背景:bulk 優化的應用
在 ES 的寫入優化裏,bulk 操作被廣泛地用於批量處理數據。bulk 操作允許用户一次提交多個數據操作,如索引、更新、刪除等,從而提高數據處理效率。bulk 操作的實現原理是,將數據操作請求打包成 HTTP 請求,並批量提交給 Elasticsearch 服務器。這樣,Elasticsearch 服務器就可以一次處理多個數據操作,從而提高處理效率。
這種優化的核心價值在於減少了網絡往返的次數和連接建立的開銷。每一次單獨的寫入操作都需要經歷完整的請求-響應週期,而批量寫入則是將多個操作打包在一起,用一次通信完成原本需要多次交互的工作。這不僅僅節省了時間,更重要的是釋放了系統資源,讓服務器能夠專注於真正的數據處理,而不是頻繁的協議握手和狀態維護。
這樣的批量請求的確是可以優化寫入請求的效率,讓 ES 集羣獲得更多的資源去做寫入請求的集中處理。但是除了客户端與 ES 集羣的通訊效率優化,還有其他中間過程能優化麼?
Gateway 的優化點
bulk 的優化理念是將日常零散的寫入需求做集中化的處理,儘量減低日常請求的損耗,完成資源最大化的利用。簡而言之就是“好鋼用在刀刃上”。
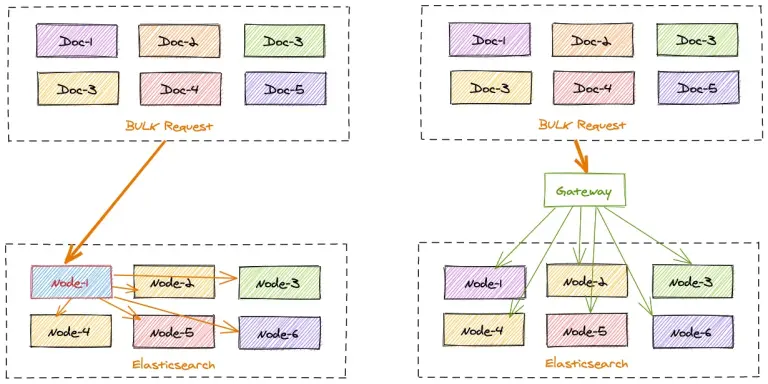
但是 ES 在收到 bulk 寫入請求後,也是需要協調節點根據文檔的 id 計算所屬的分片來將數據分發到對應的數據節點的。這個過程也是有一定損耗的,如果 bulk 請求中數據分佈的很散,每個分片都需要進行寫入,原本 bulk 集中寫入的需求優勢則還是沒有得到最理想化的提升。
gateway 的寫入加速則對 bulk 的優化理念的最大化補全。
gateway 可以本地計算每個索引文檔對應後端 Elasticsearch 集羣的目標存放位置,從而能夠精準的進行寫入請求定位。
在一批 bulk 請求中,可能存在多個後端節點的數據,bulk_reshuffle 過濾器用來將正常的 bulk 請求打散,按照目標節點或者分片進行拆分重新組裝,避免 Elasticsearch 節點收到請求之後再次進行請求分發, 從而降低 Elasticsearch 集羣間的流量和負載,也能避免單個節點成為熱點瓶頸,確保各個數據節點的處理均衡,從而提升集羣總體的索引吞吐能力。
整理的優化思路如下圖:
優化實踐
那我們來實踐一下,看看 gateway 能提升多少的寫入。
這裏我們分 2 個測試場景:
- 基礎集中寫入測試,不帶文檔 id,直接批量寫入。這個場景更像是日誌或者監控數據採集的場景。
- 帶文檔 id 的寫入測試,更偏向搜索場景或者大數據批同步的場景。
2 個場景都進行直接寫入 ES 和 gateway 轉發 ES 的效率比對。
測試材料除了需要備一個網關和一套 es 外,其餘的內容如下:
測試索引 mapping 一致,名稱區分:
PUT gateway_bulk_test
{
"settings": {
"number_of_shards": 6,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"timestamp": {
"type": "date",
"format": "strict_date_optional_time"
},
"field1": {
"type": "keyword"
},
"field2": {
"type": "keyword"
},
"field3": {
"type": "keyword"
},
"field4": {
"type": "integer"
},
"field5": {
"type": "keyword"
},
"field6": {
"type": "float"
}
}
}
}
PUT bulk_test
{
"settings": {
"number_of_shards": 6,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"timestamp": {
"type": "date",
"format": "strict_date_optional_time"
},
"field1": {
"type": "keyword"
},
"field2": {
"type": "keyword"
},
"field3": {
"type": "keyword"
},
"field4": {
"type": "integer"
},
"field5": {
"type": "keyword"
},
"field6": {
"type": "float"
}
}
}
}gateway 的配置文件如下:
path.data: data
path.logs: log
entry:
- name: my_es_entry
enabled: true
router: my_router
max_concurrency: 200000
network:
binding: 0.0.0.0:8000
flow:
- name: async_bulk
filter:
- bulk_reshuffle:
when:
contains:
_ctx.request.path: /_bulk
elasticsearch: prod
level: node
partition_size: 1
fix_null_id: true
- elasticsearch:
elasticsearch: prod #elasticsearch configure reference name
max_connection_per_node: 1000 #max tcp connection to upstream, default for all nodes
max_response_size: -1 #default for all nodes
balancer: weight
refresh: # refresh upstream nodes list, need to enable this feature to use elasticsearch nodes auto discovery
enabled: true
interval: 60s
filter:
roles:
exclude:
- master
router:
- name: my_router
default_flow: async_bulk
elasticsearch:
- name: prod
enabled: true
endpoints:
- https://127.0.0.1:9221
- https://127.0.0.1:9222
- https://127.0.0.1:9223
basic_auth:
username: admin
