









一、為什麼我們放棄了Azkaban?
我們最早選擇用 LinkedIn 開源的 Azkaban 做調度,主要是看中它兩個特點:一是界面清爽,操作簡單;二是它用“項目”來管理任務,非常直觀。那時候團隊剛開始搭建數據平台,這種輕量又清晰的工具,正好符合我們的需要。其他還有其他原因:
- 社區活躍(當時)
- 部署簡單,依賴少(僅需 MySQL + Web Server + Executor)
- 支持 job 文件定義依賴,適合 DAG 場景
但隨着業務規模擴大,Azkaban 的短板逐漸暴露:
- 缺乏任務失敗自動重試機制
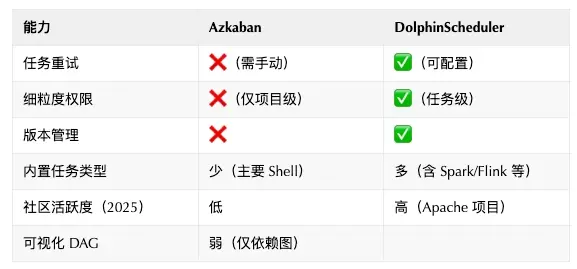
Azkaban 的重試策略極其原始:要麼手動點擊重跑,要麼通過外部腳本輪詢狀態後觸發。我們曾因一個 Hive 任務因臨時資源不足失敗,導致下游 20+ 個任務全部阻塞,運維不得不半夜手動干預。
- 權限粒度粗糙
Azkaban 的權限模型只有“項目級別”的讀寫權限,無法做到“用户A只能編輯任務X,不能動任務Y”。在多團隊共用一個調度平台時,權限混亂導致誤操作頻發。
- 缺乏任務版本管理
每次修改 job 文件都會覆蓋歷史版本,無法回滾。我們曾因一次錯誤的參數修改,導致整個 ETL 流水線跑出錯誤數據,花了兩天才定位到是哪個版本的 job 出了問題。
- 擴展性差
Azkaban 的插件機制確實不太給力,想接個企業微信告警、對一下內部的 CMDB,或者讓它支持 Spark on K8s,基本都得去改源碼。而且官方社區更新也慢,GitHub 上面一堆 issue 掛着,經常沒人理。
反思: Azkaban 用在小團隊、任務不復雜的時候還行,一旦數據平台規模上來了、團隊變多了,就會發現它的架構有點跟不上了,各種限制就冒出來了。
二、為什麼選擇DolphinScheduler?
2022 年底,我們開始評估替代方案,對比了 Airflow、XXL-JOB、DolphinScheduler 等主流調度系統。最終選擇 DolphinScheduler(以下簡稱 DS),主要基於以下幾點:
- 原生支持豐富的任務類型
DS 內置 Shell、SQL、Spark、Flink、DataX、Python 等十幾種任務類型,且支持自定義任務插件。我們無需再為每個任務類型寫 wrapper 腳本。
- 完善的失敗處理機制
- 支持任務級重試(可配置重試次數、間隔)
- 支持失敗告警(郵件、釘釘、企業微信)
- 支持“失敗後跳過”或“失敗後終止整個工作流”
- 細粒度權限控制
在DS平台裏,權限管理做得很細緻。從租户、項目、工作流到具體任務,層層都可以設置不同人員的操作權限。這樣既保證了安全,又讓不同團隊能夠順暢協作,特別實用。
- 可視化 DAG + 版本管理
拖拽式 DAG 編輯,支持任務依賴、條件分支、子流程
工作流每次發佈自動保存版本,支持回滾到任意歷史版本
- 活躍的中文社區
作為 Apache 頂級項目,DS 在國內有大量用户和貢獻者,文檔完善,問題響應快。我們遇到的幾個生產問題,都在社區羣中 24 小時內得到解答。
三、真實遷移案例:從 Azkaban 到 DolphinScheduler
背景
- 原系統:Azkaban 3.80,約 150 個工作流,日均任務數 800+
-
目標:平滑遷移至 DS 3.1.2,不影響業務數據產出
遷移步驟
-
任務梳理與分類
- 對現有的 Azkaban 作業做個盤點。先按任務類型(例如 Shell 腳本、Hive SQL、Spark 作業)分個類,然後重點梳理出它們之間的強依賴關係,把整個任務的上下游鏈路明確下來。
- 標記強依賴關係(如 A → B → C)
-
DS 環境搭建與測試
- 部署 DS 集羣(Master + Worker + API Server + Alert Server)
- 創建租户、用户、項目,配置資源隊列(YARN)
-
任務重構與驗證
- 將 Azkaban 的 .job 文件轉換為 DS 的工作流定義
- 重點處理:參數傳遞(Azkaban 用
${},DS 用${}但語法略有不同);依賴邏輯(Azkaban 用dependencies,DS 用 DAG 連線) - 在測試環境跑通全流程,驗證數據一致性
- 灰度切換
- 先遷移非核心報表任務(如運營日報)
- 觀察一週無異常後,逐步遷移核心鏈路(如用户行為日誌 ETL)
-
最終全量切換,保留 Azkaban 只讀狀態 1 個月用於回溯
踩坑記錄
- 坑1:參數傳遞不一致
Azkaban 中 ${date}會自動注入當前日期,而 DS 需要顯式定義全局參數或使用系統內置變量 {system.datetime}。我們寫了個腳本自動轉換參數語法。
- 坑2:資源隔離問題
之前我們所有任務都擠在同一個YARN隊列裏,結果那些跑得久的大任務動不動就把資源全佔了,搞得其他小任務一直卡着。後來我們給每個業務線都單獨開了賬户和YARN隊列,這下總算清淨了,大家各跑各的,誰也不耽誤誰。
- 坑3:告警風暴
任務失敗動不動就告警,一開始每天狂響上百條,實在頭疼。後來我們調整了策略:只給核心任務開實時告警,非核心的就每天彙總一下,發個郵件同步,清爽多了。
四、給後來者的具體建議
- 不要盲目追求“大而全”
如果你只有幾十個 Shell 腳本任務,用 Cron + 簡單監控可能效率更高一點。調度系統有運維成本,評估 ROI 再決定。
- 重視權限與租户設計
從第一天就規劃好租户結構(如按業務線劃分),避免後期權限混亂。建議開啓“任務審批”功能,關鍵任務變更需 review。
- 建立任務健康度指標
- 任務失敗率
- 平均運行時長波動
- 依賴阻塞次數
我們用 Prometheus + Grafana 監控這些指標,提前發現潛在問題。
- 善用子流程(SubProcess)
複雜的 DAG 一多,就容易亂得像“一鍋粥”。我們可以把那些常用的功能,比如數據質檢、日誌歸檔這些,打包成獨立的子流程。這樣一來,不僅複用起來方便,後期維護也省心多了。
- 備份與災備不能少
- 定期備份 DS 元數據庫(MySQL/PostgreSQL)
- 配置多 Master 高可用
-
關鍵任務設置“跨集羣容災”(如主集羣掛掉,自動切到備用集羣)
五、關鍵對比速查表
技術選型不是終點,而是持續優化的起點。







