









- 消息隊列
- MQ的本質
- 原始模型的進化
- 隊列模型
- 發佈-訂閲模型
- 小結
- RabbitMQ
- Rabbit安裝流程
- 名詞解釋
- channel信道
- exchange交換機和綁定routing key
- 隊列(queue)
- 持久化(duration)
- 確認機制(ack)
- Rabbit的六種工作模式
- simple簡單模式
- work工作模式(資源的競爭)
- publish/subscribe發佈訂閲(共享資源)
- routing路由模式
- topic主題模式(路由模式的一種)
- RPC模式
- 消息確認機制
- 事務機制
- confirm模式
- 開啓confirm模式的方法
- 編程模式
- 消息延時發送機制
- 死信隊列
- 什麼時候消息會變為死信隊列
- 死信隊列得原理
- 延時插件
- 如何實現
- 死信隊列
消息隊列
MQ的本質
MQ的本質 大概地講就是「一發一存一消費」,在直白點就是一個「轉發器」
生產者先將消息投遞到一個叫做「隊列」的容器中,然後再從這個容器中取出消息,最後再轉發給消費者,僅此而已
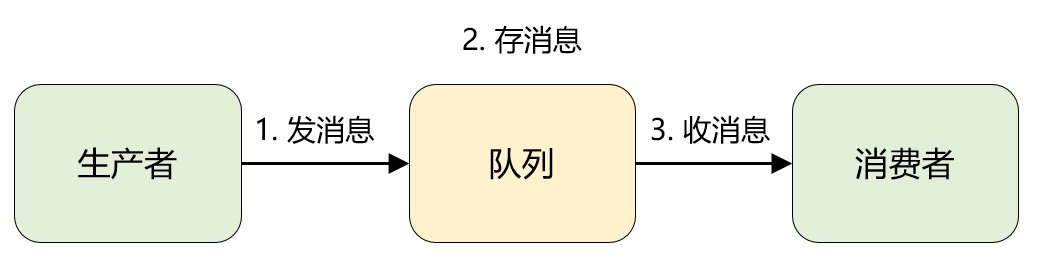
關鍵字:消息和隊列
1.消息:就是要傳輸的數據,可以是最簡單的文本字符串,也可以是自定義的複雜格式(只要能按預定格式解析出來即可)
2.隊列:是一種先進先出數據結構。它是存放消息的容器,消息從隊尾入隊,從對頭出隊,入隊即發消息的過程,出隊即收消息的過程。
原始模型的進化
如今我們最常用的消息隊列產品(RocketMQ,Kafka等等),你會發現:它們都在最原始的消息模型上做了擴展,同時提出了一些新名詞,比如:主題(topic),分區(partition),隊列(queue)等等
隊列模型
最初的消息隊列就是上一節講的原始模型,它是一個嚴格意義上的隊列(Queue)。消息按照什麼順序寫進去,就按照什麼順序讀出來。不過隊列沒有"讀"這個操作,讀就是出隊,從隊頭中"刪除"這個消息。

這便是隊列模型:它允許多個生產者往同一消息隊列發送消息。但是,如果有多個消費者,實際上是競爭的關係,依舊是一條消息只能被其中一個消費者接收到,讀完即被刪除
發佈-訂閲模型
如果需要將一份消息數據分發給多個消費者,並且每個消費者都要求收到全量的數據。隊列模型則無法滿足這個需求了
一個可行的方案是:為每個消費者創建 一個單獨的隊列,讓生產者發送多份。相當於需要讓你通知一個部門的人,而你一個一個去通知,每份通知都需要複製 ,發送 。 這種做法比較笨,而且同一份數據會被複制多份,也很浪費空間
為了解決這種問題,就演化了另外一種消息模型:發佈-訂閲模型
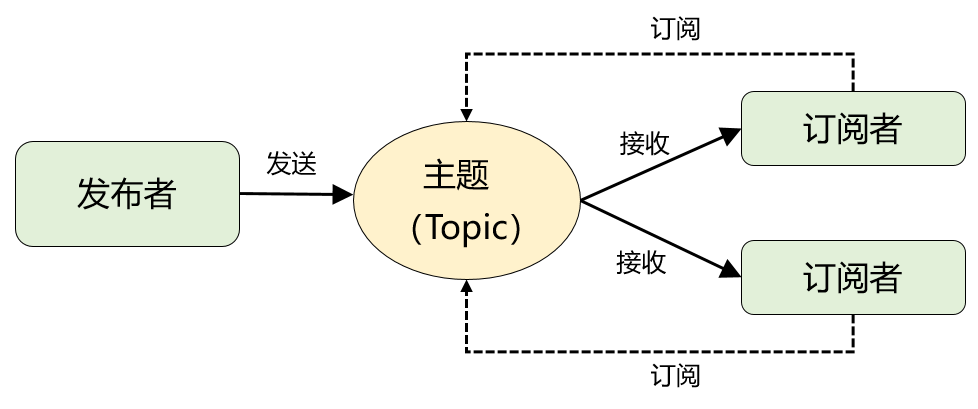
在發佈-訂閲模型中,存放消息的容器變成了"主題",訂閲者在接收消息之前需要先"訂閲主題"。最終,每個訂閲者都可以收到同一個主題的全量信息
仔細對比下它和"隊列模型"的異同:生產者就是發佈者,隊列就是主題,消費者就是訂閲者,無本質區別。唯一的不同點在於:一份消息數據是否可以被多次消費
小結
目前MQ的應用場景非常多,例如:系統解耦,異步通信和流量削峯。除此之外,還有延遲通知,最終一致性保證,順序消息,流式處理等等。
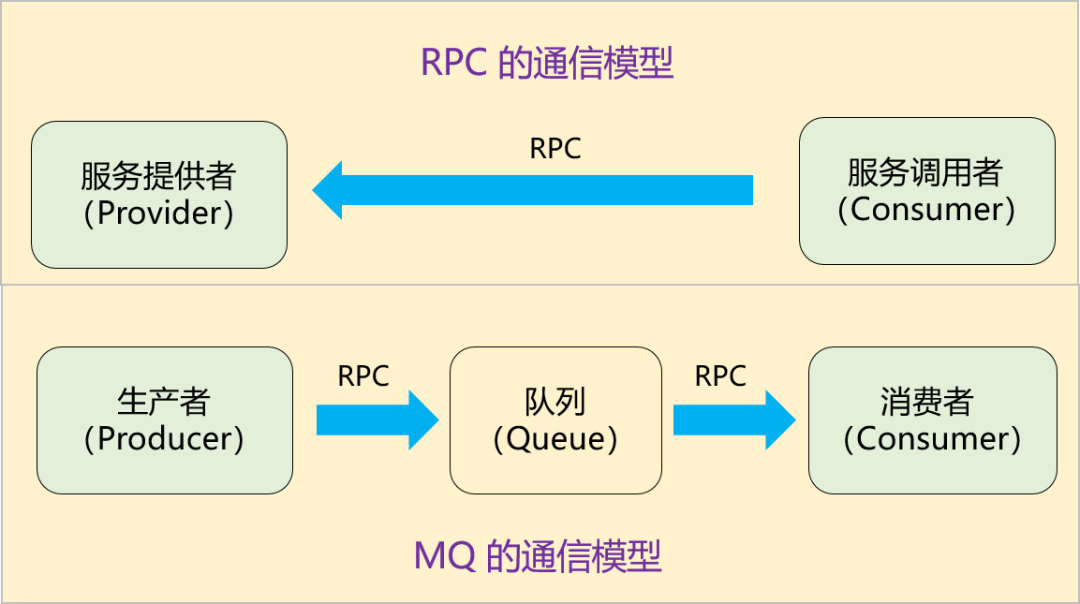
通過對比,能很明顯地看出兩點差異:
1.引入MQ後,由之前的一次RPC變成了現在的兩次RPC,而且生產者只跟隊列耦合,它根本無需知道消費者的存在。
2.多了一箇中間節點「隊列」進行消息轉儲,相當於將同步變成了異步。
