
上週一個在快手做搜索的前同事發消息給我,説他們前段時間搞了一個收益非常大的上線,發了兩篇論文,能不能幫忙宣傳一下。
這個朋友去年還跟我吐槽,感覺自己馬上要失業了,做搜索已經不知道該優化啥了。
ChatGPT 要替代搜索引擎,這個論調炒了兩年,作為一個做了五年搜索算法的老兵,過去兩年我一直在思考一個問題:搜索系統還能做點什麼。
BERT 雙塔、向量檢索、多路召回、精排蒸餾...該加的路都加了,該卷的點都卷完了。行業共識是搜索已經是一個成熟技術,增量優化空間越來越小。
我問他改進有多大?他説這套系統已經在快手搜索全量上線,創造了近兩年最大的單次實驗收益。
“你們咋做的?”他就把論文發過來了。


Rethinking 倒排索引、Rethinking 搜索架構。
倒排索引是搜索系統的基石,從 1998 年到現在 27 年了,全世界搞搜索的都在這個框架裏優化。
這兩個 Rethinking 讓我有點警惕,抱着懷疑的心態去看了下這兩篇論文。
讀完後的整體感受是:
快手這兩篇論文(UniDex 和 UniSearch)在當下生成式大模型熱度這麼高的時候,這種工業級系統改進的工作,真的非常稀缺,有種返璞歸真的感覺。
很多人以為生成式搜索就是 Perplexity 那種 AI 問答,其實快手做的是完全不同的另一件事。
Perplexity 是改變了你「怎麼看結果」,從 10 條藍鏈接變成 AI 生成的答案;快手的內容還是快手裏真實的短視頻、直播間,改變的是系統「怎麼找到結果」,後者是技術創新。具體來説:
- UniDex 把倒排索引從「詞」換成了「語義 ID」;
- UniSearch 把召回-粗排-精排三段式換成了端到端生成。
今天這篇文章,我會帶入到之前做搜索算法的角色,講一下面對數百億視頻資源、數十萬併發直播間、每天數億次搜索請求的業務場景裏,他們在技術上怎麼做到的。
UniDex 重構倒排索引
先來聊聊 UniDex。
倒排索引(Inverted Index)是所有搜索引擎的基石技術,基於詞匹配(Term-based)進行檢索。
詞 → 包含該詞的文檔列表"紅燒肉" → [Doc1, Doc5, Doc29, ...]
"教程" → [Doc1, Doc8, Doc15, ...]
比如用户搜"紅燒肉教程",系統找到“紅燒肉”、“教程”兩個索引的交集,然後用 BM25 打分。從 1998 年 Google 誕生到現在,這個範式一直在用。
