

百度垂直搜索系統將搜索核心能力賦能阿拉丁(百度搜索特型結果)、垂直領域搜索、應用內搜索等場景,支撐了數百個檢索場景、百億級內容數據的檢索。隨着接入業務數量和數據量不斷增長,系統在海量數據管理與調度上遭遇新的挑戰,通過垂搜數據管理系統彈性調度優化實踐來滿足業務增長需求。
01 背景
1.1簡介
百度垂搜架構的召回引擎經過歷史架構演進確定了異構部署的架構模型,相較於同構部署在容量自動調整、數據按需存儲等方面更具效率與成本的優勢,同時在海量數據和海量檢索方面也實現了高可用和高性能。目前系統已承接80+業務,全機房部署了數百個檢索服務,數千個索引庫,共計數百億文檔收錄。隨着接入新業務數量的增加,以及存量業務的深入迭代,我們遇到了更加複雜多樣的場景,進而對系統提出更高的要求。本文主要介紹我們的系統在海量數據管理與調度上面臨的問題, 以及各項優化工作落地後在系統擴展性、穩定性等方面取得的效果。
1.2 當前數據管理架構存在的問題
此前我們的系統設計了彈性伸縮機制應對流量和數據量的上漲,冷熱分離機制實現了資源按需部署。隨着接入業務的增加,系統逐漸暴露出一些新的問題,主要體現在以下幾點:
- 元信息管理瓶頸。系統使用ETCD進行服務發現和心跳管理, 然而所有業務實例直連ETCD存在嚴重讀寫放大問題, 導致ETCD負載超發出現單點瓶頸, 限制集羣規模進一步增長。
- 依靠人工評估資源。新業務的接入或者一些大事件運營保障依賴人工估算所需資源,不僅耗費人力,而且不夠準確,估算過高,服務長期處於低負載會造成資源浪費,估算過低,服務容易過載,進而導致穩定性問題。
- 數據量增長瓶頸。 當前的架構可以在無需重新建庫的情況下原地擴分片,但是分片數只能倍數擴展,並且分片數量有限制,大庫場景容易觸發上限,進而導致數據量無法繼續增長。
02 檢索系統與數據管理系統架構
2.1 檢索系統架構概覽
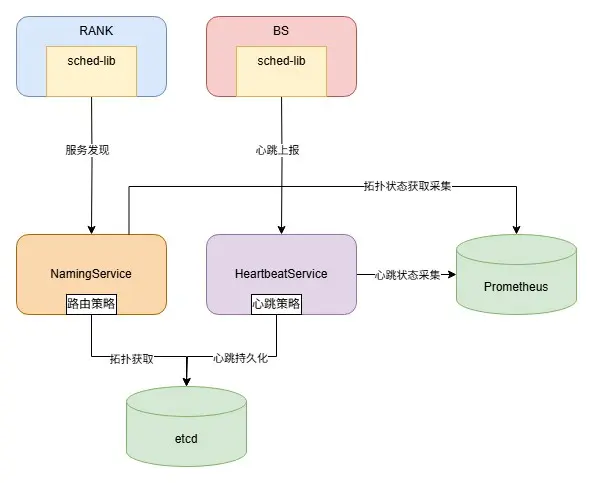
首先簡單介紹下垂搜檢索系統的各模塊,如下圖所示:
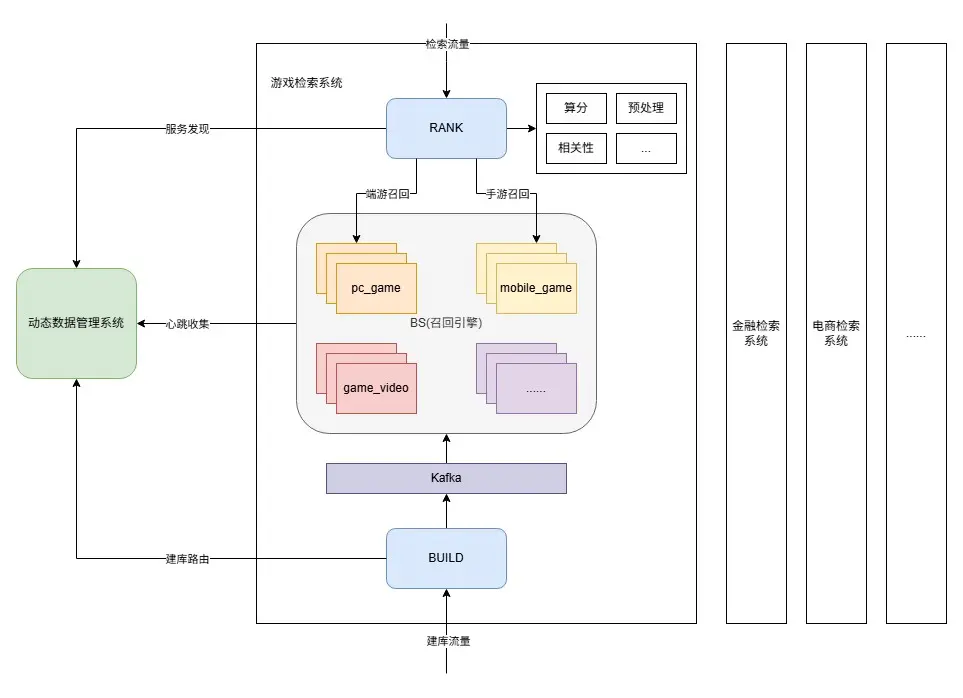
- RANK。檢索精排模塊,負責query理解、請求構造、多隊列拆分、正排數據獲取、策略因子計算、算分排序、返回結果組裝等流程。