舉一個實際例子,比如説電商業務中最常見的「訂單支付」場景:在訂單支付成功後,需要更新訂單狀態、更新用户積分、通知商家有新訂單、更新推薦系統中的用户畫像等等。

引入 MQ 後,訂單支付現在只需要關注它最重要的流程:更新訂單狀態即可。其他不重要的事情全部交給 MQ 來通知。這便是 MQ 解決的最核心的問題:系統解耦。
改造前訂單系統依賴 3 個外部系統,改造後僅僅依賴 MQ,而且後續業務再擴展(比如:營銷系統打算針對支付用户獎勵優惠券),也不涉及訂單系統的修改,從而保證了核心流程的穩定性,降低了維護成本。
這個改造還帶來了另外一個好處:因為 MQ 的引入,更新用户積分、通知商家、更新用户畫像這些步驟全部變成了異步執行,能減少訂單支付的整體耗時,提升訂單系統的吞吐量。這便是 MQ 的另一個典型應用場景:異步通信。
除此以外,由於隊列能轉儲消息,對於超出系統承載能力的場景,可以用 MQ 作為 “漏斗” 進行限流保護,即所謂的流量削峯。
我們還可以利用隊列本身的順序性,來滿足消息必須按順序投遞的場景;利用隊列 + 定時任務來實現消息的延時消費 ……
以上筆記感謝作者3y 原網址:https://mp.weixin.qq.com/s/3h-pN8qS1ex36LgXMFVOSw
RabbitMQ
RabbitMQ是消息代理:它接收並轉發消息。您可以將其視為郵局,將您要發佈的郵件放在郵箱中,可以確保最終將郵件傳遞給您的收件人。以此類推,RabbitMQ是一個郵政信箱,一個郵局和一個郵遞員
RabbitMQ與郵局之間的主要區別在於,它不處理紙張,而是接收,存儲和轉發數據消息的二進制斑點
Rabbit安裝流程
rabbitmq是erlang語言編寫的,安裝rabbitmq之前,需要先安裝erlang,這裏用erlang的源碼進行安裝,erlang安裝包官網下載地址:http://erlang.org/download/
wget http://erlang.org/download/otp_src_21.1.tar.gz
tar -zxvf otp_src_21.1.tar.gz
cd otp_src_21.1
# 這裏要新建一個erlang文件夾,因為erlang編譯安裝默認是裝在/usr/local下的bin和lib中,這裏我們將他統一裝到/usr/local/erlang中,方便查找和使用。
mkdir -p /usr/local/erlang
# 在編譯之前,必須安裝以下依賴包
yum install -y make gcc gcc-c++ m4 openssl openssl-devel ncurses-devel unixODBC unixODBC-devel java java-devel
./configure --prefix=/usr/local/erlang
erlang語言需要依賴於java環境,如果不安裝java環境,會報錯:Java compiler disabled by user
直接執行make&&makeinstall進行編譯安裝
make && make install
安裝後,在usr/local/erlang中就會出現如下:
然後將/usr/local/erlang/bin這個文件夾加入到環境變量中,加載以下即可直接使用.
vim /etc/profile # 編輯環境變量
######### 添加如下內容 ###############
PATH=$PATH:/usr/local/erlang/bin
########################################
source /etc/profile # 重新加載環境變量