但它有個致命問題:只能匹配"字詞",無法理解"語義"。比如 query 用"教程",視頻用"指南"、"tutorial"就沒辦法召回。
這就是詞彙鴻溝(Vocabulary Mismatch)。為了緩解這個問題,工程師們發明了無數補丁:同義詞詞典、停用詞處理、query 改寫、多路召回...系統也逐漸複雜,每次改動都要祈禱別把其他地方搞掛。
快手技術團隊在這篇論文裏給出了一種節省資源、搜索體驗更好的解決方案——UniDex。
從基於詞項(Term-based)轉向基於模型的語義(Model-based)索引。不用詞,改用模型學出來的語義 ID (Semantic IDs)。
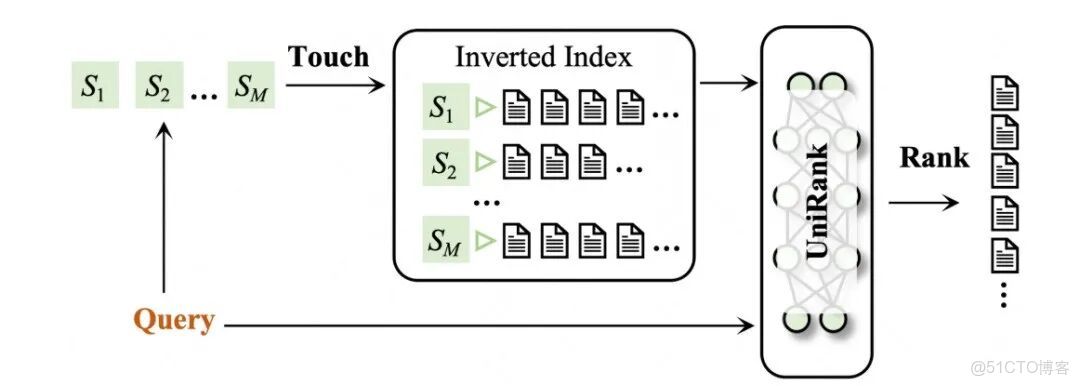
UniDex 主要包含兩個核心模塊:
- UniTouch(觸達模塊):將 query 和 doc 映射為離散的語義 ID。
- UniRank(排序模塊):通過語義匹配對檢索結果進行精細排序。
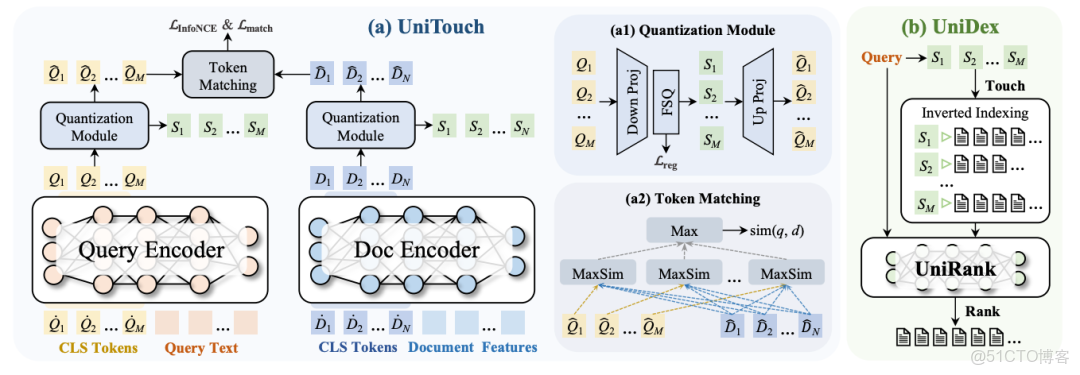
UniTouch 負責將視頻和 query 映射為語義 ID 序列:
視頻 → Doc Encoder → 語義嵌入 → FSQ 量化 → 8 個語義 ID 序列,例如:
貓咪 → [S1:57099, S2:315147, S3:315371, ...]狗狗 → [S1:57099, S2:218453, S3:425681, ...]
查詢時也生成語義 ID。
Query "可愛的貓" → Query Encoder → 語義嵌入 → FSQ 量化 → 3 個語義 ID [S1:57099,S2:315147,S3:315371]。
為什麼 query 用 3 個 ID,document 用 8 個?
因為 query 通常短且語義聚焦,3 個 ID 足夠;而 document 內容豐富,可能包含多個語義側面,需要更多 ID 來表達。
這樣即使 query 和視頻元數據沒有字面重合,只要語義相近就能檢索到。
為什麼要量化成離散 ID?
因為連續的 embedding 無法直接建倒排索引。必須把連續空間離散化,才能像傳統 Term 一樣查表。
如何判斷 query 和 document 是否相關?
傳統 BM25 看有多少詞重疊,UniDex 的方法是看有多少語義 ID 重疊。
