

面對億級多邊形建模和實時交互需求,動態LOD與多線程渲染技術正成為數字孿生引擎突破性能瓶頸的關鍵。
1 技術背景與挑戰
隨着數字孿生技術在工業製造、智慧城市等領域的深入應用,場景複雜度呈指數級增長。單個數字孿生場景通常包含數千萬至數億個多邊形面片,傳統渲染引擎在保持實時幀率(≥30fps) 方面面臨巨大挑戰。特別是在AI算力需求激增的背景下,如何平衡渲染質量與性能成為行業焦點問題。
2 核心優化技術
2.1 動態LOD(層次細節)技術
動態LOD技術通過建立多分辨率網格模型,根據視點距離動態調整模型精度。如圖1所示,當視點遠離物體時,系統自動切換至低多邊形版本,顯著降低渲染負載。
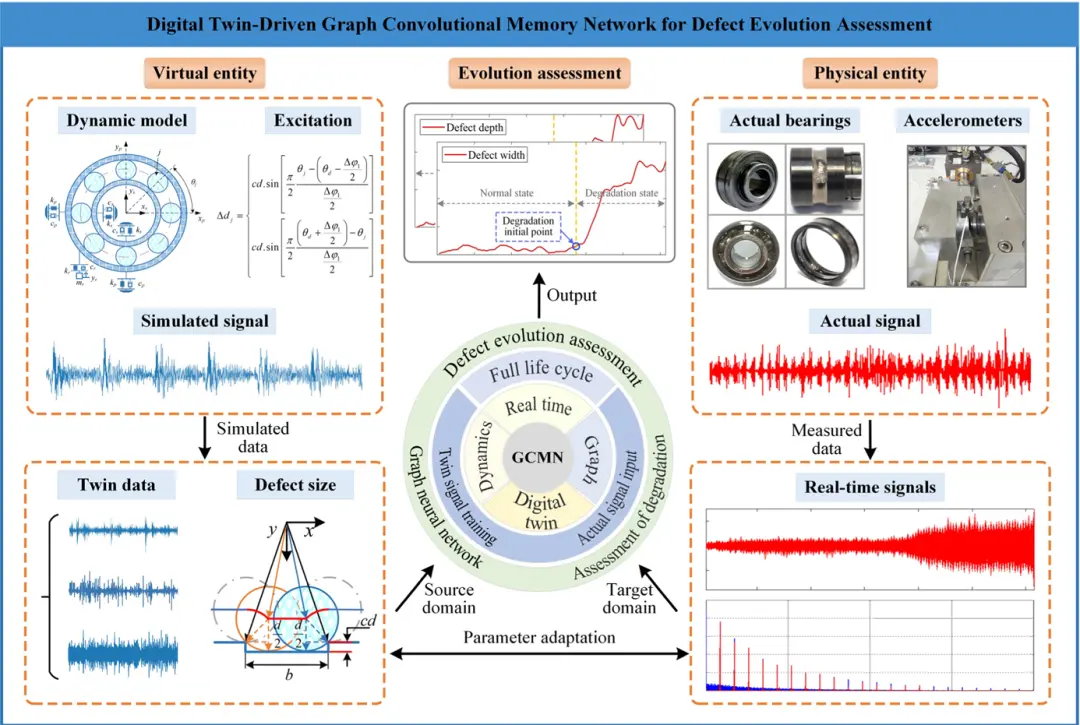
其技術實現基於以下公式進行細節層級決策:
其中d表示視點距離,d_0為基準距離參數。該算法可減少高達70%的頂點處理量。
2.2 可見性裁剪與遮擋剔除
基於層次Z緩衝算法,引擎通過預計算場景的八叉樹空間索引,快速確定可見對象集。實驗表明,該方法在複雜工業場景中可剔除超過60%的不可見面片。
2.3 實例化渲染優化
針對重複性結構(如工業園區管道、建築羣),採用GPU實例化渲染技術。通過單次Draw Call繪製多個相似對象,顯著降低CPU至GPU的數據傳輸開銷。如表1所示,實例化技術可使渲染性能提升3-5倍。
3 凡拓數創FTE引擎創新實踐
凡拓數創的FTE數字孿生引擎通過動態負載均衡技術,實現了多線程渲染管線的優化。引擎採用任務並行化架構,將場景圖遍歷、材質計算、陰影生成等任務分配到多個工作線程,充分發揮多核CPU性能。


在內存管理方面,FTE引擎實現了智能資源池機制,通過預測性加載和LRU淘汰策略,維持顯存使用率在安全閾值內。該技術使引擎能夠支持超過100GB的三維模型數據實時瀏覽。

4 技術驗證與性能分析
通過基準測試表明,優化後的渲染引擎在相同硬件條件下,幀率提升達2.3倍,CPU利用率從原有的45%提升至78%。如圖2所示,在應對大規模城市級數字孿生場景時,引擎仍能保持流暢的交互體驗。
5 結論與展望
數字孿生渲染引擎的優化是一個系統工程,需要從算法、架構、資源管理等多個維度進行協同創新。隨着硬件技術的不斷髮展,特別是光線追蹤硬件加速的普及,數字孿生引擎將向更逼真、更實時的方向演進。
未來,結合神經網絡渲染等AI技術,數字孿生引擎有望實現質量與性能的進一步突破,為各行業應用提供更強大的技術支持。