- BS。檢索召回引擎,負責基礎召回/粗排,根據基礎相關性等權重因子進行數據的粗篩,支持基於term倒排拉鍊和ANN向量基礎召回。
- BUILD。數據建庫模塊,負責數據處理、切詞、生成正排/倒排/向量/摘要等功能。
每個垂類(業務)擁有一套獨立的上述檢索系統服務,數據管理系統為每個業務的檢索系統提供實例調度、容量管理、服務發現、心跳管理、路由控制等能力,數據管理系統面向的核心管理對象是召回引擎(BS)。
2.1.1 垂搜召回引擎
如下圖所示,百度垂搜的召回引擎是一個流式、多分片、異構、有狀態的倒排+向量索引引擎:
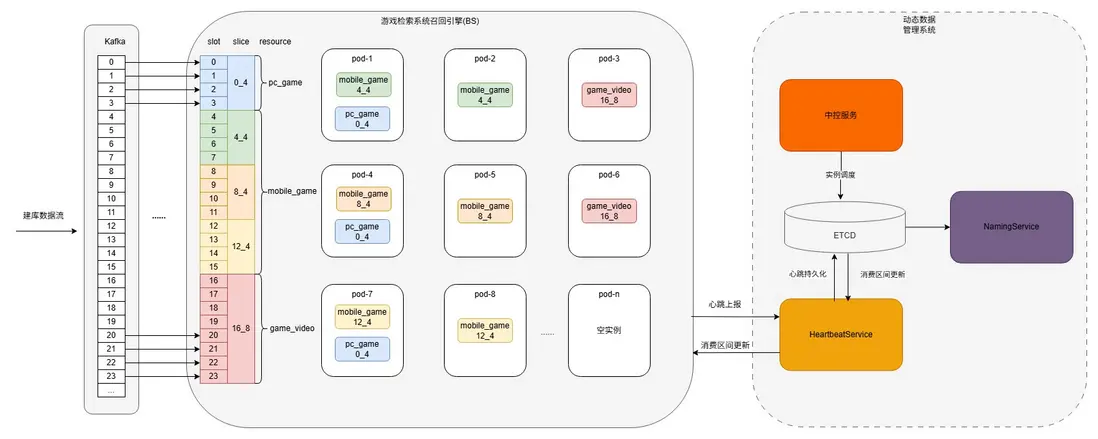
- 流式。業務經過離線建庫環節產出建庫包並生效到Kafka中,召回引擎再從Kafka消費,數據從建庫到檢索可實現秒級生效。
- 多分片。業務數據量超過單機存儲上限,會被拆分成多個分片(slice),每個分片由PaaS層面實例承載,並對應Kafka的一段partition區間。
- 異構。單個業務的若干個資源號(resource)之間支持獨佔或者混部,一般根據服務負載設置不同副本數,根據數據量設置不同分片數。
- 有狀態。每個實例承載一個或多個分片數據,週期性彙報心跳,消費分片由中控服務統一調度。
名詞解釋:
- resource(資源號): 一類或者一個場景的數據集合,即一個索引庫,一個業務通常包含多個資源號(如圖中mobile\_game,pc\_game, game_video等)。
- slice(分片):數據調度基本單位,一個resource根據數據量可能會拆分成多個slice(mobile\_game有三個slice, pc\_game和game_video1個)。
- slot:數據劃分的基本單位,一個slice下有若干個slot, 與Kafka的partition一一對應,在業務接入時根據數據量級確定。
pod:PaaS層面實際的物理存儲容器,一個pod會承載一個或多個slice,由中控服務統一調度。
2.2 動態化數據管理系統
