









在我博客裏,也多次提到了中值模糊的優化,比如以下兩篇文章:
【算法隨記三】小半徑中值模糊的急速實現(16MB圖7.5ms實現) + Photoshop中蒙塵和劃痕算法解讀。
任意半徑中值濾波(擴展至百分比濾波器)O(1)時間複雜度算法的原理、實現及效果。
但是,這些都是這對8位圖像的優化,也就是説圖像的色階最多隻有256,如果把這個優化算法直接擴展到16位的RAW圖像,有以下幾個情況:
1、小半徑的(3*3 / 5*5)的快速實現,是完全可以借鑑8位的處理方式的,而且速度依舊是非常出色的。
2、更大的半徑的,如果直接沿用8位的處理方式(上述第二篇參考文章),有以下幾個問題:
(1)對於10、12位的也許還可以,這種情況需要將直方圖分別分解為32及64個粗分及細分直方圖,然後進行處理,這個時候相關的直方圖相加的計算量也會對應的增加,內部的中值的更新計算量也會相應的增加,整體耗時要比8位的增加2倍及4倍以上。
(2)對於14位及16位的圖像,如果使用同樣的處理方式,細分及粗分直方圖的數量增加至128和256個,這個時候的增加的計算量非常客觀了,已經不具備任何的性能優勢,另外一個重要的問題是,相關的內存分配可能會失敗,因為在O(1)時間複雜度的文章中,相關的內存需要下如以下代碼所示:

當處理14位圖時,H_Fine需要分配128*128*Width*sizeof(unsigned short)字節大小的內存,假定寬度為3072像素,這個尺寸在處理RAW數據時並不是很誇張的,那麼H_Fine需要96MB的內存,如果是16位,則增加到384MB,瞭解計算機內存的都知道,分配這麼大的連續內存是很有可能失敗的。
當然,內存問題也許有其他的方案可以解決,但是核心的速度問題還是無法滿足實際的需求的。
(3)如果是9位、11位、13位、15位這種圖像,那其實直接使用8位的方式,除了上述兩個問題外,還有就是粗分和細分直方圖如何取捨,也是個研究點,當然,實際中我們很少遇到這樣的格式,而且即使遇到了,也可以把他們當成向上一位的10/12/14/16格式處理,因為中值處理算法是不會增加新的像素值(在原圖中原先不存在的像素色階)的。
因此,我一直在尋找或者説構思一個能夠快速處理unsigned short數據類型的通用的中值算法,不過這麼多年也一直沒有找到答案。
最近,來自安道爾(誰都知道怎麼回事)微信朋友江向我諮詢8位的中值和自適應中值能不能用到16位上,又讓我在這個問題上摸索了半個月,無意中在GIMP的中值模糊中找到了問題的答案。
我比較了幾個能處理16位圖像的中值,粗略的做了個耗時統計:

同樣大小的8位灰度圖,使用SSE優化後的速度耗時約為0.13S。
後續補充: 後續用halcon測試同樣的數據,結果耗時40s,我真的感謝他,可能halcon根本不關係16位的圖,畢竟工業上基本都是8位的。
測試時,我注意觀察了下CPU的使用情況,可以確認PS、GIMP、ImageJ等都使用多線程,CPU使用率都接近100%,而OpenCv實測只支持濾波器為3*3或者5*5的16位圖像的中值,後面我看了相關説明,確實有如下的講法:

不過可以確認的是16位的中值也可以是做到非常快速的。既然GIMP也能做到那麼快,那我們當然可以參考他的實現方式。
在GIMP源代碼的有關的文件夾裏搜索median,可以在gegl-master\operations\common\找到這個median-blur.c這個文件。
源代碼分析:
GIMP的源代碼其實對普通用户來説是不太優化的,因為這畢竟是一個大工程,我們也不期望直接去運行或者調試這個軟件的代碼,而是從一個代碼裏去大概得猜測他的實現思路和想法。
我已經基本吃透了這個代碼,這裏就對他做一些簡單易懂的説明:
整體來説,這個median-blur也是基於直方圖的操作,先統計第一個位置的直方圖,然後依據直方圖計算出中值,並記錄對應的中值統計累加量,對於下一個像素,更新直方圖,更新完成後不是直接用所有直方圖的信息來計算中值,而是依據前一次中值的信息,在其附近搜索新的中值,因為對於圖像來説,不管是8位還是16位的,相鄰的位置中值其實不會差異很大,因此在舊的中值處搜索新的中值,將是一個效率很高的過程。
我們關注下這個過程中的三個函數histogram_modify_vals、histogram_get_median、histogram_update,對於他們做一個簡單的解釋:
1 static inline void histogram_modify_val (Histogram *hist, const gint32 *src, gint diff, gint n_color_components, gboolean has_alpha)
2 {
3 gint alpha = diff;
4 gint c;
5 if (has_alpha)
6 alpha *= hist->alpha_values[src[n_color_components]];
7 for (c = 0; c < n_color_components; c++)
8 {
9 HistogramComponent *comp = &hist->components[c];
10 gint bin = src[c];
11 comp->bins[bin] += alpha;
12 /* this is shorthand for:
13 *
14 * if (bin <= comp->last_median)
15 * comp->last_median_sum += alpha;
16 *
17 * but with a notable speed boost.
