

作者:鷹角網絡高級大數據研發 茅旭輝
背景介紹
鷹角網絡是一家年輕且富有創新的遊戲公司,致力於開發充滿挑戰性和藝術價值的遊戲產品。公司目前涵蓋了遊戲開發、運營和發行的全生命週期業務。隨着業務的擴展,鷹角網絡從單一爆款遊戲發展到多賽道、多平台、全球化的戰略佈局,在數據業務上進行了全面的優化和升級。
從業務上看,以《明日方舟》為代表的長線運營遊戲,具有相對高頻的活動週期和豐富多樣的活動玩法,反映到數據層面則是數據需求量高、潮汐現象顯著,需要高效的開發模式支持和靈活的彈性資源供給。我們的數據支持不僅僅有傳統的BI報表形式,更是深入集成到遊戲玩法和運營層面透出,對於引擎穩定性有強烈訴求。另外,內部面向業務的分析跑數場景,存在基於Thrift Server等能力擴展支持的訴求。
為什麼選擇阿里雲EMR Serverless Spark
原有架構痛點
在業務發展過程中,原有架構逐漸暴露出瞭如下痛點:
- 產品功能上,缺少外部Catalog支持和DolphinScheduler等流行調度引擎集成支持
- 引擎性能上,社區兼容性相對較低產生穩定性問題,且不支持Remote Shuffle Service服務導致性能問題
- 服務保障上,技術支持力度較弱,在用户痛點發掘和產品迭代方面做的不足
EMR Serverless Spark優勢
我們期待的雲原生大數據架構是基於開放生態、資源彈性、可插拔集成理念下的半托管+全託管靈活組合架構,而EMR Serverless Spark正是完美匹配這套理念的重要一環。它是一款兼容開源 Spark 的高性能 Lakehouse 產品,為用户提供任務開發、調試、發佈、調度和運維等全方位的產品化服務,顯著簡化了大數據計算的工作流程,使用户能更專注於數據分析和價值提煉,具備如下核心優勢:
-
豐富的功能支持
- 元數據管理:支持管理Paimon Catalog,並且支持對接外部Hive MetaStore元數據服務。
- 調度引擎支持:提供了Airflow、DolphinScheduler等多種調度引擎無縫集成。
- 資源管理模型:提供了易於理解的三級資源管理模型(工作空間、隊列、會話)和細粒度的隊列資源監控。
- 生態能力:提供了Spark Thrift Server、Notebook等多種生態功能,便於業務靈活使用。
-
優秀的引擎性能
- Shuffle性能:內置Celeborn服務,解決了大Shuffle場景下的磁盤限制問題。
- SQL執行引擎:內置的高性能Fusion引擎,為計算加速提供支持。
- 穩定性:100%保持社區兼容性,並積極修復潛在Bug。
- 版本支持:持續追蹤Spark社區版本,提供多版本迭代支持和完整的引擎特性使用。
-
完善的服務保障
- 問題響應:提供了專業的技術諮詢和解決方案支持,增強合作信任度。
- 產品規劃:提供了清晰的產品迭代規劃,持續解決用户痛點場景。
技術方案設計
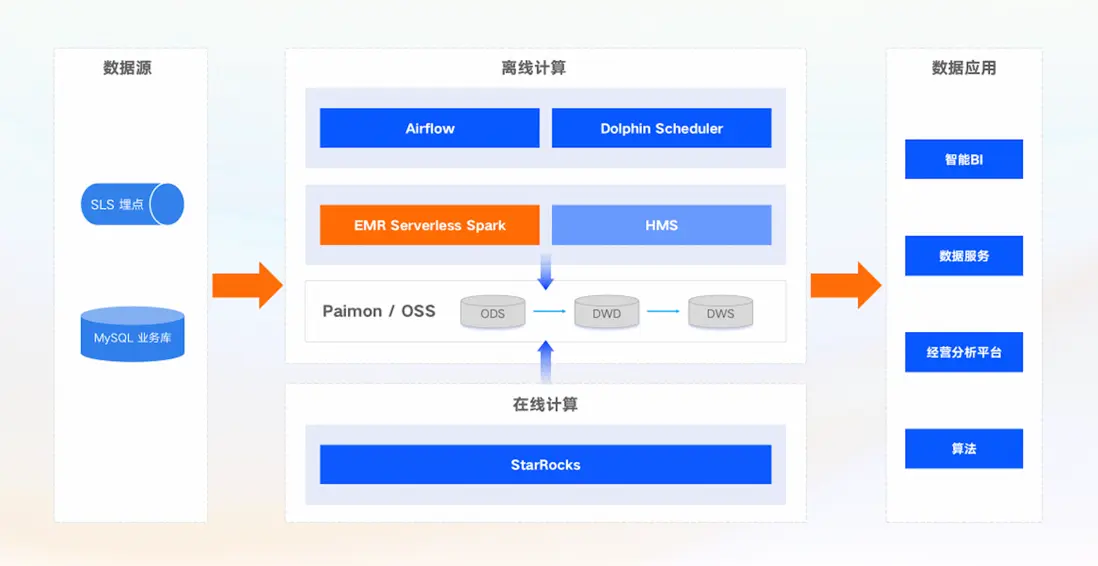
數據採集
在數據採集和管理方面,我們採用了自研的埋點工具來獲取和管理日誌數據,並利用Flink CDC技術同步數據庫表。這確保了數據的實時性和準確性,為後續的數據分析提供了可靠的基礎。
離線調度
在離線調度方面,我們實施了兩種策略一種引擎,一是使用Airflow服務支持有代碼基礎的研發用户,同時為普通數據分析師和數倉研發提供了DolphinScheduler服務,這兩種調度系統都實現了對 EMR Serverless Spark 的對接,滿足平台服務的靈活性。