動態化數據管理系統負責召回引擎的每個實例從建庫到檢索,從部署到下線的全生命週期管理。經過服務重構、架構升級、新功能建設等方面的優化工作,形成了包括中控服務,心跳服務(HeartbeatService), 名字服務(NamingService), 存儲ETCD等模塊的現有系統架構:
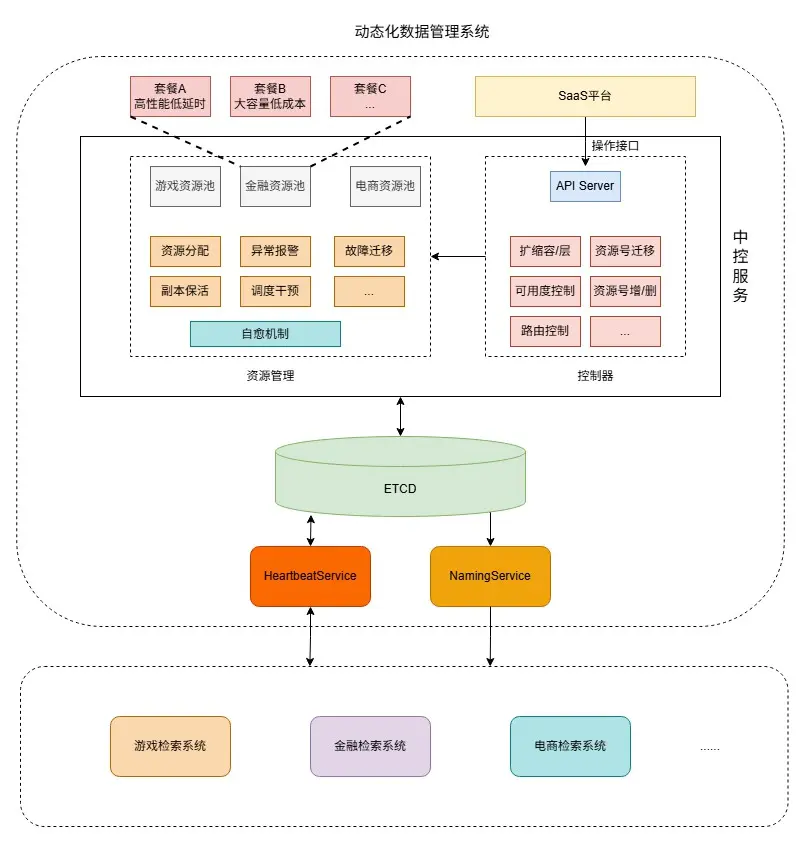
2.2.1 中控服務
整個動態化數據管理系統的核心模塊,負責各類調度任務的發起、控制等:
- 資源號接入/下線。新增資源號(索引庫),為每個資源號根據副本數、資源號之間部署關係等調度實例;下線資源號, 對應資源號的數據發起清理以及實例回收。
- 副本保活。每個資源號實際副本數可能由於擴縮副本或PaaS層面遷移,導致與目標副本數不一致,中控服務負責定期輪訓所有資源號(分片),維持副本數與目標一致。
- 容量管理。自動擴縮容服務/人工基於負載調整資源號的副本數,並通過副本保活生效,基於數據量調整資源號分片數,通過任務控制器生效。
- 可用度控制。上線重啓需要保證分片維度的可用度,變更由PaaS發起,每個實例重啓前需要請求中控服務的探針,中控服務根據當前分片可用度決定實例是否可以重啓。
2.2.2 名字服務NamingService
提供服務發現,實例屏蔽,建庫路由控制等能力:
- 服務發現。週期性加載並更新全量業務的資源號檢索路由拓撲信息,對每個分片過濾心跳丟失、未消費完成、重啓中等暫不可用實例。
- 實例屏蔽。支持異常實例的分片維度/App維度屏蔽,線上快速止損,並保留現場便於後續問題追查。
- 建庫路由控制。提供離線建庫側全量業務資源號與Kafka partition映射關係查詢,資源號倒排索引雙寫控制。
2.2.3 心跳服務HeartbeatService
負責召回引擎(BS)實例、分片心跳信息收集並持久化,實例消費區間信息傳遞等:
- 心跳管理。收集召回引擎實例上報的心跳信息,包括實例自身心跳以及消費分片信息, 並將心跳信息聚合後寫入ETCD。
- 實例調度信息傳遞。獲取由中控調度下發的最新消費分片信息,寫入心跳請求response,實例感知到消費分片發生變化後,清理舊分片數據,並重新消費新分片數據。
2.2.4 存儲ETCD