到此,即按照完成,直接輸入erl,得到如下圖則按照成功

安裝完成之後,就可以安裝rabbitmq了,安裝之前需要去官網查看一下rabbitmq版本對erlang版本的一個支持情況,官網地址:http://www.rabbitmq.com/which-erlang.html
為了方便安裝,最好直接使用編譯好的二進制文件包,即開即用,不用進行復雜的yum配置等。具體可以參考官方文檔:http://www.rabbitmq.com/install-generic-unix.html
# 下載源碼包
wget https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.7.8/rabbitmq-server-generic-unix-3.7.8.tar.xz
# 解壓
tar -xvf rabbitmq-server-generic-unix-3.7.8.tar.xz -C /usr/local/
# 添加環境變量
vim /etc/profile
------ 添加如下內容 ------
PATH=$PATH:/usr/local/rabbitmq_server-3.7.8/sbin
# 重載一下環境變量
source /etc/profile
# 添加web管理插件
rabbitmq-plugins enable rabbitmq_management
默認rabbitmq是沒有配置文件的,需要去官方github上,複製一個配置文件模版過來,最新的3.7.0以上的版本可以使用新的key-value形式的配置文件rabbitmq.conf,和原來erlang格式的advanced.config相結合,解決一下key-value形式不好定義的配置。github地址:https://github.com/rabbitmq/rabbitmq-server/tree/v3.7.8/docs 將配置文件複製到/usr/local/rabbitmq_server-3.7.8/etc/rabbitmq/下
然後,就可以啓動rabbitmq服務了
# 後台啓動rabbitmq服務
rabbitmq-server -detached
rabbitmqctl stop # 停止服務
rabbitmq-plugins list #可以列出插件列表
上面啓用了rabbitmq的管理插件,會有一個web管理界面,默認監聽端口15672,將此端口在防火牆上打開,則可以訪問web頁面:
使用默認的用户 guest / guest (此也為管理員用户)登陸,會發現無法登陸,報錯:User can only log in via localhost。那是因為默認是限制了guest用户只能在本機登陸,也就是隻能登陸localhost:15672。可以通過修改配置文件rabbitmq.conf,取消這個限制: loopback_users這個項就是控制訪問的,如果只是取消guest用户的話,只需要loopback_users.guest = false 即可。
之後,就看可以登錄到rabbitmq的web管理界面
名詞解釋
channel信道
信道是生產消費者與rabbit通信的渠道,生產者publish或是消費者subscribe一個隊列都是通過信道來通信的。信道是建立在TCP連接上的虛擬連接,rabbitmq在一條TCP上建立成百上千個信道來達到多個線程處理,這個TCP被多個線程共享,每個線程對應一個信道,信道在rabbit都有唯一的ID,保證了信道私有性,對應上唯一的線程使用
疑問:為什麼不建立多個TCP連接呢?
