









1 Redis 的簡介
Redis 實際上是簡稱,全稱為 Remote Dictionary Server (遠程字典服務器),由 Salvatore Sanfilippo 寫的高性能 key-value 存儲系統,其完全開源免費,遵守 BSD 協議。Redis 與其他 key-value 緩存產品(如 memcache)有以下幾個特點。
- 數據持久化:可以將內存中的數據保存在磁盤中,重啓的時候可以再次加載進行使用。
- 數據結構簡單豐富:既有簡單的 key-value 類型的數據,同時還提供 list,set,zset,hash 等數據結構的存儲。
- 高可用:支持主從、哨兵、集羣等模式,可以有效提高可用性。
Redis 也是一種 分佈式緩存,其代碼是 c 語言寫的,那我們該如何閲讀呢?
2 環境搭建
環境依賴,先看看 gcc 、cc、g++ 有沒有安裝
whereis gcc
whereis cc
whereis g++安裝gcc
xcode-select --install
brew install gcc
brew install pkg-config查看 gcc 的版本:
$ gcc --version
Apple clang version 14.0.0 (clang-1400.0.29.202)
Target: x86_64-apple-darwin22.1.0
Thread model: posix
InstalledDir: /Library/Developer/CommandLineTools/usr/bin我使用 CLion 2022.3.1 ,這個版本可以支持 Makefile 的項目,我們可以檢查一下環境是不是有問題, 如果有問題,這裏會有錯誤信息,我的之前報錯是因為 Clion 的版本版本太低了,升級之後就好了。
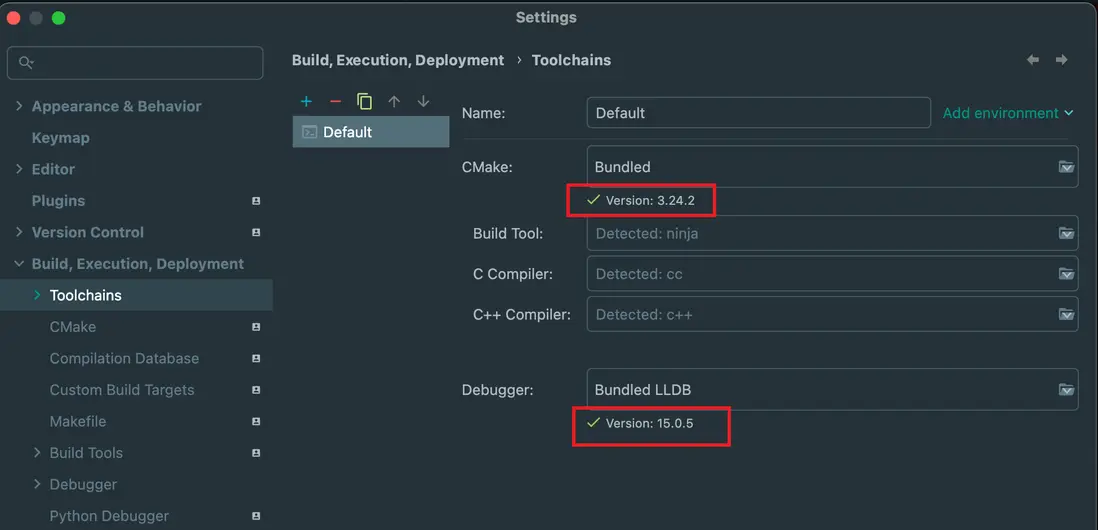
下載Redis源碼:
git clone https://github.com/redis/redis.git切換到指定的版本
git checkout 7.0File => New CMake Project from Sources, 打開源碼項目, 會自動生成根目錄下的 CMakeList.txt 文件:
Clion 導入項目的時候選擇已有的 MakeFile 文件,如果有是否 clean 項目,選擇 clean 即可,之後可以點開 MakeFile 文件:
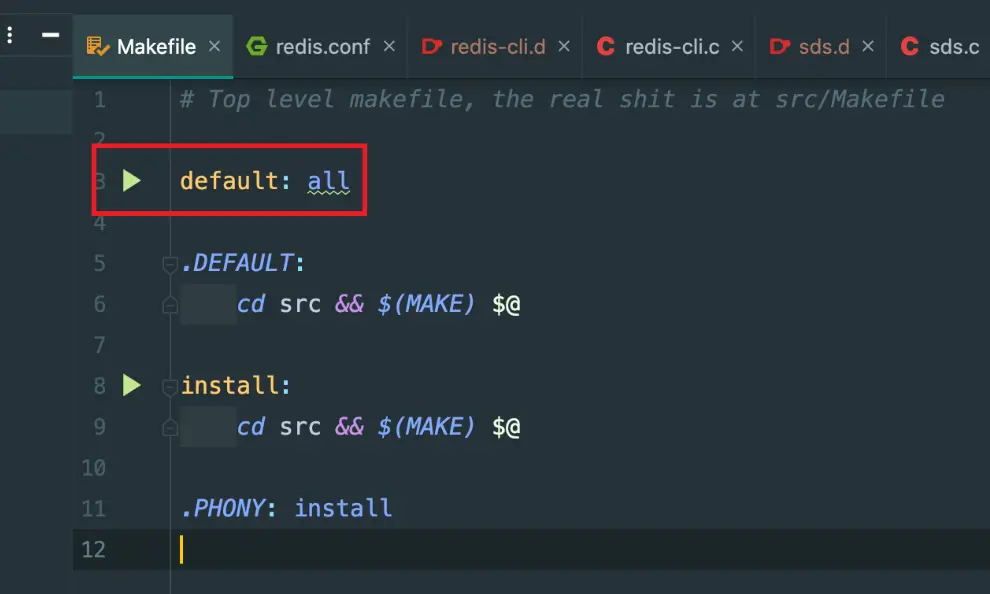
如果需要禁止編譯器優化,可以使用下面命令:
make CFLAGS="-g -O0" MALLOC=jemalloc運行完之後, Src 文件下就會出現可運行文件:
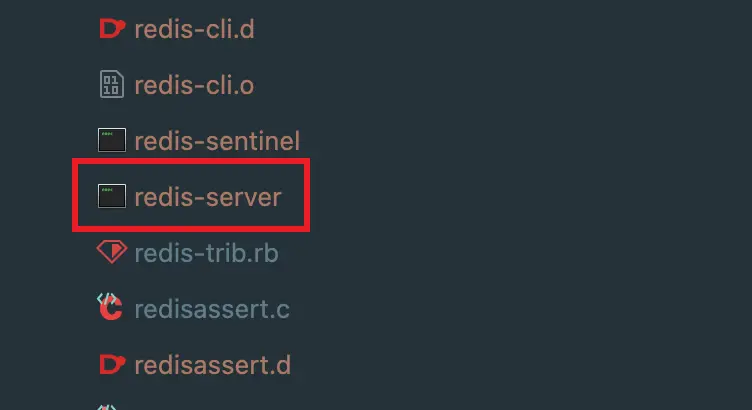
然後可以看到這些可運行的選項,繼而配置Edit configuration 運行配置:
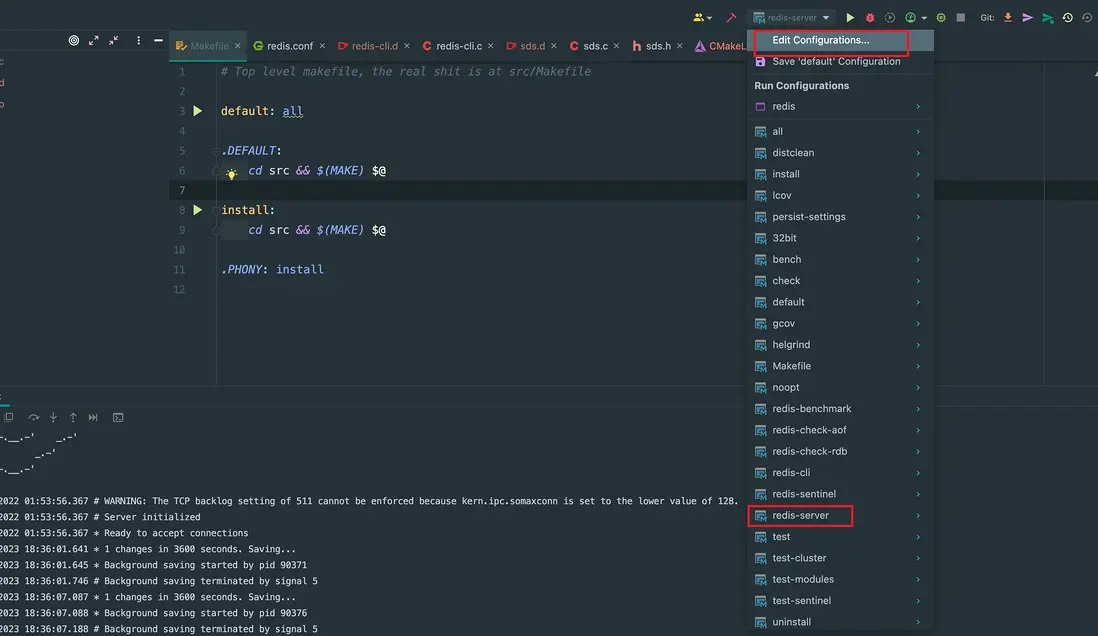