並且使用了"Max-Max"匹配策略,只要 query 的 3 個 ID 和 doc 的 8 個 ID 有 1 個匹配就召回,因為用户 query 可能有多重意圖,匹配一個就該返回。
UniRank 是精排模塊,採用類似 ColBERT 的 token 級交互,但更輕量,因為 query 和 doc 只使用少量 token,大大提升語義匹配精度。
UniRank 與 UniTouch 用的是同一套語義編碼框架,這樣的好處是召回和排序兩個階段共用統一的語義表徵方式,避免表徵差異導致的匹配偏差。
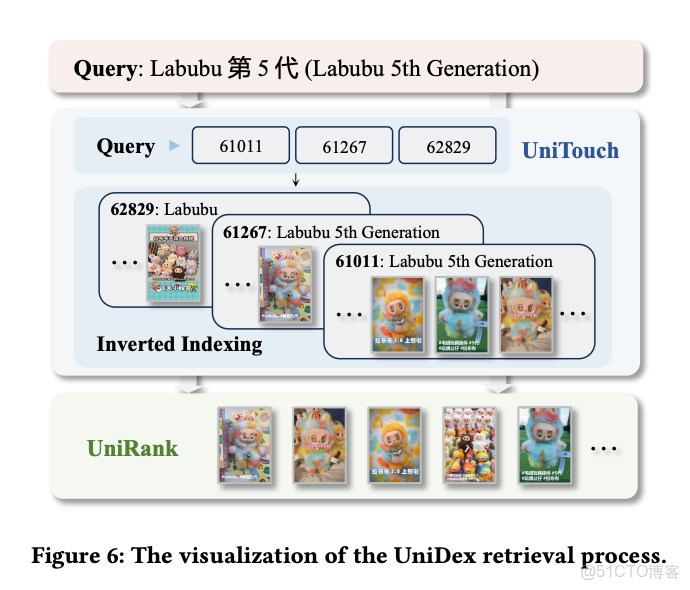
所以它是用了一個統一的語義建模框架,這就是論文標題為什麼叫"Unified Semantic Modeling"的原因。
UniDex 的實際效果
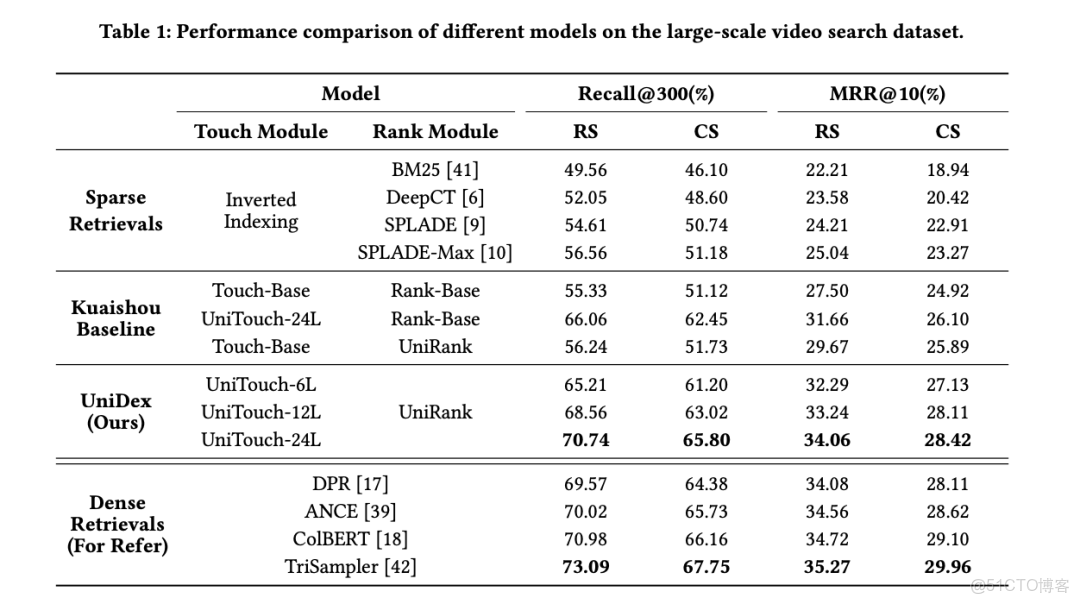
看 Table 1,這個對比很説明問題。
傳統 BM25 的 Recall@300 是 49.56%,SPLADE 這種神經稀疏檢索做到 56.56%,快手自己的 baseline 是 55.33%,UniDex 直接幹到 70.74%,逼近了 Dense Retrieval 的效果上限。
再看 Table 5 的線上數據,在快手短視頻搜索裏(10 億視頻庫),CTR、VPD、LPC 這些用户滿意度指標全漲了。
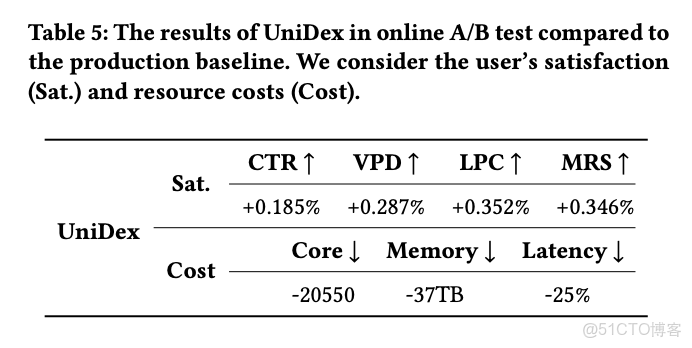
更關鍵的是資源消耗: CPU 核數-20550(節省了 2 萬多核), 內存節省 37TB ,響應延遲降低 25% 。
為什麼能省資源? 傳統的同義詞擴展、query 改寫、多路召回、複雜 term 匹配規則...都省了, UniDex 只需要一次模型推理,得到 query 語義 ID,查 UniDex 的語義倒排索引就可以,簡潔高效。
UniSearch:統一搜索三段式
再來聊一下 UniSearch。
UniDex 是重構了搜索的"索引層",那麼 UniSearch 則是動了搜索的架構。
傳統搜索(包括用了 UniDex 的系統)本質還是檢索範式,召回-粗排-精排,UniSearch 是生成範式,Query 直接生成 Top-K 結果的語義 ID 序列,統一了三段式。
“統一”的三層含義
看到一個模型替代三段式,很多人覺得就是把召回、粗排、精排三個模型合併成一個大模型。
