









大家好,我是半夏之沫 😁😁 一名金融科技領域的JAVA系統研發😊😊
我希望將自己工作和學習中的經驗以最樸實,最嚴謹的方式分享給大家,共同進步👉💓👈
👉👉👉👉👉👉👉👉💓寫作不易,期待大家的關注和點贊💓👈👈👈👈👈👈👈👈
👉👉👉👉👉👉👉👉💓關注微信公眾號【技術探界】 💓👈👈👈👈👈👈👈👈
前言
併發框架Disruptor是一個高性能隊列,其憑藉無鎖,消除偽共享等策略極大提升了隊列性能,本篇文章將基於示例和源碼,對Disruptor高性能隊列的使用和原理進行學習。
Disruptor版本:3.4.0
正文
一. Disruptor結構分析和組件介紹
Disruptor中的核心組件是RingBuffer,基於RingBuffer的生產者消費者模型,如下所示。
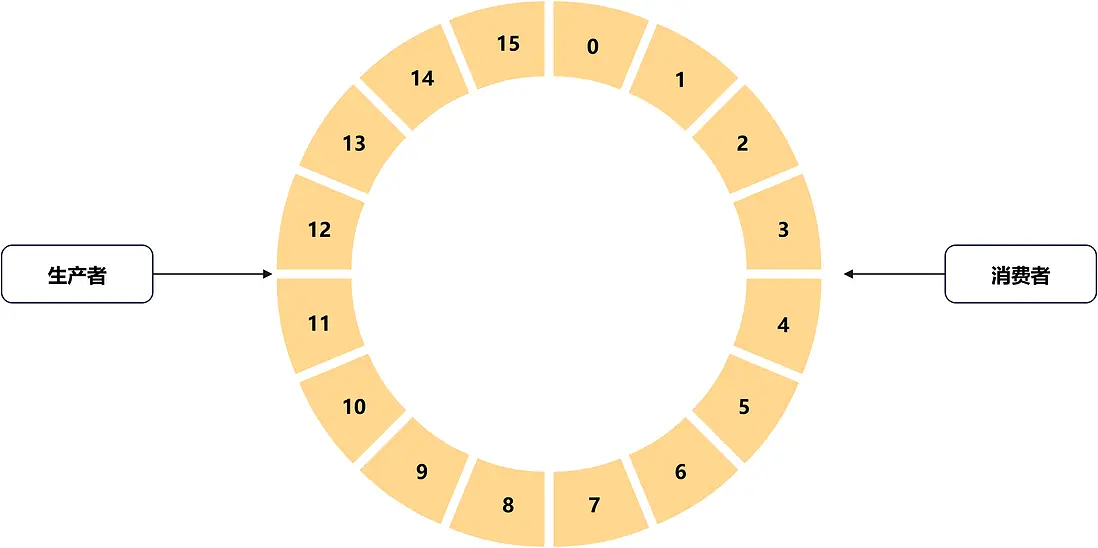
RingBuffer中有一個entries字段,是一個Object數組結構,RingBuffer使用entries來存儲元素,隊列工作過程就是生產者將數據寫入到RingBuffer的元素中,消費者從RingBuffer獲取元素中的數據。下面給出一種最簡單的使用場景,即單生產者場景。
Disruptor沒有對隊列中的元素類型做定義,需要使用者自行定義元素類型,本示例中將隊列的元素定義為TestEvent,如下所示。
public class TestEvent {
private String id;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
}然後定義TestEventHandler實現EventHandler接口,每個TestEventHandler都需要註冊到Disruptor中,Disruptor會基於每個註冊的TestEventHandler來創建BatchEventProcessor作為消費者,每個BatchEventProcessor消費到元素後會將元素交給其持有的TestEventHandler來處理。TestEventHandler實現如下所示。
public class TestEventHandler implements EventHandler<TestEvent> {
private final String consumerId;
public TestEventHandler(String consumerId) {
this.consumerId = consumerId;
}
@Override
public void onEvent(TestEvent testEvent, long sequence, boolean endOfBatch) {
System.out.println("Consumer-EventHandler-" + this.consumerId + " consumed message: " + testEvent.getId());
}
}再然後定義TestEventFactory實現EventFactory接口,用於幫助Disruptor在初始化RingBuffer時一次性將元素全部創建出來並填充滿元素數組。TestEventFactory實現如下所示。
public class TestEventFactory implements EventFactory<TestEvent> {
@Override
public TestEvent newInstance() {
return new TestEvent();
}
}最後是生產者,同樣的,Disruptor沒有對生產者做定義,本示例中自行封裝的生產者如下所示。
public class TestEventProducer {
private final RingBuffer<TestEvent> ringBuffer;
public TestEventProducer(RingBuffer<TestEvent> ringBuffer) {
this.ringBuffer = ringBuffer;
}
public void onData(String data) {
long sequence = ringBuffer.next();
try {
TestEvent testEvent = ringBuffer.get(sequence);
testEvent.setId(data);
} finally {
ringBuffer.publish(sequence);
}
}
}下面是一個測試程序,結合上述定義好的類,對生產和消費的簡單工作流程進行演示。
public class MyTest {
private static final String CONSUMER_ID_1 = "1";
private static final String CONSUMER_ID_2 = "2";
private static final String CONSUMER_ID_3 = "3";
private static final int RING_BUFFER_SIZE = 1024 * 1024;
private static final int WAIT_MS = 1000;
private static final int BATCH_NUM = 3;
public static void main(String[] args) throws Exception {
TestEventFactory factory = new TestEventFactory();
// 創建Disruptor,指定生產者類型為單生產者
Disruptor<TestEvent> disruptor = new Disruptor<>(factory, RING_BUFFER_SIZE,
Executors.defaultThreadFactory(), ProducerType.SINGLE, new YieldingWaitStrategy());