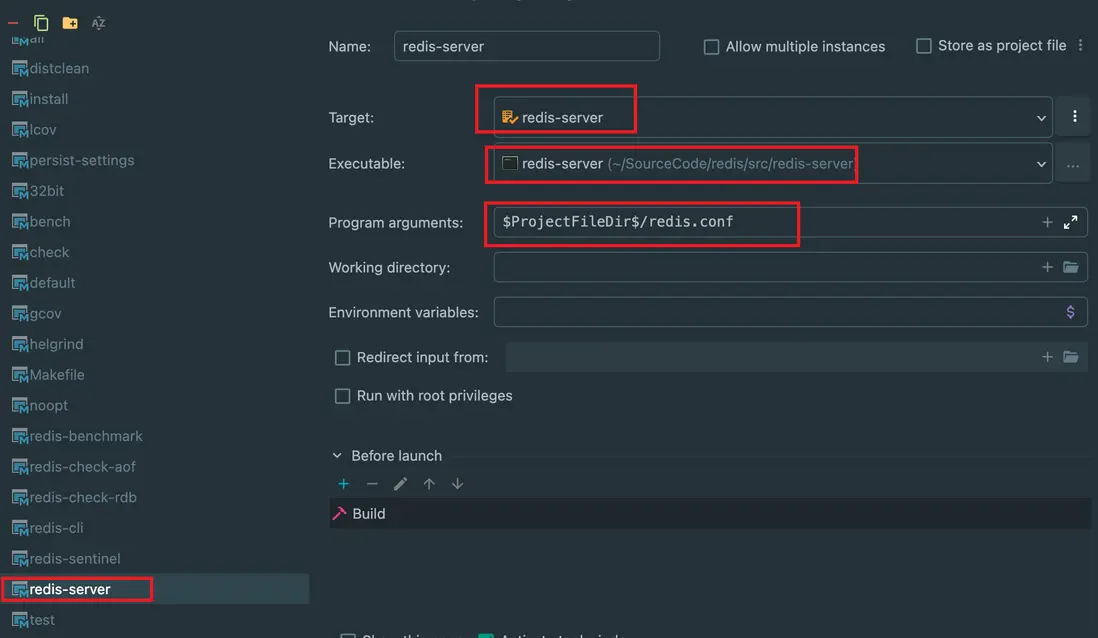
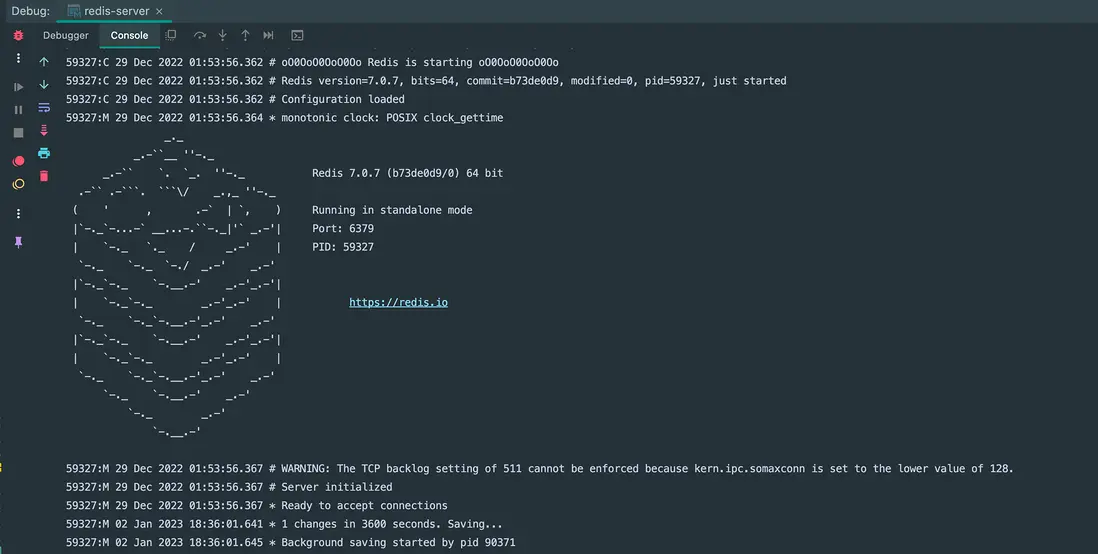
選擇 debug 進行啓動,啓動成功,然後可以進行調試了:
可以使用 Redis Desktop Manager 來進行連接:

或者命令行連接(沒有密碼就可以不需要 -a 12345):
redis-cli -h 127.0.0.1 -p 6379 -a 12345如果頭文件引入報紅色下劃線,那就試試重新加載一下
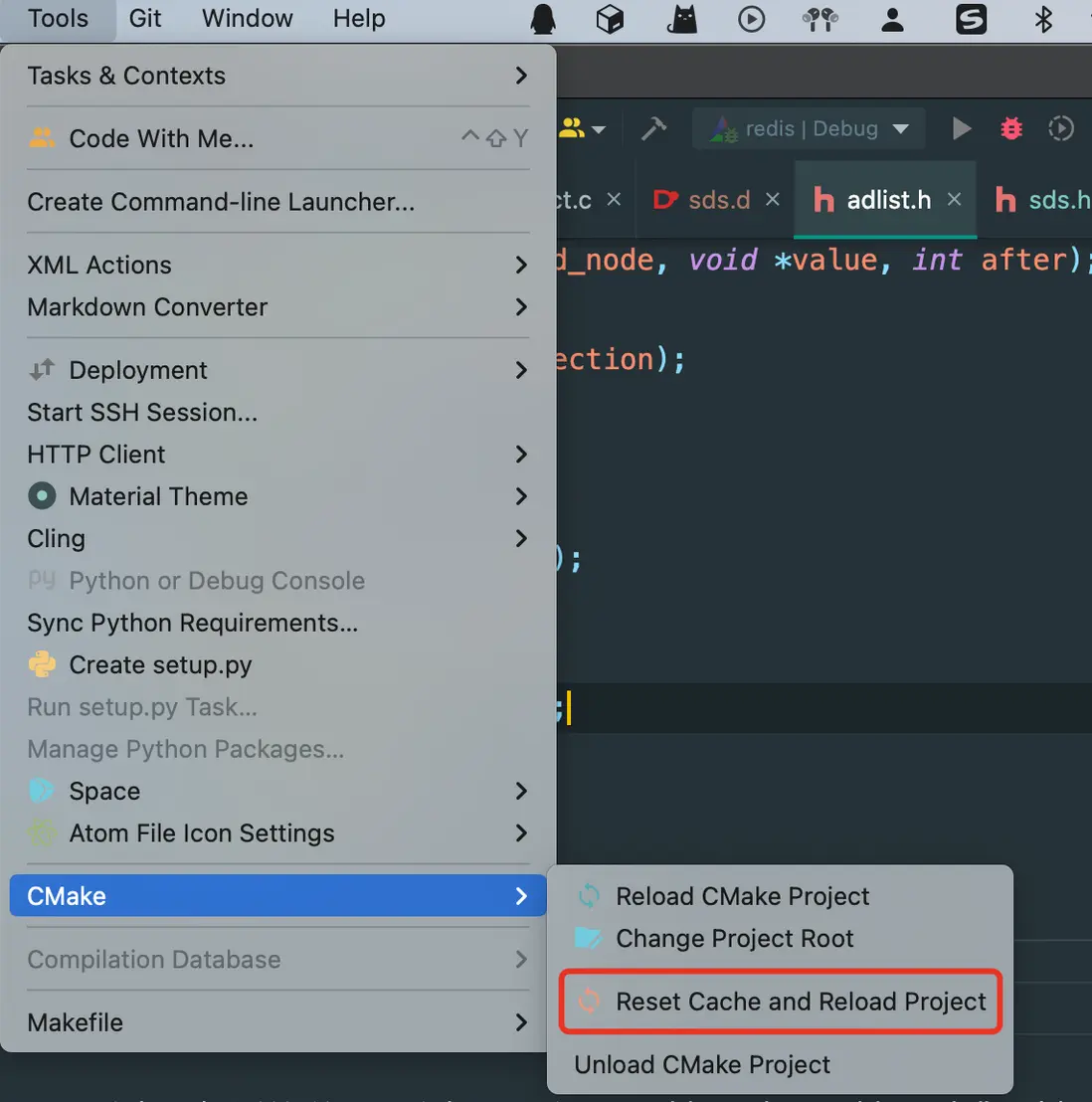
3 Redis源碼閲讀技巧
3.1 Redis 的目錄結構
Redis 的目錄:
-
deps: Redis 所依賴的第三方代碼庫
- hdr_histogram:用於生成命令的延遲追蹤直方圖
- hiredis:官方c語言客户端
- Jemalloc:內存分配器,默認情況下選擇該內存分配器來代替 Linux 系統的 libc-malloc,libc-malloc 性能不高,且碎片化嚴重。
- linenoise:一種讀線替換。它由 Redis 的 同一作者開發,但作為一個單獨的項目進行管理,並根據需要進行更新。
- lua:lua 腳本相關的功能。
-
src:源代碼
- commons:都是 json 文件,放着每個指令的原信息。
- modules:實現 Redis Module 的示例代碼。
