









一場由 AI Agent 掀起的數據庫革命,正在瓦解沿用了三十年的數據架構體系。
從 2024 年 10 月到 2025 年 5 月,短短七個月內,AI Agent 創建的數據庫數量從 30% 爆漲至 80%,遠超人類工程師的工作產出。與此同時,Databricks 以 10 億美元收購 Neon 的消息震動業界——這家人工智能巨頭正在用真金白銀搶佔下一代數據基礎設施入口。

“傳統架構正在集體失靈。”
前 Facebook core infra、阿里搜索數據和機器學習平台,以及達摩院機器智能工程的技術領軍人、ProtonBase 創始人兼 CEO 王紹翾指出。
01/崩塌的舊秩序,AI Agent 重寫數據規則
假如採用傳統 “拼湊式架構”,一個 toC 智能 AI Agent 請求,有時需要穿透 MySQL 用户庫、Elasticsearch 日誌系統、向量數據庫和 ClickHouse 分析系統。當四個系統完成數據拼接時,手機端的用户早已關閉應用界面。
更致命的是成本黑洞。某頭部電商的技術總監算過一筆賬:為支撐推薦系統的 AI Agent,每年需要支付超過 500 萬元,其中包括 Aurora 數據庫費用、維護 Elasticsearch 集羣的費用、用於向量檢索服務的費用,還有工程師團隊晝夜不停地系統維護、開發、和調優。根據 IDC 2025 企業雲支出報告,電商行業數據架構年成本中位數為 460 萬元。
採用拼湊式架構,就像用十台蒸汽機車拼湊高鐵。而數據觸目驚心背後,真正的顛覆者已經入場。
2025 年或將成為數據基礎設施行業的分水嶺,巨頭們正以資本重注押定下一代技術標準。當 Databricks 豪擲 10 億美金收購雲原生數據庫 Neon 時,全球技術圈突然意識到:這場爭奪的本質是搶佔 AI Agent 的底層入口。幾乎同一時間,Snowflake 收購 CrunchyDB,其戰略意圖直指 PostgreSQL 生態的掌控權。更值得玩味的是,曾以實時數倉著稱的 ClickHouse 悄然開始淡化 “數據倉庫” 標籤,而開始強調 Data Warehouse + Database,全面轉向多模數據庫。舊時代的技術邊界,正被資本與 AI 的雙重浪潮徹底沖垮。
02/Data Warebase 技術革命破解不可能三角
舊秩序崩塌,真正的拷問浮出水面:到底怎樣的技術架構才能承載 AI 時代的洪流?
答案正從 Data Warebase 架構的工程實戰中浮現。金融高頻交易和風控引擎、車聯網日誌和安全報警系統、電商推薦系統、廣告實時競價聯盟等多個場景的成功實踐,宣告數據架構領域持續十年的 “不可能三角” 困局正在瓦解——實時性、多模態、高併發三大核心能力首次在 Data Warebase 架構中實現融合。
