









看到這一篇文章的 xdm ,應該對組織結構同步有一些想法了吧,如果沒有,可以看前面兩篇文章,可以通過如下地址查看一下:
- 【性能優化上】第三方組織結構同步優化一,你 get 到了嗎?
<!---->
- 坑爹,線上同步近 3w 個用户導致鏈路阻塞引入發的線上問題,你經歷過嗎?
這類文章,主要是期望能給 xdm 帶來不一樣的思考,如有表述不當的地方,還請不吝賜教,期望對你有幫助😀
這篇文章主要是闡述將臨時表中的用户組數據/用户數組,按照既定的步驟同步到我們的正式表,過程中遇到異常中斷,可以對我們的正式平台無影響,能夠保證下一次同步任務過來仍然可以進行斷點續傳
首先全量同步和增量同步分別指什麼?🧐🧐

🔥全量同步
簡單理解,全量同步,咱們就是將對方所有的數據,全部同步到我們內部系統中,對於組織結構同步的時候,我們沒有必要每一次都是全量的,一般是第一次,無到有的時候會用到全量同步,可以理解為全量覆蓋
🔥增量同步
那麼增量同步就比較好理解了,此處的增量同步指的是,第三方數據對於目前內部系統數據來説,哪一些是增加或者變動的數據,那麼就同步這一部分數據到內部系統中
那麼對於我們本次同步組織結構來説,就看內部系統是否已經存在了 /IDaaS 組,如果存在了,那麼就走增量同步,如果不存在,則走全量同步
😃😃😃
🔥全量同步基本流程
全量同步的基本流程比較簡單,再來回顧一下之前文章的一張總體圖
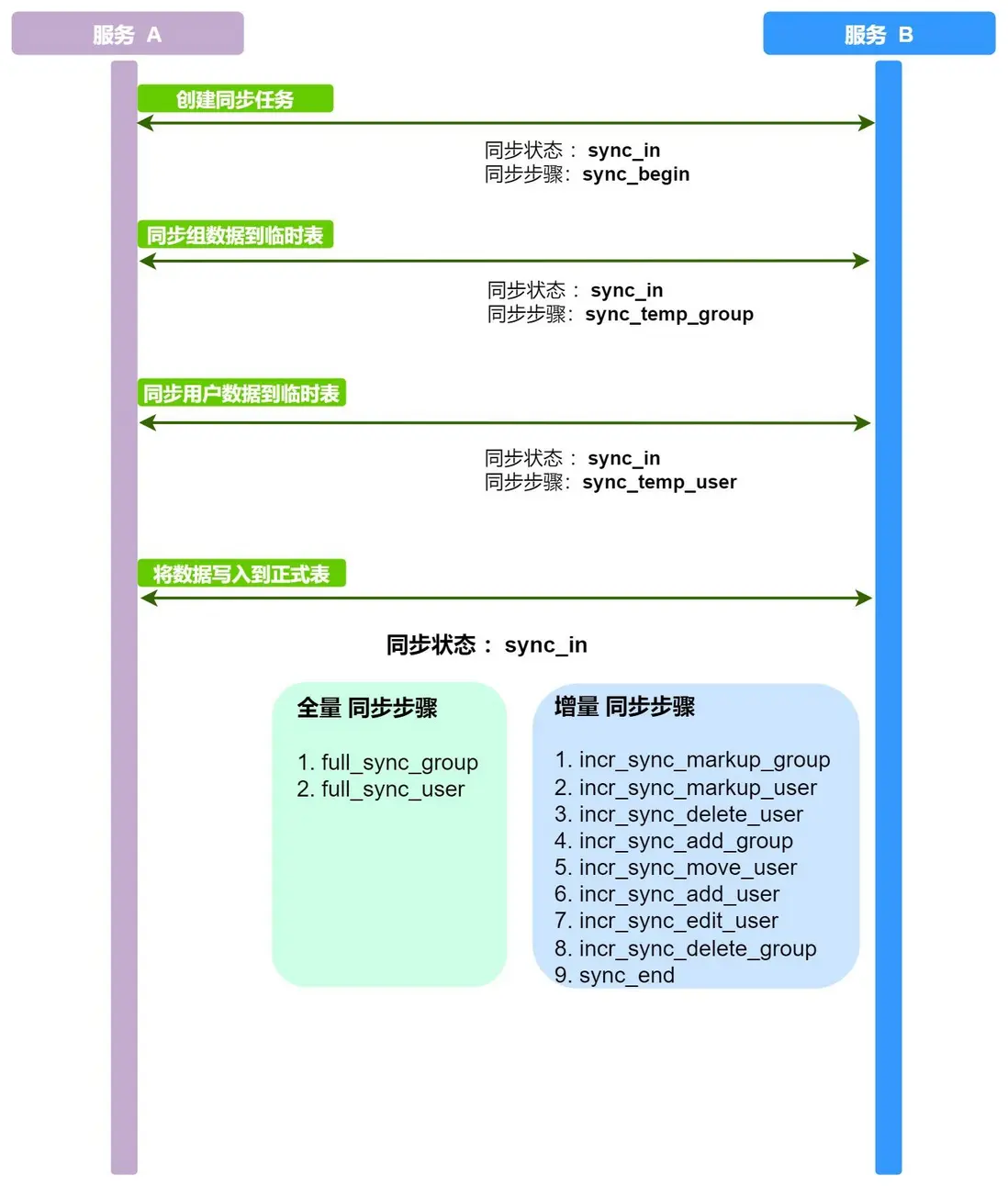
可以看到全量同步和增量同步在我們整個同步流程的第四個階段,到這個階段的時候,第三方組織結構的數據已經全部正確的寫入到了我們的臨時表中
這個時候,我們就需要將臨時表中的數據按照我們的邏輯和步驟寫入到正式表中
此處階段,顯示判斷是否有 /IDaaS 組,如果沒有,則在同步記錄表中寫入 同步類型為 full 全量同步,如果有 /IDaaS 組,則記錄同步類型為 incr 增量同步

