










🏆🏆🏆教程全知識點簡介:涵蓋圖像識別背景、目標檢測定義和應用場景。核心算法原理包括R-CNN系列算法(R-CNN、SPPNet、Faster R-CNN、RPN原理)、YOLO算法(單次檢測、候選框機制、單元格概念)以及SSD算法(單次多框檢測器、多個Detector & classifier、訓練與測試流程)。數據處理模塊包含目標數據集標記、數據集格式轉換(TFRecords文件、VOC2007數據集)、slim庫和API使用。項目實現涉及項目結構設計、數據模塊接口、預處理和數據增強技術。模型訓練包括預訓練模型、SSD模型定義、default boxes、模型加載、變量初始化、交互式會話。模型推理涵蓋predictions篩選、bbox處理、scores排序、NMS算法。部署方案包括Web Server、TensorFlow Serving Client、環境安裝、DeploymentConfig配置。訓練主函數包含設備選擇、全局步長變量、網絡參數獲取、批處理數據隊列、多GPU/CPU平均損失計算。

📚📚👉👉👉本站這篇博客: https://segmentfault.com/a/1190000047079328 中查看
📚📚👉👉👉本站這篇博客: https://segmentfault.com/a/1190000047234804 中查看
<!-- end:bj1 -->
✨ 本教程項目亮點
🧠 知識體系完整:覆蓋從基礎原理、核心方法到高階應用的全流程內容
💻 全技術鏈覆蓋:完整前後端技術棧,涵蓋開發必備技能
🚀 從零到實戰:適合 0 基礎入門到提升,循序漸進掌握核心能力
📚 豐富文檔與代碼示例:涵蓋多種場景,可運行、可複用
🛠 工作與學習雙參考:不僅適合系統化學習,更可作為日常開發中的查閲手冊
🧩 模塊化知識結構:按知識點分章節,便於快速定位和複習
📈 長期可用的技術積累:不止一次學習,而是能伴隨工作與項目長期參考
🎯🎯🎯全教程總章節


🚀🚀🚀本篇主要內容
數據集處理
瞭解常用目標檢測數據集
瞭解數據集構成
瞭解數據集標記的需求
知道labelimg的標記使用
應用TensorFlow完成pascalvoc2007數據集的轉換
瞭解TensorFlow slim庫
瞭解TFRecords文件的作用
瞭解slim讀取數據流程
應用TF-slim的data模塊完成VOC2007TFRecord文件的讀取2.2 目標數據集標記
學習目標
-
