

一個改變語音合成的技術突破
你有沒有想過,輸入一段對話腳本,AI 就能生成兩個人自然交談 90 分鐘的播客音頻——不是機械的電子音,而是有停頓、有情感、能互動的真實對話。
微軟剛開源的 VibeVoice 做到了。
它解決了什麼實際問題
傳統文本轉語音工具存在三個明顯短板:
長度受限
市面上的語音合成工具,生成超過 5 分鐘就開始出現音質下降、韻律混亂的問題。
單人侷限
想做多人對話場景?只能分段生成再拼接,效果往往不自然。
響應速度慢
等待幾十秒才出第一個字,實時對話場景根本無法使用。
VibeVoice 針對這些痛點給出了系統性解決方案。
核心技術架構
微軟研究院在語音合成領域做了一次技術創新。
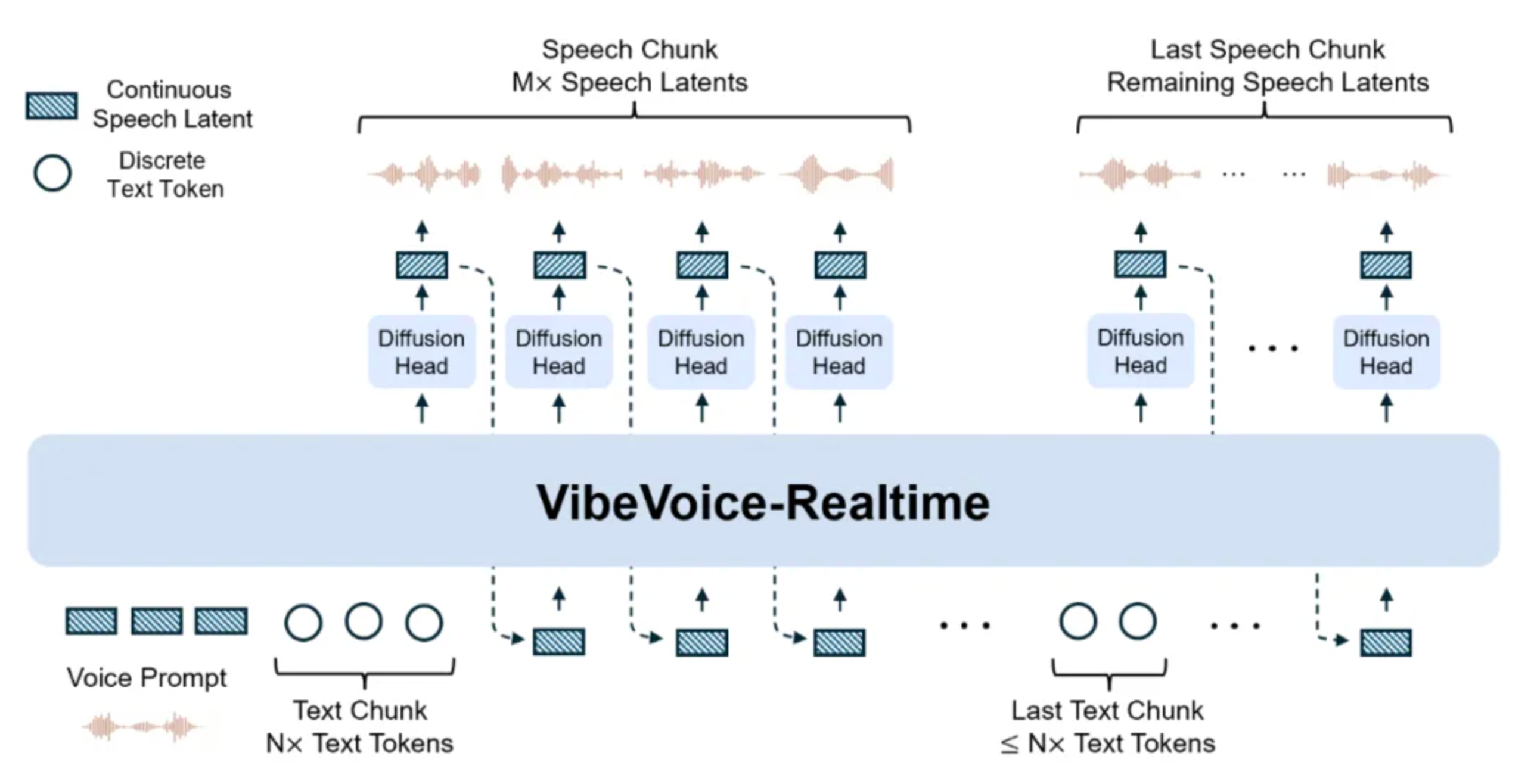
超低幀率設計
傳統語音模型使用 50Hz 幀率,VibeVoice 採用 7.5Hz——計算量直接降低 85%,但音質保持穩定。
實現方式是雙 Tokenizer 架構:
文本輸入 → 語義 Tokenizer(理解內容)
↓
聲學 Tokenizer(控制音色)
↓
擴散解碼(生成音頻波形)
σ-VAE 壓縮技術
聲學 Tokenizer 採用變分自編碼器,實現 3200 倍壓縮率。90 分鐘音頻的特徵表示,只需要傳統方法 1/3200 的存儲空間。
Next-Token Diffusion 機制
基於 Qwen2.5 大模型,用擴散模型逐 token 生成。這讓長序列生成保持穩定,不會出現"跑偏"。
兩個版本的差異化定位
| 模型版本 | 參數規模 | 核心能力 | 適用場景 |
|---|---|---|---|
| VibeVoice-1.5B | 15 億 | 90 分鐘長文本、4 人對話 | 播客製作、有聲書、訪談節目 |
| VibeVoice-Realtime | 5 億 | 300ms 首字延遲、流式輸入 | 實時客服、語音助手 |
長文本版本適合內容創作場景,生成質量接近真人錄製。
實時版本針對交互場景優化,300 毫秒首字延遲,普通筆記本電腦就能運行。
快速上手實踐
從零到生成第一段音頻,實測只需 5 分鐘。
基礎語音生成
from vibevoice import VibeVoiceRealtime
import soundfile as sf
# 加載模型
model = VibeVoiceRealtime.from_pretrained(
"microsoft/VibeVoice-Realtime-0.5B"
)
# 生成語音
text = "大家好,今天分享一個語音合成項目"
audio = model.generate(text)
# 保存音頻文件
sf.write("output.wav", audio, 24000)
多人對話場景
conversation = [
{"speaker": "主持人", "text": "歡迎收聽本期節目"},
{"speaker": "嘉賓", "text": "很高興參加這次分享"}
]
for turn in conversation:
audio = model.generate(