全量同步比較簡單,總共分成兩個階段,一個階段是全量同步組 full_sync_group,一個是全量同步用户 full_sync_user
| 序號 | 步驟 | 含義 |
|---|---|---|
| 1 | full_sync_group | 全量同步臨時表中的組到正式表 |
| 2 | full_sync_user | 全量同步臨時表中的用户到正式表 |
此處比較簡單,同步用户之前,自然是先要將組給同步過來,完全分清楚,對於正式表中,數據是從無到有,所以步驟相對就簡單一些
🧐開始全量同步
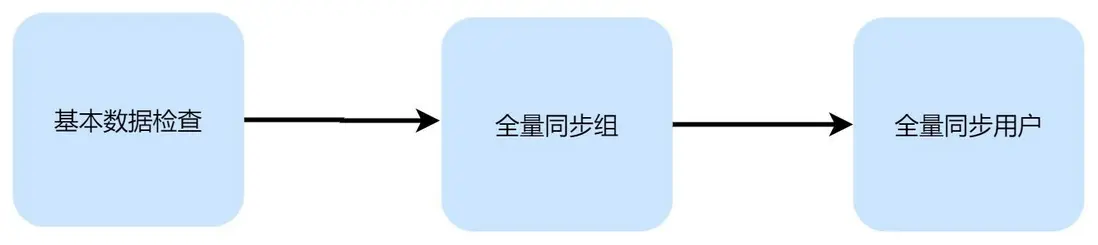
在進行全量同步前,仍然還是檢查當前的同步狀態是否是 sync_in,且同步步驟是否是sync_temp_user,若不是則不處理
-
檢查用户數量是否超過平台最大限制
- 若過程中出現 error,則關閉當前任務,不進行同步,並且將同步記錄中同步狀態設置為同步中斷 sync_interrupt,同步記錄表中重試次數 +1
- 檢查臨時表有效用户 + 已有正式表中未刪除用户的數量是否超過平台最大限制(一般平台會有對於一個租户最多容納多少用户的限制),更新同步狀態為同步失敗 sync_fail,並且清空臨時數據,通知其他服務處理失敗,且關閉當前任務
<!---->
- 校驗當前同步步驟是 sync_temp_user 或者 full_sync_group ,則開始正式將臨時表的組信息同步到正式表中,並將當前的同步步驟修改為 full_sync_group
- 這次這樣進行判斷,如果是 sync_temp_user 説明第一次處理到這裏,如果是 full_sync_group 步驟,説明這個步驟之前被中斷了,此刻需要斷點續傳
-
- 獲取臨時表中的組深度,且獲取按照深度排序的組列表
- 按照由淺到深的將組數據寫入到正式表中
- 刪除臨時用户表
- 如果過程中出現 error,則在該租户的同步記錄中,同步狀態標記為 sync_interrupt
- 當同步步驟是 full_sync_group 或者 full_sync_user 的時候,則開始將用户從臨時表加入到正式用户表中,且將同步步驟修改為 full_sync_user
- 同理,此處這樣的處理邏輯,也是為了斷點續傳,邏輯之外,關於一個步驟中數據庫的處理都是開啓事務的
-
- 一層一層的去添加用户,先從臨時表中查詢同一個深度下對應的所有用户
- 從正式表中讀取已經存在的用户
- 從臨時表中按照例如 1000 條每次去讀取數據(有效合法用户),寫到到正式表中,校驗如果用户已經存在於正式表中,則記錄衝突用户,且不錄入該用户,反之亦然
- 刪除臨時表中已經插入到正式表中的用户數據,並在臨時表中更新指定用户是非法的
- 如果過程中出現 error,則在該租户的同步記錄中,同步狀態標記為 sync_interrupt
- 同步結束,則將同步狀態設為 sync_success ,同步步驟設置為 sync_end,同時將臨時表中非法的組,非法的用户全部讀書出來,將非法數據傳出去
- 最終清除臨時用户組表,和臨時用户表 ,在 redis 中記錄下一次需要同步的時間
🔥增量同步基本流程
增量同步的話,相對步驟就會多一些,看起來可能會覺得複雜,實際上按照如下步驟走的話,會很清晰並不複雜
| 序號 | 步驟 | 含義 |
|---|---|---|
| 1 | incr_sync_markup_group | 標記組步驟 |
| 2 | incr_sync_markup_user | 標記用户步驟 |
| 3 | incr_sync_delete_user | 從正式表中刪除用户步驟 |
| 4 | incr_sync_add_group | 將臨時表中的組寫入到正式表中 |
| 5 | incr_sync_move_user | 處理正式表中移動用户 |
| 6 | incr_sync_add_user | 將臨時表中的用户添加到正式表中 |
| 7 | incr_sync_edit_user | 編輯正式表中的用户 |
| 8 | incr_sync_delete_group | 刪除正式表中的組 |
| 9 | sync_end | 增量同步結束 |
那麼對於增量同步為什麼需要那麼多步驟才能保證咱們順利同步?才能保證咱們可以斷點續傳??
實際上稍加思考的話,我們就需要考慮這些問題:
- 同步數據,自然是需要先同步組
<!---->
- 那麼對於組的增刪改查,用户的增刪改,我們需要按照這樣的順序處理呢?
<!---->
-
思考之後,自然是
- 刪除正式表中的用户(避免後續衝突,此步驟説明最新的同步數據中沒有這一部分用户)
- 添加組
- 移動用户 (如果移動的目的組不存在的話,那還玩什麼??所以添加組要放在這個步驟的前面)
- 添加用户
- 編輯用户
- 刪除組