目標
- 瞭解數據集標記的需求
- 知道labelimg的標記使用
-
應用
- 應用labelimg完成產品數據集的標記
為什麼要進行數據集標記呢?
1、提供給訓練的數據樣本,圖片和目標真是實結果
2、特定的場景都會缺少標記圖片
2.2.1 數據集標記工具介紹
2.2.1.1 介紹
LabelImg是一個圖形圖像註釋工具。它是用Python編寫的,並使用Qt作為其圖形界面。註釋以PASCAL VOC格式保存為XML文件,這是ImageNet使用的格式。
注:官網:https://github.com/tzutalin/labelImg
2.2.1.2 安裝
官網給出了不同平台的安裝教程,由於教程過於粗略。安裝細節參考安裝教程本地文件
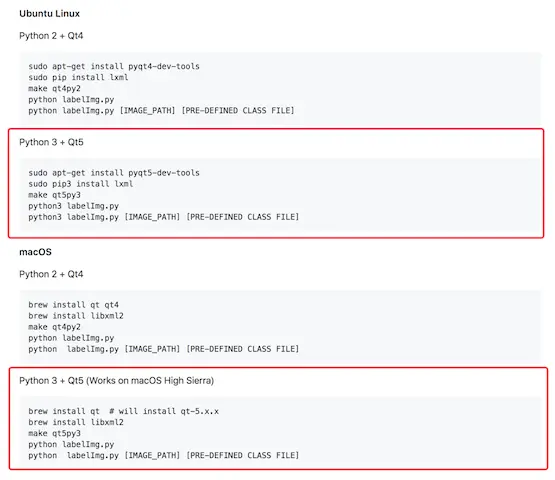
- 參考本地文件:

2.2.2 產品數據集標記
在這裏 只是體驗標記的過程,那麼對於標記這個費時費力的工作,一般會有專門的數據標記團隊去做,也稱之為打標籤,標記師。特別是缺乏具體應用場景的訓練數據的時候。
2.2.2.1 需求介紹
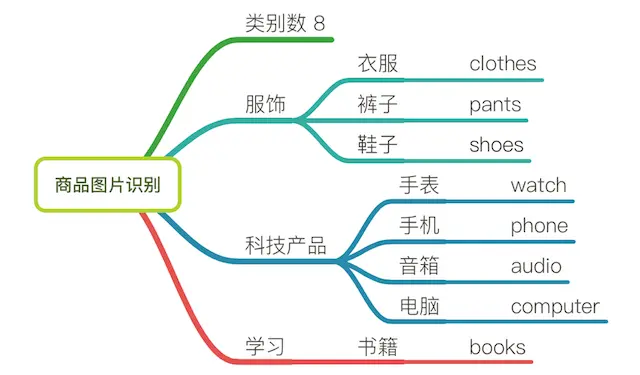
首先在確定標記之前的需求,本項目以產品數據為例,需要明確的有
- 1、產品圖片
-
2、需要被標記物體有哪些
確定了8種類別的產品(如需更細緻,可將類別產品擴大),如下圖
2.2.2.2 標記
使用lableimg進行產品數據集標記
- 運行labelimg
python labelImg.py
打開如下結果
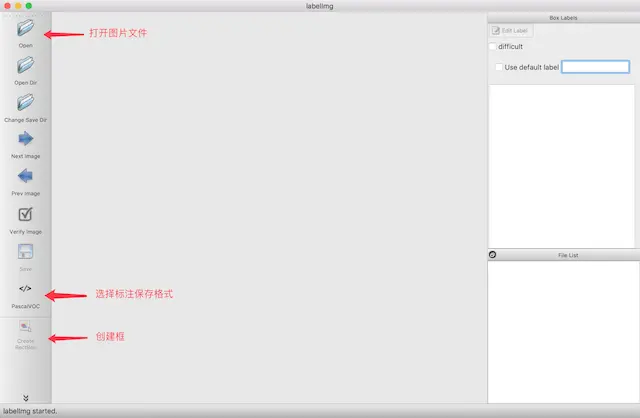
- 對圖片中的物體進行標記
標記原則為圖片中所出現的物體與 確定的8個類別物體相匹配即可
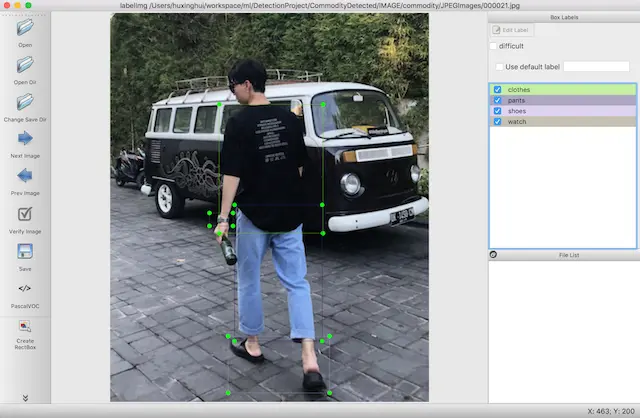
- 按下ctrl+s鍵保存,軟件將會保存為默認XML文件格式(XML文件名與圖片文件名保持一致方便後續處理)
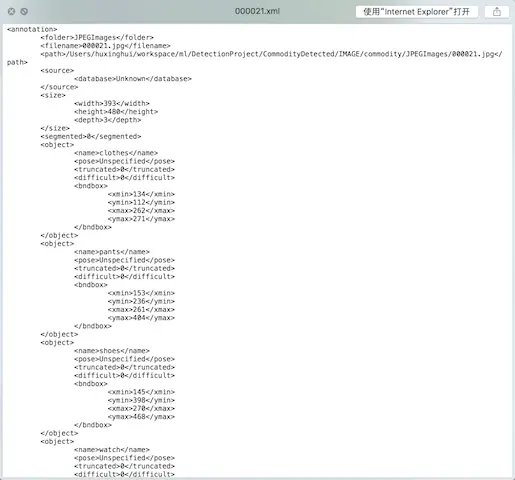
其中關於(xmin,ymin,xmax,ymax) 已經解釋過,可通過軟件標記的時候觀察是否一致
2.2.3 總結
- 掌握labelimg的標註使用
2.2.4 問題
通過這樣標記數據,假設你想做一個潮流產品品牌(Nike、H&M等)或者其他具體某個子領域的大部分產品的識別模型,你的數據集怎麼準備?
