作者:趙紅梅 Hologres PD
本次分享的主題是Dynamic Table快速入門,由Hologres PD 趙紅梅分享。今天的分享分為三個部分。首先,第一部分介紹Dynamic Table;第二部分進行Dynamic Table的實操;第三部分為一些使用DynamicTable的建議和最佳實踐。
- Hologres Dynamic Table介紹
- Dynamic Table的使用方法和實操
- Dynamic Table的使用建議
一、Hologres Dynamic Table介紹
首先進入第一個部分。先來探討一下實時數倉的典型應用場景,總結起來大致有以下四類。
比如BI報表分析類,這包括常見的實時大屏、BI報表數據中台等;
第二類是人羣運營類;
第三類是日誌分析與檢索類,如行為分析、流量分析等;
第四類則是實時監控類,例如實時風控、直播監控等。
這些實時數倉的場景廣泛應用於廣告、遊戲、電商、互聯網等多個行業。但是並非這些實時數倉的場景都要求達到秒級或毫秒級的低延遲,更多的場景,如報表分析、人羣運營類應用,其實更多地屬於準實時場景,即分鐘級延遲。

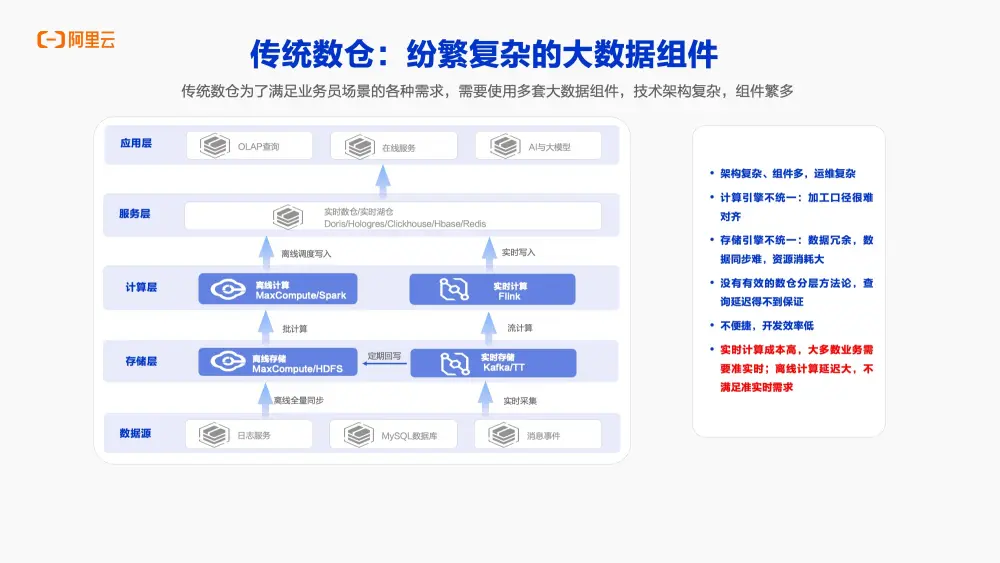
為了支撐實時數倉,包括離線、實時以及準實時等場景,我們來看看這些場景背後的數倉技術是如何實現的。
常見的數倉架構如下圖所示,首先在存儲層會包含多個存儲組件,比如離線存儲和實時存儲。為了滿足實時數倉中不同的查詢需求,以及離線場景的計算需求,通常會採用不同的計算引擎。離線場景可能會使用像MaxCompute或Spark這樣的離線計算引擎來處理數據。通過這些引擎以批處理的方式計算離線數據,並將結果寫入到服務層,比如實時數倉Hologres、Starrocks等中,最終對接到應用端。