原因是rabbit保證性能,系統為每個線程開闢一個TCP是非常消耗性能, 每秒成百上千的建立銷燬TCP會嚴重消耗系統。所以rabbitmq選擇建立多個信道(建立在tcp的虛擬連接) 連接到rabbit上。 類似概念:TCP是電纜,信道就是裏面的光纖,每個光纖都是獨立的,互不影響。
exchange交換機和綁定routing key
exchange的作用就是類似路由器,routing key就是路由鍵,服務器會根據路由鍵將消息從交換機路由到隊列上去
exchange有多個種類,常用的有direct,fanout,topic。前三種類似集合對應關係那樣,(direct)1:1,(fanout)1:N,(topic)N:1
direct:類似完全匹配
fanout:可以把一個消息並行發佈到多個隊列上去,簡單的説就是,當多個隊列綁定到fanout的交換機,那麼交換器一次性拷貝多個消息分別發送到綁定的隊列上,每個隊列有這個消息的副本
ps:這個可以在業務上實現並行處理多個任務,比如,用户上傳圖片功能,當消息到達交換器上,它可以同時路由到積分 增加隊列和其它隊列上,達到並行處理的目的,並且易擴展,以後有什麼並行任務的時候,直接綁定到fanout交換器 不需求改動之前的代碼。
topic:多個交換機可以路由消息到同一個隊列。根據模糊匹配,比如一個隊列的routing key為*.test,那麼凡是到達交換器的消息中的routing key後綴.test都被路由到這個隊列上
隊列(queue)
1.推模式:通過AMQP的basic.consume命令訂閲,有消息會自動接收,吞吐量高
2.拉模式:通過AMQP的basic.get命令
注:當隊列擁有多個消費者時,隊列收到的消息將以循環的方式發送給消費者。每條消息只會發送給一個訂閲的消費者
持久化(duration)
開啓持久化功能,需同時滿足:消息投遞模式選擇持久化,交換器開啓持久化,隊列開啓持久化
確認機制(ack)
1.發送方確認模式:消息發送到交換器—發送完畢—>消息投遞到隊列或持久化到磁盤異步回調通知生產者
2.消費者確認機制:消息投遞消費者—ack—刪除該條消息—投遞下一條
注:收到ACK前,不會把消息再次發送給該消費者,但是會把下一條消息發送給其他消費者
Rabbit的六種工作模式
simple簡單模式
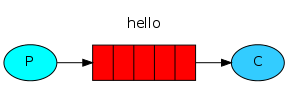
1.生產者產生消息,將消息放入隊列
2.消息的消費者(consumer)監聽 消息隊列,如果隊列中有消息,就消費掉,消息被拿走後,自動從隊列中刪除(隱患 消息可能沒有被消費者正確處理,已經從隊列中消失了,造成消息的丟失,這裏可以設置成手動的ack,但如果設置成手動ack,處理完後要及時ack消息給隊列,否則會造成內存溢出)
work工作模式(資源的競爭)
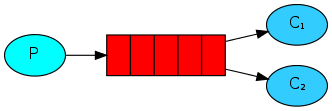
1.消息產生者將消息放入隊列消費者可以有多個,消費者1,消費者2同時監聽一個隊列,消息被消費。C1,C2共同爭搶當前的消息隊列內容,誰先拿到誰負責消費消息(隱患:高併發情況下,默認會產生某一個消息被多個消費者共同使用,可以設置一個開關(syncronize)保證一條消息只能被一個消費者使用)
publish/subscribe發佈訂閲(共享資源)
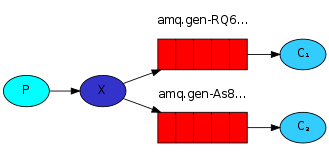
1.每個消費者監聽自己的隊列
2.生產者將消息發給broke,由交換機將消息轉發到綁定此交換機的每個隊列,每個綁定交換機的隊列都將接收到消息
routing路由模式
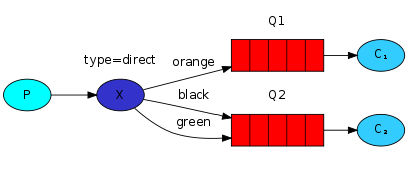
1.消息生產者將消息發送給交換機按照路由判斷,路由是字符串(info) 當前產生的消息攜帶路由字符(對象的方法),交換機根據路由的key,只能匹配上路由key對應的消息隊列,對應的消費者才能消費消息;
2.根據業務功能定義路由字符串
3.從系統的代碼邏輯中獲取對應的功能字符串,將消息任務扔到對應的隊列中。