// 向Disruptor註冊TestEventHandler,即註冊消費者
disruptor.handleEventsWith(new TestEventHandler(CONSUMER_ID_1),
new TestEventHandler(CONSUMER_ID_2), new TestEventHandler(CONSUMER_ID_3));
// 開啓Disruptor,基於線程池將消費者運行起來
disruptor.start();
Thread.sleep(WAIT_MS);
// 創建生產者,並將數據寫入RingBuffer的元素中
RingBuffer<TestEvent> ringBuffer = disruptor.getRingBuffer();
TestEventProducer testEventProducer = new TestEventProducer(ringBuffer);
for (int i = 0; i < BATCH_NUM; i++) {
testEventProducer.onData(String.valueOf(i));
}
Thread.sleep(WAIT_MS);
// 關閉Disruptor
disruptor.shutdown();
}
}結合上述示例,在Disruptor框架中有如下幾個關鍵角色。
Disruptor對象。可以理解為Disruptor框架中的錨點,其持有一個RingBuffer對象,一個線程池Executor對象以及一個ConsumerRepository對象,生產者生產的數據會存放在RingBuffer中的元素中,同時當向Disruptor註冊事件處理器時Disruptor會基於註冊的事件處理器創建消費者並添加到ConsumerRepository中;RingBuffer對象。Disruptor框架中的核心對象,其持有一個Object數組用於存放元素以及一個Sequencer對象實現對生產者的同步控制;Sequencer對象。其實際是一個接口,有兩個實現類分別為SingleProducerSequencer和MultiProducerSequencer,代表對單生產者和多生產者的同步控制(可以這麼理解,上面示例中定義的生產者TestEventProducer如果向RingBuffer生產元素,那麼就會和其他生產者以及消費者產生併發衝突,Sequencer就是用於控制並解決這個併發衝突的);SequenceBarrier對象。其由Sequencer創建,並且會由消費者持有,主要用於消費者獲取當前可以消費的元素的序號;EventProcessor對象。其實際是一個接口,表示消費者,當向Disruptor對象註冊EventHandler對象時,Disruptor會基於EventHandler創建一個BatchEventProcessor對象作為消費者,當向Disruptor註冊WorkHandler對象時,Disruptor會基於WorkHandler創建一個WorkProcessor對象作為消費者,本篇文章提及的消費者全部指BatchEventProcessor;Sequence對象。每個EventProcessor消費者會持有一個Sequence,同時SingleProducerSequencer持有一個Sequence,MultiProducerSequencer持有兩個Sequence。Sequence的使用者都是使用Sequence來維護自己的讀/寫序號。
二. Disruptor對象的創建
Disruptor對象的構造方法如下所示。
public Disruptor(
final EventFactory<T> eventFactory,
final int ringBufferSize,
final ThreadFactory threadFactory,
final ProducerType producerType,
final WaitStrategy waitStrategy) {
this(
RingBuffer.create(producerType, eventFactory, ringBufferSize, waitStrategy),
new BasicExecutor(threadFactory));
}在創建Disruptor時會一併將RingBuffer創建出來,看一下RingBuffer的create()方法,如下所示。
public static <E> RingBuffer<E> create(
ProducerType producerType,
EventFactory<E> factory,
int bufferSize,
WaitStrategy waitStrategy) {
// 創建RingBuffer時會一併將Sequencer創建出來
// 如果指定的生產者類型為SINGLE,則創建SingleProducerSequencer
// 如果指定的生產者類型為MULTI,則創建MultiProducerSequencer
switch (producerType) {
case SINGLE:
return createSingleProducer(factory, bufferSize, waitStrategy);
case MULTI:
return createMultiProducer(factory, bufferSize, waitStrategy);
default:
throw new IllegalStateException(producerType.toString());
}
}本篇文章中的producerType為SINGLE,所以這裏分析createSingleProducer()方法,如下所示。
public static <E> RingBuffer<E> createSingleProducer(
EventFactory<E> factory,
int bufferSize,
WaitStrategy waitStrategy) {
