









文本到圖像(T2I)生成模型的發展速度超出很多人的預期。從SDXL到Midjourney,再到最近的FLUX.1,這些模型在短時間內就實現了從模糊抽象到逼真細膩的跨越。但問題也隨之而來——如何讓模型生成的不僅僅是"一張圖",而是"正確的那張圖"?這涉及到如何讓AI理解人類在審美、風格和構圖上的真實偏好。
強化學習(RL)成為解決這個問題的關鍵技術。通過將人類偏好分數作為獎勵信號,可以對這些大模型進行微調。羣體相對策略優化(GRPO)是近期比較熱門的方案。但清華大學和快手的研究團隊最近發現,這個方法存在一個隱藏的根本性缺陷。
這個缺陷會讓模型學錯東西,即便最終生成的圖像看起來還不錯。論文"SAMPLE BY STEP, OPTIMIZE BY CHUNK: CHUNK-LEVEL GRPO FOR TEXT-TO-IMAGE GENERATION"提出了一個叫Chunk-GRPO的解決方案,思路直接並且效果出眾,算是訓練生成模型思路上的一次轉向。
GRPO的問題:不準確的優勢歸因
要理解Chunk-GRPO做了什麼,得先搞清楚現有方法的問題出在哪。論文把這個問題叫做"不準確的優勢歸因"(inaccurate advantage attribution)。
可以用一個類比來説明。假設你在教學徒做酸麪糰麪包,整個流程有17個步驟。學徒做了兩個麪包——麪包A各方面都很棒,麪包B勉強及格。作為師傅,你給A打了高分(+10),給B打了低分(+2)。
標準GRPO的做法相當於告訴學徒:"麪包A的每一個步驟都比B好。"它把最終的高分獎勵追溯性地分配給製作A的所有17個步驟。
但實際情況可能是,做A的第3步時學徒差點打翻面團,而做B的第3步手法其實很標準。標準GRPO仍然會獎勵A的糟糕第3步,懲罰B的正常第3步,就因為最終結果不同。這就是"不準確的優勢歸因"——模型被強化的某個具體動作,單獨看其實是個錯誤。訓練幾千次之後,這種錯誤的反饋信號會讓模型困惑,導致訓練不穩定,效果也達不到最優。
論文用圖像生成的真實案例展示了這個問題:
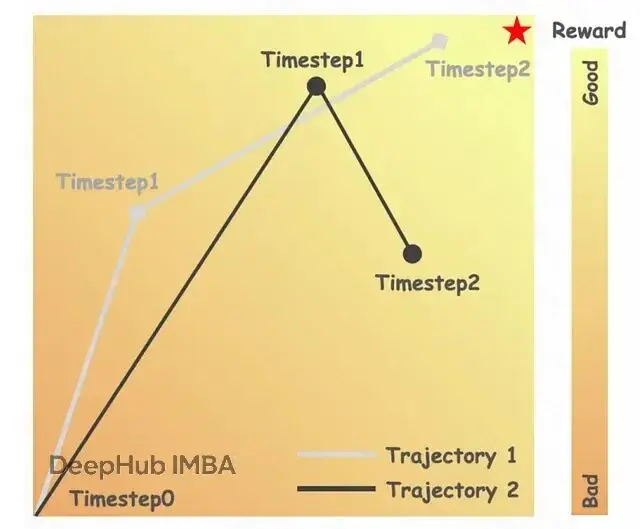
軌跡1有更好的最終圖像,但與軌跡2相比,有更差的中間步驟(t=1)。説明標準GRPO如何錯誤地獎勵軌跡1中的壞步驟。除了歸因不準確,還有第二個相關問題:忽略時間動態。做麪包的17個步驟重要程度其實不同——步驟1到5是建立面團基礎結構,步驟6到12是發酵和發展,步驟13到17是烘烤收尾。每個階段的作用和特點都不一樣。
在基於流匹配(flow-matching)的T2I生成中也是類似的情況。模型從純噪聲開始,逐步細化成連貫圖像。早期時間步決定整體構圖和主體,做大幅度的粗調整;中間步驟細化形狀,添加中等細節;最後的步驟打磨光照、紋理這些精細元素。標準GRPO對決定"這是隻貓"的步驟和細化貓眼睛反光的步驟給予相同的優化權重,這既低效,也違背了生成過程本身的階段性特徵。
Chunk-GRPO的核心思路:按塊而非按步優化
Chunk-GRPO的解決方案很簡單:停止對每個步驟做微觀管理,改為按階段思考。不再評估每個單獨的步驟,而是把相關步驟分組成"塊"(chunk),對每個塊的整體表現進行評估。
還是麪包的例子。與其對17個步驟逐一反饋,不如評估三個階段:混合揉麪階段(步驟1-5)麪糰基礎建得怎麼樣?發酵整形階段(步驟6-12)發酵控制和整形技巧如何?烘烤冷卻階段(步驟13-17)温度掌握和外皮發展是否到位?