我們選擇了 Serverless Spark 作為其離線計算引擎,相比於之前的架構,Serverless Spark顯著減少了運維成本,並提高了系統的穩定性和可靠性。其 Celeborn 能力解決了大 Shuffle 任務操作中的磁盤限制問題,同時任務狀態與調度工具實現了強一致性,無需二次確認,進一步優化了數據處理流程。
在線計算
為了支持在線計算和數據應用,我們使用Starrocks進行在線計算,高質量的指標數據通過智能BI系統實現可視化實時展示,並提供了清晰的業務洞察。同時,數據還被整合到經營分析平台,為其業務發展提供了統一支持。數據也應用於算法團隊進行業務探索與數據科學分析。
典型應用場景
DolphinScheduler 集成作業開發
Serverless Spark在DolphinScheduler中集成了專用的作業類型ALIYUN_SERVERLESS_SPARK,支持SQL、SQL File、Jar包等多種作業形式。我們在本地Git倉庫開發作業,通過CI流程部署到OSS存儲路徑下,並使用SQL File/Jar作業類型,提交相應的作業文件到Serverless Spark執行計算。
Thrift Server 支持 Ad-Hoc
Serverless Spark內置了Thrift Server服務,支持通過JDBC的方式連接Spark執行SQL查詢,提供了便捷將Spark環境與其他數據分析工具集成的途徑。目前Spark Thrift Server能力在內部主要支持以下兩類場景:
- 以產品運營人員為主的Ad-Hoc分析場景,期望通過Spark引擎執行SQL查詢,但希望忽略資源配置等非必要信息,可以直接使用DolphinScheduler內置的SQL作業類型 + Spark數據源進行簡單查詢。同時Spark Thrift Server會話支持動態資源配置,可以自適應支持Ad-Hoc查詢所需資源。
- 以數倉研發為主的數據結果返回場景,能夠拿到SQL查詢結果並傳遞給下游作業使用。
遷移後的收益
通過這一系列技術棧的優化,我們不僅優化了數據管理和分析流程,還有效支持了公司的全球化戰略和業務擴展,目前我們已經在海外基於 EMR Serverless Spark 搭建類似數據架構。
EMR Serverless Spark主要給我們帶來了以下收益:
- 研發效率提升,支持業務快速發展
遷移到EMR Serverless Spark + DolphinScheduler架構後,使用Spark SQL會話功能快速開發驗證+DolphinScheduler生產調度的模式,研發效率顯著提升,多次保障了關鍵活動節點的數據產出支持。
- 計算效率提升,增強SLA保障
在以用户寬表為代表的指標計算場景下,單作業計算用時從30分鐘降低到15分鐘,計算加速50%;核心SLA鏈路整體產出時間縮短1.5小時,大幅增強了SLA保障能力。
- 穩定性提升,降低運維壓力
EMR Serverless Spark 的多版本管理能力為用户提供了靈活的選擇空間,支持快速升級至最新優化版本,確保用户始終享有最穩定的運行體驗。
總結及後續期待
經過了業務實踐證明,EMR Serverless Spark在大數據研發下Spark生態領域的經典業務場景具備了足夠的優勢。對於未來,我們期望它能繼續以開放原則發展Lakehouse生態能力,例如統一Catalog管理等能力,並逐步覆蓋更多的邊緣場景和探索型場景。