

寫在前面
你是不是也遇到過這種情況:昨天用 Claude Code 寫了一段複雜業務邏輯,今天重新打開項目,AI 助手卻像失憶了一樣,完全不記得你們討論過什麼,只能從頭再解釋一遍?
這個痛點,Claude-Mem 給出瞭解決方案——一個專為 Claude Code 打造的持久化記憶系統,讓 AI 助手真正記住你們的每一次協作。
它到底解決了什麼問題
傳統的 AI 編程助手每次啓動都是"全新的大腦",無法跨會話保留項目上下文。Claude-Mem 通過自動捕獲、AI 壓縮、智能檢索三個步驟,實現了:
- ✅ 跨會話記憶保持:自動記錄所有工具調用和代碼操作
- ✅ 智能內容壓縮:用 Claude Agent SDK 將冗長對話壓縮成精煉摘要
- ✅ 按需精準檢索:通過自然語言查詢歷史記憶,大幅節省 Token 成本
技術架構解析
核心組件構成
系統架構:
├── 鈎子系統(7 個生命週期鈎子)
├── Worker 服務(HTTP API + Web UI)
├── 存儲層(SQLite FTS5 + Chroma 向量庫)
└── PM2 進程管理
主要技術棧:
- Node.js + TypeScript:插件主體實現
- SQLite FTS5:全文檢索引擎
- Chroma Vector DB:語義向量搜索
- Claude Agent SDK:AI 壓縮核心能力
工作原理拆解
五大生命週期鈎子
Claude-Mem 採用觀察者模式,在不干擾主會話的前提下,通過鈎子捕獲關鍵事件:
| 鈎子名稱 | 觸發時機 | 核心作用 |
|---|---|---|
| context-hook | 會話啓動時 | 注入最近記憶作為上下文 |
| new-hook | 用户提問時 | 創建新會話並保存提示詞 |
| save-hook | 工具執行後 | 捕獲文件讀寫等操作記錄 |
| summary-hook | 會話結束時 | 生成 AI 摘要並持久化存儲 |
| cleanup-hook | 停止指令時 | 清理臨時數據 |
漸進式披露策略
這是 Claude-Mem 最巧妙的設計——不是一股腦把所有歷史記錄塞給 AI,而是分層展示:
Level 1: 最近 3 條會話摘要(約 500 tokens)
Level 2: 相關觀察記錄(用户主動查詢)
Level 3: 完整歷史檢索(mem-search 技能)
這種策略借鑑了前端開發中的懶加載思想,在雲棧社區的技術實踐中,我們也常強調"按需加載"的性能優化原則。
實際應用場景
場景一:Bug 修復追溯
用户:"上週修復的登錄超時問題,具體改了哪些文件?"
Claude:[自動觸發 mem-search]
→ 檢索到 2 條相關觀察記錄
→ 返回:修改了 auth.ts 和 session.middleware.ts
場景二:項目知識庫構建
長期使用後,Claude-Mem 會自動構建項目的"知識圖譜":
- 架構決策記錄
- 常用代碼模式
- 踩過的坑和解決方案
場景三:團隊協作可視化