在塊級別優化的好處是,第3步那個小失誤會被整個"混合揉麪"塊的表現平均掉。如果這個塊裏其他步驟都做得好,塊整體還是算成功的。這種方法對偶發的孤立錯誤更加泛化,也更符合專家實際教學和學習複雜技能的方式——不是把知識切成無數個離散點,而是按連貫的多步驟動作來組織。
"動作分塊"(action chunking)這個概念在機器人學等領域已經被證明很有效,能幫機器人學會流暢的長時程任務,而不是生硬的逐步動作。Chunk-GRPO論文是首次系統性地把這個思路應用到T2I模型的強化學習微調中。
具體機制上,Chunk-GRPO改變了優化目標。它不再為每個時間步
t計算重要性比率(importance ratio,衡量策略變化的指標),而是為整個塊
j計算一個重要性比率,方法是取該塊內所有步驟重要性比率的幾何平均值。然後把最終的優勢值(來自最終圖像的獎勵)應用到這個塊級的單一數值上。
從步驟級到塊級優化的轉變直接緩解了不準確歸因的問題。一個原本不錯的步驟序列中出現的單個壞步驟,不會再獲得不該有的獎勵。優化信號變得更平滑也更穩定,能更真實地反映該生成階段的實際貢獻。
但這帶來一個關鍵問題:怎麼確定塊的邊界?是分3塊、5塊還是其他?每塊大小要相同嗎?論文的第二個巧妙之處就在這裏。
時間動態引導的分塊策略
如果隨意把17個生成步驟分成4、4、4、5這樣的塊,確實已經比步驟級優化好了。並且論文的消融實驗證實,幾乎任何形式的分塊都優於不分塊。
但他們想知道:能不能找到一種有原則的方法來定義塊邊界?生成過程是否存在某種自然的內在結構可供參考?