// 先創建SingleProducerSequencer
SingleProducerSequencer sequencer = new SingleProducerSequencer(bufferSize, waitStrategy);
// 然後基於SingleProducerSequencer創建RingBuffer
return new RingBuffer<E>(factory, sequencer);
}在createSingleProducer()方法中,會先創建SingleProducerSequencer,然後再基於這個SingleProducerSequencer創建RingBuffer,下面看一下RingBuffer的構造方法。
RingBuffer(
EventFactory<E> eventFactory,
Sequencer sequencer) {
super(eventFactory, sequencer);
}繼續跟進RingBuffer父類RingBufferFields的構造方法,如下所示。
RingBufferFields(
EventFactory<E> eventFactory,
Sequencer sequencer) {
this.sequencer = sequencer;
this.bufferSize = sequencer.getBufferSize();
// 隊列容量不能小於等於0
if (bufferSize < 1) {
throw new IllegalArgumentException("bufferSize must not be less than 1");
}
// 隊列容量需要為2的冪次方,方便進行模運算
if (Integer.bitCount(bufferSize) != 1) {
throw new IllegalArgumentException("bufferSize must be a power of 2");
}
this.indexMask = bufferSize - 1;
// 初始化元素數組,空間多了BUFFER_PAD * 2
// 這是為了避免數組的首和尾的有效元素和其它無關數據加載到同一個緩存行從而出現偽共享
this.entries = new Object[sequencer.getBufferSize() + 2 * BUFFER_PAD];
// 預先將元素數組中的元素對象全部創建出來
fill(eventFactory);
}
private void fill(EventFactory<E> eventFactory) {
for (int i = 0; i < bufferSize; i++) {
entries[BUFFER_PAD + i] = eventFactory.newInstance();
}
}上述構造方法中,首先會對bufferSize進行校驗,這個bufferSize實際就是元素數組的大小,因為RingBuffer是一個環形存儲結構,存儲的元素放在元素數組中,所以每添加一個元素時,這個元素在數組中的下標索引的取值是這個元素的序號對bufferSize取模(元素的序號由Sequencer中的Sequence記錄,是一直增加的),那麼這裏的校驗規則就是bufferSize需要是大於等於1且滿足2的冪次方,之所以需要滿足2的冪次方,就是因為對滿足2的冪次方的bufferSize可以使用與上bufferSize - 1的方式來取模,這樣的方式取模更快,這和HashMap中的取模方式是一致的。
其次,可以注意到存儲元素的元素數組的實際大小為sequencer.getBufferSize() + 2 * BUFFER_PAD,這樣做的原因是要在元素數組的首和尾額外分別創建一個緩存行大小的填充空間,這樣就可以避免元素數組的有效元素與其它無關數據被加載到同一個緩存行從而出現偽共享的情況。
在上述構造方法的最後,還會將元素數組預熱,即提前將所有有效元素對象創建出來,這些元素對象會一直存在以達到複用的效果,可以有效的解決頻繁對元素對象GC的問題。
三. 消費者消費邏輯
本篇文章的示例中,在創建出Disruptor對象後,此時會調用Disruptor的handleEventsWith()方法來註冊事件處理器,同時每個事件處理器會對應創建一個消費者,下面看一下handleEventsWith()方法的實現,如下所示。
public final EventHandlerGroup<T> handleEventsWith(final EventHandler<? super T>... handlers) {
return createEventProcessors(new Sequence[0], handlers);
}
EventHandlerGroup<T> createEventProcessors(
final Sequence[] barrierSequences,
final EventHandler<? super T>[] eventHandlers) {
checkNotStarted();
final Sequence[] processorSequences = new Sequence[eventHandlers.length];
// 通過RingBuffer創建SequenceBarrier
final SequenceBarrier barrier = ringBuffer.newBarrier(barrierSequences);
// 遍歷每個事件處理器
for (int i = 0, eventHandlersLength = eventHandlers.length; i < eventHandlersLength; i++) {
final EventHandler<? super T> eventHandler = eventHandlers[i];
// 創建消費者,注意這裏傳入了SequenceBarrier