password: admin
pipeline:
- name: bulk_request_ingest
auto_start: true
keep_running: true
retry_delay_in_ms: 1000
processor:
- bulk_indexing:
max_connection_per_node: 100
num_of_slices: 3
max_worker_size: 30
idle_timeout_in_seconds: 10
bulk:
compress: false
batch_size_in_mb: 10
batch_size_in_docs: 10000
consumer:
fetch_max_messages: 100
queue_selector:
labels:
type: bulk_reshuffle測試腳本如下:
#!/usr/bin/env python3
"""
ES Bulk寫入性能測試腳本
"""
import hashlib
import json
import random
import string
import time
from typing import List, Dict, Any
import requests
from concurrent.futures import ThreadPoolExecutor
from datetime import datetime
import urllib3
# 禁用SSL警告
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
class ESBulkTester:
def __init__(self):
# 配置變量 - 可修改
self.es_configs = [
{
"name": "ES直連",
"url": "https://127.0.0.1:9221",
"index": "bulk_test",
"username": "admin", # 修改為實際用户名
"password": "admin", # 修改為實際密碼
"verify_ssl": False # HTTPS需要SSL驗證
},
{
"name": "Gateway代理",
"url": "http://localhost:8000",
"index": "gateway_bulk_test",
"username": None, # 無需認證
"password": None,
"verify_ssl": False
}
]
self.batch_size = 10000 # 每次bulk寫入條數
self.log_interval = 100000 # 每多少次bulk寫入輸出日誌
# ID生成規則配置 - 前2位後5位
self.id_prefix_start = 1
self.id_prefix_end = 999 # 前3位: 01-999
self.id_suffix_start = 1
self.id_suffix_end = 9999 # 後4位: 0001-9999
# 當前ID計數器
self.current_prefix = self.id_prefix_start
self.current_suffix = self.id_suffix_start
def generate_id(self) -> str:
"""生成固定規則的ID - 前2位後5位"""
id_str = f"{self.current_prefix:02d}{self.current_suffix:05d}"
# 更新計數器
self.current_suffix += 1
if self.current_suffix > self.id_suffix_end:
self.current_suffix = self.id_suffix_start
self.current_prefix += 1
if self.current_prefix > self.id_prefix_end:
self.current_prefix = self.id_prefix_start
return id_str
def generate_random_hash(self, length: int = 32) -> str:
"""生成隨機hash值"""
random_string = ''.join(random.choices(string.ascii_letters + string.digits, k=length))
return hashlib.md5(random_string.encode()).hexdigest()
def generate_document(self) -> Dict[str, Any]:
"""生成隨機文檔內容"""
return {
"timestamp": datetime.now().isoformat(),
"field1": self.generate_random_hash(),
"field2": self.generate_random_hash(),
"field3": self.generate_random_hash(),
"field4": random.randint(1, 1000),
"field5": random.choice(["A", "B", "C", "D"]),
"field6": random.uniform(0.1, 100.0)
}
def create_bulk_payload(self, index_name: str) -> str:
"""創建bulk寫入payload"""
bulk_data = []
for _ in range(self.batch_size):
#doc_id = self.generate_id()
doc = self.generate_document()
# 添加index操作
bulk_data.append(json.dumps({
"index": {
"_index": index_name,
# "_id": doc_id
}
}))
bulk_data.append(json.dumps(doc))
return "\n".join(bulk_data) + "\n"
def bulk_index(self, config: Dict[str, Any], payload: str) -> bool:
"""執行bulk寫入"""
url = f"{config['url']}/_bulk"
headers = {
"Content-Type": "application/x-ndjson"
}
# 設置認證信息
auth = None