- 其他文件均是源碼
-
test:測試代碼
- cluster,Redis Cluster 功能測試。
- sentinel,哨兵集羣功能測試。
- unit,單元測試。
- integration,主從複製功能測試。
- utils:工具類
- Makefile:編譯文件
- redis.conf : redis 啓動的配置文件
- sentinel.conf:哨兵配置
3.2 Redis 源碼閲讀順序
網上的源碼閲讀順序(引自網上):
- 自底向上:從耦合關係最小的模塊開始讀,然後逐漸過度到關係緊密的模塊。就好像寫程序的測試一樣,先從單元測試開始,然後才到功能測試。
- 從功能入手:通過文件名(模塊名)和函數名,快速定位到一個功能的具體實現,然後追蹤整個實現的運作流程,從而瞭解該功能的實現方式。
- 自頂向下:從程序的 main() 函數,或者某個特別大的調用者函數為入口,以深度優先或者廣度優先的方式閲讀它的源碼。
從大方向來説,學習 Redis 會有兩種路徑:
-
先從數據機構入手,直接手撕數據結構
- 好處:學着踏實,知根知底
- 壞處:容易從入門到放棄
-
先從啓動 Redis 開始,跟着啓動順序讀源碼,跟着具體的操作讀源碼
- 好處:比較符合人的認知路線,知道 Redis 啓動做了哪些操作,執行命令時做了哪些操作。
- 壞處:容易迷路,前期看哪一句,都不知道在幹嘛,畢竟 RDB,AOF,集羣,哨兵這些源碼,如果實操過才相對容易理解一點。