final BatchEventProcessor<T> batchEventProcessor =
new BatchEventProcessor<>(ringBuffer, barrier, eventHandler);
if (exceptionHandler != null) {
batchEventProcessor.setExceptionHandler(exceptionHandler);
}
// 將消費者相關對象添加到consumerRepository中
consumerRepository.add(batchEventProcessor, eventHandler, barrier);
// 每個消費者都持有一個Sequence對象
// 這裏將消費者的Sequence對象添加到processorSequences數組中
processorSequences[i] = batchEventProcessor.getSequence();
}
updateGatingSequencesForNextInChain(barrierSequences, processorSequences);
// 創建EventHandlerGroup並返回
return new EventHandlerGroup<>(this, consumerRepository, processorSequences);
}在上述的handleEventsWith()方法中會調用到createEventProcessors()方法,createEventProcessors()方法中做的第一件關鍵事情就是創建SequenceBarrier對象,這個SequenceBarrier會被這一批創建出來的消費者共同持有,用於消費者來判斷當前是否可以消費元素數據。createEventProcessors()方法做的第二件事情就是遍歷這一批的所有事件處理器(即傳入的所有EventHandler),基於每個事件處理器都會創建一個消費者BatchEventProcessor對象,同時每個BatchEventProcessor對象的相關信息都會添加到Disruptor的consumerRepository字段中,consumerRepository字段是一個ConsumerRepository對象,其類圖如下所示。
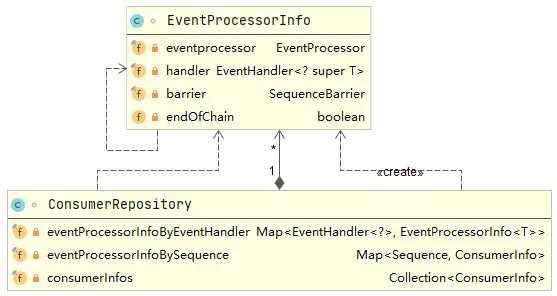
主要目的就是用於Disruptor持有消費者的引用。
上面分析完了消費者的創建,繼續往下分析前,先看一下本示例中的消費者BatchEventProcessor的類圖。
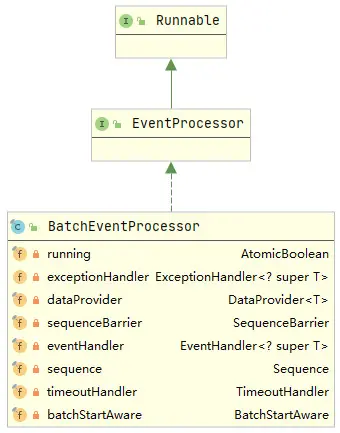
首先應該知道BatchEventProcessor實現了Runnable接口,那麼每個消費者都應該由Disruptor將其放入一個線程中運行起來,其次每個BatchEventProcessor都持有一個SequenceBarrier對象,一個EventHandler對象以及一個Sequence對象,這三個對象在消費者消費元素數據的過程中都會發揮重要作用,簡要來説,SequenceBarrier對象會將消費者與生產者關聯起來,EventHandler對象會實際的處理消費到的元素,Sequence會記錄消費者消費到了哪裏。
本篇文章的示例中,Disruptor創建完並且向Disruptor註冊完EventHandler後,接下來就是調用Disruptor的start()方法將整個隊列啓動起來,下面看一下Disruptor的start()方法,如下所示。
public RingBuffer<T> start() {
checkOnlyStartedOnce();
// 遍歷每一個消費者對應的ConsumerInfo,並調用其start()方法
for (final ConsumerInfo consumerInfo : consumerRepository) {
consumerInfo.start(executor);
}
return ringBuffer;
}前面提到過Disruptor通過一個ConsumerRepository對象持有消費者的相關信息,這裏Disruptor通過ConsumerRepository遍歷每一個消費者對應的ConsumerInfo並調用其start()方法,本示例中的ConsumerInfo實際類型為EventProcessorInfo,下面看一下其start()方法的實現,如下所示。
public void start(final Executor executor) {
executor.execute(eventprocessor);
}實際就是將每個消費者作為Runnable扔進線程池中,那麼消費者的啓動以及如何工作的邏輯,肯定就在消費者BatchEventProcessor的run()方法中,如下所示。
public void run() {
if (!running.compareAndSet(false, true)) {
throw new IllegalStateException("Thread is already running");
}
sequenceBarrier.clearAlert();
notifyStart();
T event = null;
// 消費者的初始序號是-1,而-1是消費不到數據的
// 所以消費者消費的第一個元素序號是初始序號+1,即序號0
long nextSequence = sequence.get() + 1L;
try {
while (true) {
try {
// 調用SequenceBarrier的waitFor()方法獲取當前實際可以消費到的元素的最大序號
final long availableSequence = sequenceBarrier.waitFor(nextSequence);
if (batchStartAware != null) {