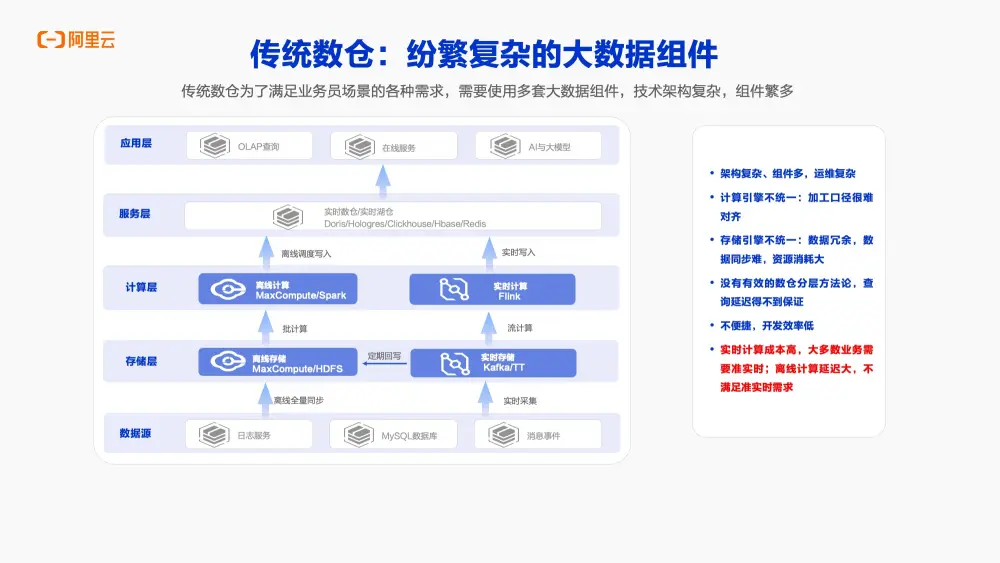
為了滿足實時或準實時場景的需求,通常依賴於實時計算引擎,比如Flink來提供支持。Flink這類實時計算引擎能夠對數據進行實時處理,並將處理結果寫入實時數倉或數據湖中,最終為在線服務提供支持。這套架構其實是一個典型的Lambda架構,然而該架構也存在許多痛點:
- 例如,架構中涉及的組件眾多,既有離線計算引擎,也有實時計算引擎,這無疑增加了開發和運維的複雜性和不便性。
- 第二個問題是,由於需要支持不同的場景,如離線場景、實時場景和準實時場景,而這套架構採用了不同的組件。在存儲層,離線場景和實時場景各自擁有獨立的存儲系統,這導致了數據的冗餘。在計算層,既有離線計算引擎,也有實時計算引擎,這意味着需要維護兩套代碼,這可能導致實時和離線的數據口徑不一致,進而引發數據不一致的問題。
- 此外如前所述,實時數倉的場景不僅包含實時計算,還包含準實時計算。然而這套架構在支持準實時計算場景時存在不足。如果採用離線計算引擎來支持準實時場景,那麼延遲會非常高,無法滿足分鐘級延遲的需求。而如果採用實時計算引擎來支持準實時場景,雖然可以滿足延遲要求,但實時計算的成本卻很高,這使得在實際應用中難以權衡。
是否有一款產品能夠同時支持多種計算模式,統一數據存儲,並且更好地滿足準實時計算場景的需求呢?
