

你是小阿巴,正在公司敲代碼。
老闆走過來説:小阿巴,給咱們網站加個商品搜索功能吧。
你拍拍胸脯:沒問題,我直接用 MySQL 數據庫的 LIKE 模糊查詢實現搜索,1 小時上線~
結果上線後,用户點擊搜索,卡了半天沒反應,老闆氣得臉都綠了。
你急的汗流浹背,只能找到號稱『後端之狗』的魚皮求助:阿巴阿巴,俺用 MySQL 搞不定,咋辦啊……
魚皮:不是哥們,又不是隻有 MySQL 這一個數據庫。
下面我來帶你認識 10 種不同類型的數據庫,讓你知道什麼場景該用什麼數據庫。

點個收藏,我們開始~
⭐️ 推薦觀看視頻版,有動畫更好理解:https://www.bilibili.com/video/BV1ChkjBsEzq
關係型數據庫
首先是我們接觸最多的、也是後端入門必學的 關係型數據庫。
在關係型數據庫中,數據以 表 的形式進行組織和存儲,每個表就像一個 Excel 表格,包含多個 行 和多個 列。
比如你要做個學生管理系統,把學生信息存儲到關係型數據庫中,結構大概是這樣的:
| 學號 | 學生姓名 | 所屬班級號 |
|---|---|---|
| 1 | 小李 | 1 |
| 2 | 小魚 | 2 |
| 3 | 小皮 | 3 |
上述學生表格中,每一行代表一個學生的信息,每一列代表學生的一個屬性。
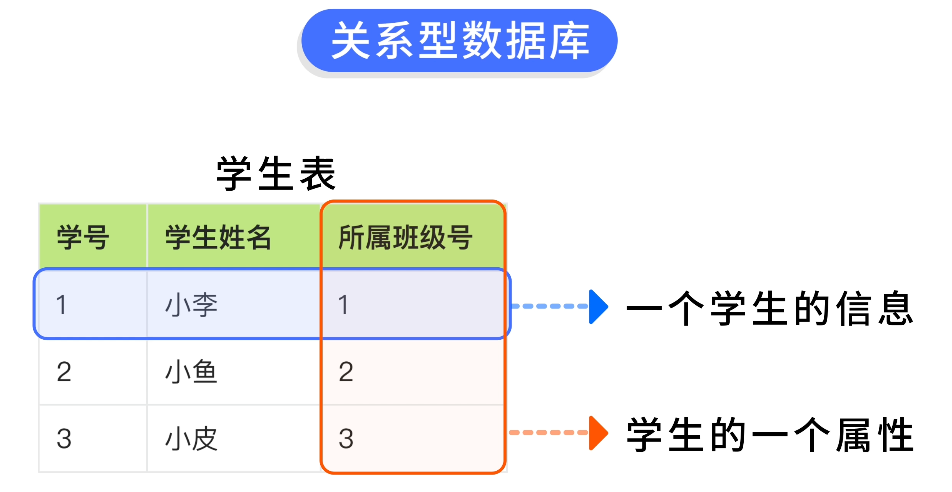
我們可以使用結構化查詢語言 SQL 來對關係型數據庫表的數據進行靈活地查詢、選擇、過濾等。

而關係型數據庫最大的特點,就是表和表之間可以 存在關係。比如學生管理系統中還可以有班級表,結構如下:
| 班號 | 班級名稱 |
|---|---|
| 1 | 快樂班 |
| 2 | 泰酷班 |
| 3 | 躺平班 |
如果我想知道某個學生所屬的班級信息,只需要在查詢時將學生表的 所屬班級號 和班級表的 班號 進行關聯,而不用把所有表格的列存儲在一起,非常靈活。

通過 SQL 可以連接查詢多張表:
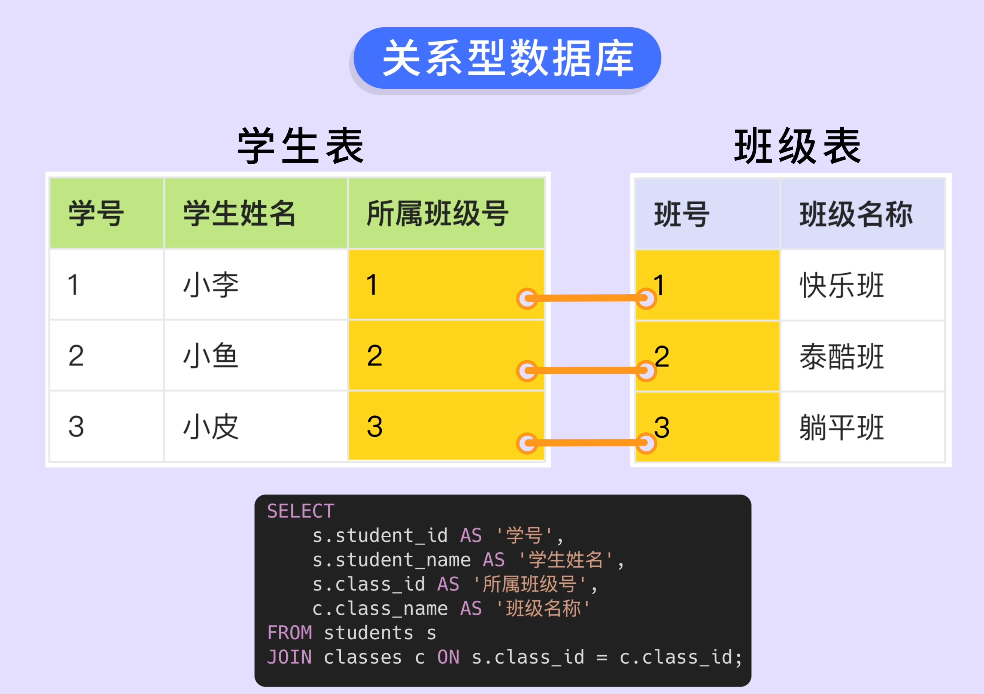
得到下面的查詢結果:
| 學號 | 學生姓名 | 所屬班級號 | 班級名稱 |
|---|---|---|---|
| 1 | 小李 | 1 | 快樂班 |
| 2 | 小魚 | 2 | 泰酷班 |
| 3 | 小皮 | 3 | 躺平班 |
此外,關係型數據庫遵循 ACID 原則(原子性、一致性、隔離性和持久性),通過 事務 機制可以保證多個操作同時進行時,數據的狀態保持一致。
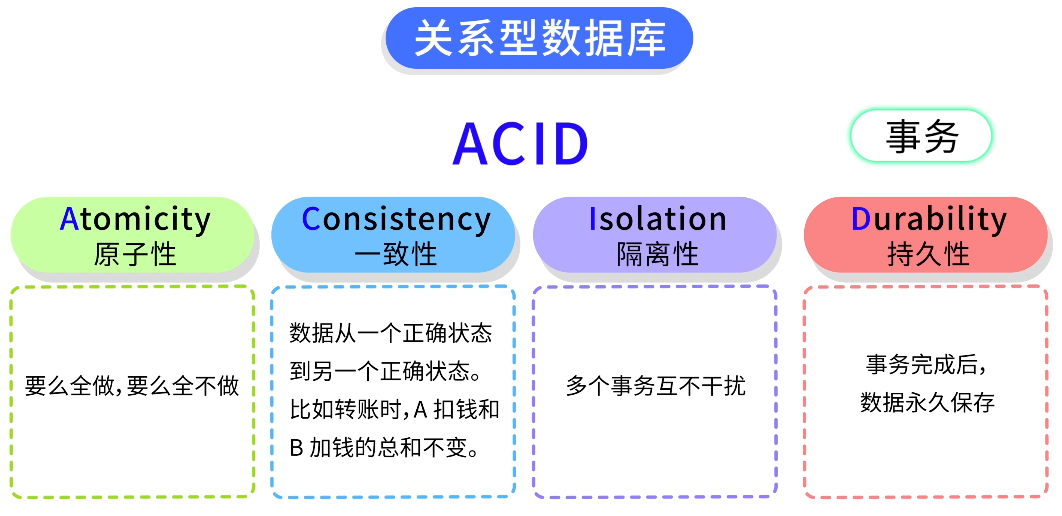
舉個例子,A 給 B 轉賬,A 扣錢的同時 B 也會加錢,不會出現 A 扣了錢 B 卻沒收到錢的情況。