個人建議是先學習如何啓動 Redis,抓大放小(大致知道哪個類啓動,讀那些配置文件,大概是做什麼用的),學習 Redis 到底能幹什麼,大致知道 Redis 的一些用法之後,再去了解 Redis 的常用的數據結構,到底怎麼實現的,這個時候對 Redis 的一些數據結構大致有印象,之後可以跟着 Redis 啓動,執行命令去看具體功能執行的路徑。
在 Debug 的過程中,可以加深影響,更加了解數據結構的設計,代碼的調用關係。
4 C語言的知識
4.1 \#define的基本用法
在C語言中,常量是使用頻率很高的一個量。常量是指在程序運行過程中,其值不能被改變的量。常量常使用 #define來定義。
使用#define定義的常量也稱為符號常量,可以提高程序的運行效率,Redis 的源代碼中有比較多的地方都使用該方式。
一般有以下兩種用法:
#define 宏名 宏值
#define 宏名(參數列表) 表達式第一種就是定義常量,比如:
#define N 100此後直到 #undef N之前, N的值都是100。當遇到#undef N,其後如果再出現 N,則 N 需要重新定義之後才可以使用。
第二種語法常用來定義符號函數。
例如:
#define AREA(x,y) (x)*(y)表示用來求長和寬分別是x和y的矩形的面積。
需要注意的是,在表達式(x) * (y)中,x和y都要使用“()”括起來,這是因為符號函數在編譯時時進行符號形式替換。如果不加()則可能會發生意想不到的錯誤,例如:
#define AREA(x,y) x*y
...
