










🏆🏆🏆教程全知識點簡介:微服務保護、服務異步通信、消息中間件部署、分佈式事務、搜索引擎、緩存、數據同步以及相關組件的安裝配置等技術要點。在微服務保護方面,介紹了 Sentinel 的基礎知識,包括雪崩問題、超時處理、艙壁模式、斷路器機制,以及不同服務保護技術的對比;講解了流量控制(簇點鏈路、流控模式、熱點參數限流)、隔離與降級(FeignClient 整合 Sentinel、線程隔離)、授權規則(自定義異常結果)及規則持久化(規則管理模式與 pull 模式),並演示了基於 Nacos 的規則持久化改造。服務異步通信部分探討了消息可靠性(生產者消息確認、Return 回調、ConfirmCallback)、死信交換機、TTL 隊列等高級應用。RabbitMQ 部署指南涵蓋了單機部署、DelayExchange 插件安裝、集羣部署、鏡像模式等內容。分佈式事務部分介紹了 CAP 定理、BASE 理論、常見解決方案,Seata 的基礎與部署(TC 服務部署、Nacos 配置、數據庫表創建)、多種事務模式(XA 模式及優缺點、四種模式對比)和高可用架構。分佈式搜索引擎章節講解了 Elasticsearch 的原理(ELK 技術棧、倒排索引)、索引庫與文檔操作、RestAPI 與 RestClient 的使用、排序與高亮、酒店搜索案例(分頁、競價排名、ad標記、算分函數)、自動補全、數據同步(同步調用、監聽 binlog)、集羣搭建與腦裂問題、分片存儲測試,以及單點 ES、Kibana、IK 分詞器安裝。緩存部分介紹了 Redis 持久化(RDB 與 AOF 對比)、單機安裝 Redis、Redis 集羣、多級緩存(JVM 進程緩存、Caffeine)、請求參數處理、Tomcat 查詢、HTTP 工具與 CJSON 工具類、Redis 緩存查詢。數據同步與網關部分包括 Canal 安裝(開啓 MySQL 主從、設置權限)、OpenResty 安裝(開發庫、目錄結構、環境變量配置)及運行流程。

📚📚👉👉👉本站這篇博客: https://segmentfault.com/a/1190000047235729 中查看
📚📚👉👉👉本站這篇博客: https://segmentfault.com/a/1190000047225271 中查看
<!-- end:bj1 -->
✨ 本教程項目亮點
🧠 知識體系完整:覆蓋從基礎原理、核心方法到高階應用的全流程內容
💻 全技術鏈覆蓋:完整前後端技術棧,涵蓋開發必備技能
🚀 從零到實戰:適合 0 基礎入門到提升,循序漸進掌握核心能力
📚 豐富文檔與代碼示例:涵蓋多種場景,可運行、可複用
🛠 工作與學習雙參考:不僅適合系統化學習,更可作為日常開發中的查閲手冊
🧩 模塊化知識結構:按知識點分章節,便於快速定位和複習
📈 長期可用的技術積累:不止一次學習,而是能伴隨工作與項目長期參考
🎯🎯🎯全教程總章節

🚀🚀🚀本篇主要內容
分佈式搜索引擎01
-- elasticsearch基礎
0.學習目標
1.初識elasticsearch
1.1.瞭解ES
1.1.1.elasticsearch的作用
elasticsearch是一款非常強大的開源搜索引擎,具備非常多強大功能,可以幫助 從海量數據中快速找到需要的內容
例如:
-
在GitHub搜索代碼
-
在電商網站搜索產品
-
在百度搜索答案
-
在打車軟件搜索附近的車
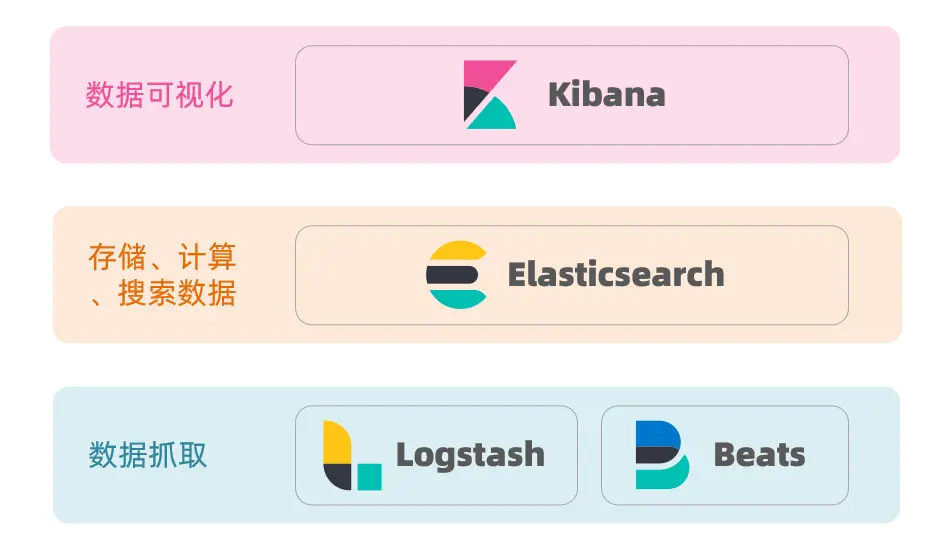
1.1.2.ELK技術棧
elasticsearch結合kibana、Logstash、Beats,也就是elastic stack(ELK)。被廣泛應用在日誌數據分析、實時監控等領域:
而elasticsearch是elastic stack的核心,負責存儲、搜索、分析數據。
1.1.3.elasticsearch和lucene
elasticsearch底層是基於lucene來實現的。
Lucene是一個Java語言的搜索引擎類庫,是Apache公司的頂級項目,由DougCutting於1999年研發。官網地址:https://lucene.apache.org/ 。