正因為關係型數據庫既能靈活查詢、又能準確寫入,所以它幾乎可以被應用在任何項目中。比如各類管理系統、數據分析系統、金融銀行系統等。
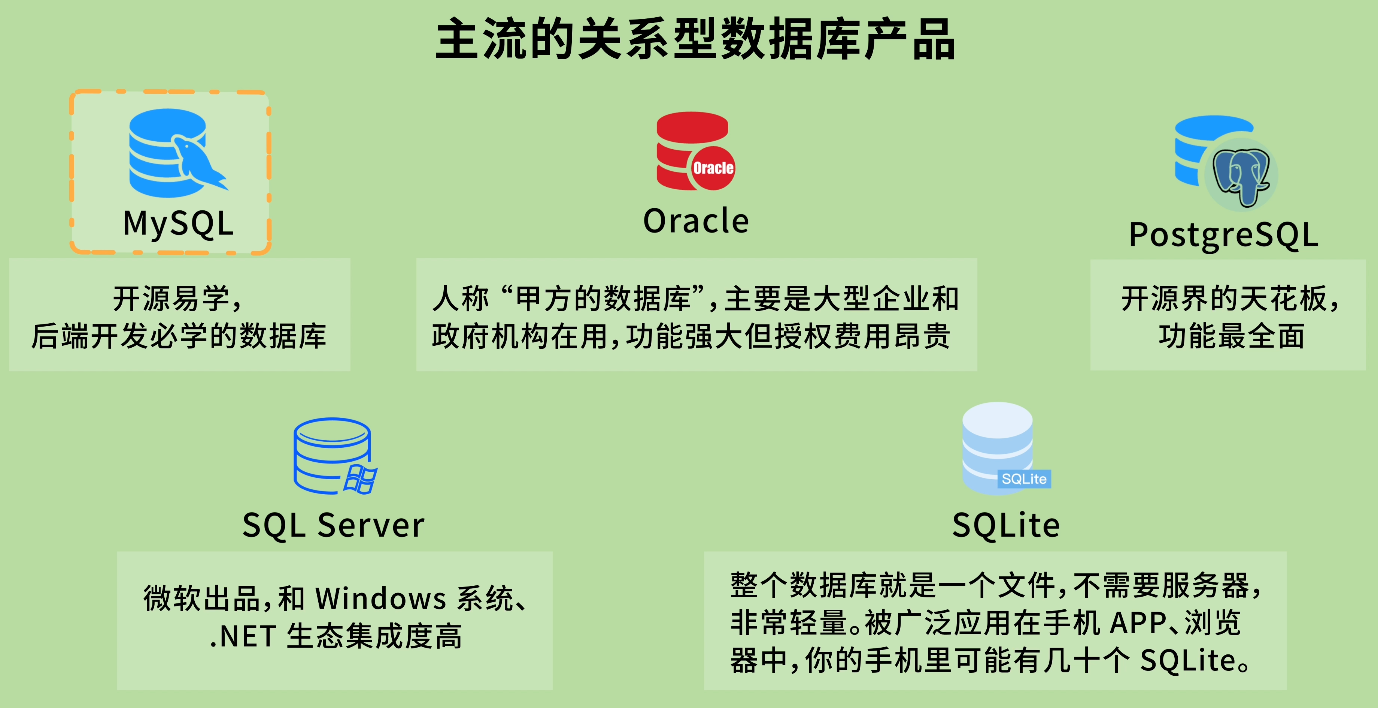
比較主流的關係型數據庫產品有:
-
MySQL:開源易學,後端開發必學的數據庫
-
Oracle:人稱 “甲方的數據庫”,主要是大型企業和政府機構在用,功能強大但授權費用昂貴
-
PostgreSQL:開源界的天花板,功能最全面
-
SQL Server:微軟出品,和 Windows 系統、.NET 生態集成度高
-
SQLite:整個數據庫就是一個文件,不需要服務器,非常輕量。被廣泛應用在手機 APP、瀏覽器中,你的手機裏可能有幾十個 SQLite。
對於大多數項目,用 MySQL 等關係型數據庫來存儲數據就足夠了。但如果要存儲的數據間沒有複雜關係、或者需要極致的性能時,它並不是最佳選擇。
你點點頭:俺知道,就好比俺要寫一篇文章,沒必要非得把內容塞進 Excel 表格裏,直接放到 Word 文檔裏會更方便編輯和閲讀。

魚皮:沒錯,這時就需要與關係型數據庫互補的 非關係型數據庫。
非關係型數據庫
非關係型數據庫又叫 NoSQL(Not Only SQL),適合存儲關係不強的、結構靈活的、需要快速訪問的數據。
打個比方,關係型數據庫像圖書館,書籍分類明確、擺放有序、借閲有規矩;非關係型數據庫像你的書桌,怎麼順手怎麼放,拿取方便最重要。