Data Warebase 的概念是將 Data Warehouse 與 Database 融合於一體,構建統一的數據底座,以全面支撐 AI 工作流中從數據高吞吐寫入、實時加工、高頻的分析和檢索的全過程。
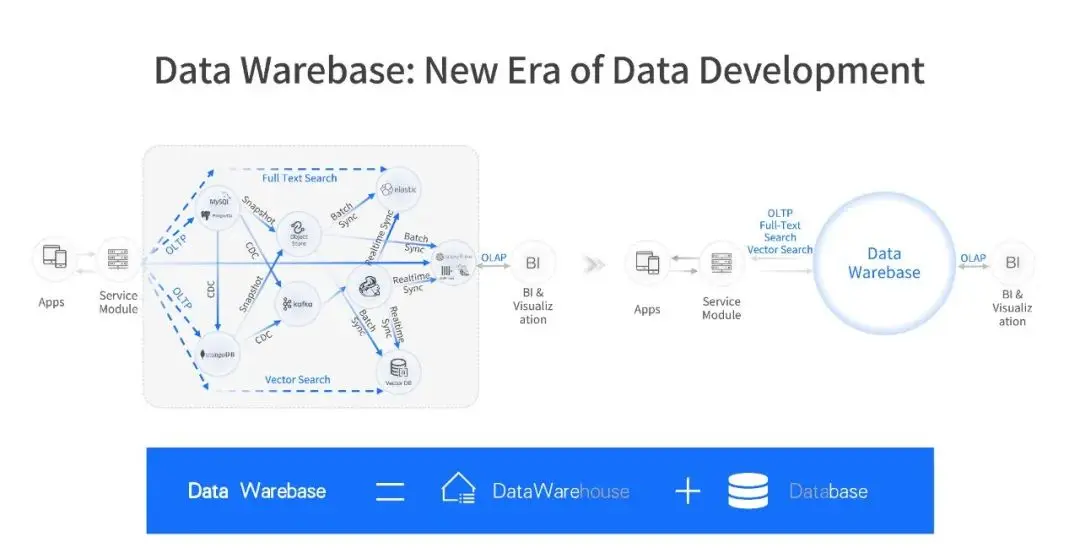
這場革命的技術本質,源自幾個已被驗證的關鍵突破:
其一,PostgreSQL 的生態統治力成為破局基石。
幾乎所有的新型數據庫項目都選擇基於 PostgreSQL 構建。剛才提到的 Neon 和 CrunchyDB,只是其中的代表,全球近幾年新出現的數據庫產品無一例外的選擇了 PostgreSQL 作為查詢 API。PostgreSQL 靠其強大的可擴展性和生態,贏得了全球所有新興數據庫的青睞。一則非官方報道,OpenAI 內部的一個 PostgreSQL 只讀從庫就部署了近 50 個實例,這意味着行業確認了 AI 時代的數據接口標準。 Anthropic 進一步在 MCP(Model Context Protocol)中直接內置 PostgreSQL 接口,這進一步印證了 PostgreSQL 在 AI 應用工作負載中的關鍵作用——它不僅是一種數據庫,更是 AI 系統與數據交互的中樞平台。
其二,行列混存,多模索引,存算分離。
Data Warebase 實現了數據庫和大數據的最重要的三個能力:在存儲層,它支持數據的行存、列存以及行列混存;在索引上,它實現了分佈式數據庫最重要的全局二級索引,以及搜索所需要的倒排索引、向量索引、和分析所需要的列存索引等等;最後,它在高速雲存儲上做到數據庫級別的存算分離。
其三,實時增量物化視圖技術正在終結流處理引擎時代。
這項創新被王紹翾在 AICon 大會定義為 “流批一體的終極形態”。其技術原理在於:感知變更的數據、基於高效索引的增量計算、事務型存儲三層能力熔鑄在統一架構的 Data Warebase 內核中,讓 Instant ingestion-transform-retrieval 得以在一個系統中完成,消除傳統方案的冗長鏈路。正如王紹翾所認為,流計算不應依賴外部引擎,真正的實時性必須內生於一個統一的多模數據庫之中。
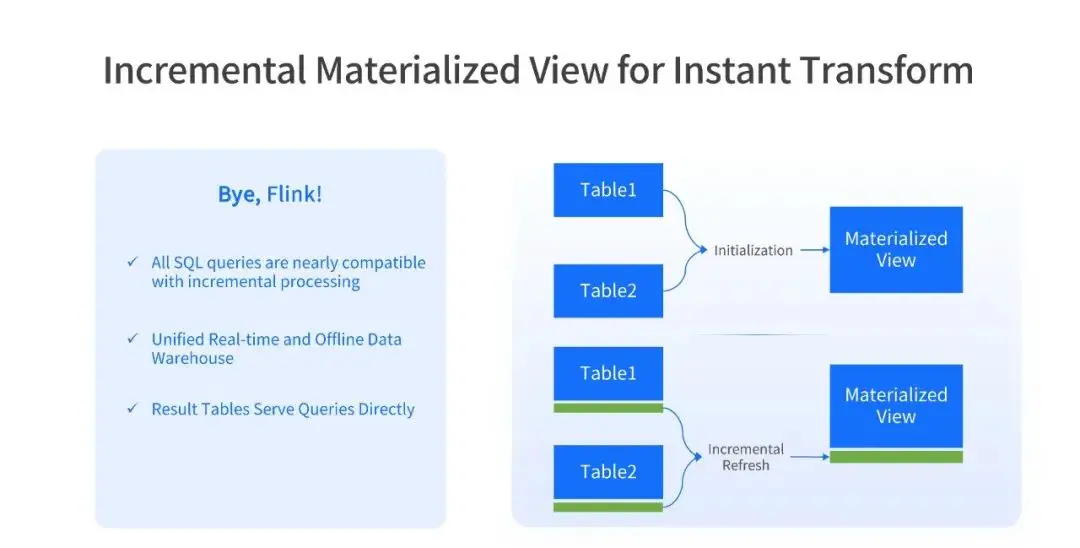
Data Warebase 的本質是通過 PostgreSQL 生態實現多模態數據的協議統一,借實時物化視圖完成流批數據的引擎重構,最終在單一產品內實現分佈式計算與分佈式存儲的高效融合。正是這些多重革命,讓曾經撕裂的實時性、多模態、高併發能力發生鏈式反應,從而在數據庫內核中溶解了傳統架構單機物理隔離造成的性能鴻溝。
03/萬億級市場爆破:誰在收割數據革命紅利?