18 */
19 comp->last_median_sum += (bin <= comp->last_median) * alpha;
20 }
21 if (has_alpha)
22 {
23 HistogramComponent *comp = &hist->components[n_color_components];
24 gint bin = src[n_color_components];
25 comp->bins[bin] += diff;
26 comp->last_median_sum += (bin <= comp->last_median) * diff;
27 }
28 hist->count += alpha;
29 }
這個histogram_modify_val是個修改直方圖值的一個內聯函數,代碼一堆,實際的意思呢,其實也很簡單,就是如果要把某個位置的像素信息(像素值為bin)添加到現有的直方圖中,則alpha設置為1,對應Bins[bin]就增加1,如果這個時候bin值小於或等於之前的中值last_median,則需要將last_median_sum增加1,而last_median_sum實際上是保存了之前第一次超過或等於中值時所有元素的總數量。
如果是要將某個位置的像素信息從現有直方圖中刪除掉,則則alpha設置為-1,對應Bins[bin]就減少1,如果這個時候bin值於小於或等於之前的中值last_median,則需要將last_median_sum減少1。這樣就動態的保持了直方圖信息和中值累加值的更新。
而從更新後的直方圖中獲取新的中值則需要使用histogram_get_median函數。
1 static inline gfloat histogram_get_median (Histogram *hist, gint component, gdouble percentile)
2 {
3 gint count = hist->count;
4 HistogramComponent *comp = &hist->components[component];
5 gint i = comp->last_median;
6 gint sum = comp->last_median_sum;
7 if (component == hist->n_color_components)
8 count = hist->size;
9 if (count == 0) return 0.0f;
10 count = (gint) ceil (count * percentile);
11 count = MAX (count, 1);
12 if (sum < count)
13 {
14 while ((sum += comp->bins[++i]) < count);
15 }
16 else
17 {
18 while ((sum -= comp->bins[i--]) >= count);
19 sum += comp->bins[++i];
20 }
21 comp->last_median = i;
22 comp->last_median_sum = sum;
23 return comp->bin_values[i];
24 }
不要過分的在意代碼裏的一些不知所謂的判斷和變量啊,我們只關注下第12行到第20行,這裏sum變量表示上一次統計直方圖時,第一次超過或等於中值時所有元素的總數量,如果sum小於我們設定的中值統計停止值,則需要增加中值,直到他再次大於或等於停止值,如果sum已經大於了停止值,則需要減少中值,直到他第一次小於停止值,但是此時,我們需要將得到的臨時中值增加1,同時sum也要增加對應的數量,以便讓新的中值滿足大於或等於停止值的要求。
這個代碼裏充分體現了++i和i++的靈活運用,不過我感覺我還是不要用這種方式書寫代碼,寧願分開寫,也要讓理解變得更為簡單。
下面是histogram_update的過程,這個在GIMP裏支持矩形、圓形、菱形的中值,我只貼出矩形部分的代碼:
static inline void histogram_update (Histogram *hist, const gint32 *src, gint stride,GeglMedianBlurNeighborhood neighborhood, gint radius,const gint *neighborhood_outline,Direction dir)