🧐開始處理增量同步數據
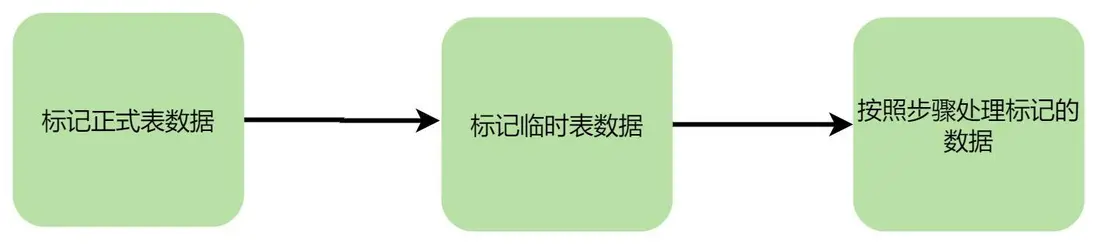
下面關於校驗步驟的位置,理由都是為了確定當前執行的步驟是正確的,並且為了做到斷點續傳
-
開始標記組
- 校驗當前同步步驟是 sync_temp_user 或者 incr_sync_markup_group,則當前的同步步驟修改為 incr_sync_markup_group
- 讀取原有正式表中的組,讀取臨時表中的組數據
- 通過標記,找到新增的組,找到刪除的組,並在臨時用户組表中標記新增的組,在正式表中標記刪除的組
<!---->
-
開始標記用户
- 校驗當前同步步驟是 incr_sync_markup_group 或者 incr_sync_markup_user,則將當前步驟修改為 incr_sync_markup_user
- 獲取原有正式表中的非IDaaS組下的用户,讀取臨時表中的用户,通過讀取出來的臨時表中的用户去讀取正式表中的數據,標記哪一些用户是新增的,哪一些是修改的,哪一些是移動的(組變動了),在正式表中標記刪除的用户
<!---->
-
開始處理正式表,臨時表中的標記數據
- 刪除用户 ,檢查當前步驟是 incr_sync_markup_user 或者是 incr_sync_delete_user 才進行,且更新步驟為 incr_sync_delete_user
- 新增用户組,校驗同步步驟是 incr_sync_delete_user 或者是 incr_sync_add_group 才進行,且更新步驟為 incr_sync_add_group
- 移動用户,校驗同步步驟是incr_sync_add_group 或者是 incr_sync_move_user 才進行,且更新步驟為 incr_sync_move_user
- 刪除用户組,校驗同步步驟是 incr_sync_move_user 或者是 incr_sync_delete_group 才進行,且更新步驟為 incr_sync_delete_group
- 新增用户,校驗同步步驟是 incr_sync_delete_group 或者是incr_sync_add_user 才進行,且更新步驟為 incr_sync_add_user
- 修改用户,校驗同步步驟是 incr_sync_add_user 或者是 incr_sync_edit_user 才進行,且更新步驟為 incr_sync_edit_user
- 如果過程中出現 error,則在該租户的同步記錄中,同步狀態標記為 sync_interrupt
- 同步結束,則將同步狀態設為 sync_success ,同步步驟設置為 sync_end,同時將臨時表中非法的組,非法的用户全部讀書出來,將非法數據傳出去
- 最終清除臨時用户組表,和臨時用户表 ,在 redis 中記錄下一次需要同步的時間
自然,對於每一個步驟的實現方式根據實際情況來定,這只是一個例子,主要是理解,整個流程的 3 張表,4 個同步狀態,以及 14 個同步步驟