當 Data Warebase 打破數據架構領域持續數十年的 “不可能三角”,商業世界的價值裂變已然在真實戰場爆發——從金融領域的量化交易和實時風控,到車機數據每秒更新並即時進行規則匹配和安全分析...... 技術範式躍遷正沿着三重座標軸撕開萬億市場的豁口:
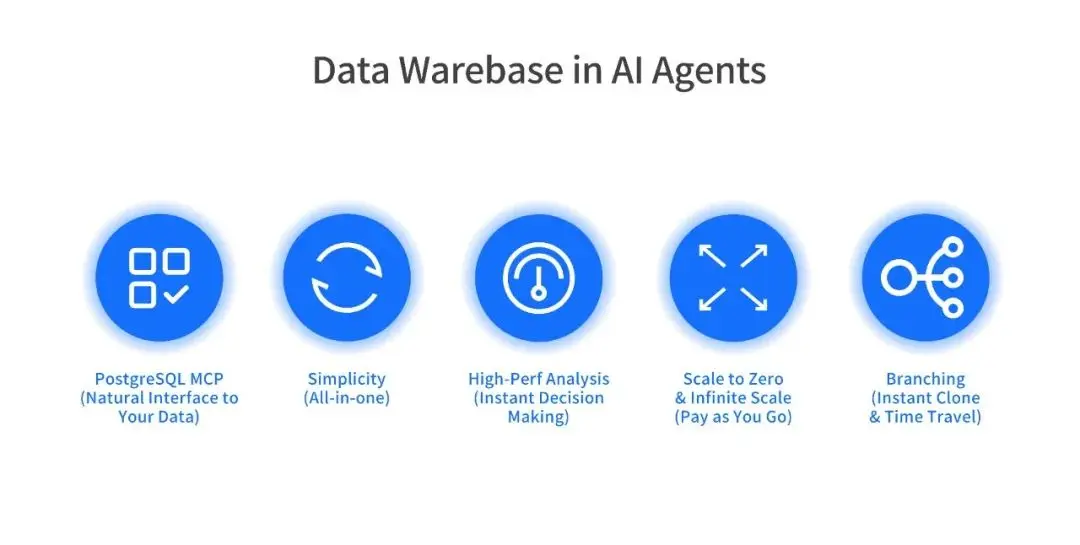
AI Agent 戰場率先掀起革命。未來大部分服務將依託 AI Agent 進行智能交互,而 AI Agent 需要一個強大的 Data API,Data Warebase 提供了強大的多模查詢、極致彈性、以及分支管理的能力,能夠很好地支持 AI Agent 的場景。未來的 AI Agent,不需要對接多個 MCP,而是連接一個多模數據庫。用一個數據庫,一個 MCP 接口,極大降低 LLM 大模型的智力和推理的門檻。
金融量化交易正在兑現亞秒級決策。在金融證券行業的極速戰場,當每秒百萬級行情數據必須實時寫入並立即可見時,某頭部券商最初採用分佈式 OLAP 數據庫遇到數據新鮮度和吞吐瓶頸而腰斬,轉用分佈式 OLTP 數據庫又遇到多維分析查詢性能過差而被迫放棄——作為 Data Warebase 範式的典型實現,ProtonBase 以亞秒級 Freshness + 高吞吐 Instant Decision 破解該券商的困局,最終在毫秒定盈虧的金融沙場上,將數據新鮮度代差轉化為真金白銀的盈虧差。

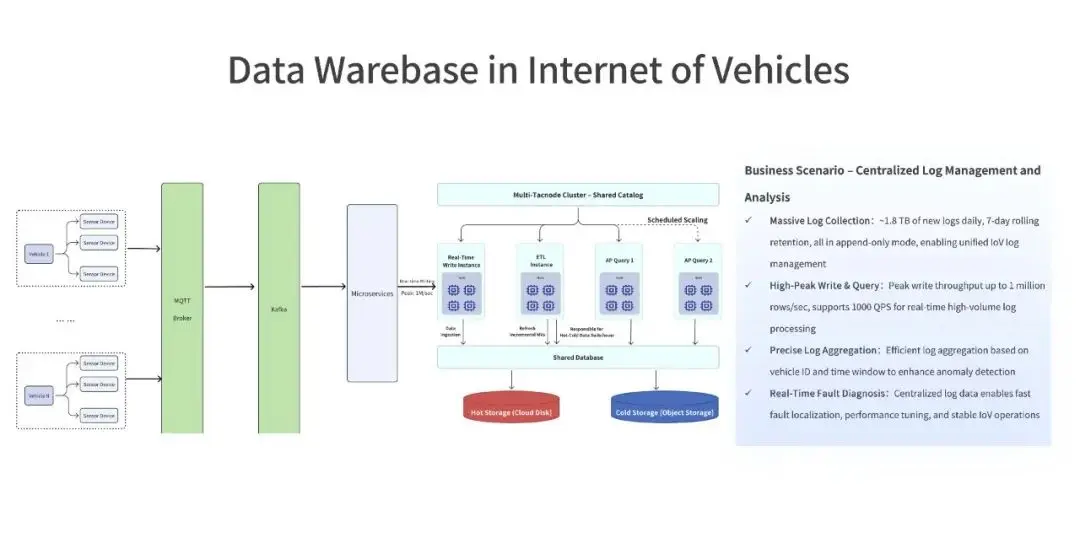