A = AREA( 2+3, 1+2 );此處預期的結果是15,但是實際的結果卻是7,這是因為該段代碼在編譯進行了簡單的符號替換而得到的實際表達式是:
A = 2+3 * 1+2;
根據運算符的優先級,先進行乘法運算,然後才是加法,這就導致了錯誤。
而如果使用
#define AREA(x,y) (x)*(y)
...
A = AREA( 2+3, 1+2 );則在編譯時替換的結果是:
A = (2+3) * (1+2);#include"stdio.h"
#define AREA(x,y) (x)*(y)
int main()
{
int a = AREA(2+3, 1+2);
printf( " %d\n", a);
return 0;
}4.2 頭文件
Redis 是使用 c 語言寫的,裏面有很多頭文件:
#include "server.h"
#include "monotonic.h"
#include "cluster.h"
#include "slowlog.h"
#include "bio.h"
#include "latency.h"
#include "atomicvar.h"
#include "mt19937-64.h"
#include "functions.h"
#include "syscheck.h"
#include <time.h>以 < 開頭的,比如 #include <time.h> 是標準庫的頭文件,會在系統指定路徑下查找,對應到 Java裏面可以理解為 官方的 jdk 裏面的類,而類似 #include "server.h" 則是工程裏面自定義的。
我沒怎麼寫過 c 語言的代碼, 一般 .c 文件是寫實現的代碼邏輯的,那如何在 a 文件裏面寫一個方法,讓 b 文件也能用呢?
通過頭文件的機制,類似 Java 裏面的 接口, public 和 private 的概念,Java 中 一般希望對外暴露的方法,會設置為 public ,,如果不希望暴露,則設置為private。c 語言裏面如果希望暴露,則可以在頭文件裏面定義,否則不用定義。(雖然c語言是面向過程的,但是Redis確實在裏面實踐一些面向對象的思想)。
比如計算兩數之和 與 兩數之差 的乘積 test.c
long long mul(int a,int b) {
return a*b;
}
long long calculate(int a,int b) {
return mul(a+b,a-b);
}暴露出去的頭文件test.h
long long calculate(int a,int b);運行的代碼 main.c ,可以正常計算結果為 -3:
#include "stdio.h"
#include "test.h"
int main(){
printf("結果:%lld",calculate(1,2));
return 0;
}但是如果直接引用 sum() 方法,則會報錯,無法使用:
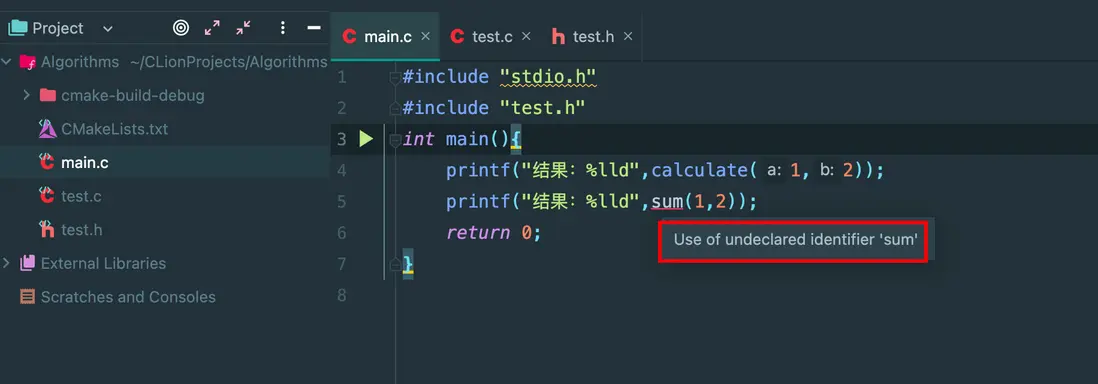
如果我們多次引用頭文件會怎麼樣?結果是正常運行:
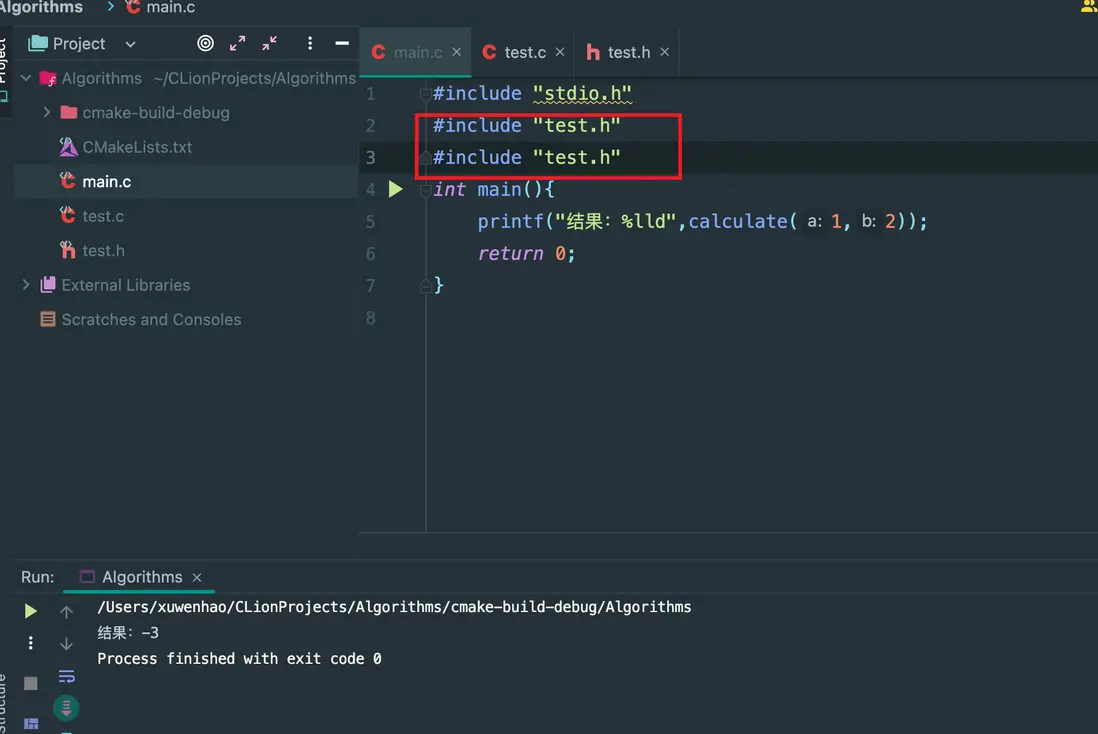
4.3 ifndef
Redis 裏面有挺多的地方定義頭文件的時候總是來一句 #isdef 或者 ifndef
#ifdef __linux__
#include <sys/mman.h>
#endif#ifndef __ADLIST_H__
#define __ADLIST_H__
...
#endif /* __ADLIST_H__ */如果加了 #ifndef ,則會判斷只有沒有定義這個宏的時候,才會定義它,第二次再次遇到 include 的時候,發現這個宏已經被定義過了,就會直接跳過,這樣可以保證多次 include 也不會被解析多次,有且只有一次。
解析多次的壞處是什麼?