{
gint i;
switch (neighborhood)
{
case GEGL_MEDIAN_BLUR_NEIGHBORHOOD_SQUARE:
switch (dir)
{
case LEFT_TO_RIGHT:
histogram_modify_vals (hist, src, stride, -radius - 1, -radius, -radius - 1, +radius, -1);
histogram_modify_vals (hist, src, stride, +radius, -radius, +radius, +radius, +1);
break;
case RIGHT_TO_LEFT:
histogram_modify_vals (hist, src, stride,+radius + 1, -radius, +radius + 1, +radius, -1);
histogram_modify_vals (hist, src, stride,-radius, -radius,-radius, +radius, +1);
break;
case TOP_TO_BOTTOM:
histogram_modify_vals (hist, src, stride,-radius, -radius - 1, +radius, -radius - 1,-1);
histogram_modify_vals (hist, src, stride,-radius, +radius,+radius, +radius, +1);
break;
}
break;
}
所謂的直方圖更新,意思是當計算完一個位置的像素中值後,我們根據當前像素已經統計好的直方圖信息,去利用相關重疊信息來獲取下一個位置的新的直方圖,在GIMP這個的代碼裏,採用了一個更新策略,即先從左到右(LEFT_TO_RIGHT)更新,到一行像素的最後一個位置時,再從上到向下(TOP_TO_BOTTOM)更新,到下一行時,則從右到左(RIGHT_TO_LEFT)更新,處理到下一行的第一個元素是,再次從上到下更新,然後接着又是從左到右,如下圖所示,如此往復循環。

在更為具體的GIMP代碼裏,我們還注意到GIMP還有很有意思的convert_values_to_bins函數,這個東西是個有點意思的玩意,他實際上是幹啥呢,説白了就是減少冗餘的信息,正常來説一個16位的圖像,那麼他可能所含有的色階數最多就是有65536中,但是實際上一副圖裏真正都用到的色階呢很有可能是不到65536個的,那這個現象有什麼意義呢,他的核心就在於可以減少統計直方圖獲取中值的時間,具體來説,convert_values_to_bins就是把原始的圖像信息做適當壓縮,使得每個色階都有至少一個值存在於圖像中。我們舉個例子,一副只有10個像素的16位圖,他們的值分別為:
1 100 2000 150 100 40000 350 1 2000 300
這個時候如果我們定義的直方圖為Histgram[65536],那麼只有稀疏幾個色階有對應的直方圖信息,大部分都為0,這樣我們要統計中值還是要從0開始循環,一次掃過一堆為0的直方圖信息,直到某個值為止符合中值的條件才停止。但是如果在進行直方圖統計前已經把圖像信息進行過統計和重新賦值,則有可能極大的改進這個統計過程。
具體如下操作,首先統計只10個數據有幾個不同的值,明顯有 1、100、150、300、350、2000、40000等7個不同的值,然後把不同大小的值按從小到大排序,再把原始10個數據修改為這些排序後的不同的值的索引,則新的10個值變為:
0 1 5 2 1 6 4 0 5 3
這個時候直方圖的定義只需要敢為Histgram[7]就可以了,統計直方圖獲取中值的次數將大大減少。當然這個時候獲得中值的值不是真正的像素值,而是一個索引,而根據這個索引結合上述排序後的數據,則就可以獲取真正的像素了。
GIMP中為了上述效果,使用一個sort_input_values函數,對所有像素帶索引信息進行排序,然後在獲取新的索引值,個人覺得這是個思路,但是其實針對圖像數據來説,可以不用這麼複雜,完全可以根據直方圖信息來,我後面修改為如下簡單易理解的代碼?