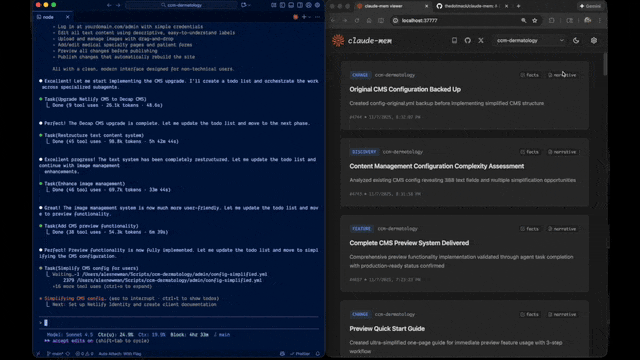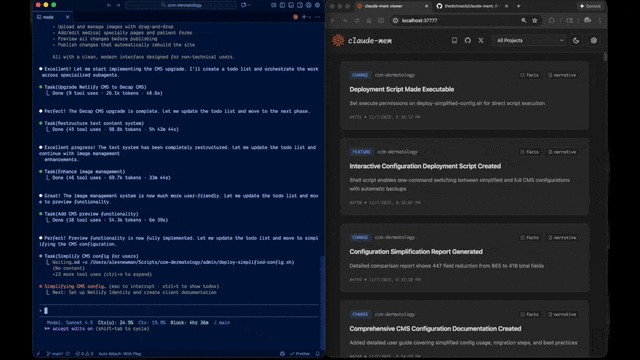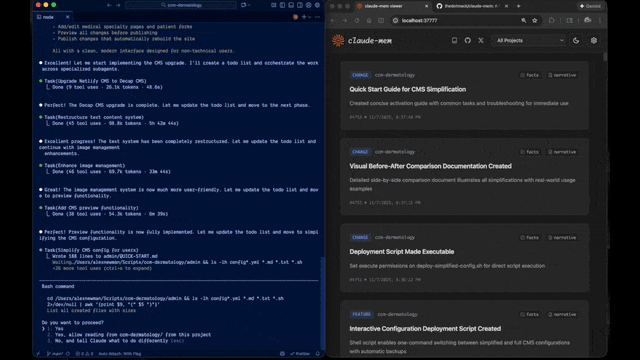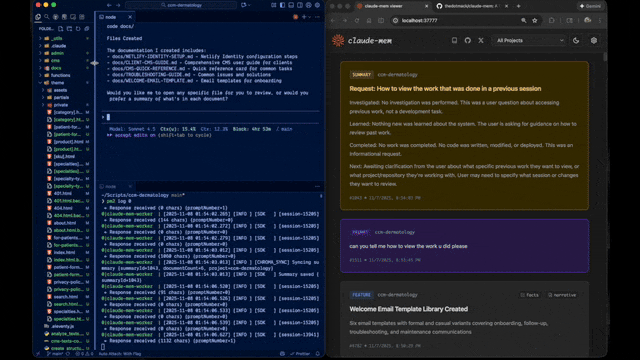
通過 Web UI(localhost:37777)可以實時查看:
- 記憶流動態
- 會話摘要時間線
- Token 消耗統計
快速上手指南
安裝步驟(3 步完成)
# 在 Claude Code 終端執行
> /plugin marketplace add thedotmack/claude-mem
> /plugin install claude-mem
# 重啓 Claude Code 即可使用
核心技能使用
mem-search 技能:自然語言查詢歷史記憶
示例:mem-search "關於數據庫遷移的討論"
效果:相比傳統 MCP 方式節省約 2,250 tokens
架構設計亮點
混合檢索策略
// 結合傳統全文檢索和現代向量搜索
interface SearchStrategy {
fullText: SQLite FTS5, // 關鍵詞精準匹配
semantic: Chroma Vector, // 語義相似度計算
hybrid: RRF 融合排序 // 最佳結果輸出
}
隱私控制機制
使用 <private> 標籤排除敏感內容:
<private>
API_KEY=sk-xxx # 不會被系統記錄
</private>
雙標籤系統(v7.0 新特性)
<private>:完全排除觀察記錄<no-summary>:記錄但不生成摘要
性能表現數據
| 優化指標 | 實際效果 |
|---|---|
| Token 節省 | 每次啓動節省 2,250 tokens |
| 查詢響應速度 | 向量檢索 < 50ms |
| 存儲壓縮效率 | 10GB 代碼庫壓縮至約 200MB |
工程實踐啓示
作為全棧工程師,Claude-Mem 展示了幾個值得學習的工程實踐:
- 插件化設計:標準的生命週期鈎子系統
- AI 工程化:將 LLM 能力封裝為可複用服務
- 成本意識:Token 優化是 AI 原生應用的核心指標
- 用户體驗:漸進式披露配合可視化 UI
對於想深入學習 Node.js 開發和 人工智能應用的朋友,這個項目提供了很好的參考範例。
寫在最後
Claude-Mem 不僅是一個工具,更是 AI 輔助編程的範式探索:如何讓 AI 從"一次性對話"進化為"長期協作夥伴"。
如果你正在使用 Claude Code,不妨試試這個插件,讓你的 AI 助手真正"記住"你們的每一次協作。更多優質開源項目解析,歡迎關注《雲棧開源日記》!
項目資源
- GitHub 倉庫:
thedotmack/claude-mem - 官方文檔:
docs.claudemem.com - AI 學習:
https://yunpan.plus/f/29 - TypeScript 學習:
https://yunpan.plus/f/18
標籤:#Claude #GitHub #AI編程助手 #向量數據庫 #TypeScript #持久化存儲 #開發工具
原文 https://yunpan.plus/t/1920-1-1 版權所有