batchStartAware.onBatchStart(availableSequence - nextSequence + 1);
}
// 循環的消費元素,直到消費完序號為availableSequence的元素
while (nextSequence <= availableSequence) {
event = dataProvider.get(nextSequence);
// 每消費一個元素,就將該元素交由事件處理器來處理
eventHandler.onEvent(event, nextSequence, nextSequence == availableSequence);
nextSequence++;
}
// 更新當前消費者的消費進度,即將當前消費者的序號設置為最後一次消費的元素的序號
sequence.set(availableSequence);
} catch (final TimeoutException e) {
notifyTimeout(sequence.get());
} catch (final AlertException ex) {
if (!running.get()) {
break;
}
} catch (final Throwable ex) {
exceptionHandler.handleEventException(ex, nextSequence, event);
sequence.set(nextSequence);
nextSequence++;
}
}
} finally {
notifyShutdown();
running.set(false);
}
}單看BatchEventProcessor的run()方法的邏輯其實很簡單,就是循環的獲取當前可以消費的元素的最大序號,只要獲取到可以消費的元素的最大序號,就依次消費直到消費到這個最大序號下的元素,每消費到一個元素就將這個元素傳入當前消費者持有的事件處理器進行處理,也就是調用EventHandler的onEvent()方法來處理消費到的元素。那麼問題就來了,因為RingBuffer是一個環形的結構,生產者生產數據填充元素的時候,如果RingBuffer滿了,且不加以同步控制,那麼會按照後添加的數據覆蓋先添加的數據來處理,所以當消費者在獲取到了一個可以消費的元素的最大序號後,就可能會出現生產者新生產的數據覆蓋掉當前消費者還未消費的數據的情況,所以肯定是需要進行同步控制的,這個同步控制在消費者和生產者都有相應的實現,本小節主要分析消費者的同步控制,主要邏輯在SequenceBarrier的waitFor()方法中,要分析SequenceBarrier的waitFor()方法,需要先分析SequenceBarrier的創建,其創建的時機在上面已經有提及,就是在Disruptor的createEventProcessors()方法中,相關的代碼片段如下所示。
// 本示例中的barrierSequences是一個空數組
final SequenceBarrier barrier = ringBuffer.newBarrier(barrierSequences);所以SequenceBarrier就是在註冊事件監聽器的時候,通過RingBuffer的newBarrier()方法創建出來的,下面看一下newBarrier()方法的實現,如下所示。
public SequenceBarrier newBarrier(Sequence... sequencesToTrack) {
return sequencer.newBarrier(sequencesToTrack);
}本篇文章中討論的Sequencer實際均為SingleProducerSequencer,所以繼續跟進SingleProducerSequencer的newBarrier()方法,如下所示。
public SequenceBarrier newBarrier(Sequence... sequencesToTrack) {
// 這裏的waitStrategy在本示例中為YieldingWaitStrategy
// cursor為Sequencer持有的一個Sequence
return new ProcessingSequenceBarrier(this, waitStrategy, cursor, sequencesToTrack);
}上述方法中調用了ProcessingSequenceBarrier的構造方法,並且傳入的cursor參數為Sequencer持有的用於記錄生產者發佈了的元素的序號的Sequence。繼續跟進ProcessingSequenceBarrier的構造方法,如下所示。
ProcessingSequenceBarrier(
final Sequencer sequencer,
final WaitStrategy waitStrategy,
final Sequence cursorSequence,
final Sequence[] dependentSequences) {
// SequenceBarrier持有Sequencer的引用
this.sequencer = sequencer;
// SequenceBarrier持有一個等待策略,決定消費者在等待可消費元素時的策略
this.waitStrategy = waitStrategy;
// SequenceBarrier持有生產者最新發布元素的序號
this.cursorSequence = cursorSequence;
// 本示例中滿足0 == dependentSequences.length
// 所以dependentSequence取為cursorSequence
if (0 == dependentSequences.length) {
dependentSequence = cursorSequence;
} else {
dependentSequence = new FixedSequenceGroup(dependentSequences);
}