動態化數據管理系統各類元信息持久化存儲:
- 實例心跳信息。包括版本號,實例唯一標識,上報時間戳,消費分片等。
- 分片路由拓撲信息。分片下全量副本狀態信息,包括endpoint,snapshot版本,上報時間戳,消費狀態等。
- 業務資源號拓撲信息、建庫路由信息。單業務視角下全量資源號信息,包括版本號,分片數,副本數,對應Kafka partition區間,rpc參數配置等。
03 彈性調度機制優化實踐
3.1 服務發現、心跳管理模塊重構
3.1.1 原有架構
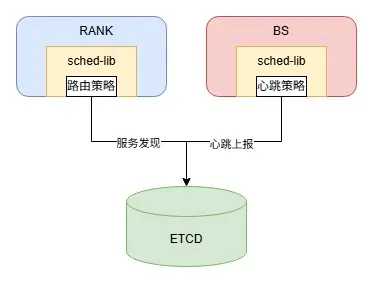
可以看到在原有架構,業務RANK和BS實例都是直連ETCD,隨着業務接入數量的增加逐漸暴露出一些問題:
- 讀流量放大。同業務的不同RANK實例會各自訪問ETCD獲取相同的路由拓撲,導致讀流量放大,對於RANK實例數多的業務放大現象愈發明顯。
- 寫流量放大。每個分片含有多個副本,在進行更新時,一輪週期內同一個分片會被寫入多次,導致寫流量放大,對於副本數多的分片寫競爭愈發激烈。
- 升級改造困難。路由篩選策略、心跳上報策略均內嵌在sched-lib中, 進行升級需要給每個業務RANK/BS上線,人力成本巨大。
為了解決上述問題,我們對心跳管理和服務發現模塊進行了微服務拆分,新增心跳服務(以下簡稱HS)和名字服務(以下簡稱NS)避免了業務實例直連ETCD,同時引入了Prometheus,對心跳上報狀態和路由獲取狀態等信息進行監控和可視化展示。
3.1.2 NS(NamingService)設計
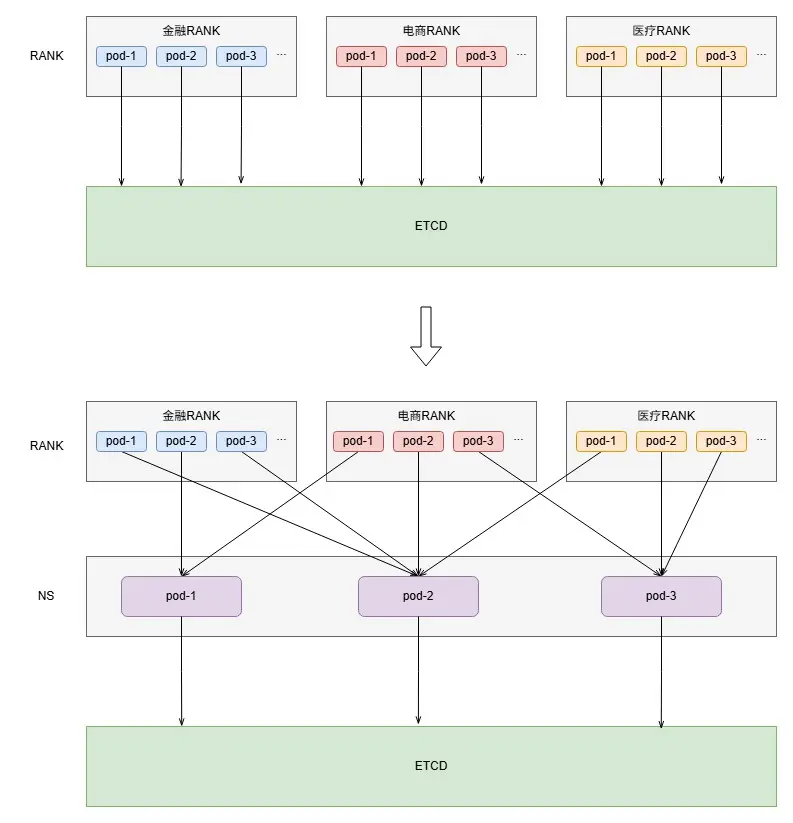
我們對NS的定位是作為ETCD的cache,採用Read-Through的模式,對全量業務的RANK提供拓撲信息查詢,RANK不再直接訪問ETCD:
- NS本身設計為一個無狀態服務, RANK可以訪問任意一台NS獲取拓撲,NS實例之間拓撲路由保證最終一致性,NS在拓撲變更時返回拓撲信息+MD5(拓撲)+更新時間戳,未變更時僅返回MD5和時間戳, RANK基於MD5和時間戳自行判斷是否需要更新。