經過技術調研,我們發現增量計算技術非常適合用於支持準實時計算場景。因此,在Hologres的3.0版本中,重點引入了Dynamic Table這一新型表類型,也稱作動態表。它能夠自動地將查詢結果物化。同時Dynamic Table提供了兩種計算模式:增量計算模式和全量計算模式,來滿足不同場景的計算需求。
顧名思義,增量計算即每次刷新時僅處理新增的數據,也被稱為增量刷新。與傳統的全量數據計算相比,通過增量計算可以顯著減少數據的處理量,從而提升Query的處理速度,並降低計算成本。這種計算方式非常適用於準實時計算場景的需求。
而全量刷新是指每次處理查詢時,都會通過全量的方式來更新數據。這種方式通常建議用於週期性調度、數據回刷等場景。雖然全量刷新的成本在某些情況下可能會比增量刷新更低,但Hologres本身支持實時和離線存儲。通過結合Hologres和Dynamic Table,可以實現一份數據同時支持多種計算模式,從而在性能和成本之間達到完美平衡,滿足業務對於不同刷新延遲的多樣化需求。
Dynamic Table的使用
剛剛介紹了Dynamic Table,它是一種特殊的表類型。在創建Dynamic Table時,語法與創建普通表相似,但需要注意的是有三個關鍵參數需要設置:
- 創建Dynamic Table時,需要指定刷新模式,根據業務的具體需求選擇增量刷新或全量刷新模式。
- 其次,需要設置好刷新間隔,通過設定的刷新間隔,Dynamic Table會週期性地更新數據。
- 最後,需要指定處理的Query,而Dynamic Table會通過Query自動執行該查詢並存儲查詢結果。
- 在查詢時,只需查詢這張Dynamic Table,即可獲得經過聚合處理的查詢結果。
Dynamic Table在使用上帶來了諸多優勢,總結起來主要有以下幾點:
- 首先是聲明式的數據處理,它實現了自動化的數據處理。以往,對於一段數據的ETL加工邏輯,需要額外編寫任務調度腳本來處理相應的Query 。而現在,只需為Dynamic Table設置刷新模式和刷新間隔,它就會自動刷新數據,並自動管理刷新任務,無需再啓動其他調度腳本,這使得開發方式從命令式轉變為聲明式,無需再額外關注每次任務的運維情況,只需關注最終數據結果的一致性,從而大大提高了運維的便捷性。