}通過上面的構造方法可知,ProcessingSequenceBarrier持有Sequencer的引用,持有一個等待策略WaitStrategy,持有兩個Sequence,在本篇文章示例中兩個Sequence是完全相同的,均為生產者最新發布元素的序號,ProcessingSequenceBarrier的類圖如下所示。

下面開始分析消費者獲取當前實際可以消費到的元素的最大序號的實現,即SequenceBarrier也就是ProcessingSequenceBarrier的waitFor()方法,如下所示。
public long waitFor(final long sequence)
throws AlertException, InterruptedException, TimeoutException {
checkAlert();
// 調用等待策略的waitFor()方法得到一個可用序號
long availableSequence = waitStrategy.waitFor(sequence, cursorSequence, dependentSequence, this);
// 如果可用序號小於目標序號,則直接返回可用序號
// 説明當前最多隻能消費到可用序號的元素
if (availableSequence < sequence) {
return availableSequence;
}
// 如果可用序號大於等於目標序號,則調用Sequencer來得到當前最大的已發佈的序號
// 本示例中這裏的Sequencer實際為SingleProducerSequencer
// SingleProducerSequencer的策略就是直接返回可用序號
return sequencer.getHighestPublishedSequence(sequence, availableSequence);
}
// SingleProducerSequencer#getHighestPublishedSequence
public long getHighestPublishedSequence(long lowerBound, long availableSequence) {
return availableSequence;
}在ProcessingSequenceBarrier的waitFor()方法中,先通過等待策略拿到一個可用序號availableSequence,然後判斷可用序號與目標序號sequence(這裏目標序號就是消費者想要消費到的序號)的大小關係,如果可用序號小於目標序號,表明當前消費者想要消費到的數據還沒有被生產者生產(未發佈),此時直接返回可用序號,如果可用序號大於等於目標序號,則調用Sequencer來得到當前最大的已發佈的序號,本示例中的Sequencer實際為SingleProducerSequencer,而SingleProducerSequencer的策略就是將可用序號返回,即當出現當前生產者發佈的元素已經多於消費者想要消費的元素時,允許消費者消費到最新發布的元素。
下面再繼續跟進等待策略是如何獲取可用序號的,本示例中的等待策略為YieldingWaitStrategy,YieldingWaitStrategy的waitFor()方法如下所示。
public long waitFor(
final long sequence, Sequence cursor, final Sequence dependentSequence, final SequenceBarrier barrier)
throws AlertException, InterruptedException {
long availableSequence;
// SPIN_TRIES = 100
int counter = SPIN_TRIES;
// 通過dependentSequence來拿到可用序號
// 這裏的dependentSequence就是生產者最新發布的元素的序號
// 循環的獲取生產者最新發布的元素序號直到最新發布的元素序號大於等於目標序號為止
// 前100次循環不放棄時間片,從第101次開始,每次循環需要放棄時間片
while ((availableSequence = dependentSequence.get()) < sequence) {
counter = applyWaitMethod(barrier, counter);
}
// 返回時可用序號一定是大於等於目標序號的,否則就會一直在上面循環
return availableSequence;
}
private int applyWaitMethod(final SequenceBarrier barrier, int counter)
throws AlertException {
barrier.checkAlert();
if (0 == counter) {
Thread.yield();
} else {
--counter;
}
return counter;
}YieldingWaitStrategy的waitFor()方法就是循環的判斷生產者當前最新發布的元素序號是否大於等於消費者的目標序號,如果滿足就返回這個最新發布的元素序號作為可用序號,如果不滿足就一直循環的判斷直到滿足為止,並且前100次循環不放棄時間片,從第101次開始,每次循環都需要放棄時間片。
至此消費者的消費邏輯分析完畢。
四. 生產者生產邏輯
在本篇文章示例中,自定義了一個生產者叫做TestEventProducer,再貼出其實現如下。
public class TestEventProducer {
private final RingBuffer<TestEvent> ringBuffer;
public TestEventProducer(RingBuffer<TestEvent> ringBuffer) {
this.ringBuffer = ringBuffer;
}
public void onData(String data) {