數據集處理
瞭解常用目標檢測數據集
瞭解數據集構成
瞭解數據集標記的需求
知道labelimg的標記使用
應用TensorFlow完成pascalvoc2007數據集的轉換
瞭解TensorFlow slim庫
瞭解TFRecords文件的作用
瞭解slim讀取數據流程
應用TF-slim的data模塊完成VOC2007TFRecord文件的讀取2.3 數據集格式轉換
學習目標
-
目標
- 瞭解TFRecords文件的作用
-
應用
- 應用TensorFlow完成pascalvoc2007數據集的轉換
首先來看下轉換的效果:
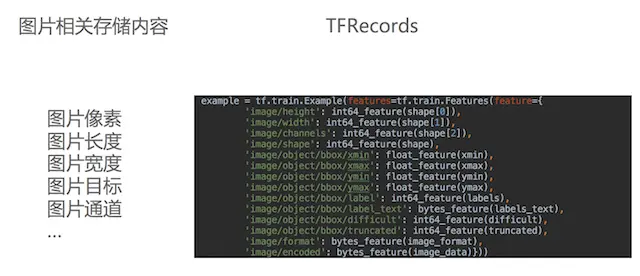
為什麼要進行格式轉換?
數據集的圖片以及標記文件分佈在不同的文件當中,並且圖片與標籤沒有一一對應。在後續項目當中不方便處理,也不方便項目的解耦合,需要將數據集轉換成一個標準、統一使用、方便賦值移動到其他模塊當中。
2.3.2 TFRecords文件
TensorFlow提供了TFRecord的格式來統一存儲數據,TFRecord格式是一種將圖像數據和各種標籤放在一起的二進制文件,在tensorflow中快速的複製、移動、讀取、存儲。特點:
- 文件格式:.tfrecord or.tfrecords
-
寫入文件內容:使用Example將數據封裝成protobuffer協議格式
- 體積小:消息大小隻需要xml的1/10~1/3
- 解析速度快:解析速度比xml快20~100倍
- 每個example對應一張圖片,其中包括圖片的各種信息
2.3.3 案例:VOC2007數據集轉換
2.3.3.1 轉換效果顯示
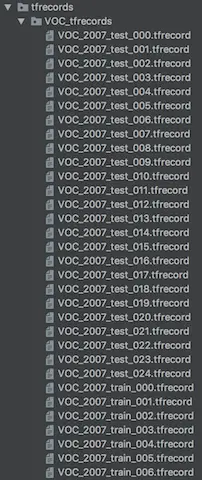
2.3.3.2 TensorFlow API
gfile讀取模塊
-
tf.gfile.MakeDirs(dirname):
- 以遞歸方式建立父目錄及其子目錄,如果目錄已存在且是可覆蓋則會創建成功,否則報錯,無返回
-
tf.gfile.Exists(filename):
- 判斷目錄或文件是否存在,filename可為目錄路徑或帶文件名的路徑,有該目錄則返回True,否則False
-
tf.gfile.FastGFile(filename, mode):
- 該函數與tf.gfile.GFile的差別僅僅在於“無阻塞”,即該函數會無阻賽以較快的方式獲取文本操作句柄
建立TFRecord存儲器
-
tf.python_io.TFRecordWriter(path)
- 寫入tfrecords文件
- path: TFRecords文件的路徑
- return:寫文件
-
method
- write(record):向文件中寫入一個example
-
close():關閉文件寫入器
注:字符串為一個序列化的Example,Example.SerializeToString()
構造每個樣本的Example協議塊
-
tf.train.Example(features=None)
- 寫入tfrecords文件
- features:tf.train.Features類型的特徵實例
- return:example格式協議塊
-
tf.train.Features(feature=None)
- 構建每個樣本的信息鍵值對
- feature:字典數據,key為要保存的名字,value為tf.train.Feature實例
- return:Features類型
-
tf.train.Feature(**options)
- **options:例如
- bytes_list=tf.train. BytesList(value=[Bytes])
- int64_list=tf.train. Int64List(value=[Value])
處理XML庫
-
import xml.etree.ElementTree as ET
- tree = et.parse(filename):形成樹狀結構
- tree.getroot():獲取樹結構的根部分
- root.find與findall()進行查詢XML每個標籤的內容.text
2.3.3.2 轉換步驟
- 1、存入多個tfrecord文件,每個文件固定N個樣本
- 2、讀取每張圖片內容以及XML文件
- 3、將每次讀取內容寫入tfrecord文件
2.3.3.3 代碼
首先導入需要用到的庫以及相關設置
import os
import tensorflow as tf
import xml.etree.ElementTree as ET