- 第二個優勢是,Dynamic Table能夠提供極低延遲的數據更新。正如之前提到的,可以通過設置數據刷新間隔來提升數據的新鮮度。增量刷新模式在理論上可以做到最低每分鐘刷新一次,這能夠很好地滿足準實時場景中分鐘級延遲的需求。
- 第三個優勢是,Dynamic Table的開發完全基於標準的SQL,因此非常容易上手。只要熟悉標準的SQL語法,就可以像使用其他SQL工具一樣使用Dynamic Table,無需額外的學習成本。此外,Dynamic Table在業務定義的查詢中支持多種常見的SQL表達式,如JOIN、GROUP BY、窗口函數等,功能強大且靈活。因此可以像使用普通的SQL查詢一樣輕鬆地使用Dynamic Table,其上手成本非常低。
- 最後一個優勢是Dynamic Table能夠實現多模式的統一計算。這是如何做到的呢?正如之前提到的,Dynamic Table支持多種刷新模式,包括增量刷新和全量刷新。這兩種刷新模式在使用上並無差異,只需通過修改Refresh Mode參數,即可輕鬆地將增量刷新切換為全量刷新。
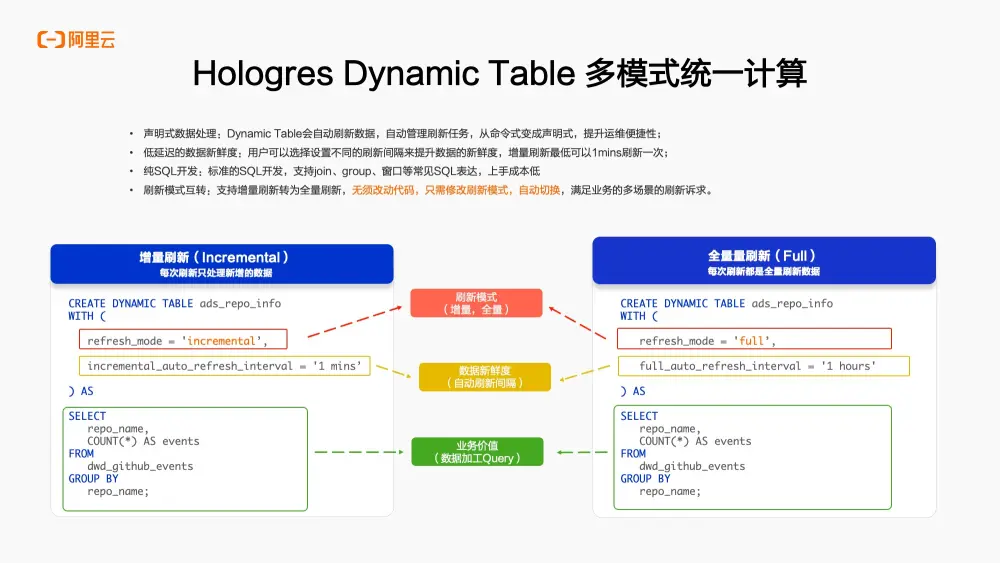
在過去傳統的開發模式中,實時計算和離線計算往往需要分別編寫兩套代碼。然而通過Dynamic Table,無需修改任何刷新邏輯,只需調整一次Refresh Mode參數,即可輕鬆地將增量刷新轉換為全量刷新,實現刷新模式的無縫切換,從而達成多模式的統一計算。這種方式能夠很好地滿足業務場景中多樣化的刷新需求。

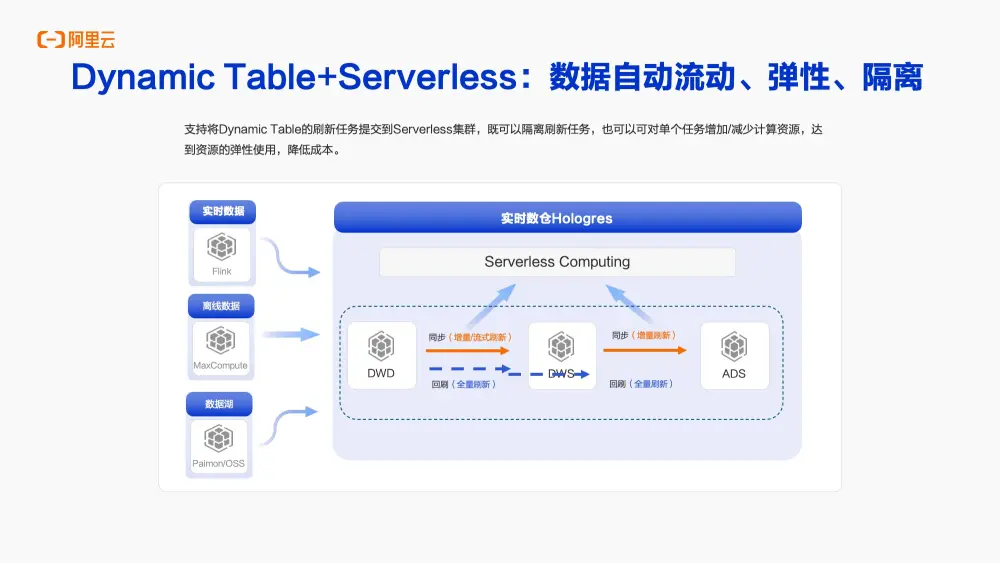
同時Dynamic Table可以與Serverless結合使用。無論是增量刷新還是全量刷新,都可以提交到Serverless集羣上執行。
好處為一方面可以隔離刷新任務。例如,如果有較大的刷新任務可能會對本實例中的其他生產任務或查詢造成影響,通過將刷新任務提交到Serverless集羣上執行,可以有效隔離這些任務,避免相互影響。