太淺了。
傳統級聯架構的問題不是"模型太多",而是召回、粗排、精排的優化目標都不一致。
而且號稱"生成式推薦"的相關模型們,也沒有逃出這個陷阱,也是兩階段,先訓練 Video Encoder,再訓 Generator。
UniSearch 是一個“真端到端”的訓練架構。
把 Search Generator 和 Video Encoder 放到一個訓練框架裏,聯合優化。
看架構圖。Search Generator 負責理解 query、生成語義 ID 序列;Video Encoder 負責把視頻編碼成 embedding、通過 VQ-VAE 量化成語義 ID。
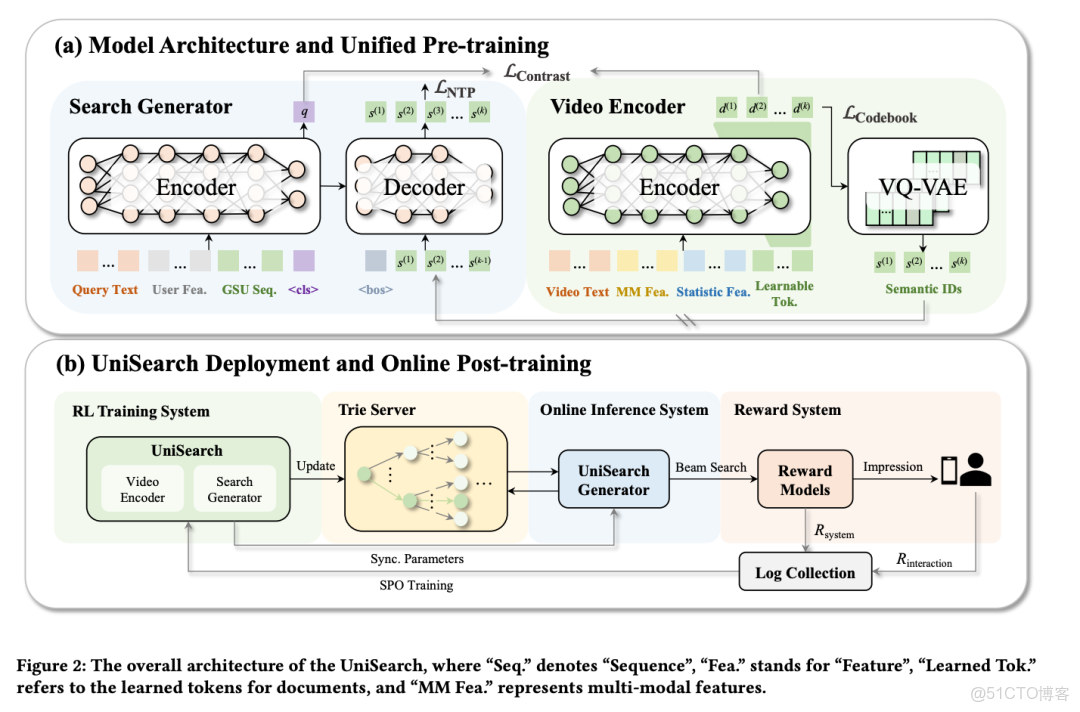
兩個模型雖然獨立,但關鍵在於它們通過統一的損失函數綁在一起。論文裏的聯合損失函數寫得很清楚:
L = λ1·L_contrast + λ2·L_codebook + λ3·L_NTP- L_contrast:query 和 video 的語義對齊。
- L_codebook:VQ-VAE 的 codebook 質量。關鍵是這個 codebook 是可學習的。
- L_NTP:Generator 的生成準確性。
從語義對齊、離散化質量、生成準確性,全程一個目標函數聯合優化。
論文裏還有個很巧妙的設計。
每個視頻用 k 個語義 ID 表示,但這 k 個 ID 不是獨立學的,而是用殘差對比學習(Residual Contrastive Learning)逐步遞進:
- 第 1 步生成:ID_1(粗粒度語義:動畫類)
- 第 2 步生成:ID_2(細粒度語義:兒童向)
- 第 3 步生成:ID_3(最細粒度:熊出沒 IP)
分別對應召回的粗粒度、粗排的中粒度、精排的細粒度,自然形成了從粗到細的層次結構,模擬了傳統三階段的能力遞進。
UniSearch 要在直播搜索全量上線,面臨的第一個問題就是:直播內容的極端動態性。
電商搜索,商品相對穩定,小時級更新就夠了。短視頻搜索,內容緩慢增長,分鐘級更新也能接受。
但直播不一樣。
11:00:00,某主播開播"熊出沒玩具開箱";11:30:00,轉播"王者榮耀";12:00:00,下播。內容每分鐘都在變,直播間每秒都在開播/下播。快手有數十萬併發直播間,每秒數千次狀態變化,所以 UniSearch 的實時鏈路必須做到秒級響應。
所以線上實時鏈路裏是怎麼跑的呢?