是怎麼保證斷點續傳的?
可以看到對於每一個步驟都在我們的操控範圍內,還記的最開始創建同步任務的時候嗎?

這個 同步中斷 就是用於斷點續傳的
可以這樣來實現 斷點續傳
- 後台會啓動一個定時任務,定時去掃同步記錄表中 同步狀態是 sync_interrupt 狀態的記錄
<!---->
- 根據每一條記錄是全量同步還是增量同步,來走不同的同步路徑
<!---->
- 再根據每一條同步記錄中的同步步驟,就可以接着中斷之前的步驟來進行同步數據了
自然,細心的同學還發會發,同步記錄表中有重試次數這個字段,用法是每中斷一次,這個字段值 +1,如果發現已經 3 次了,那麼就會刪除這條記錄,若之後再次觸發該租户的同步任務,則從 0 開始同步即可
至此,關於本次組織結構同步的內容更新完畢,如果對你能夠帶來一些思考的話,歡迎冒個泡吧
感謝閲讀,歡迎交流,點個贊,關注一波 再走吧
歡迎點贊,關注,收藏
朋友們,你的支持和鼓勵,是我堅持分享,提高質量的動力

好了,本次就到這裏
技術是開放的,我們的心態,更應是開放的。擁抱變化,向陽而生,努力向前行。
我是阿兵雲原生,歡迎點贊關注收藏,下次見~
文中提到的技術點,感興趣的可以查看這些文章:
- 【性能優化上】第三方組織結構同步優化一,你 get 到了嗎?
<!---->
- 坑爹,線上同步近 3w 個用户導致鏈路阻塞引入發的線上問題,你經歷過嗎?
<!---->
- OAUTH之釘釘第三方授權