另一方面,這樣做還帶來了資源彈性使用的好處。比如,在業務高峯期,可以根據需要對單個Dynamic Table的刷新任務或單個刷新任務增加或減少計算資源,而無需對整個實例進行擴容,從而實現了資源的靈活調配和成本的進一步降低。
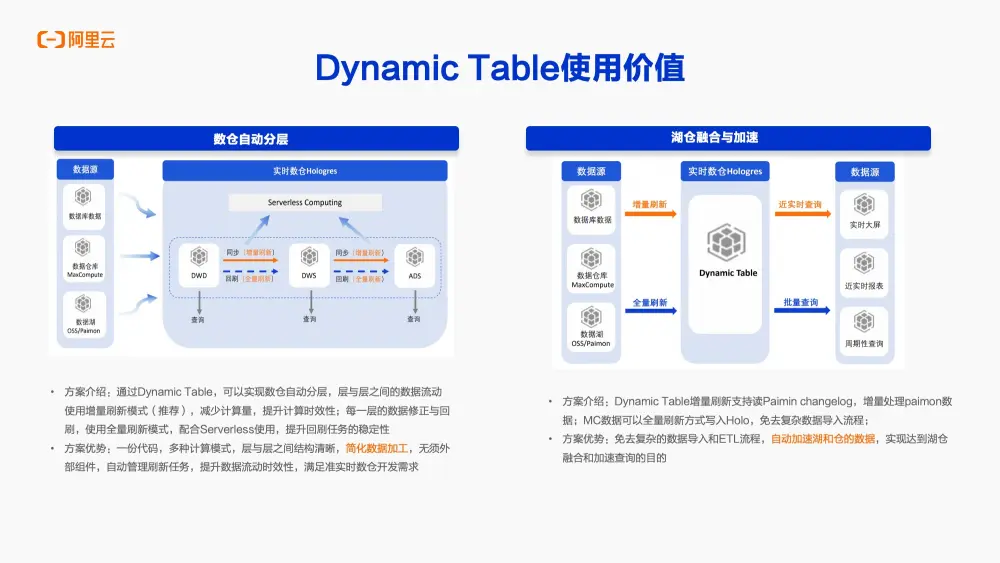
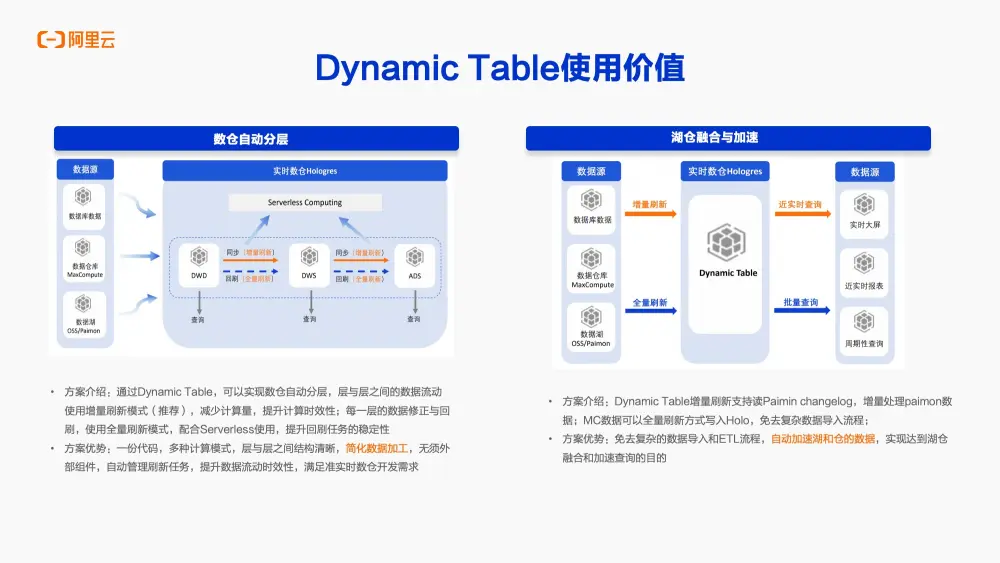
綜上所述,Dynamic Table能夠支持眾多典型的應用場景。
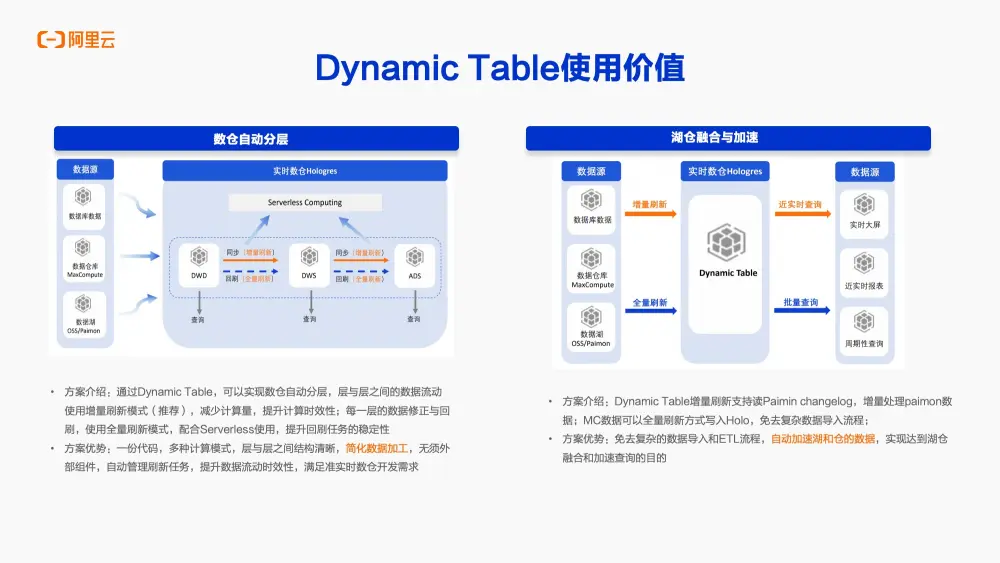
首先,通過Dynamic Table可以實現數倉的自動分層。
以往數倉分層更多地依賴於外部組件,如編寫調度腳本或Flink任務等。而現在,利用Dynamic Table可以自動地實現數倉的分層,無需額外的外部組件或任務。而從DWD層到ADS層,強烈推薦每一層之間採用增量刷新模式來執行。這樣做既可以減少每一層的數據刷新計算量,同時也可以提高數據計算的時效性。例如,如果某一層的數據有新增或對歷史數據有修改,可以很方便地通過Dynamic Table將增量刷新模式切換為全量刷新模式。並且當與Serverless服務結合使用時,可以進一步提升每一層數據之間歷史數據回刷的穩定性和便捷性。通過Dynamic Table可以非常方便地實現一份代碼支持多種計算模式。這樣極大地簡化了數據加工流程,無需引入其他外部調度組件,就能自動管理各層之間的刷新任務。同時,這也提升了數據刷新的靈活性,滿足了準實時數倉開發的需求。
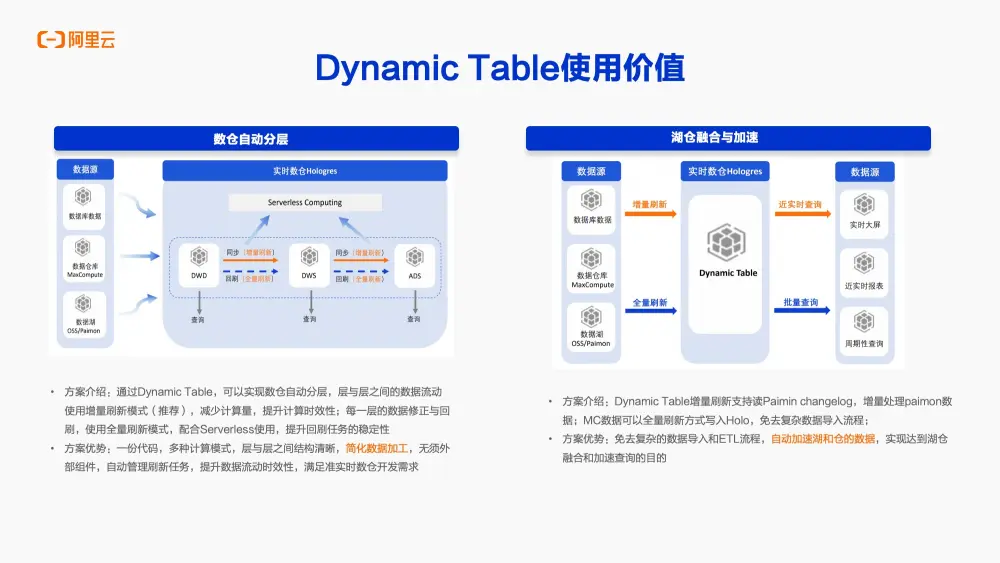
第二個典型場景是數據湖與數據倉的融合。Dynamic Table的基表,即查詢中的基礎表,可以來源於OSS 、Parquet 、以及MaxCompute等數據源。
一個常見的應用是,Dynamic Table通過增量方式讀取Parquet文件中的增量日誌。由於Parquet支持高效的列式存儲和讀取,可以利用Dynamic Table的增量刷新功能,高效地消費Parquet中的日誌數據,實現數據的增量處理。