4.業務場景:error 通知;EXCEPTION;錯誤通知的功能;傳統意義的錯誤通知;客户通知;利用key路由,可以將程序中的錯誤封裝成消息傳入到消息隊列中,開發者可以自定義消費者,實時接收錯誤;
topic主題模式(路由模式的一種)
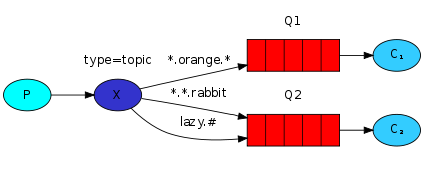
1.星號井號代表通配符
2.星號代表多個單詞,井號代表一個單詞
3.路由功能添加模糊匹配
4.消息產生者產生消息,把消息交給交換機
5.交換機根據key的規則模糊匹配到對應的隊列,由隊列的監聽消費者接收消息消費
(在我的理解看來就是routing查詢的一種模糊匹配,就類似sql的模糊查詢方式)
RPC模式
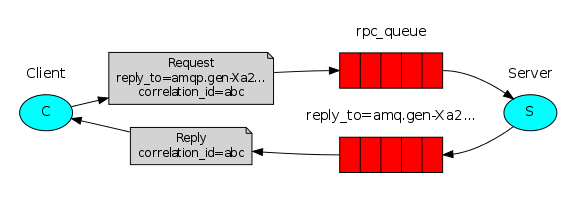
消息確認機制
事務機制
RabbitMQ中與事務機制有關的方法有三個:txSelect(),txCommit()以及txRollback(),txSelect()用於將當前channel設置成transaction模式,txCommit用於提交事務,txRollback用於回滾事務,在通過txSelect開啓事務之後,我們便可以發佈消息給broke代理服務器了,如果txCommit提交成功了,則消息一定到達了broke了,如果在txCommit執行之前broke異常崩潰或者由於其他原因拋出異常,這個時候我們便可以捕獲異常通過txRollback回滾事務
channel.txSelect();
channel.basicPublish(ConfirmConfig.exchangeName,ConfirmConfig.routingKey,MessageProperties.PERSISTENT_TEXT_PLAIN,ConfirmConfig.msg_10B.getBytes());
channel.txCommit();
事務回滾代碼如下:
try {
channel.txSelect();
channel.basicPublish(exchange, routingKey, MessageProperties.PERSISTENT_TEXT_PLAIN, msg.getBytes());
int result = 1 / 0;
channel.txCommit();
} catch (Exception e) {
e.printStackTrace();
channel.txRollback();
}
confirm模式
上面我們介紹了RabbitMQ可能會遇到的一個問題,即生成者不知道消息是否真正到達broker,隨後通過AMQP協議層面為我們提供了事務機制解決了這個問題,但是採用事務機制實現會降低RabbitMQ的消息吞吐量,那麼有沒有更加高效的解決方式呢?答案是採用Confirm模式。
生產者將信道設置成confirm模式,一旦信道進入confirm模式,所有在該信道上面發佈的消息都會被指派一個唯一的ID(從1開始),一旦消息被投遞到所有匹配的隊列之後,broker就會發送一個確認給生產者(包含消息的唯一ID),這就使得生產者知道消息已經正確到達目的隊列了,如果消息和隊列是可持久化的,那麼確認消息會將消息寫入磁盤之後發出,broker回傳給生產者的確認消息中deliver-tag域包含了確認消息的序列號,此外broker也可以設置basic.ack的multiple域,表示到這個序列號之前的所有消息都已經得到了處理。
confirm模式最大的好處在於他是異步的,一旦發佈一條消息,生產者應用程序就可以在等信道返回確認的同時繼續發送下一條消息,當消息最終得到確認之後,生產者應用便可以通過回調方法來處理該確認消息,如果RabbitMQ因為自身內部錯誤導致消息丟失,就會發送一條nack消息,生產者應用程序同樣可以在回調方法中處理該nack消息。
在channel 被設置成 confirm 模式之後,所有被 publish 的後續消息都將被 confirm(即 ack) 或者被nack一次。但是沒有對消息被 confirm 的快慢做任何保證,並且同一條消息不會既被 confirm又被nack