if config.get('username') and config.get('password'):
auth = (config['username'], config['password'])
try:
response = requests.post(
url,
data=payload,
headers=headers,
auth=auth,
verify=config.get('verify_ssl', True),
timeout=30
)
return response.status_code == 200
except Exception as e:
print(f"Bulk寫入失敗: {e}")
return False
def refresh_index(self, config: Dict[str, Any]) -> bool:
"""刷新索引"""
url = f"{config['url']}/{config['index']}/_refresh"
# 設置認證信息
auth = None
if config.get('username') and config.get('password'):
auth = (config['username'], config['password'])
try:
response = requests.post(
url,
auth=auth,
verify=config.get('verify_ssl', True),
timeout=10
)
success = response.status_code == 200
print(f"索引刷新{'成功' if success else '失敗'}: {config['index']}")
return success
except Exception as e:
print(f"索引刷新失敗: {e}")
return False
def run_test(self, config: Dict[str, Any], round_num: int, total_iterations: int = 100000):
"""運行性能測試"""
test_name = f"{config['name']}-第{round_num}輪"
print(f"\n開始測試: {test_name}")
print(f"ES地址: {config['url']}")
print(f"索引名稱: {config['index']}")
print(f"認證: {'是' if config.get('username') else '否'}")
print(f"每次bulk寫入: {self.batch_size}條")
print(f"總計劃寫入: {total_iterations * self.batch_size}條")
print("-" * 50)
start_time = time.time()
success_count = 0
error_count = 0
for i in range(1, total_iterations + 1):
payload = self.create_bulk_payload(config['index'])
if self.bulk_index(config, payload):
success_count += 1
else:
error_count += 1
# 每N次輸出日誌
if i % self.log_interval == 0:
elapsed_time = time.time() - start_time
rate = i / elapsed_time if elapsed_time > 0 else 0
print(f"已完成 {i:,} 次bulk寫入, 耗時: {elapsed_time:.2f}秒, 速率: {rate:.2f} bulk/秒")
end_time = time.time()
total_time = end_time - start_time
total_docs = total_iterations * self.batch_size
print(f"\n{test_name} 測試完成!")
print(f"總耗時: {total_time:.2f}秒")
print(f"成功bulk寫入: {success_count:,}次")
print(f"失敗bulk寫入: {error_count:,}次")
print(f"總文檔數: {total_docs:,}條")
print(f"平均速率: {success_count/total_time:.2f} bulk/秒")
print(f"文檔寫入速率: {total_docs/total_time:.2f} docs/秒")
print("=" * 60)
return {
"test_name": test_name,
"config_name": config['name'],
"round": round_num,
"es_url": config['url'],
"index": config['index'],
"total_time": total_time,
"success_count": success_count,
"error_count": error_count,
"total_docs": total_docs,
"bulk_rate": success_count/total_time,
"doc_rate": total_docs/total_time
}
def run_comparison_test(self, total_iterations: int = 10000):
"""運行雙地址對比測試"""
print("ES Bulk寫入性能測試開始")
print(f"測試時間: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
print("=" * 60)
results = []
rounds = 2 # 每個地址測試2輪
# 循環測試所有配置
for config in self.es_configs:
print(f"\n開始測試配置: {config['name']}")
print("*" * 40)
for round_num in range(1, rounds + 1):
# 運行測試
result = self.run_test(config, round_num, total_iterations)
results.append(result)
# 每輪結束後刷新索引
print(f"\n第{round_num}輪測試完成,執行索引刷新...")