- 拓撲更新策略下沉到NS中,RANK獲取到的拓撲即為直接可用拓撲,針對不同業務提供不同的控制策略並且後續升級改造只需上線NS,成本大幅降低。
單機房3台NS實例即可支撐全部業務拓撲查詢,重構前後ETCD讀流量比例為M:3,M為平均每個業務RANK實例數,假設N取30,則讀流量下降90%。
3.1.3 HS(HeartbeatService)設計
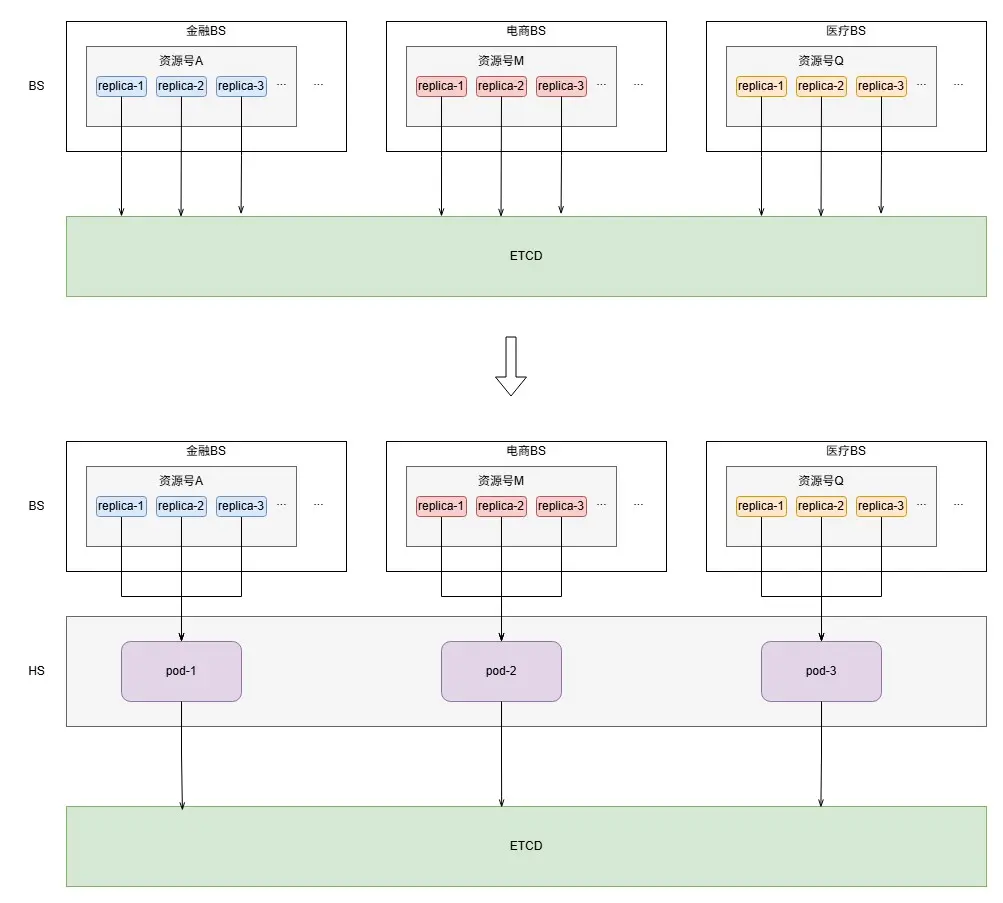
HS負責收集BS實例本身的心跳以及實例消費的分片的心跳,週期性聚合寫入ETCD,並且向BS實例返回其最新的消費分片信息:
- HS採用無主節點設計,也支持任意水平擴展。同一個業務的不同BS實例通過一致性hash方式請求同一台HS實例, 便於HS進行分片維度的信息聚合,這樣在大部分時間,每個分片無論有多少個副本一個週期內只會被寫入一次,實例本身的心跳採用批量更新形式,寫競爭大幅降低。
- BS在上報心跳的同時會從HS的response中獲取自身消費的最新分片信息,如果分片信息變化,則清理老分片數據,消費新分片數據,後續只上報新分片狀態信息。
單機房3台NS實例即可支撐全部業務心跳更新,重構前後ETCD寫流量比例為N:1,N為平均每個分片副本數,假設N取5,則寫流量下降80%。
3.2 自動擴縮容
3.2.1 當前現狀
BS是一個多分片、異構服務,即每個App內通常部署了多個資源號,各業務App在PasS層面隔離部署,在資源利用率、擴縮容管理等方面我們遇到以下問題:
- 整體資源利用率低。全機房擁有上百個BS業務App、上千個資源號,PaaS層面的整體平均峯值CPU利用率低於平均水平,峯值CPU超過70%的資源號佔比不足20%。
- 依賴人工進行資源號副本數調整。一般上線前通過人工壓測評估放量後所需的資源然後進行申請,有時候通過壓測難以估算真實的資源,並且後續業務迭代或者流量變化也會引起資源使用的變化,如果負載超發,服務穩定性難以保障,如果負載太過空閒,也會造成資源浪費。
- 無法直接接入PaaS層面自動擴縮容能力。一方面PaaS無法感知每個App內資源號維度負載信息,另一方面每個實例承載分片信息只能由中控服務調度,因此無法直接服用PaaS層面自動擴縮容能力。