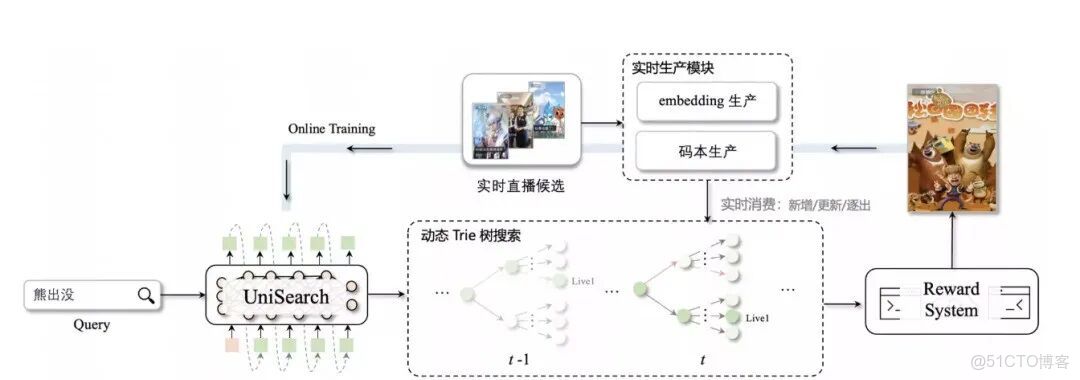
看架構圖,整個鏈路分三塊:以用户輸入 Query "熊出沒" 為例進行説明:
實時生產模塊
這是保證內容時效性的關鍵。
Embedding 生產:直播間一開播,Video Encoder 立刻提取標題、封面、主播信息等特徵,編碼成語義向量。
碼本生產:語義向量通過 VQ-VAE 量化成離散的語義 ID。論文設計是 k=3 層 ID,每層 512 個 codebook,總共 512³≈1.3 億種組合。
實時消費:新增/更新/逐出。
- 新增:直播間開播,生成語義 ID,寫入 Trie 樹。
- 更新:主播改變內容(從聊天變打遊戲),1 分鐘內 embedding 刷新,ID 重新映射。
- 逐出:直播間下播,從 Trie 樹刪除對應路徑。
論文説的是"1 分鐘時間窗口"——直播間的表徵每分鐘更新一次,保證內容和 ID 的一致性。
動態 Trie 樹
這是整個實時鏈路的核心創新。
傳統生成式模型的致命問題:可能生成不存在的 ID 組合。Trie 樹能實時監聽"碼本生產"的數據流,維護所有在線直播間的有效路徑。
圖上畫的很清楚,t-1 時刻的 Trie 和 t 時刻的 Trie,結構在動態變化——有新節點加入,有舊節點移除。
UniSearch 輸出的不是直接的 ID 序列,而是碼本概率分佈。然後在 Trie 樹上做 beam search。
第1步生成:ID=57099(動畫類)問Trie:"接下來能選哪些?" Trie返回:[315147, 315148, 315149](當前在線的有效子節點)
第2步生成:從[315147, 315148, 315149]裏選,假設選了315147(兒童向) 再問Trie:"接下來能選哪些?" Trie返回:[315371, 315372, ...]