在實際項目開發中,最常用的非關係型數據庫是 KV 數據庫和文檔數據庫。
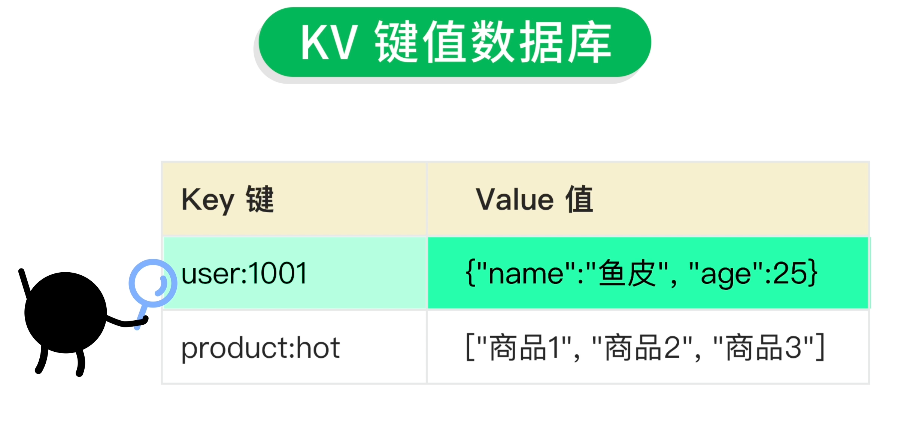
KV 鍵值數據庫
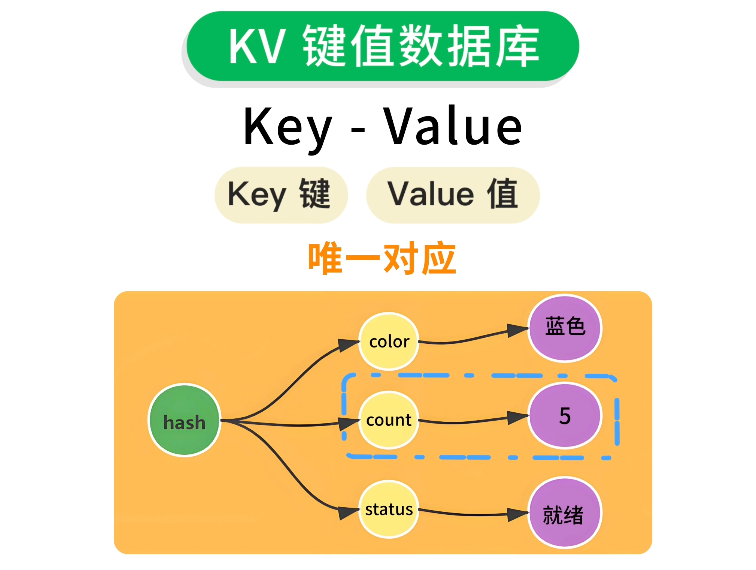
KV 即 Key-Value,數據是以 鍵值對 的方式存儲在數據庫中的,可以理解為一個超大的 HashMap,數據庫中存儲的每個鍵都 唯一對應 一個值。
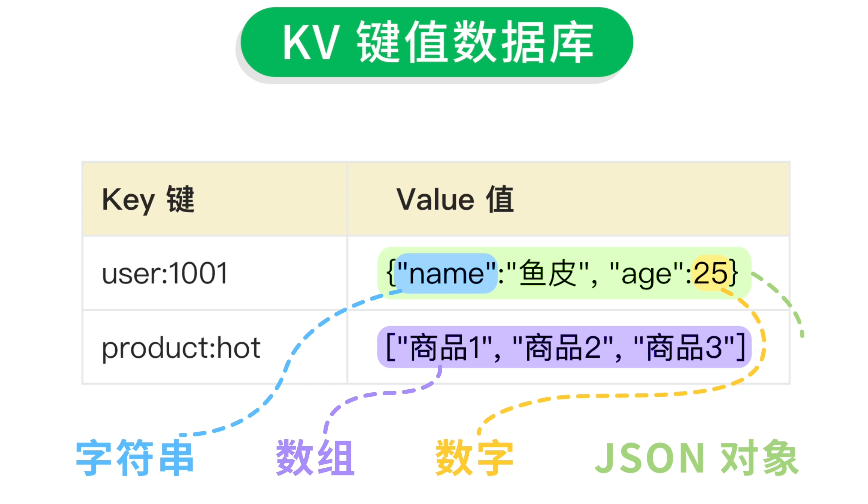
比如存儲用户信息和熱門商品信息,結構是這樣的:
| Key 鍵 | Value 值 |
|---|---|
| user:1001 | {"name":"魚皮", "age":25} |
| product:hot | ["商品1", "商品2", "商品3"] |
鍵和值都可以是任意類型的數據,包括字符串、數字、數組、JSON 對象等,非常靈活。
由於 KV 存儲的結構簡單清晰,我們能夠很輕鬆地根據某個鍵查找出對應的值,就像查字典一樣,讀寫數據的性能都非常高。
此外,KV 數據庫的可擴展性很強。因為數據間不存在直接關聯,我們可以把鍵值對分散到多台機器上存儲,通過數據分片、負載均衡等策略來支持海量數據的高併發訪問。
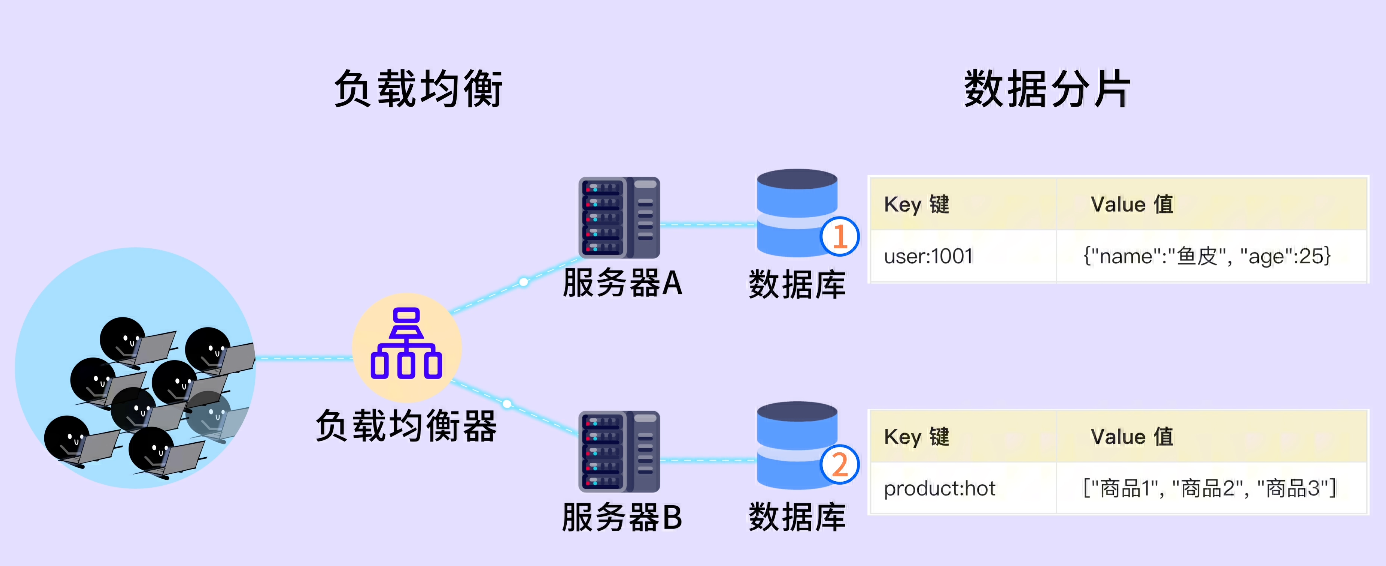
由於高性能和高可擴展性,KV 數據庫被廣泛應用於緩存、分佈式會話、分佈式鎖、實時統計等場景。
最經典的 KV 數據庫肯定是 Redis,它是開源的、基於內存的數據庫,不僅支持豐富的數據類型和功能,還有持久化等重要特性,也是後端必學的技術。其他的常用 KV 數據庫有 Memcached、Etcd、LevelDB、RocksDB 等。

文檔數據庫
文檔數據庫也屬於非關係型數據庫。顧名思義,它適用於存儲和管理 半結構化的 文檔數據,數據一般以 JSON(BSON)格式存儲。

相比於關係型數據庫中嚴格定義的表格行列,文檔數據庫的數據結構更像是一份份獨立的文檔,每個文檔都可以包含不同類型和格式的數據,結構非常靈活。
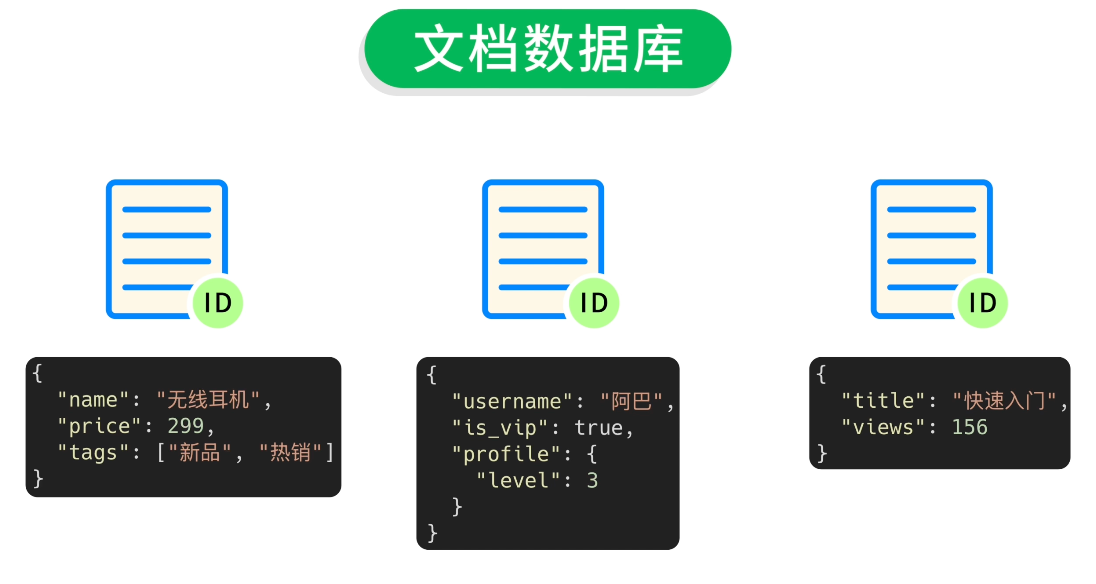
比如存儲博客文章,結構是這樣的:
| 文檔 ID | 文檔數據 |
|---|---|
| 1 | {"_id": 1, "title": "文章標題1", "content": "這是文章1的內容"} |
| 2 | {"_id": 2, "title": "文章標題2", "author": "程序員魚皮"} |
你撓撓頭:誒,文檔 1 和文檔 2 的字段都不一樣啊,這也行?