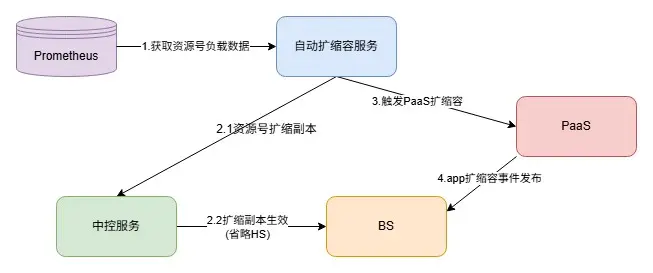
3.2.2 自動擴縮容實現
為了實現容量自適應調整,我們開發了一個自動擴縮容服務,對全量資源號進行容量管理。自動擴縮容服務週期性計算資源號維度負載,根據負載情況,觸發中控服務進行資源號副本數調整,或者PaaS層面實例數調整。對於擴容,優先調度存量資源池中實例,如果存量實例不足則觸發PaaS擴容;對於縮容,先將空閒副本數回收至空閒資源池,再觸發PaaS縮容。對於自動擴縮容服務的設計我們主要考慮了以下幾點:
負載指標選取
垂搜系統大部分業務BS為純內存版本,且幾乎沒有下游網絡請求,屬於典型的計算密集型業務, 因此我們選擇CPU作為負載計算參考指標,另外資源號混部場景進一步結合QPS和Latency進行判斷。此前我們已經實現了基於Prometheus採集實分片維度CPU、MEM、QPS、Latency、建庫數據量等指標全量業務覆蓋,因此可以低成本的獲取到全量資源號維度的負載數據。
負載狀態流轉
每個資源號從擴容到縮容,共定義如下7種狀態:
enum LoadStatus { LOAD_STATUS_LOAD_OK = 0; //正常負載 LOAD_STATUS_OVERLOAD = 1; //超負載 LOAD_STATUS_IDLELOAD = 2; //低負載 LOAD_STATUS_BS_ADD_REPLICA = 3; //bs 擴副本中 LOAD_STATUS_BS_REMOVE_REPLICA = 4; // bs 縮副本中 LOAD_STATUS_TRIGGER_PAAS_EXPENSION = 5; // PaaS 擴容中 LOAD_STATUS_TRIGGER_PAAS_SHRINK = 6; // PaaS 縮容中 }
每個資源號根據負載情況在上述狀態之間流轉:
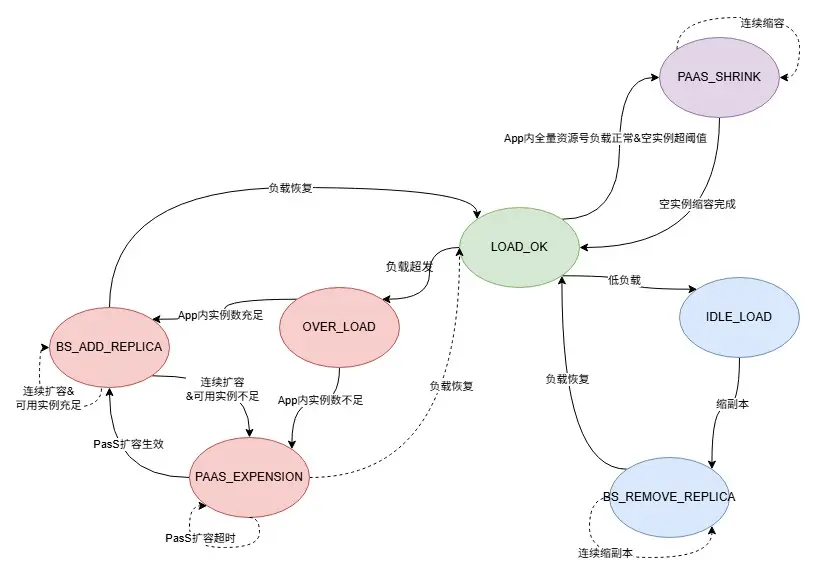
擴縮容執行流程
-
擴副本
- 優先調度App內空閒實例,不足則觸發PaaS層面實例數擴容,循環執行直到負載恢復正常。
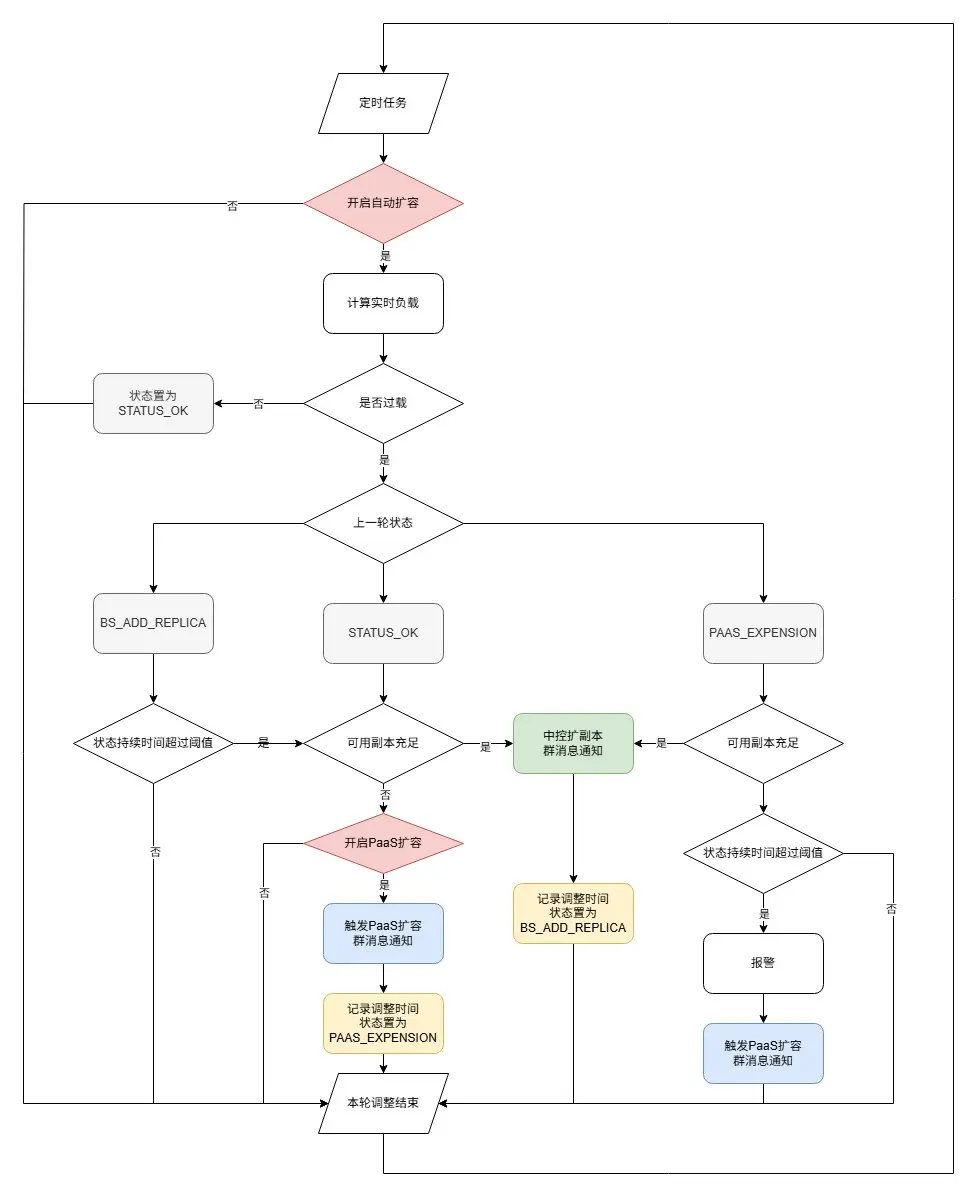
-