車聯網安全監控實現秒級預警重構。面對百萬輛電動車每秒涌入的百萬條車機信號,某頭部車聯網企業遭遇監管存儲與安全監控的雙重夾擊——傳統架構下核心信號異常監控延遲高達數分鐘,而熱失控等風險的響應窗口不足 10 秒。通過 ProtonBase 的 Data Warebase 範式,該企業以實時增量物化視圖引擎實現秒級數據加工及風險診斷,在統一架構內同步完成歷史數據合規存儲與關鍵信號掃描,終結雙系統割裂時代。
04/Data Warebase 提出者終極預判
商業紅利的快速涌現印證了王紹翾的前瞻洞見:生態霸權與協議簡化正重塑數據基礎設施的未來版圖。他斬釘截鐵預言——PostgreSQL 將在 AI 時代扮演類似 TCP/IP 的基礎協議角色,而 Iceberg 終將成為數據湖領域的終極標準。
此刻的技術淘汰賽已進入倒計時:
- 三年內無法同時支撐 AI Agent 高吞吐交互與實時決策的數據庫廠商必將退場。
- 未來企業只需兩個 API:Data API 喂數據,AI API 出決策。
對創業者而言,生存法則從未如此清晰:必須將技術命脈深扎 PostgreSQL 的擴展生態,同時把商業引擎轉向全球海域。“Made in China, Sold Global” 不再只是口號,而是技術代差碾壓下的必然利潤迴流。Data Warebase 的本質,正是支撐這一預判的工程基石——通過 PostgreSQL 生態統一數據基座、利用分佈式行列混存和多模態索引提升寫入和查詢性能、使用實時增量物化視圖解決實時數據加工、最後利用極致的存算分離技術解決秒級彈性以及存儲和計算的無限水平擴展,將全鏈路(寫入、加工、和查詢)亞秒級的決策能力轉化為全球企業的生產現實。而它正在點燃的,不止是技術架構的重構之火,更是一場全球產業權力的無聲遷徙。