另一個例子是,對於MaxCompute中的數據,可以通過全量刷新的方式將其寫入Dynamic Table。這種方式結合了增量與全量的數據處理方式,極大地簡化了數據導入和ETL過程,並自動加速了數據湖與數據倉之間的數據流動,實現了兩者之間的數據融合與加速。
二、Dynamic Table實操demo
本次演示將分為三個場景進行介紹。
2.1 創建全量刷新的Dynamic Table
第一個場景,即端到端地創建一張全量刷新的Dynamic Table。
2.2 創建增量量刷新的Dynamic Table
如何基於Parquet外表進行增量刷新來更新表格。
2.3 創建全量和增量融合的Dynamic Table
第三個場景是增量和全量混合使用的場景。
通常原表的數據量可能非常大,動輒幾億、幾十億條記錄,因此經常需要進行分區操作。在業務上,往往需要對當天的分區數據進行實時查詢,而對於歷史分區的數據,則可能需要進行離線查詢或離線修正。而為了滿足這樣的需求,可以通過Dynamic Table來實現。
具體操作Demo視頻請參考:
<u>https://cloud.video.taobao.com/vod/0xrZGXTojnmEI53NUIPNITzuJhG_TUXAmYBYxmDvJ1I.mp4</u>
三、Dynamic Table使用建議
Demo完成後,接下來來看一下關於Dynamic Table的使用建議。
- 第一個是要明確何時選擇增量刷新,何時選擇全量刷新。我的建議是,在可能的情況下,都儘量使用增量刷新。因為增量刷新每次處理的Query數據量較少,所以處理速度會更快,同時消耗的計算資源也會更低。然而目前增量刷新有一些使用上的限制,需要參考文檔來了解這些限制。此外使用增量刷新還需要為Base表開啓Blog,這會產生一定的存儲開銷。另外需要注意目前增量刷新主要支持維表,而雙流的支持正在開發中,大家可以等待一段時間,未來就可以使用上雙流的功能了。