魚皮:沒錯,這就是文檔數據庫的靈活性。當我們要給某個文檔新增一個字段時,不需要像關係型數據庫那樣先改表結構,直接加就完事了。

而且支持水平擴展,可以分散到多台服務器上存儲,適用於內容管理系統、博客平台、電商商品詳情頁等場景。

推薦學習的文檔數據庫是 MongoDB,因為它存儲的就是 JSON(BSON)格式數據,對前端同學很友好,入門難度也很低。

特定場景的數據庫
雖然關係型和非關係型數據庫已經能夠滿足大部分場景,但在一些特殊場景下,使用專門設計的數據庫會更高效。就像你可以用菜刀砍樹,但用斧子會更快更省力。
搜索引擎數據庫
專門為搜索功能設計的數據庫。它能存儲和管理大量文本數據,提供快速、準確、靈活的全文檢索功能。
你撓撓頭:憑什麼它能做到這些呢?
魚皮:秘密在於它使用了 倒排索引 的方式存儲數據。
以存儲博客文檔為例,關係型數據庫的存儲結構是:
| 文檔 id | 文檔內容 |
|---|---|
| 1 | 感謝關注魚皮 |
| 2 | 魚皮是一名程序員 |
| 3 | 感謝關注編程導航 |
我們能夠根據 id 來查找到對應的單篇文檔,也可以通過搜索精確的關鍵詞,來查找到多篇文檔。
比如搜索 "魚皮",能搜出文檔 1、2。
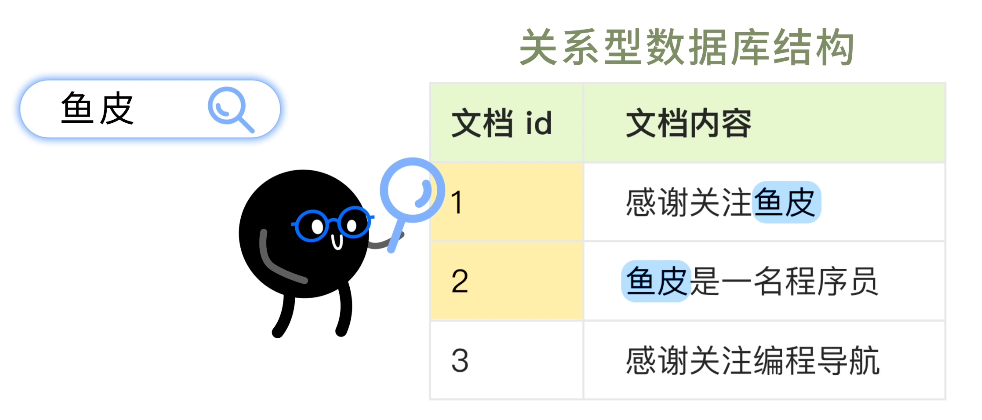
但是,如果你搜索 "魚皮程序員",是無法得到搜索結果的,因為沒有任何一個文檔的內容完全包含 "魚皮程序員" 這個詞。
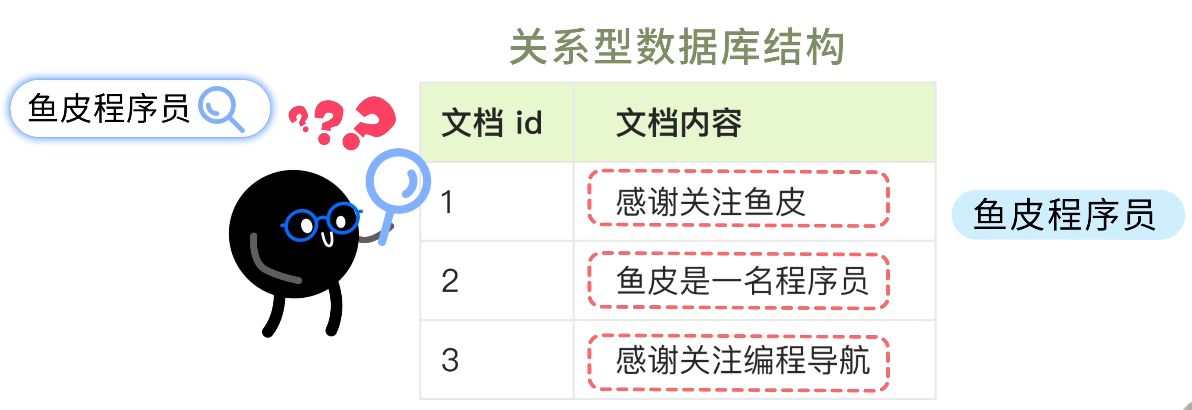
而在搜索引擎數據庫中,首先會將文檔內容按照單詞進行分割,也就是 分詞。然後 建立倒排索引,也就是構建 單詞到文檔 id 的映射。

有了上述的倒排索引,當用户搜索 "魚皮程序員" 時,搜索引擎數據庫會先對搜索詞進行分詞,得到 "魚皮" 和 "程序員",然後根據這兩個詞彙就能找到文檔 id 1 和 2 了。不用再一行一行遍歷表內所有的數據,實現了更靈活、快速的搜索。

此外,搜索引擎數據庫還支持 相關性排序,能夠根據用户的搜索詞對所有搜索結果進行打分,把最相關的文檔排到最上面,就像谷哥度娘那樣。

主流的搜索引擎數據庫技術有 Elasticsearch、Apache Solr 等,建議只學習 Elasticsearch 就夠了,它的社區最活躍、學習資料最豐富。
向量數據庫
向量數據庫是專門用於存儲和處理 高維向量數據 的數據庫,也是 AI 時代最火的數據庫。
你好奇道:啥是向量?
魚皮:簡單來説,向量是一個數字數組,每個數字代表一個 特徵 維度。

舉個例子,在人臉識別系統中,我們需要通過人臉的特徵來判斷是否為同一個人。每張人臉圖像都可以通過 AI 模型轉換成一個向量,這個向量可能包含成百上千個數字,每個數字代表圖像的一個 抽象 特徵維度。