他們通過分析流匹配過程的時間動態(temporal dynamics)找到了線索。使用的指標是相對L1距離
L1_rel,本質上衡量圖像的潛在表示從一個時間步到下一步的變化幅度——高值表示劇烈變化,低值表示微調細化。
當把這個指標在FLUX.1模型的生成時間步上畫出來時,他們發現了一個規律:
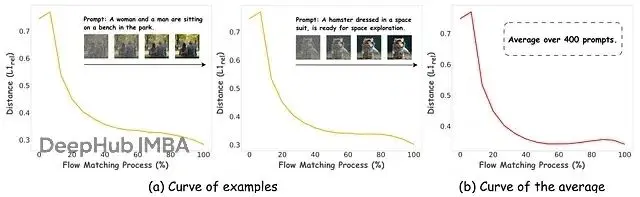
流匹配的提示不變時間動態,顯示跨時間步的L1_rel距離曲線。曲線應該在開始時顯示高值,在中間下降,在結束時上升。註釋圖表以顯示生成的"階段":"結構定義"、"細化"和"細節刻畫"。圖表顯示出清晰、一致且與提示無關的模式。不管模型生成的是"一隻貓坐在墊子上"還是"火星上降落的宇宙飛船",創作的節奏都是一樣的。
早期時間步的
L1_rel值很高,模型在做大幅度跳躍,把純噪聲轉化為基本構圖,這是粗略草圖階段。中間時間步
L1_rel降低,變化變得細緻,模型在細化形狀、清理構圖、填補細節,相當於上色和陰影階段。後期時間步
L1_rel可能再次上升,模型添加高頻細節、紋理和最終光效,進入打磨階段。
這個動態曲線提供了一種數據驅動的自然分割方式。作者據此實現了時間動態引導的分塊(temporal-dynamic-guided chunking),在生成節奏發生變化的位置設置塊邊界。
針對17個採樣步驟的實驗,他們採用了4個塊,大小分別是
[2, 3, 4, 7]。這不是隨便定的,反映的是模型自身的行為特徵:塊1(大小2)是定義宏觀結構的初始混亂階段;塊2(大小3)和塊3(大小4)是圖像成型的核心細化期;塊4(大小7)是添加細節和打磨輸出的漫長收尾階段。
這就是Chunk-GRPO的關鍵。它不只是簡單地把步驟湊成組,而是把它們分成與模型內部工作流對應的、語義上有意義的階段。就像聽藝術家的創作過程,在每個主要階段結束時給反饋,而不是每一筆都打斷。
技術細節:從步驟級到塊級的數學轉換
對想深入瞭解的讀者,這裏拆解一下Chunk-GRPO的具體機制。得先看標準GRPO的目標函數。
步驟級GRPO的數學形式
在流匹配的標準GRPO中,策略(T2I模型,記為
θ)通過最大化目標
J(θ)來更新。簡化後大致是這樣:
J(θ) ≈ Σ_i Σ_t [ r_t^i(θ) * A^i ]這裏
i是給定提示下生成的每張圖像的索引。
t是時間步,從
1到
T。
A^i是第
i張圖像的優勢(advantage),通過比較最終圖像的獎勵與組內平均獎勵計算得到。關鍵是,
A^i對所有時間步
t都相同——這就是"不準確優勢歸因"問題的數學體現。
r_t^i(θ)是時間步
t的重要性比率,衡量新策略
θ相對舊策略
θ_old在該步驟上的轉換概率比值,反映策略的變化程度。
優化過程會推動策略增加那些導致高優勢圖像的步驟的概率。但因為
A^i是常數,所有步驟都被同等地推動。
塊級方案的重構
Chunk-GRPO重新定義了這個目標。不對每個時間步
t求和,而是對數量更少的塊
j求和:
J(θ) ≈ Σ_i Σ_j [ r_j^i(θ) * A^i ]優勢
A^i還是一樣的(基於最終圖像),但重要性比率現在定義在塊級別。論文把塊級重要性比率
r_j^i(θ)定義為該塊內步驟級比率的幾何平均:
r_j^i(θ) = ( Π_{t ∈ ch_j} r_t^i(θ) )^(1/cs_j)其中
ch_j是塊
j包含的時間步集合,
cs_j是塊
j的大小,
Π表示連乘。
為什麼這樣更好?論文附錄有數學分析,直觀理解就是這種平均化過程提供了更平滑穩定的優化地形。通過幾何平均,任何一個可能有噪聲或者異常的單個
r_t^i(θ)的影響都會被抑制。傳回模型的梯度信號不再是一連串尖鋭的、可能相互矛盾的步驟級指令,而是針對整個生成階段的更平滑、更整體的引導。
論文附錄的分析表明,在存在不準確優勢歸因的情況下,塊級目標可以被證明比標準步驟級GRPO目標更接近"真實"目標,尤其是當塊大小保持適度(比如5或更小)時。這為實驗結果提供了理論支撐。
加權採樣策略
作者還引入了一個可選的增強方案——加權採樣策略(weighted sampling strategy)。
訓練時為了提效,常見做法是隻對每個訓練樣本的一部分時間步(或塊)計算損失,通常採用均勻採樣。但作者認為不同塊在學習中的重要性不一樣。
他們做了個消融實驗,只訓練某一個特定的塊,結果發現優化早期的高噪聲塊(比如塊1)帶來的偏好分數提升最大,但也有不穩定的風險:
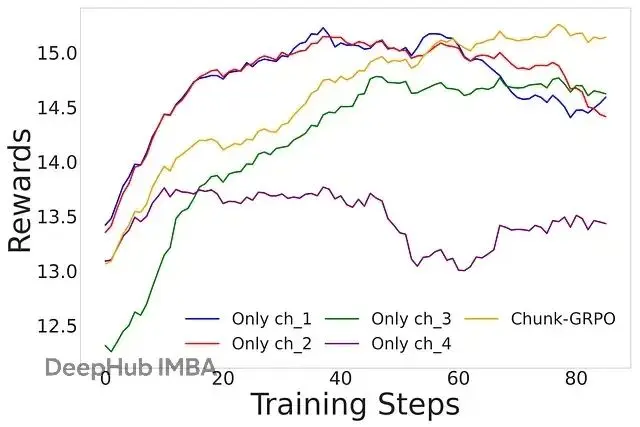
訓練特定塊的結果,顯示訓練單個塊時的性能改進。圖表應該顯示訓練早期塊(ch1)給出高獎勵但可能不穩定,而後期塊(ch4)更穩定但改進較少。基於這個發現,他們設計了加權採樣方案,讓訓練過程更偏重那些平均
L1_rel距離更高的塊——也就是發生劇烈變化的階段。策略目標是兼得兩頭:通過聚焦高影響區域來加速偏好對齊。
不過從結果看,這種能力是有代價的。可以把它理解為一個旋鈕,調高能獲得更好的偏好對齊,但有時會"破壞"圖像的核心結構——典型的獎勵黑客(reward hacking)現象。
實驗結果:量化和視覺上的改進
任何方法最終都要看輸出質量。Chunk-GRPO在這方面表現不錯,研究團隊把它和基礎FLUX.1模型以及標準步驟級Dance-GRPO做了對比。
數值指標
在偏好對齊基準測試上,Chunk-GRPO有明顯提升:
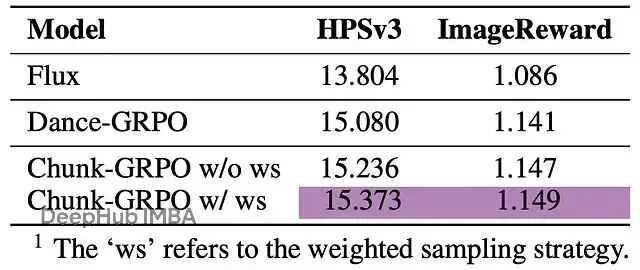
偏好對齊的結果,顯示HPSv3和ImageReward分數。使用清晰的標籤,如"基礎模型(FLUX.1)"、"標準RL(Dance-GRPO)"和"Chunk-GRPO"。突出顯示Chunk-GRPO的獲勝分數。Chunk-GRPO在訓練用的域內獎勵模型(HPSv3)和域外模型(ImageReward)上都持續高於標準GRPO,説明改進具有泛化性,不是單純針對測試調優。帶加權採樣的版本(
w/ ws)把偏好分數推得更高。
在WISE基準測試上,這個測試評估模型根據物理、生物、文化等領域的世界知識生成圖像的能力,不帶加權採樣的Chunk-GRPO拿到了最高總分,展現出對語義概念更好的理解:
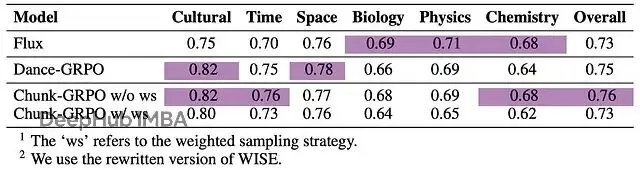
WISE的結果,顯示WISE基準測試結果。再次強調Chunk-GRPO(w/o ws)獲得了最高的"總體"分數。有意思的是,加權採樣策略在提升審美偏好的同時,在基於知識的WISE和指令遵循的GenEval基準上反而略有損失。這印證了前面提到的權衡:激進地優化"感覺"有時會犧牲語義準確性。對需要平衡這些競爭目標的實踐者來説,這是個值得注意的發現。