// 從RingBuffer中申請空間
// 元素數組sequence位置的元素是可用的
// 可用的意思就是可以生產數據到這個元素上併發布
long sequence = ringBuffer.next();
try {
// 從元素數組中將sequence位置的元素獲取出來
TestEvent testEvent = ringBuffer.get(sequence);
// 將生產的data數據設置到sequence位置的元素中
testEvent.setId(data);
} finally {
// 發佈元素
// 也就是消費者可以消費了
// 不發佈消費者就不能消費
ringBuffer.publish(sequence);
}
}
}如上所示,Disruptor的生產者生產元素的步驟可以概括如下。
- 從
RingBuffer中申請空間,即獲取到一個可以設置數據的元素的序號; - 根據步驟1中獲取到的索引將可以設置數據的元素從數組中獲取出來;
- 為步驟2中獲取出來的元素設置數據;
- 發佈步驟3中的元素,即這個元素允許被消費者消費了。
所以,關鍵步驟就是生產者如何申請空間,下面來分析一下RingBuffer的next()方法,如下所示。
public long next() {
return sequencer.next();
}可知RingBuffer的next()方法會調用到其持有的Sequencer的next()方法,本示例中這裏的Sequencer為SingleProducerSequencer,其next()方法如下所示。
public long next() {
return next(1);
}
public long next(int n) {
if (n < 1) {
throw new IllegalArgumentException("n must be > 0");
}
// nextValue初始值是-1
// nextValue可以理解為最近一次寫入的元素的序號
long nextValue = this.nextValue;
// nextSequence為本次申請的元素的序號
long nextSequence = nextValue + n;
// wrapPoint表示生產者可能追尾消費最慢的消費者的點
long wrapPoint = nextSequence - bufferSize;
// cachedGatingSequence表示上一次緩存的最慢消費者消費到的元素序號
// cachedValue初始值是-1
long cachedGatingSequence = this.cachedValue;
// 當wrapPoint大於cachedGatingSequence時,表示發生追尾
// 此時需要獲取最新的最慢消費者的消費進度
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > nextValue) {
// 調用UNSAFE的putLongVolatile()方法,對cursor插入StoreLoad屏障,讓cursor的值對消費者可見
// 這樣做的目的是讓消費者及時見到cursor的值並消費發佈的元素數據,因為下面會重新獲取最慢消費者的消費進度
// 這裏的cursor表示生產者最近一次發佈的元素的序號
cursor.setVolatile(nextValue);
long minSequence;
// 先重新拿一次最慢消費者的消費進度,並判斷是否還會追尾
// 如果還是會追尾,那麼就睡眠1納秒後再重複上面的判斷步驟,直到不追尾為止
while (wrapPoint > (minSequence = Util.getMinimumSequence(gatingSequences, nextValue))) {
LockSupport.parkNanos(1L);
}
this.cachedValue = minSequence;
}
// 先將nextSequence更新給nextValue
this.nextValue = nextSequence;
// 返回nextSequence,生產者會生產數據填充到nextSequence對應的元素中
// 最後會發布元素,即將nextSequence賦值給cursor,所以cursor的更新晚於nextValue
return nextSequence;
}在上述SingleProducerSequencer的next()方法中,有五個重要變量,這裏先給出其含義,如下所示。
- nextValue表示最近一次寫入的元素的序號;
- nextSequence表示本次想要申請寫入的元素的序號;
- cursor表示最近一次發佈的元素的序號,發佈了的元素才可以被消費者消費;
- wrapPoint表示生產者和消費者可能會追尾的點;
- cachedGatingSequence表示上一次緩存的最慢消費者消費的元素序號。
在SingleProducerSequencer的next()方法中,首先會將nextValue加n得到nextSequence,然後用nextSequence減去環形數組的大小bufferSize來得到可能會追尾的點wrapPoint,得到wrapPoint後,就會將wrapPoint與cachedGatingSequence比較大小,只要wrapPoint大於cachedGatingSequence,就會發生追尾,由於cachedGatingSequence是上一次緩存的最慢消費者的消費進度,那麼此時就需要等待最慢消費者去消費元素從而緩存最新的最慢進度,直到不發生追尾。
注意到在等待最慢消費者去消費元素前,還執行了一個cursor.setVolatile(nextValue)的操作,這是因為cursor在更新的時候,調用的是UNSAFE的putOrderedLong()方法來更新cursor的值,而UNSAFE的putOrderedLong()方法插入的屏障類型是StoreStore屏障,該屏障不能保證消費者能及時看見cursor的最新值,所以需要在等待最慢消費者消費元素前先調用UNSAFE的putLongVolatile()方法,對cursor插入StoreLoad屏障,讓cursor的值對消費者可見,確保消費者能儘快的消費到最新一次發佈的元素。