實際上,很難説清楚每個數字代表什麼,但便於理解,你可以 想象 下標 0 代表鼻子大小,下標 1 代表眼睛距離等等,以此類推。

之後通過餘弦相似度等算法來計算兩個向量的相似度,就能判斷出兩張人臉是不是同一個人。

向量數據庫能夠高效存儲這些多維向量數據、快速計算向量的相似度、並實現各種不同算法的相似性搜索。適用於人臉識別、推薦系統、語義搜索等場景。
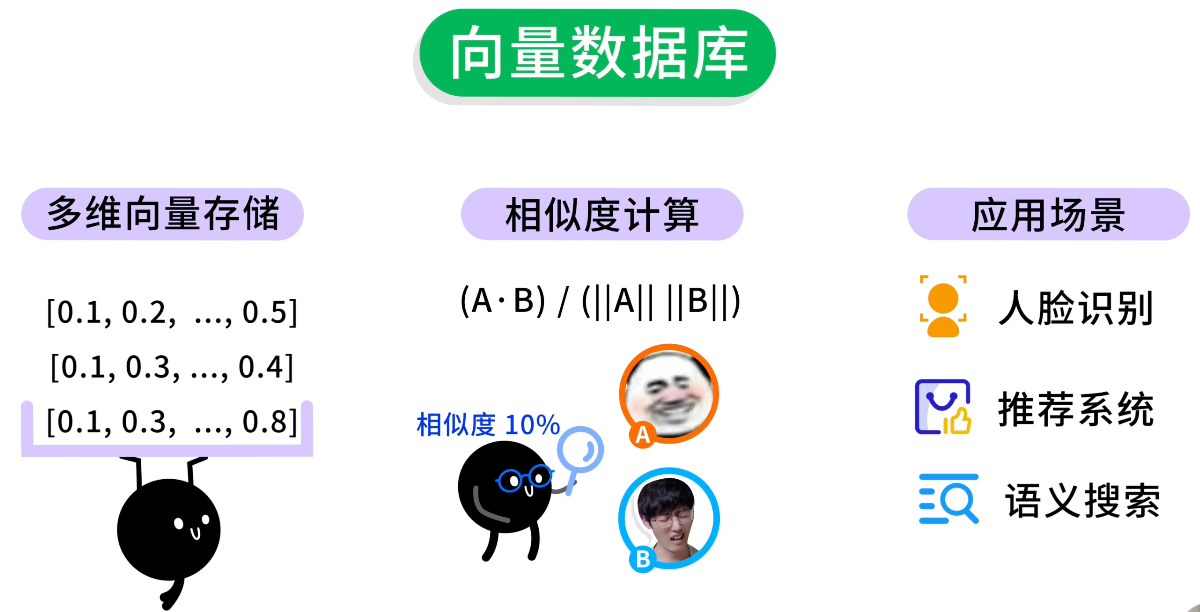
在 AI 時代,可以用向量數據庫給 AI 提供特定領域的知識庫,大大提升回答的準確性。
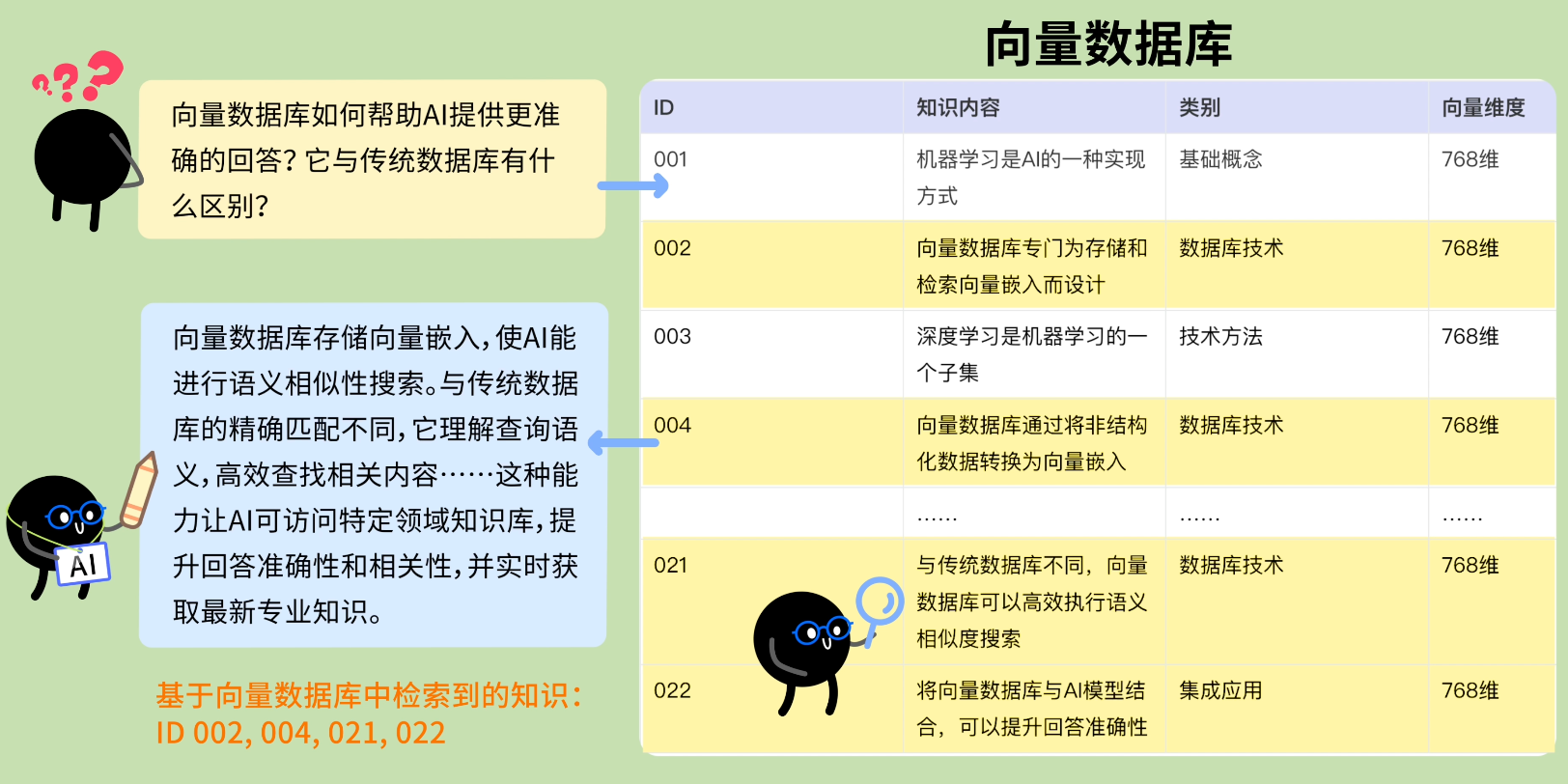
主流的向量數據庫技術有 Milvus、Pinecone 等,像 PostgreSQL 關係型數據庫也通過插件支持存儲向量類型的數據。