開啓confirm模式的方法
生產者通過調用channel的confirmSelect方法將channel設置為confirm模式,如果沒有設置no-wait標誌的話,broker會返回confirm.select-ok表示同意發送者將當前channel信道設置為confirm模式(從目前RabbitMQ最新版本3.6來看,如果調用了channel.confirmSelect方法,默認情況下是直接將no-wait設置成false的,也就是默認情況下broker是必須回傳confirm.select-ok的)。
已經在transaction事務模式的channel是不能在設置成confirm模式的,即這兩種模式不能共存的
編程模式
對於固定消息體大小和線程數,如果消息持久化,生產者confirm(或者採用事務機制),消費者ack那麼對性能有很大的影響.
消息持久化的優化沒有太好方法,用更好的物理存儲(SAS, SSD, RAID卡)總會帶來改善。生產者confirm這一環節的優化則主要在於客户端程序的優化之上。歸納起來,客户端實現生產者confirm有三種編程方式:
普通confirm模式:每發送一條消息後,調用waitForConfirms()方法,等待服務器端confirm。實際上是一種串行confirm了。
批量confirm模式:每發送一批消息後,調用waitForConfirms()方法,等待服務器端confirm。
異步confirm模式:提供一個回調方法,服務端confirm了一條或者多條消息後Client端會回調這個方法。
消息延時發送機制
死信隊列
什麼時候消息會變為死信隊列
1.消息被否定接收,消費者使用basic.reject或者basic.nack並且requeue重回隊列屬性設為false
2.消息在隊列裏得時間超過了該消息設置得過期時間(TTL)
3.消息隊列到達了它的最大長度,之後再收到得消息
死信隊列得原理
當一個消息再隊列裏變為死信時,它會被重新publish到另一個exchange交換機上,這個exchange就為DLX。因此我們只需要再聲明正常得業務隊列時添加一個可選的”x-dead-letter-exchange“參數,值為死信交換機,死信就會被rabbitmq重新publish到配置的這個交換機上,我們接着監聽這個交換機就可以了。
延時插件
RabbitMQ Delayed Message Plugin是一個rabbitmq的插件,所以使用前需要安裝它,可以參考的GitHub地址:https://github.com/rabbitmq/rabbitmq-delayed-message-exchange
如何實現
1.安裝好插件後只需要聲明一個類型type為"x-delayed-message"的exchange,並且在其可選參數下配置一個key為"x-delayed-typ",值為交換機類型(topic/direct/fanout)的屬性。
2.聲明一個隊列綁定到該交換機
3.在發送消息的時候消息的header裏添加一個key為"x-delay",值為過期時間的屬性,單位毫秒。
4.代碼就在上面,配置類為DMP開頭的,發送消息的方法為send2()。
5.啓動後在rabbitmq控制枱可以看到一個類型為x-delayed-message的交換機。
6.繼續再瀏覽器中發送兩個請求http://localhost:4399/send2?msg=消息A&time=30和http://localhost:4399/send2?msg=消息B&time=10,這樣不會出現死信隊列出現的問題
Activemq和Rabbitmq的區別?
-
Activemq它實現的是JMS協議(Java消息協議)
-
Rabbitmq實現的是AMQP協議(高級消息隊列協議)
-
Activemq是Java寫的
-
Rabbitmq是Erlang寫的,吞吐更多,延時更低