視覺質量
數字之外,圖像本身更有説服力。大量樣本顯示Chunk-GRPO生成的圖像確實更好:

Chunk-GRPO顯著提高了圖像質量,特別是在結構、光照和細粒度細節方面,展示了塊級優化的優越性。
和已經很強的基礎模型及標準RL調優版本比,Chunk-GRPO的圖像在結構和構圖上更連貫、更有意圖感;光照處理更戲劇化也更真實,對比度、陰影和高光的物理合理性更好;色彩更飽滿,紋理更細膩,細節更豐富。

FLUX、DanceGRPO、不帶時間動態的Chunk-GRPO、帶時間動態的Chunk-GRPO和帶加權採樣的Chunk-GRPO之間的額外可視化比較。
論文也展示了失敗案例。有個具有挑戰性的提示,加權採樣策略在激進追求更好外觀時把提示中的關鍵對象給漏掉了。這種分析幫助理解模型的行為邊界。
説明審美質量和語義準確性之間存在這種權衡,實際應用時如何調優,取決於具體場景的需求側重。
未來方向和侷限
Chunk-GRPO是個不小的進步,但論文作者也指出了後續研究的空間。
一個比較有吸引力的方向是超越單一獎勵信號,在不同塊之間使用異質獎勵(heterogeneous rewards)。可以設想對早期結構塊用關注構圖正確性的獎勵模型,對後期打磨塊用關注照片真實感和精細細節的另一個獎勵模型。這種做法更精細,也更像人類藝術指導的工作方式。
另一個改進點是分塊策略本身。目前塊邊界是預先計算好的,訓練時保持固定。更高級的系統可以實現自適應或動態分塊(self-adaptive or dynamic chunking),讓模型在訓練過程中學習最優塊邊界,甚至針對不同提示做調整。
拋開這些具體擴展,Chunk-GRPO的核心理念——讓優化過程與模型固有動態對齊——本身就很有價值。它提示應該把這些大型神經網絡當作有自己內部邏輯的複雜系統來對待,學會配合它們工作,而不是簡單粗暴地強行訓練。
這項工作展現了AI研究有意思的地方:理論洞察、工程技巧和可見的最終效果結合在一起。從優化步驟轉向優化塊,不只是小的技術調整,而是在教AI藝術家按照更接近人類藝術家的方式思考——分階段,有意圖,按自然節奏來。結果確實更好看。
總結
T2I模型的標準RL方法有個"不準確優勢歸因"的毛病,把好圖像的最終獎勵錯誤地應用到每個生成步驟,包括那些有問題的步驟。這些方法還忽視了不同時間步在生成中的差異化作用。
Chunk-GRPO的解決辦法是把連續時間步分組成"塊",把這些塊作為整體單元來優化,讓訓練信號更平滑,過程更穩定。塊的劃分不是隨意的,而是由模型自身的"時間動態"決定——創作過程的自然節奏,通過圖像在每步的變化幅度來度量。這讓優化過程和模型的內部工作流保持一致。
實驗結果顯示Chunk-GRPO生成的圖像在結構、光照和細節上都更優秀,在審美偏好和世界知識基準測試上的得分也高於標準方法。
這個思路開闢了新的研究方向,比如為不同塊使用不同的獎勵模型,或者開發能在訓練中自適應的動態分塊策略。
論文:
https://avoid.overfit.cn/post/801e16bc6ddb464bbeb532f74cdceb91
作者:ArXiv In-depth Analysis