- 第二個是關於如何觀測增量刷新的延遲問題。由於增量刷新是通過週期性間隔來執行的,如果上游數據寫入頻繁,且每次刷新時效性要求較高、延遲間隔較短,那麼可能會出現動態表與原表數據不一致的情況。該如何觀測這種不一致呢?Hologres 提供了一個名為 Dynamic_Table_Refresh_History 的系統表,可以查看到每一次刷新的記錄。在這張系統表中,有一個字段叫做 Refresh_Latency ,通過這個字段,可以查詢到動態表中的數據與基表數據之間的延遲時間。基於這個延遲時間就可以判斷增量刷新的延遲情況了。但是每次通過週期性的增量刷新,雖然可能在某次刷新中存在延遲,但這一延遲通常會在下一次刷新時被彌補,確保數據的最終一致性。儘管短期內可能存在延遲,但最終延遲會趨向於零。
- 第三是在使用Dynamic Table時,推薦儘量採用分區表的形式。以剛剛演示的Demo為例,如果一張表既需要滿足實時寫入的需求,又存在歷史數據回刷和訂正的場景,那麼使用Dynamic Table的分區表將是一個非常好的選擇。在這種情況下,推薦對最新的分區採用增量刷新模式,而對歷史的分區則使用全量刷新模式。這樣一來通過一套代碼就可以實現不同的刷新策略。在剛才的演示中分區表的使用場景確實相對複雜。由於目前Dynamic Table還未支持動態刷新功能,那麼該如何應對這一挑戰呢?讓再次回到之前的界面。大家可以看到,目前的分區都是手動創建的,而且增量刷新也需要手動轉換為全量刷新,這在Circle上的操作並不便捷。不過可以通過Dataworks這一新版的數據開發平台來提供支持。Dataworks的新版數據開發同樣支持動態表。例如,我這裏已經有一個創建好的動態表實例展示,在這個實例中,所有動態表的創建和配置都已經完成,大大簡化了操作流程。而在構建分區表時,一旦確定了分區字段,右側的配置選項將能夠自動進行相應設置。例如可以預設分區創建的提前時間,以實現動態分區的效果。具體來説是可以設定分區創建的提前量,以及分區的具體創建時間點。此外還可以設定分區刷新的啓動時機,以及何時自動將分區從增量刷新模式切換為全量刷新模式。通過DataWorks這一平台能夠輕鬆實現動態分區的目的。歡迎大家積極嘗試並使用這一功能。另外正在開發新版的動態分區表,屆時Dynamic Table的使用將會變得更加簡便,無需用户關心分區的創建以及刷新模式的切換。系統會自動處理模式的轉換,並自動創建所需的分區索引,極大地簡化了操作流程。這一功能預計將在3.1版本中推出,歡迎大家屆時體驗。回到PPT的界面,關於分區表的應用場景。通過Hologres的分區表功能,可以總結得出僅通過一套代碼,就能實現增量和全量兩種刷新計算模式,既高效又便捷。