圖數據庫
圖數據庫是專門用於存儲和處理 圖結構數據 的數據庫。
注意,這裏的 “圖” 可不是照片或圖表,而是數學中的圖論概念,由節點(Node)和邊(Edge)構成的圖形結構。
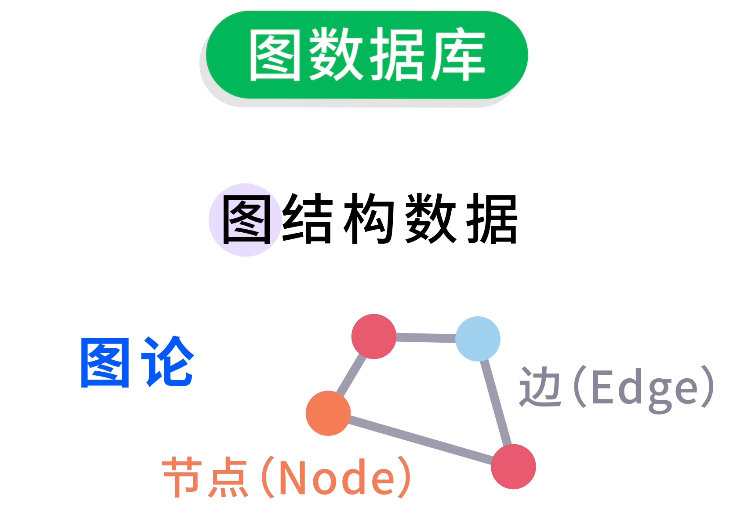
比如我們要存儲一個社交網絡的朋友關係,對應的圖可能是由多個用户節點和好友關係邊組成的。
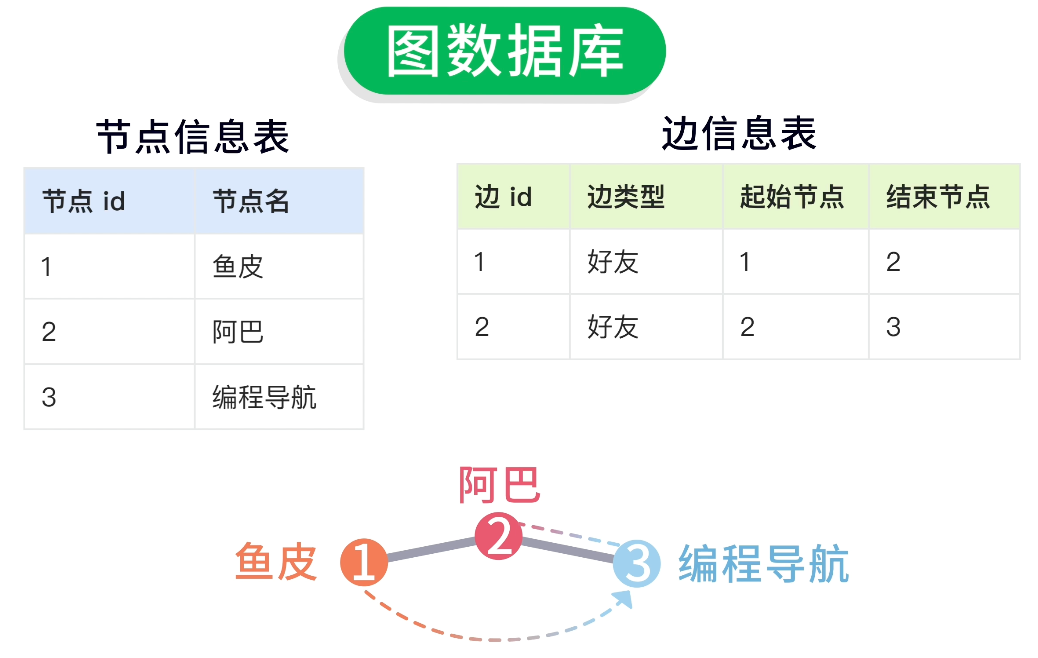
在圖數據庫中,需要 2 個表格來存儲。
1)節點信息表:
| 節點 id | 節點名 |
|---|---|
| 1 | 魚皮 |
| 2 | 阿巴 |
| 3 | 編程導航 |
2)邊信息表:
| 邊 id | 邊類型 | 起始節點 | 結束節點 |
|---|---|---|---|
| 1 | 好友 | 1 | 2 |
| 2 | 好友 | 2 | 3 |
通過存儲這些節點和邊的信息,圖數據庫就能快速查詢和分析複雜的關係網絡。比如查找 “朋友的朋友”、計算兩個用户之間的最短路徑、發現社交圈子等等。
因此,圖數據庫非常適合構建社交網絡、推薦系統、知識圖譜等。
比較主流的圖數據庫有 Neo4j、TigerGraph 等,都支持複雜的圖算法和分佈式擴展,能夠通過並行計算加速圖形處理。
時序數據庫
時序數據庫是專門用於高效存儲和處理 時間序列 的數據庫。
時間序列是指以時間作為主要維度的數據序列,也就是每個數據單元都帶着 時間戳,按時間順序排列。
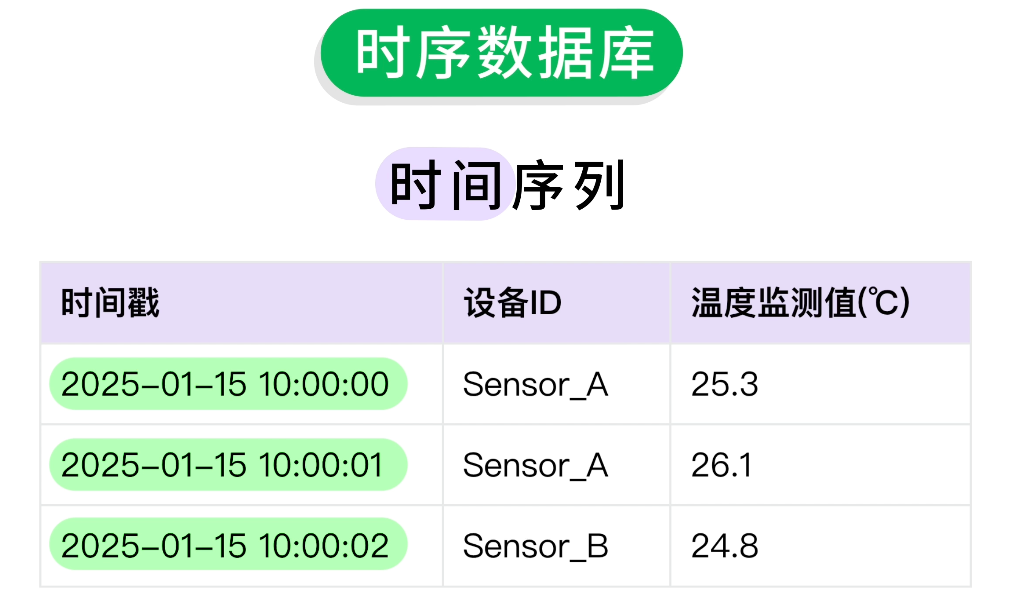
舉個例子,在服務器監控系統中,我們需要每分鐘記錄服務器的 CPU 使用率、內存使用率等指標,數據結構如下:
| 時間戳 | 設備ID | CPU使用率 | 內存使用率 |
|---|---|---|---|
| 2026-01-08 10:00 | Server001 | 45% | 60% |
| 2026-01-08 10:01 | Server001 | 48% | 62% |
| 2026-01-08 10:02 | Server001 | 52% | 65% |
有了這些數據,我們就能夠按照時間範圍進行高效查詢、做聚合分析(比如計算過去 1 小時的平均 CPU 使用率)、進行數據可視化展示。
因此,時序數據庫非常適用於物聯網設備監控、服務器性能監控、金融交易數據分析等場景。
主流的時序數據庫技術有 InfluxDB、TimescaleDB 等,一般會配合 Grafana 監控看板一起使用,實現數據存儲 + 快速可視化。你在運維團隊看到的那些酷炫的實時監控大屏,背後就是時序數據庫在支撐。
列存數據庫