for (int Y = 0; Y < Width * Height; Y++)
{
Histgram[Src[Y]]++;
}
// 統計不同的色階數量,注意這裏要搜索MaxV這個值
for (int Y = 0; Y <= MaxV; Y++)
{
if (Histgram[Y] != 0) BinAmount++;
}
// 分配合適的大小
BinValue = (unsigned short*)malloc(BinAmount * sizeof(unsigned short));
BinAmount = 0;
for (int Y = 0; Y <= MaxV; Y++)
{
if (Histgram[Y] != 0)
{
Table[Y] = BinAmount; // 通過索引Y(即像素實際值)能找到對應的Bin
BinValue[BinAmount] = Y; // 通過Bin也能得到對應的像素值
BinAmount++;
}
}
// 把Expand裏的數據隱射到更小的範圍裏,Expand是中間數據,可以隨意更改
for (int Y = 0; Y < ExpandW * ExpandH; Y++)
{
Expand[Y] = Table[Expand[Y]];
}
這個效率就比GIMP那個高很多了。
另外,仔細看GIMP的代碼,在其process函數裏,還增加了分開處理的部分,核心部分如下所示:
if (! data->quantize &&
(roi->width > MAX_CHUNK_WIDTH || roi->height > MAX_CHUNK_HEIGHT))
{
gint n_x = (roi->width + MAX_CHUNK_WIDTH - 1) / MAX_CHUNK_WIDTH;
gint n_y = (roi->height + MAX_CHUNK_HEIGHT - 1) / MAX_CHUNK_HEIGHT;
gint x;
gint y;
for (y = 0; y < n_y; y++)
{
for (x = 0; x < n_x; x++)
{
GeglRectangle chunk;
chunk.x = roi->x + roi->width * x / n_x;
chunk.y = roi->y + roi->height * y / n_y;
chunk.width = roi->x + roi->width * (x + 1) / n_x - chunk.x;
chunk.height = roi->y + roi->height * (y + 1) / n_y - chunk.y;
if (! process (operation, input, output, &chunk, level))
return FALSE;
}
}
return TRUE;
}
其中MAX_CHUNK_HEIGHT和MAX_CHUNK_WIDTH 定義為128。
這裏也是很有意思的部分,我理解他至少有幾重意義:
1、分塊後更加適合多線程處理了。原始的工作方式,從左到右,從上到下,從右到左在從上到下更新直方圖,這個過程是前後依賴的,是不能直接使用多線程的,而分塊後,每一個塊之間可以做到獨立處理,當然就可以線程並行了,代價時整體的計算量其實是增加的,但是耗時會變少。
2、前面説了GIMP需要通過排序來壓縮數據,減少直方圖的總量,但是如果不分快,一個整個圖,實際上由於數據量大,實際使用過的色階數還是比較多的,但是分成小塊之後,這個數據就有可能極大的減少,特別有一些RAW圖像常有的背景區域,基本上就幾十個色階,這種對於速度提升來説是很有幫助的。
3、另外一個問題就是,排序是個耗時的工作,如果對整幅圖的數據進行排序,那麼這個意義就很小了,但是我們知道一個事實,24*24次 128*128的排序,要比單次3072*3072數量的排序快很多的,雖然實際上分塊後的排序寬度和高度上還要增加半徑值,但是也還是比整體排序快很多,所以分塊默認還帶來了這個好處。
所以這個代碼也是一環扣一環,當然,如果用我上面那種處理方式,就不存在排序的事情了。
最後在説一點,就是前面那種直方圖從左到右,從上到下,從右到左的更新方式還有一個好處,就是直方圖的清零工作只需要做一次,而以前我寫的此類算法一般都是在每一行第一個點位置處清零,然後直接從左到右進行更新計算,這種寫法對於不分塊整體處理來説可能影響不大,但是對於分塊的算法來説,如果還是這種做法,需要 n_x * width清零,其中n_x 表示水平分塊的數量,比如3072*3072的,則需要24*3072清零,如果直方圖大小平均為10000個元素,這個操作也是有點佔用時間的。所以這些好處都是潛在的需要炸取的。
進過這一系列的操作,加上我自己的一些其他的優化,目前,我能在相同配置的機器上做到和PS差不多或者更強的速度,比如同樣的測試圖,我做到了多線程版本85ms的速度(16位的)。
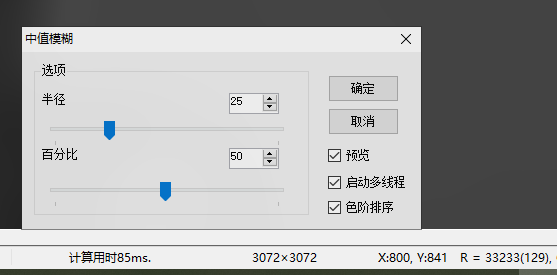
基於中值的實現呢,可以輔助實現一些其他的功能,比如基於中值的鋭化,基於中值的去噪等等。因此,也是非常有意義的一項工作。
關於16位RAW圖像,本人開發了一個簡易的增強和處理程序,可在 https://files.cnblogs.com/files/Imageshop/Optimization_Demo_16.rar下載測試。
如果想時刻關注本人的最新文章,也可關注公眾號:

