體機的挑戰
AI 時代傳統數據架構的痛點
Legacy Data Architecture(傳統數據架構)。它已經難以適配 AI 時代日益增長的實時性、統一性和智能化需求。
- 事務型數據庫:用於實時寫入與查詢(如訂單、行為日誌)。
- 文本搜索引擎:處理非結構化關鍵詞匹配(如全文搜索)。
- 向量搜索引擎:支撐語義檢索。
- 分析引擎:進行數據分析(如行情分析、指標監控、報表)。
痛點問題:
- 系統運維複雜:需管理多個技術棧,版本依賴、部署、運維壓力大。
- 數據割裂嚴重:數據需在多個系統間反覆同步、複製,口徑難統一。
- 性能和響應鏈路長:查詢需跨系統拼接,影響響應時間和穩定性。
統一多模數據架構
通過統一架構,將多模態數據能力深度集成於單一平台,以更簡潔高效的方式支撐複雜 AI Workflow。該架構並非多個引擎的簡單拼裝,而是從底層實現事務處理、全文搜索、向量檢索與實時分析的有機融合,真正實現“一套系統,全場景覆蓋”。
具體能力包括:
- 支持行存表、列存表及行列混存表,適應不同業務場景的存儲與訪問需求。
- 提供 OLTP 全局二級索引:倒排索引滿足文本搜索、列存索引優化分析查詢、JSON 索引提升半結構化數據的訪問效率。
構建統一數據底座
只有構建一個滿足實時性、融合性、高併發與易用性的數據平台,才能真正釋放大模型和 Agent 的智能潛力。
- 數據庫:擅長處理 Fresh Data(數據新鮮性)和 Instant Retrieval(即時檢索),適用於實時寫入和快速查詢場景。但其大多基於單機或簡單主從架構,難以支撐大規模的高併發訪問。
- 數據倉庫(如 ClickHouse):在分析性能(Fast Analytics)和 使用簡潔性(Simplicity)方面表現出色,但它們普遍不適合高頻寫入或低延遲響應場景。
- 數據庫一體機:將 Data Warehouse 與 Database 融合於一體,構建統一的數據底座,以全面支撐 AI 工作流中從數據採集、加工、分析到檢索的全過程。
構建支持 AI 應用的雲原生數據庫一體機
擁有云能力的數據庫一體機有效支持了 AI 應用。在可觀測性場景中,彈性能力至關重要:系統正常運行或行情平穩時可能僅需支持少量用户;一旦出現系統問題或金融行情波動,用户量會急劇增加,容易導致系統崩潰。因此,雲上的彈性擴縮容能力成為關鍵支撐。
採用領先的存算分離架構的 Data Warebase 能夠在業務無感的情況下實現秒級彈性擴縮容,滿足瞬時高併發需求。同時,該架構具備多模能力與精簡架構(Simplicity),兼顧了可觀測性場景所需的簡潔性和實時決策(Instant Decision)能力。
在金融領域的 Trading 、Fraud Detection 、 車聯網領域的信號收集、檢測與報警,以及 Ads、Search 和 Recommendation 等場景中,均需要此類能夠提供即時決策支持的一體化數據平台。
AI 時代的工作流技術
AI 工作流,從數據獲取到結果交付,必須滿足五大核心能力:

CData 是 AI 時代的數據庫
相比傳統的數據庫部署方式,數據庫一體機具有以下幾個明顯的優勢:
- 部署方式:支持在物理機上、虛擬機上、容器中部署數據庫。在同一個物理機或虛擬機中還可以部署多個數據庫實例(使用 cgroup 做資源隔離)。
- 高性能:CData 支持 iSER、NVMe over Fabric、SPDK 等多種 IO 傳輸模式,提供了卓越的性能表現,能夠滿足大規模數據處理和高併發訪問的需求。
- 成本節省:支持雲化部署,支持基於共享存儲和數據庫自身主庫方式的高可用方案。支持負載均衡。支持完善的監控和告警功能。
- 多模查詢:可以運行支持多模查詢的數據庫 PostgreSQL 或 HighgoDB,配合 pgvector 可以提供向量查詢,本身可以提供全文檢索、JSON 搜索等文本搜索。
- 可靠性高:CData 支持跨機器的 Raid1、Raid10、Raid5、Raid6、Raid50、Raid60 等冗餘設計,保證數據的可靠性。
總結
AI 時代的數據庫一體機已從性能優化工具發展為智能應用的核心基礎設施。雲原生架構、多模態檢索和彈性擴展技術解決了數據割裂、運維複雜和響應延遲等問題。PostgreSQL 生態、MCP 協議和 Agent 協作框架進一步強化了數據庫作為 AI 與數據交互中樞的角色。隨着多模查詢、實時決策和資源池化技術的成熟,數據庫一體機將持續支撐大模型與 Agent 的智能應用。