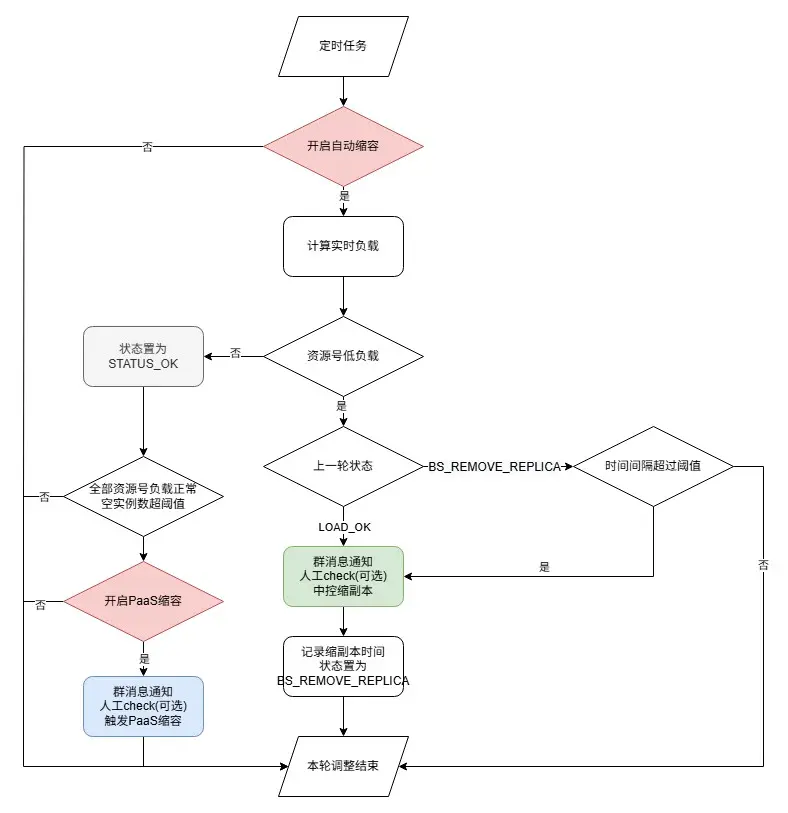
縮容
- 先將資源號多餘副本釋放為空閒實例,再觸發PaaS層面縮容,循環執行直到資源號負載以及空閒實例數回到正常水平。
3.3 資源號擴分片進階
每個資源號隨着數據量級不斷增長,分片數也需要動態擴展,否則會出現分片內存超發的情況。
3.3.1 當前擴分片方案
每個資源號按resource->slice->slot的層級劃分,slot 是數據劃分最小單位與kafka partion一一對應,在業務接入時每個資源號slot(partion)的數量已經確定。擴層時,資源號的slot數量不變,分片數變成原來2倍, 每個分片的slot數則為原來的1/2。

原有的擴分片方案可以在無需重新建庫的情況下實現業務無感的原地分片擴縮操作,然而依舊存在兩個問題:
- 分片數按指數增長,當分片數超過一定數值,將帶來不容忽視的資源成本。
- 如果初始分配slot數太少,當slice:slot=1:1時,無法再擴層,數據增長出現瓶頸。
3.3.2 進階擴展方案
對於分片無法繼續擴展但是依舊需要繼續建庫的情況,先前的方案只能是重建一個新的資源號,需要業務、架構共同介入,歷史上我們使用原方案遷移一個資源號,前後投入近3周時間,耗費成本巨大,因此我們需要一個成本更低的方案。通過分析,當前分片的擴展瓶頸主要有以下三個限制條件:
- 每個資源號的slots是一段連續的區間。
- BS的slot與Kafka的partition一一對應。
- 初始分配slot數太少,且後續不支持調整。
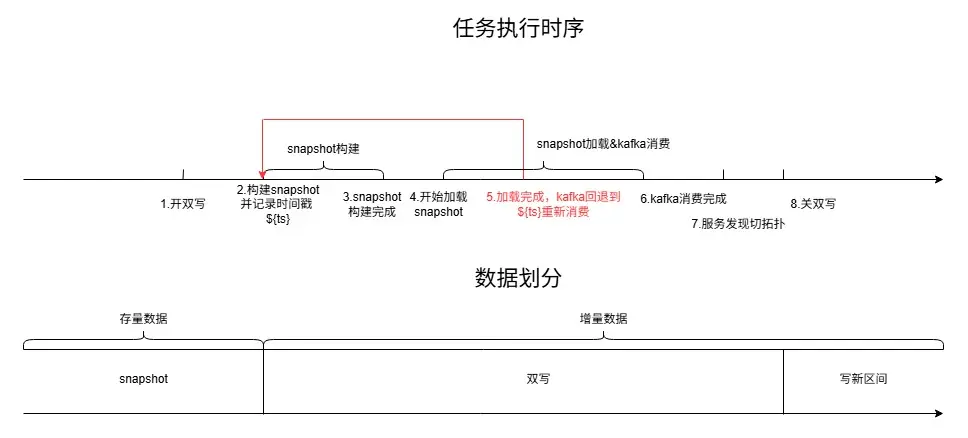
只需要打破其中任意一個條件,則可以消除瓶頸。綜合考慮改造成本、擴展靈活性、實現難度等因素,我們選擇從條件三入手,在新的partition區間重建分片,分片數和slot數根據數據量設置,將舊分片的數據全量複製到新的分片上,再將新分片替換舊分片,如下圖所示。
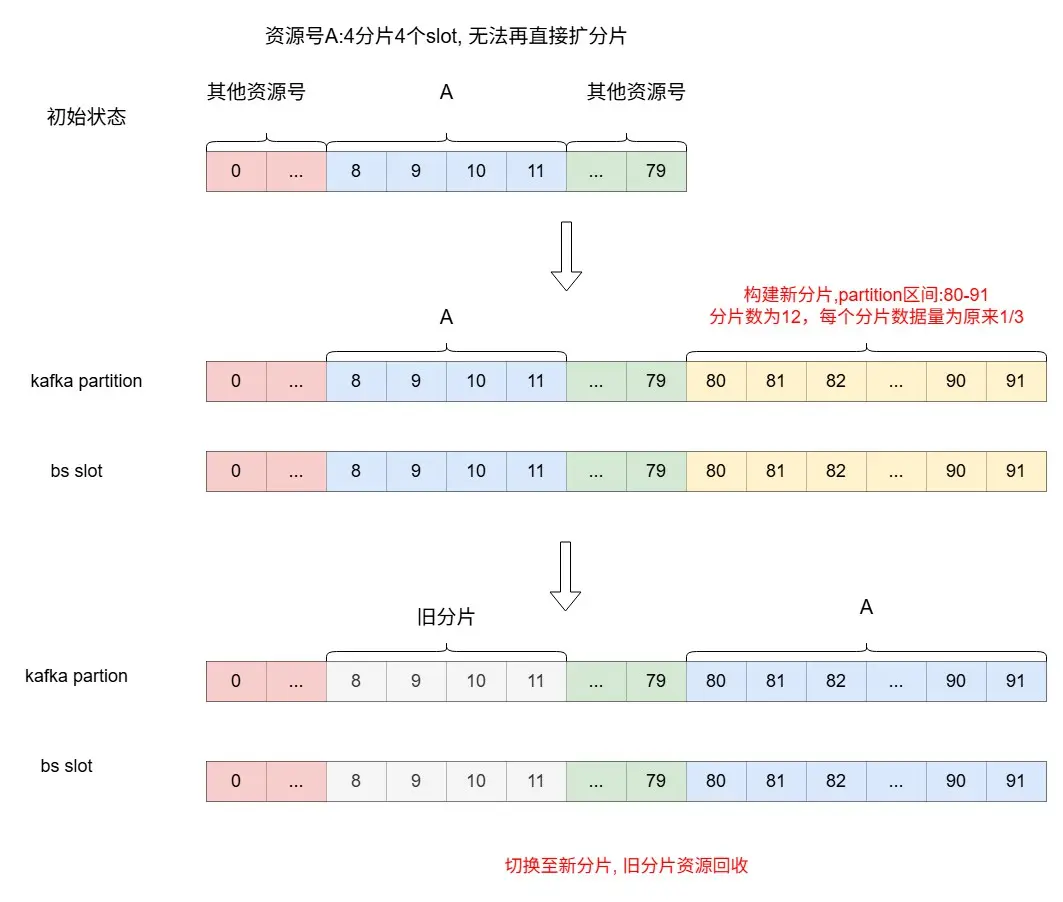
整體實現