區別於傳統的行式數據庫,列存數據庫 以列作為基本的存儲單位,把每一列的數據存儲在一起。
拿公司每天的收入來舉個例子,傳統的行式數據庫是這麼存儲的:
| 日期 | 銷售額 | 成本 | 利潤 |
|---|---|---|---|
| 2026-01-01 | 500 | 600 | -100 |
| 2026-01-02 | 280 | 450 | -170 |
| 2026-01-03 | 290 | 480 | -190 |
而在列存數據庫中,底層大概是這麼存儲的,看起來像是對矩陣做了一次轉置:
| 日期 | 2026-01-01 | 2026-01-02 | 2026-01-03 |
|---|---|---|---|
| 銷售額 | 500 | 280 | 290 |
| 成本 | 600 | 450 | 480 |
| 利潤 | -100 | -170 | -190 |
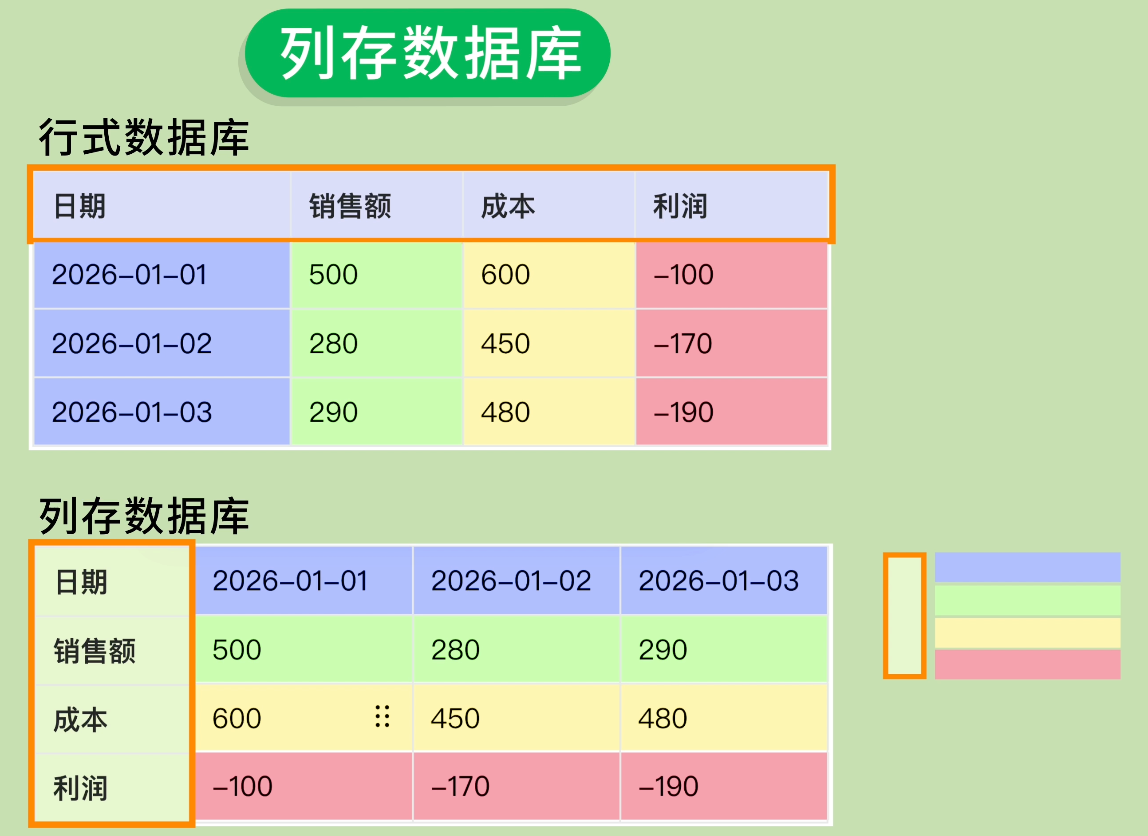
如果我們要統計這 3 天公司的總利潤,傳統的行式數據庫需要依次讀取每一行的數據,然後再提取出利潤這一列進行計算;而列存數據庫直接讀取利潤這一列就行了,不用管其他列,大大提高了數據分析和聚合操作的效率。
而且從計算機底層來分析,把相同類型的數據在同一列中連續存儲,可以實現更好的數據壓縮效果、節約存儲空間。
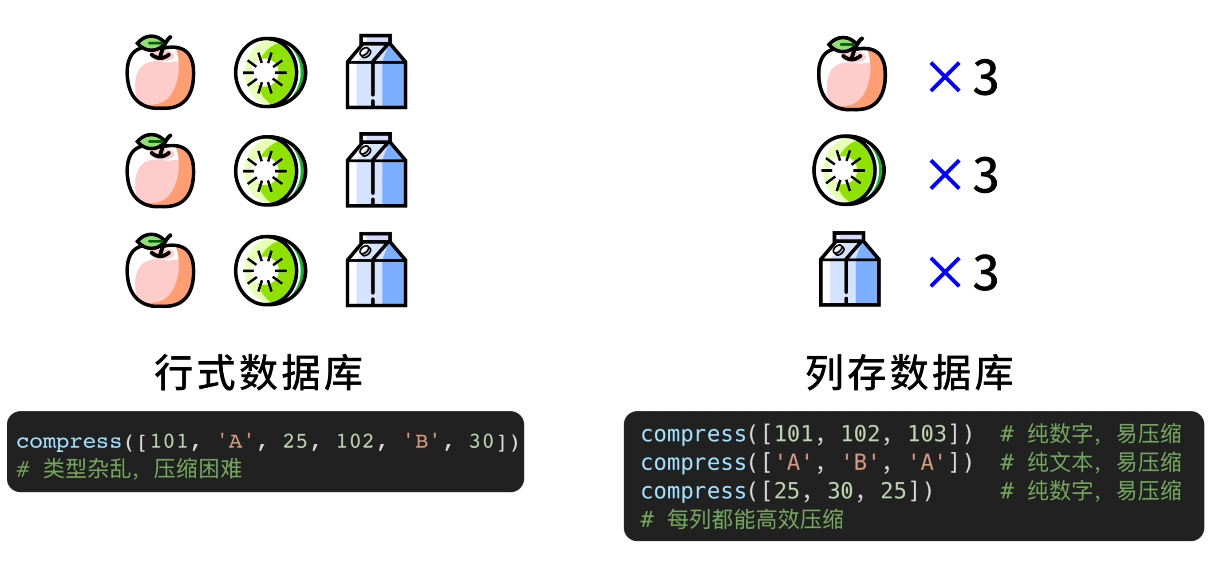
因此,列存數據庫適用於報表生成、數據倉庫、商業智能分析等場景。
主流的列存數據庫技術有 ClickHouse、Apache HBase、Druid 等,都是大數據開發的必修課。
融合型數據庫
前面我們講了關係型和非關係型數據庫,要麼強調靈活查詢、要麼強調性能和擴展,各有側重。
但有些數據庫偏偏 “既要又要”,要把兩者的優點融合到一起,這就是接下來要講的融合型數據庫。
NewSQL 數據庫
NewSQL 是一類新興的數據庫,它融合了傳統關係型和非關係型數據庫的優點。既有傳統 SQL 數據庫的 ACID 特性和事務支持,又有 NoSQL 的水平擴展能力和高性能。支持標準 SQL 查詢、分佈式架構、自動容錯和故障恢復,可以替代傳統的分庫分表方案,特別適用於大廠的高併發系統。
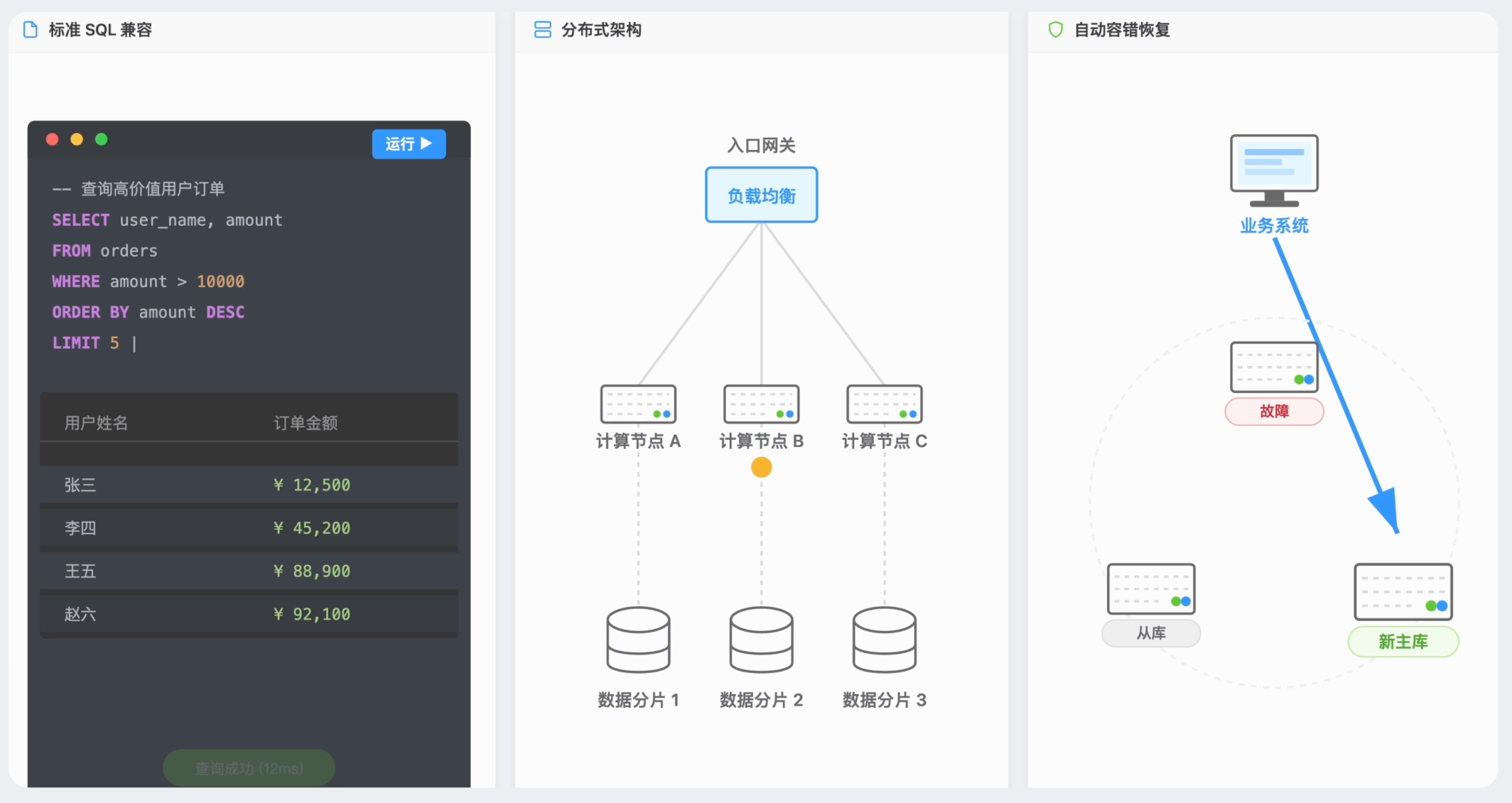
主流的 NewSQL 數據庫有 TiDB、CockroachDB、Google Spanner 等。其中 TiDB 是國產之光,支持 HTAP(混合事務分析處理),而且完全兼容 MySQL 協議,遷移成本低;CockroachDB 人稱 “蟑螂數據庫”,因為它像蟑螂一樣頑強,集羣中一個節點掛了,其他節點依然能正常服務,打不死。