from datasets.utils.dataset_utils import int64_feature, float_feature, bytes_feature
from datasets.dataset_config import DIRECTORY_ANNOTATIONS, SAMPLES_PER_FILES, DIRECTORY_IMAGES, VOC_LABELS代碼結構按照如下目錄結構
dataset_utils當中存放常用代碼,dataset_config存放一些配置,先看配置
# 原始圖片的XML和JPG的文件名
DIRECTORY_ANNOTATIONS = "Annotations/"
DIRECTORY_IMAGES = "JPEGImages/"
# 每個TFRecords文件的example個數
SAMPLES_PER_FILES = 200- 1、存入多個tfrecord文件,每個文件固定N個樣本
def run(dataset_dir, output_dir, name="data"):
"""
存入多個tfrecords文件,每個文件通常會固定樣本的數量
:param dataset_dir: 數據集目錄
:param output_dir: tfrecord輸出目錄
:param name: 數據集名字
:return:
"""
# 1、判斷數據集的路徑是否存在,如果不存在新建一個文件夾
if tf.gfile.Exists(dataset_dir):
tf.gfile.MakeDirs(dataset_dir)
# 2、去Annotations讀取所有的文件名字列表,與JPEGImages一樣的數據量
# 構造文件的完整路徑
path = os.path.join(dataset_dir, DIRECTORY_ANNOTATIONS)
# 排序操作,因為會打亂文件名的前後順序
filenames = sorted(os.listdir(path))
# 3、循環列表中的每個文件
# 建立一個tf.python_io.TFRecordWriter(path)存儲器
# 標記每個TFRecords存儲200個圖片和相關XML信息
# 所有的樣本標號
i = 0
# 記錄存儲的文件標號
fidx = 0
while i < len(filenames):
# 新建一個tfrecords文件
# 構造一個文件名字
tf_filename = _get_output_filename(output_dir, name, fidx)
with tf.python_io.TFRecordWriter(tf_filename) as tfrecord_writer:
j = 0
# 處理200個圖片文件和XML
while i < len(filenames) and j < SAMPLES_PER_FILES:
print("轉換圖片進度 %d/%d" % (i+1, len(filenames)))
# 處理圖片,讀取的此操作
# 處理每張圖片的邏輯
# 1、讀取圖片內容以及圖片相對應的XML文件
# 2、讀取的內容封裝成example, 寫入指定tfrecord文件
filename = filenames[i]
img_name = filename[:-4]
_add_to_tfrecord(dataset_dir, img_name, tfrecord_writer)
i += 1
j += 1
# 當前TFRecords處理結束
fidx += 1
print("完成數據集 %s 所有的樣本處理" % name)存入的邏輯,給文件名字進行format
def _get_output_filename(output_dir, name, number):
return "%s/%s_%03d.tfrecord" % (output_dir, name, number)def _add_to_tfrecord(dataset_dir, img_name, tfrecord_writer):
"""
# 1、讀取圖片內容以及圖片相對應的XML文件
# 2、讀取的內容封裝成example, 寫入指定tfrecord文件
:param dataset_dir: 數據集目錄
:param img_name: 該圖片名字
:param tfrecord_writer: tfrecord文件的符號
:return:
"""
# 1、讀取圖片內容以及圖片相對應的XML文件
image_data, shape, bboxes, difficult, truncated, labels, labels_text = \
_process_image(dataset_dir, img_name)