self.refresh_index(config)
# 重置ID計數器
if round_num == 1:
# 第1輪:使用初始ID範圍(新增數據)
print("第1輪:新增數據模式")
else:
# 第2輪:重複使用相同ID(更新數據模式)
print("第2輪:數據更新模式,複用第1輪ID")
self.current_prefix = self.id_prefix_start
self.current_suffix = self.id_suffix_start
print(f"{config['name']} 第{round_num}輪測試結束\n")
# 輸出對比結果
print("\n性能對比結果:")
print("=" * 80)
# 按配置分組顯示結果
config_results = {}
for result in results:
config_name = result['config_name']
if config_name not in config_results:
config_results[config_name] = []
config_results[config_name].append(result)
for config_name, rounds_data in config_results.items():
print(f"\n{config_name}:")
total_time = 0
total_bulk_rate = 0
total_doc_rate = 0
for round_data in rounds_data:
print(f" 第{round_data['round']}輪:")
print(f" 耗時: {round_data['total_time']:.2f}秒")
print(f" Bulk速率: {round_data['bulk_rate']:.2f} bulk/秒")
print(f" 文檔速率: {round_data['doc_rate']:.2f} docs/秒")
print(f" 成功率: {round_data['success_count']/(round_data['success_count']+round_data['error_count'])*100:.2f}%")
total_time += round_data['total_time']
total_bulk_rate += round_data['bulk_rate']
total_doc_rate += round_data['doc_rate']
avg_bulk_rate = total_bulk_rate / len(rounds_data)
avg_doc_rate = total_doc_rate / len(rounds_data)
print(f" 平均性能:")
print(f" 總耗時: {total_time:.2f}秒")
print(f" 平均Bulk速率: {avg_bulk_rate:.2f} bulk/秒")
print(f" 平均文檔速率: {avg_doc_rate:.2f} docs/秒")
# 整體對比
if len(config_results) >= 2:
config_names = list(config_results.keys())
config1_avg = sum([r['bulk_rate'] for r in config_results[config_names[0]]]) / len(config_results[config_names[0]])
config2_avg = sum([r['bulk_rate'] for r in config_results[config_names[1]]]) / len(config_results[config_names[1]])
if config1_avg > config2_avg:
faster = config_names[0]
rate_diff = config1_avg - config2_avg
else:
faster = config_names[1]
rate_diff = config2_avg - config1_avg
print(f"\n整體性能對比:")
print(f"{faster} 平均性能更好,bulk速率高 {rate_diff:.2f} bulk/秒")
print(f"性能提升: {(rate_diff/min(config1_avg, config2_avg)*100):.1f}%")
def main():
"""主函數"""
tester = ESBulkTester()
# 運行測試(每次bulk 1萬條,300次bulk = 300萬條文檔)
tester.run_comparison_test(total_iterations=300)
if __name__ == "__main__":
main()1. 日誌場景:不帶 id 寫入
測試條件:
- bulk 寫入數據不帶文檔 id
- 每批次 bulk 10000 條數據,總共寫入 30w 數據
這裏把
反饋結果:
性能對比結果:
================================================================================
ES直連:
第1輪:
耗時: 152.29秒
Bulk速率: 1.97 bulk/秒
文檔速率: 19699.59 docs/秒
成功率: 100.00%
平均性能:
總耗時: 152.29秒
平均Bulk速率: 1.97 bulk/秒
平均文檔速率: 19699.59 docs/秒
Gateway代理:
第1輪:
耗時: 115.63秒
Bulk速率: 2.59 bulk/秒
文檔速率: 25944.35 docs/秒
成功率: 100.00%
平均性能:
總耗時: 115.63秒
平均Bulk速率: 2.59 bulk/秒
平均文檔速率: 25944.35 docs/秒
整體性能對比:
Gateway代理 平均性能更好,bulk速率高 0.62 bulk/秒
性能提升: 31.7%2. 業務場景:帶文檔 id 的寫入
測試條件:
- bulk 寫入數據帶有文檔 id,兩次測試寫入的文檔 id 生成規則一致且重複。
- 每批次 bulk 10000 條數據,總共寫入 30w 數據
這裏把 py 腳本中 第 99 行 和 第 107 行的註釋打開。
反饋結果:
性能對比結果:
================================================================================
ES直連:
第1輪:
耗時: 155.30秒
Bulk速率: 1.93 bulk/秒
文檔速率: 19317.39 docs/秒
成功率: 100.00%
平均性能:
總耗時: 155.30秒
平均Bulk速率: 1.93 bulk/秒
平均文檔速率: 19317.39 docs/秒
Gateway代理:
第1輪:
耗時: 116.73秒
Bulk速率: 2.57 bulk/秒
文檔速率: 25700.06 docs/秒
成功率: 100.00%
平均性能:
總耗時: 116.73秒
平均Bulk速率: 2.57 bulk/秒
平均文檔速率: 25700.06 docs/秒
整體性能對比:
Gateway代理 平均性能更好,bulk速率高 0.64 bulk/秒
性能提升: 33.0%小結
不管是日誌場景還是業務價值更重要的大數據或者搜索數據同步場景, gateway 的寫入加速都能平穩的節省 25%-30% 的寫入耗時。
關於極限網關(INFINI Gateway)

INFINI Gateway 是一個開源的面向搜索場景的高性能數據網關,所有請求都經過網關處理後再轉發到後端的搜索業務集羣。基於 INFINI Gateway,可以實現索引級別的限速限流、常見查詢的緩存加速、查詢請求的審計、查詢結果的動態修改等等。
官網文檔:https://docs.infinilabs.com/gateway
開源地址:https://github.com/infinilabs/gateway
作者:金多安,極限科技(INFINI Labs)搜索運維專家,Elastic 認證專家,搜索客社區日報責任編輯。一直從事與搜索運維相關的工作,日常會去挖掘 ES / Lucene 方向的搜索技術原理,保持搜索相關技術發展的關注。
原文:https://infinilabs.cn/blog/2025/gateway-bulk-write-performanc...