第3步生成:選315371(熊出沒IP)
每一步生成時,Trie 只允許選擇"有效路徑",保證生成的路徑一定指向真實的直播間。
論文數據:有效生成率從 51.3% 提升到 99.8%。
Reward System + Online Training
右側的 Reward System 收集兩種信號:
- R_system:精排模型的系統評分(相關性、質量)
- R_interaction:用户真實行為(點擊、觀看、關注)
合成最終獎勵:R = γ1×R_system + γ2×R_interaction
每天晚上,左側的 Online Training 用 SPO 算法(Search Preference Optimization)更新模型。
比如發現用户更喜歡"玩具開箱"類直播? → 增加相關 ID 的生成概率。第二天早上新參數同步到線上,系統在持續進化。
這就是工業級生成式搜索的完整閉環。
UniSearch 在快手直播搜索全量上線後,TPC +3.31% 是快手直播搜索近兩年單次實驗的最大收益。
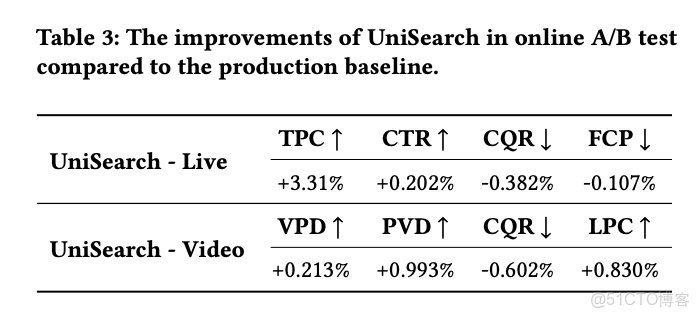
更有意思的是深入分析:65% 的增長來自長尾 query,因為 UniSearch 本質是語義理解提升了。
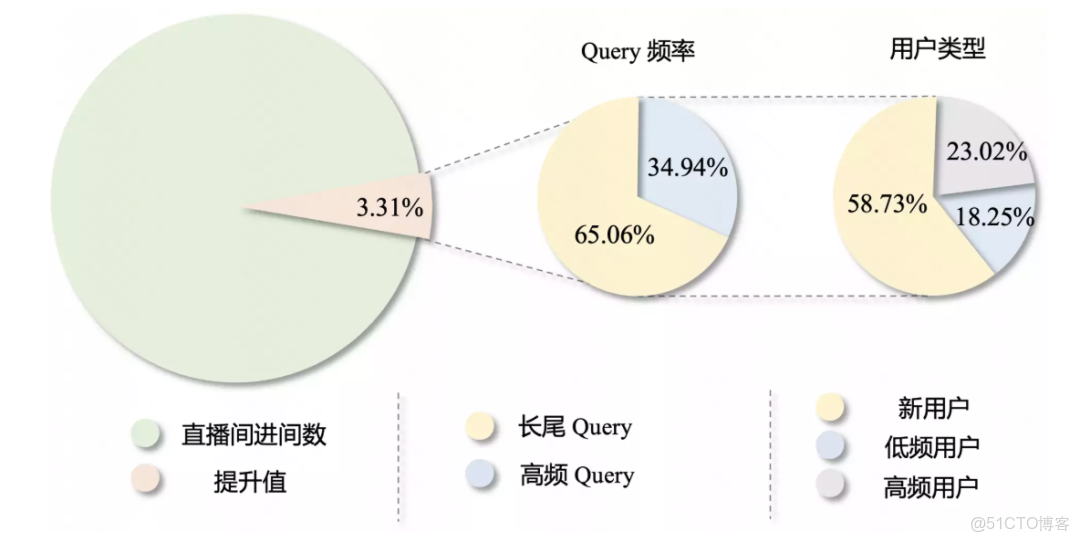
還有,58% 的增長來自新用户。
新用户沒有歷史行為,傳統推薦很難個性化。UniSearch 靠語義理解能給出更準確的搜索結果。
最後
當所有人都在討論"大模型能做什麼"的時候,大部分答案都指向:生成文本、寫代碼、做助手。彷彿生成式 AI 的全部價值就是"替代人類生產內容"。
但快手這個案例讓我看到了完全不同的可能性:
生成式 AI 不一定要生成內容,它可以用來重構系統架構。
UniDex 和 UniSearch 的核心都是“統一”——統一的語義空間、統一的優化目標、統一的訓練框架。
端到端優化,消除系統內耗,這應該是工業級系統的護城河。