text=turn["text"],
speaker=turn["speaker"]
)
代碼邏輯清晰,上手門檻不高。
實際應用場景
內容創作方向
- 自媒體播客製作,降低錄音成本
- 有聲書批量生產,製作成本降低 90%
- 短視頻配音,支持批量生成
企業服務領域
- 智能客服系統,提供 24 小時服務
- 語音通知播報,實現個性化定製
- 會議紀要轉換,自動生成語音版本
教育培訓場景
- 在線課程配音製作
- 語言學習材料生成
- 有聲教材批量製作
雲棧社區( https://yunpan.plus )實測發現,這些場景都能快速落地。
性能表現數據
在 RTX 4090 顯卡上的實測結果:
- 生成速度:實時率 10 倍(生成 1 秒音頻只需 0.1 秒)
- 音質評分:MOS 4.2/5.0(接近真人水平)
- 顯存佔用:6GB(消費級顯卡可用)
- 支持語言:中文、英文
技術棧學習價值
對於求職者來説,這個項目覆蓋多個技術方向:
算法層面
- Transformer 架構應用
- 變分自編碼器(VAE)實現
- 擴散模型(Diffusion)原理
工程層面
- PyTorch 模型訓練流程
- 實時推理性能優化
- 音頻信號處理技術
應用層面
- 大模型微調方法
- API 服務設計思路
- 產品落地實踐經驗
簡歷上寫"基於 VibeVoice 實現語音合成系統",面試時會是個加分項。
使用注意事項
研究用途定位
MIT 協議開源,官方強調研究用途,商業化使用需要謹慎評估。
倫理風險防範
高質量語音合成存在被濫用風險,使用時需遵守相關規範。
語言支持範圍
目前支持中英文,其他語言還在開發中。
硬件配置要求
實時版本需要至少 8GB 顯存,長文本版本建議 16GB 以上。
為什麼值得關注
- 微軟官方出品,技術可靠性有保障
- MIT 開源協議,可以自由研究改造
- 完整工程實現,不只是論文 Demo
- 社區活躍度高,1.6k Forks 證明實用性
- 持續更新迭代,團隊在快速響應
對於想進入 AI 語音領域的開發者,這是一個不錯的學習樣本。
技術點評
VibeVoice 的出現,標誌着語音合成進入長文本時代。
它不是簡單的技術堆砌,而是在壓縮率、音質、實時性之間找到了平衡點。雙 Tokenizer 架構的設計思路,值得做生成式 AI 的團隊參考。
微軟選擇開源,讓更多開發者能站在這個基礎上創新。
建議動手跑一遍代碼,會對語音 AI 技術有更深入的理解。
關注《雲棧開源日記》,每天 3 分鐘,帶你看最火開源項目
項目資源
GitHub 倉庫: microsoft/VibeVoice
官方文檔: microsoft.github.io/VibeVoice
技術論文: microsoft.com/en-us/research/articles/vibevoice
Python 學習資源: https://yunpan.plus/f/26
AI 學習資源: https://yunpan.plus/f/29
標籤:#VibeVoice #GitHub #微軟開源 #語音合成 #AI語音 #深度學習