- 如果在
.h文件裏面定義了全局變量,會導致變量重複定義。這個基本不太會,公司編碼規範一般都會禁止,這樣寫是不人道的。 - 浪費編譯時間。
既然禁止了在 .h 文件裏面定義全局變量,那全局變量在哪裏定義呢?當然是 .c 文件,比如 Redis 裏面的全局變量:
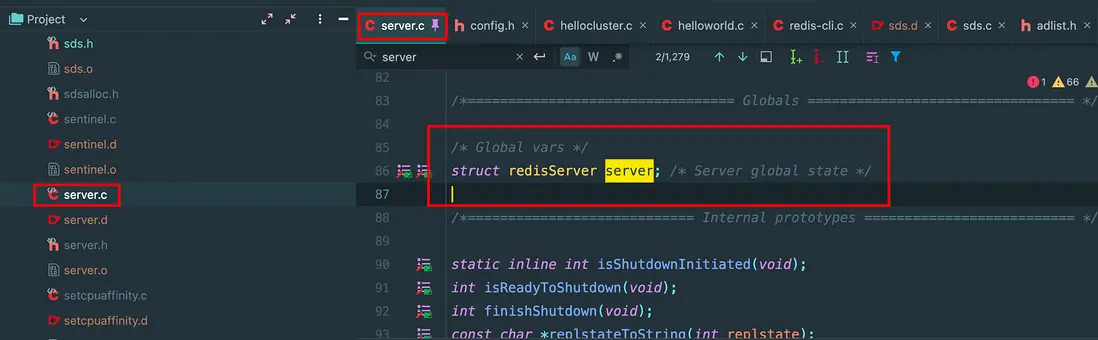
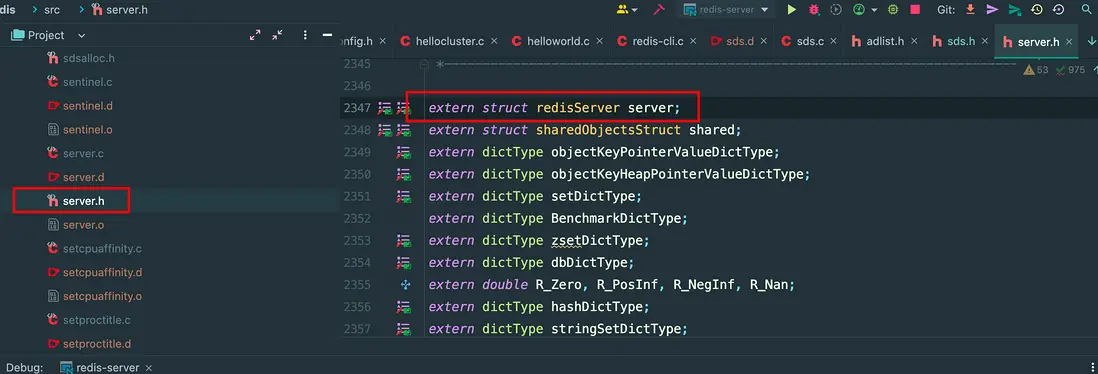
那其他的文件怎麼使用?這個 sever 可是全局唯一的,維護了 redis 的全部狀態數據,那當然是暴露出去,在哪裏暴露出去,在 .h 文件,使用關鍵字 extern
5 小結一下
閲讀源碼,是一件長期的事情,但是我們每次跟讀代碼的時候,一定要帶着問題去閲讀,否則效率會下降挺多。前期瞭解數據結構模型的時候,可以在網上找一些簡單易懂的博客,最好是有圖片的,書籍比較推薦《Redis 設計與實現》。有一定了解之後,會有些疑問,不用擔心,此時再通過讀源代碼去驗證我們的想法,可能不少小夥伴沒學過 c 語言,也不必擔心,語言之間都是相通的,其次即使有關鍵字不會,可以通過搜索也可以快速瞭解其作用。
希望我們都能從全局看功能 --> 實踐 --> 抓大放小 --> 帶疑問看源碼 --> 重構知識圖譜 --> 關聯知識 --> 跳出細節俯瞰全局,最終完成 Redis 相關的知識學習,並形成一套自己的方法論。
作者:秦懷