多模數據庫
區別於前面所有存儲單一數據模型的數據庫,多模數據庫能夠直接在一個數據庫裏同時存儲和處理 多種不同類型 的數據。比如關係型數據、文檔數據、圖形數據、鍵值對數據等等,非常靈活、省去了維護多個數據庫的麻煩。

而且多模數據庫還支持跨模型事務,能夠更輕鬆地實現數據的一致性和完整性,不需要手動實現跨庫事務、跨庫數據同步這些複雜操作。

雖然聽起來很厲害,但實際開發中很少用,因為樣樣通樣樣鬆,多模數據庫的性能往往不如專注單一場景的數據庫。
原生的多模數據庫技術有 ArangoDB、OrientDB 等,它們從設計之初就是為多模式設計的。前面也提到,雖然 PostgreSQL 這樣的老牌關係型數據庫可以通過豐富的插件支持多種數據類型(比如 JSON 文檔、向量、地理空間數據等),但它的核心始終是關係模型,多模支持算是錦上添花,不過這也體現了 PostgreSQL 的強大。

怎麼選擇數據庫?
你一臉懵逼:阿巴阿巴,你講了這麼多數據庫,俺頭都大了,到底該選哪個?

魚皮笑了笑:別慌,數據庫選型其實沒那麼複雜。
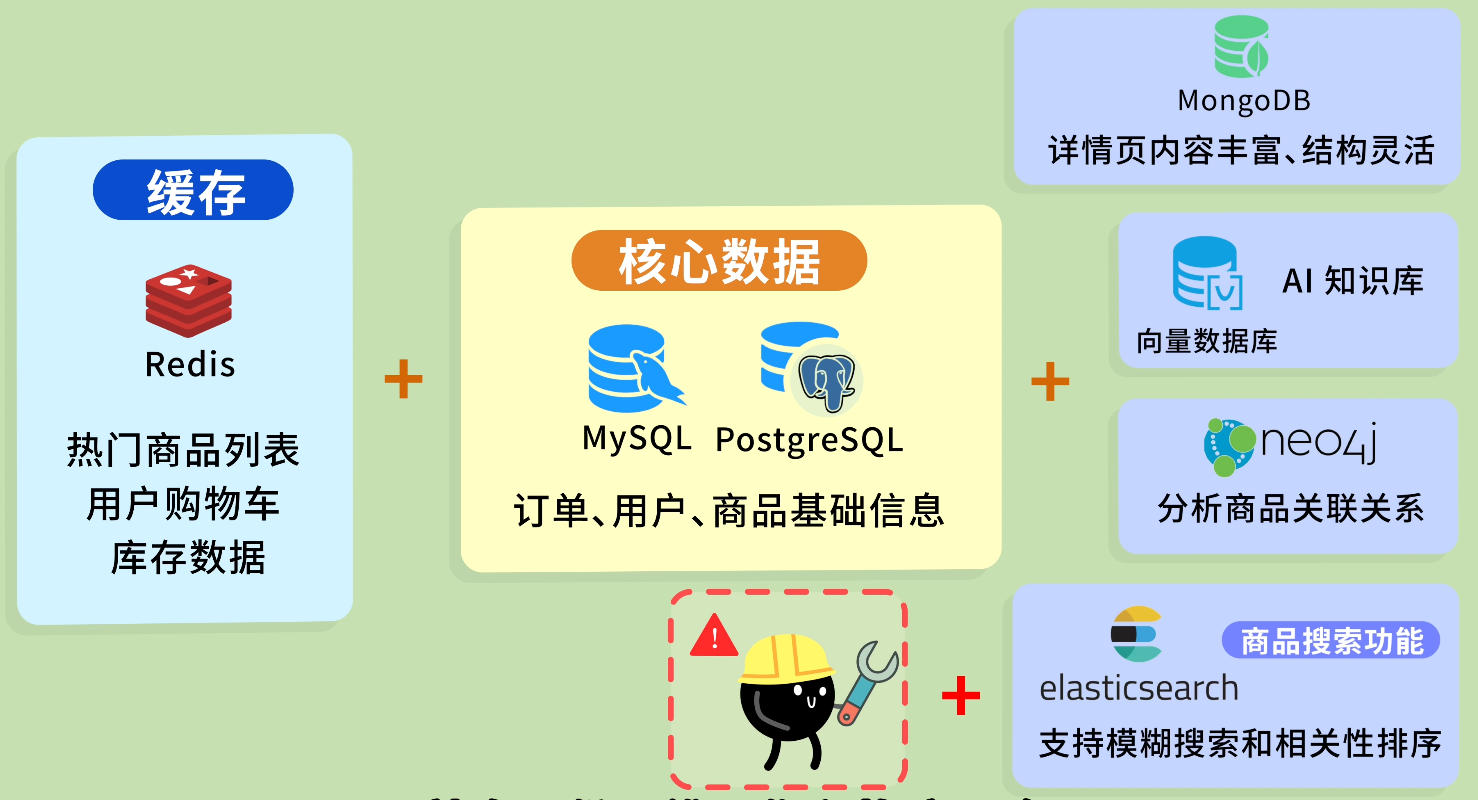
優先選用 MySQL / PostgreSQL + Redis,能覆蓋 90% 的項目需求。
有特定功能或優化需求時,再選擇專業數據庫。比如需要搜索功能了,再加 Elasticsearch;要做 AI 知識庫了,再加向量數據庫。
畢竟每多一個數據庫,就多一份運維工作和故障風險。
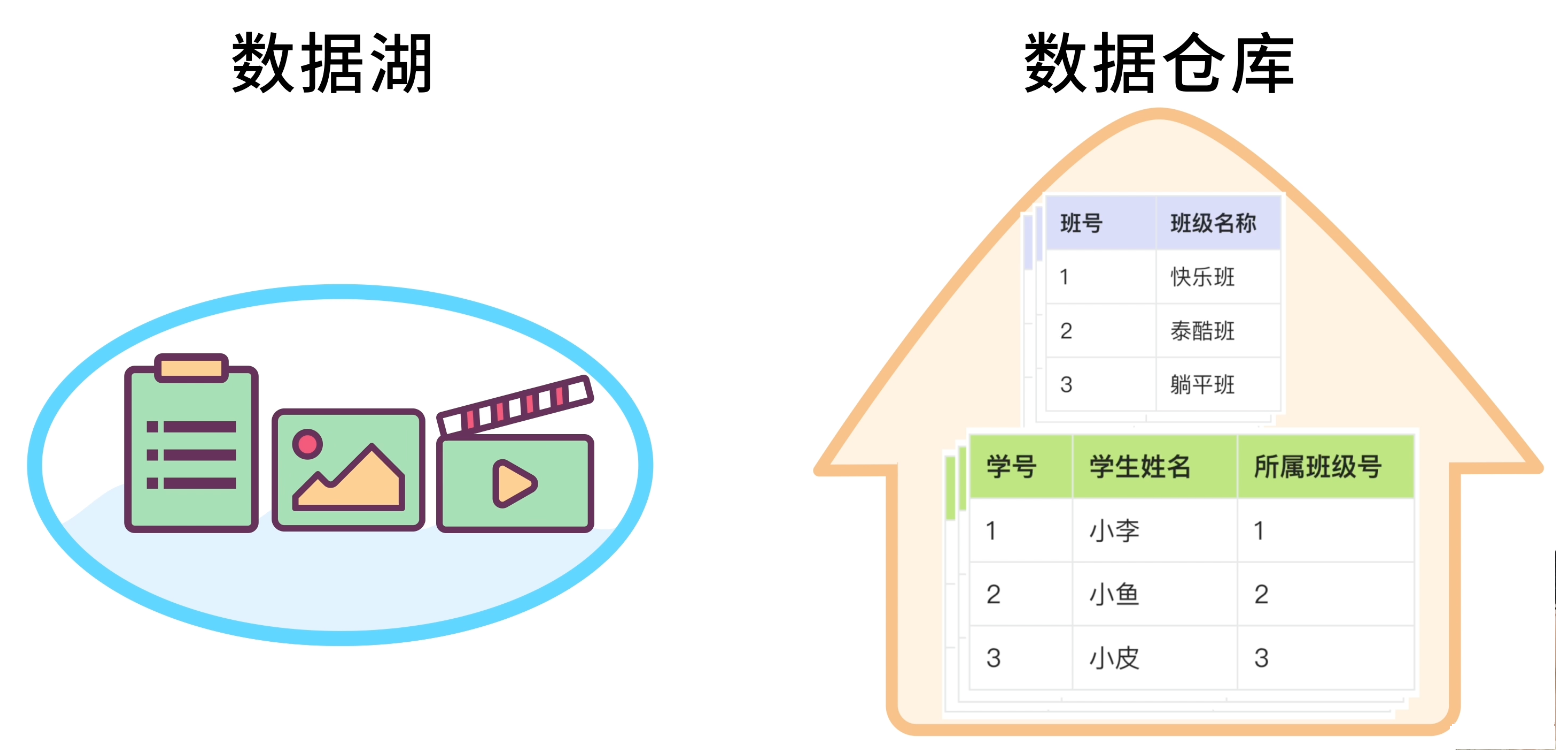
你:學會了學廢了!對了魚皮,我還聽説過數據湖、數據倉庫,這些是啥啊?
魚皮:簡單來説,數據倉庫是用來存儲和分析大量結構化數據的;數據湖更像個大水池,什麼數據都能往裏扔,包括日誌、圖片、視頻這些非結構化數據。它們更多是大數據架構層面的概念。
感興趣的話,點個關注,後面專門出一期講講~