最後,當成功申請到要寫入元素的序號後,會先將nextSequence賦值給nextValue,但是實際記錄生產者發佈了的元素的cursor還沒更新,而在我們自定義的生產者TestEventProducer的最後有這麼一行代碼。
ringBuffer.publish(sequence);這裏的sequence就是上面申請到的nextSequence,那麼其實就是調用RingBuffer的publish()方法來發布元素,看一下其實現,如下所示。
public void publish(long sequence) {
// 更新cursor
cursor.set(sequence);
waitStrategy.signalAllWhenBlocking();
}至此,生產者的生產邏輯也分析完畢。
現在對Disruptor中的生產者和消費者進行一個簡單小節。
- 對於消費者來説(這裏僅針對
BatchEventProcessor),消費者會循環的通過SequenceBarrier來拿到當前最大可以消費的序號並消費,如果拿不到則根據傳入的等待策略waitStrategy進行等待,那實際上就是消費者會通過SequenceBarrier來拿到生產者當前已經發布的元素的序號cursor,從而得到最大可以消費的序號,所以消費者是通過SequenceBarrier來完成與生產者的關聯。 - 對於生產者來説,生產數據前需要先申請空間,也就是申請可用的元素的序號並通過可用元素的序號將可用元素獲取出來,然後生產數據填充可用元素併發布這個元素,這是一個兩階段提交,第一階段是申請可用元素序號,會基於所有消費者的Sequence(也就是消費者當前消費到了的元素的序號)得到最慢消費者的消費進度,從而判斷申請的序號是否會導致發生追尾,如果會發生追尾,則等待最慢消費者消費,直到不發生追尾為止,如果不會發生追尾,那麼就成功申請到可用元素序號,第二階段是生產數據填充可用元素,然後發佈這個序號,此時會更新生產者的cursor,此時消費者就能去消費新發布的元素。
最後以圖例的方式,對消費者和生產者的一個工作模式進行説明。
消費者消費數據
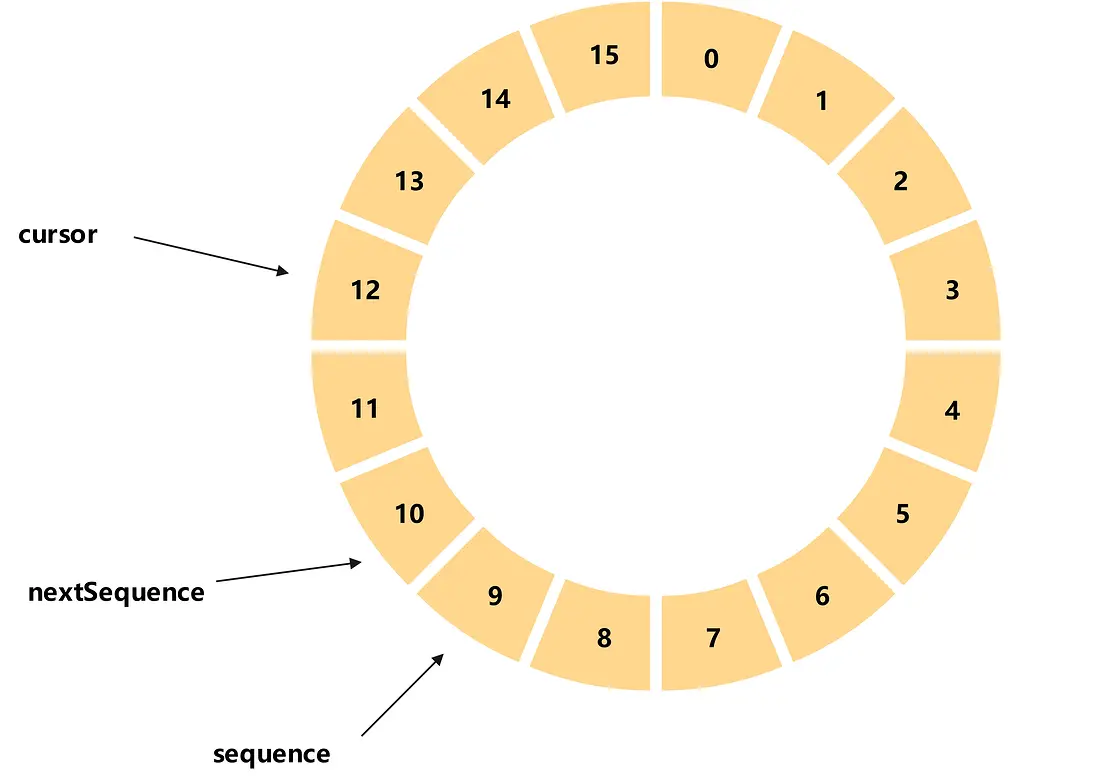
如圖,當前消費者消費到的元素的序號為9(sequence),那麼本次消費的目標序號就是10(nextSequence),由於生產者已經發布的元素的序號為12(cursor),所以消費者本次能夠一直消費到序號為12的元素。
生產者生產數據-不發生追尾
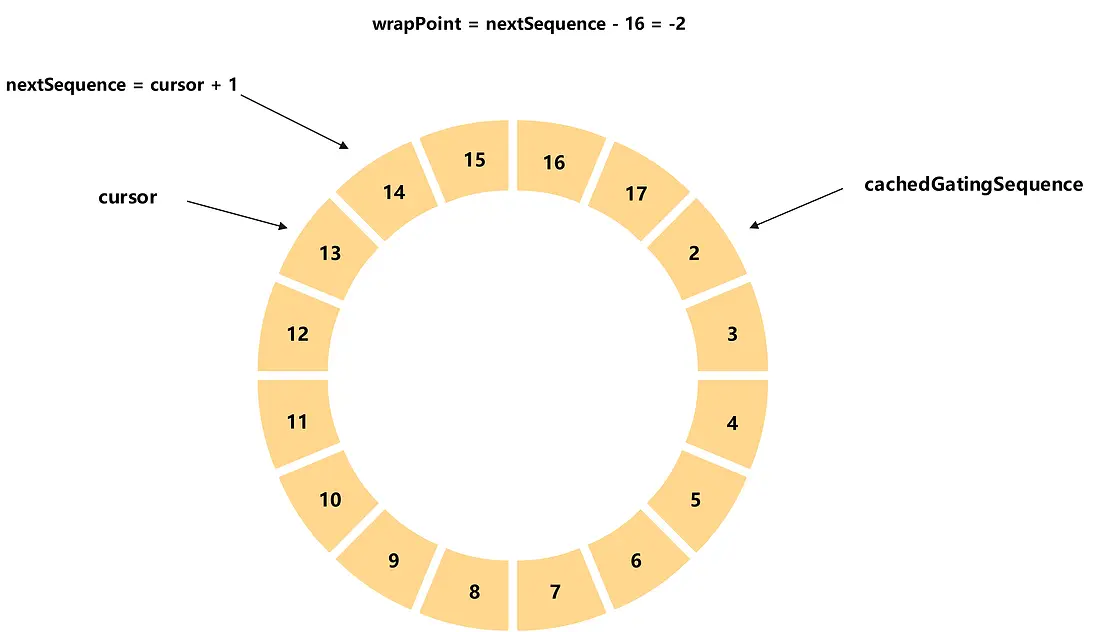
如圖,生產者當前已經發布的元素的序號為13(cursor),那麼本次申請的序號為14(nextSequence),由於環形數組大小為16(bufferSize),所以追尾點為-2(wrapPoint),同時最慢消費者的消費進度為2(cachedGatingSequence),所以不會發生追尾。
生產者生產數據-發生追尾
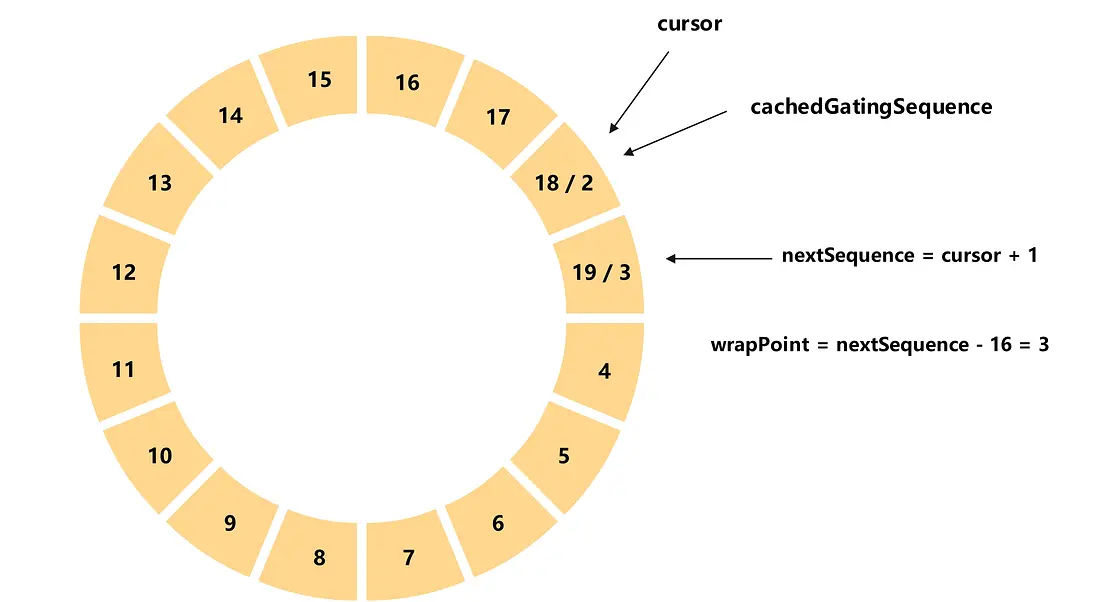
如圖,生產者當前已經發布的元素序號為18(cursor),那麼本次申請的序號為19(nextSequence),由於環形數組大小為16(bufferSize),所以追尾點為3(wrapPoint),同時最慢消費者的消費進度為2(cachedGatingSequence),所以會發生追尾(wrapPoint > cachedGatingSequence)。
總結
本篇文章初步對Disruptor的工作原理進行了分析,並結合一個單生產者示例,深入源碼對消費者如何消費數據,生產者如何生產數據以及併發控制思想進行了學習。
最後給出如下總結,回答Disruptor為什麼快。
1. 合理利用數據填充,避免了偽共享發生
以Disruptor中使用頻次最高的組件Sequence進行舉例説明。Sequence的實現如下所示。
class LhsPadding {
protected long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding {
protected volatile long value;
}
class RhsPadding extends Value {
protected long p9, p10, p11, p12, p13, p14, p15;
}
public class Sequence extends RhsPadding {
......
}可知Sequence本質就是對一個volatile的長整型變量value的一層包裝,但是除了value之外,還分別在value的左右填充了8個長整型變量,因此value只會和從不更新的填充變量在一個緩存行上,避免了其它會更新的變量的更新操作導致value的緩存失效。這樣的一個空間換時間的操作,極大提升了對緩存的利用,使得高頻使用數據的讀取更加的高效。
2. 提前初始化元素對象並反覆利用
Disruptor存儲元素使用的是一個環形Object數組,在一開始就會將這個數組中的所有元素對象全部初始化出來,並且這些對象會反覆利用,避免了元素對象的頻繁創建和GC。
3. 兩階段提交和CAS操作替代鎖
無論是消費者消費數據,還是生產者生產數據,均沒有使用重量級鎖來進行併發控制,而是基於兩階段提交和CAS操作來實現了併發控制,減少了線程切換導致的性能開銷。
大家好,我是半夏之沫 😁😁 一名金融科技領域的JAVA系統研發😊😊
我希望將自己工作和學習中的經驗以最樸實,最嚴謹的方式分享給大家,共同進步👉💓👈
👉👉👉👉👉👉👉👉💓寫作不易,期待大家的關注和點贊💓👈👈👈👈👈👈👈👈
👉👉👉👉👉👉👉👉💓關注微信公眾號【技術探界】 💓👈👈👈👈👈👈👈👈