對於一個流式建庫系統,業務可能時刻都在進行數據建庫,我們希望做到遷移過程中業務依舊可以持續建庫,並且保證數據不丟失、時序不錯亂。我們的方案是將數據分為存量數據(老分片中的全量數據)和增量數據(實時寫入的新數據),對於增量數據可以通過雙寫機制,同時寫入新舊分片,存量數據則通過構建snapshot的方法遷移至新分片,新分片數據ready後,再由服務發現層將檢索流量切換至新分片,整體流程如下:
- 離線側開啓雙寫,保證增量倒排索引數據同時寫入新舊分片,正排和摘要部分數據無需變化。
- 基於舊分片構建新分片snapshot, 並記錄構建時間點。將該時間點前舊分片所有數據進行resharding構建新分片snapshot。
- 新分片的BS實例加載構建好的snapshot,然後每個partition的消費offset回退到snapshot構建時間點開始重新消費。
- 服務發現層將資源號到slot區間映射切換到新分片上,檢索流量從老分片遷移至新分片。
- 將舊分片BS實例回收,並關閉雙寫。
04 總結與展望
4.1 總結
本文介紹了百度垂搜檢索數據管理架構在彈性機制建設上的一系列優化工作,並且在擴展性、穩定性、以及成本效率等方面均取得了預期成果:
-
擴展性
- ETCD負載下降一個量級,單機房BS、RANK集羣規模提升兩個量級, 單分片副本數上限提升至5000+。
- 分片擴展數量不再受限,解決了部分存量業務無法擴展分片導致的內存超發問題,並支持搜索創新業務數據量從百萬級逐步增加至數十億量級。
-
穩定性
- 存量調度問題被修復,新增多種路由調度策略以應對不同場景,分片可用度不足干預時間從小時級縮短至分鐘級。
- ETCD負載不再超發,慢查詢基本消失,穩定性風險基本消除,心跳上報、拓撲獲取狀態建立監控,異常情況及時感知。
-
成本效率
- 全機房BS接入自動擴縮容,實現容量自適應調整,整體峯值CPU利用率提升了15%+,同時相比之前減少了80%人工介入容量調整的情況出現。
- 部分業務通過分片合併,最終使用存儲資源為下降至原來的20%,並且檢索97分位耗時降低了20ms,業務側效果與先前打平。
4.2 展望
目前索引庫的自動擴縮容機制實現了副本數隨負載(CPU)的自動調整,後續將實現分片數隨數據量的自動調整。另外,在大庫場景將持續建設流批一體機制,以追求用更低的存儲成本實現更高的檢索性能。