- 第四是關於計算資源的選擇,即在本地實例和Serverless之間如何做出抉擇。如果刷新任務相對較小,使用本地實例的資源通常是沒有問題的。然而當每次刷新,特別是涉及到歷史數據的全量回刷時,強烈建議使用Serverless資源。這樣做不僅可以提高任務的穩定性,還能有效避免對其他任務可能產生的干擾和影響。
- 第五是關於刷新任務的監控、告警及觀測。外部系統可以管理整個刷新任務及其血緣關係。同時在監控指標中,也可以查看到與Refresh相關任務的運行情況,例如QPS、RPS以及失敗情況等。大家還可以通過雲監控等方式,設置相應的監控項和報警規則。以上是關於dynamic table使用的一些建議。
四、與其他產品對比
此外,分享一下Dynamic Table與其他產品的對比情況,這裏主要對比的是DIS的異步物化視圖和Snowflake的Dynamic Tables。
總結來説,目前Hologres的Dynamic Table功能已經基本上與Snowflake的Dynamic Tables相當。兩者都支持批量刷新,同時也都支持分鐘級的增量刷新。在查詢類型上,它們都支持單表聚合、多表關聯以及維度表關聯等。在觀測性方面,Hologres也如同Snowflake一樣,提供了可視化界面以及監控告警等功能。另外,在與Doris的異步物化視圖進行對比時,可以發現Doris的異步物化視圖主要依賴於批量刷新機制。儘管它能夠針對指定的分區或數據範圍進行刷新,但本質上仍是批量處理。相比之下,Hologres的優勢在於支持增量刷新。這意味着在每次處理時,系統僅需處理增量的數據,從而顯著減少了數據計算量,降低了資源消耗。這一特性使得Hologres能夠輕鬆應對分鐘級延遲的準實時場景。
然而,異步物化視圖也具備一個顯著優勢,即支持查詢的透明改寫。目前,若要使用Hologres的Dynamic Table進行查詢,用户僅能查詢與Dynamic Table相關的數據。但值得注意的是,後續也將支持這一功能,以進一步提升用户體驗。