elasticsearch的發展歷史:
- 2004年Shay Banon基於Lucene開發了Compass
- 2010年Shay Banon 重寫了Compass,取名為Elasticsearch。

1.1.4.為什麼不是其他搜索技術?
目前比較知名的搜索引擎技術排名:
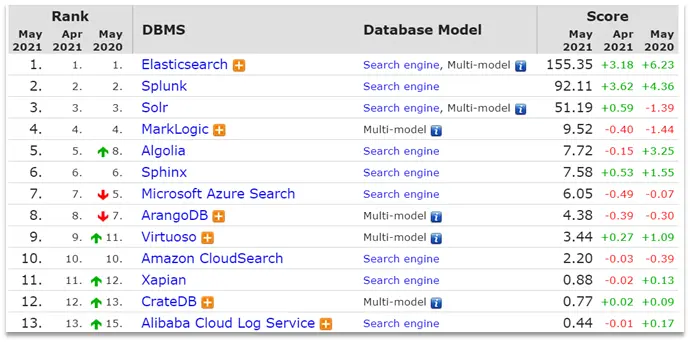
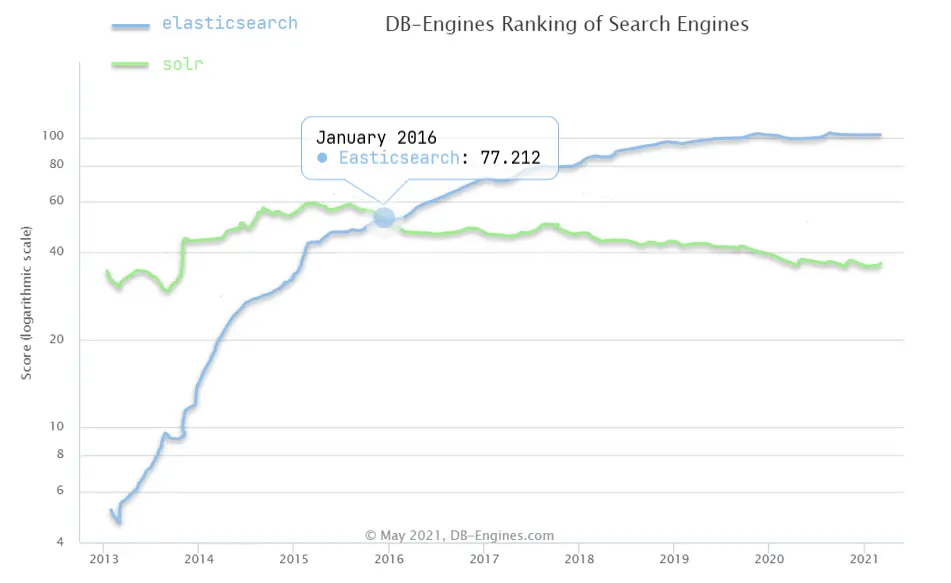
雖然在早期,Apache Solr是最主要的搜索引擎技術,但隨着發展elasticsearch已經漸漸超越了Solr,獨佔鰲頭:
1.1.5.總結
什麼是elasticsearch?
- 一個開源的分佈式搜索引擎,可以用來實現搜索、日誌統計、分析、系統監控等功能
什麼是elastic stack(ELK)?
- 是以elasticsearch為核心的技術棧,包括beats、Logstash、kibana、elasticsearch
什麼是Lucene?
- 是Apache的開源搜索引擎類庫,提供了搜索引擎的核心API
1.2.倒排索引
倒排索引的概念是基於MySQL這樣的正向索引而言的。
1.2.1.正向索引
那麼什麼是正向索引呢?例如給下表(tb_goods)中的id創建索引:
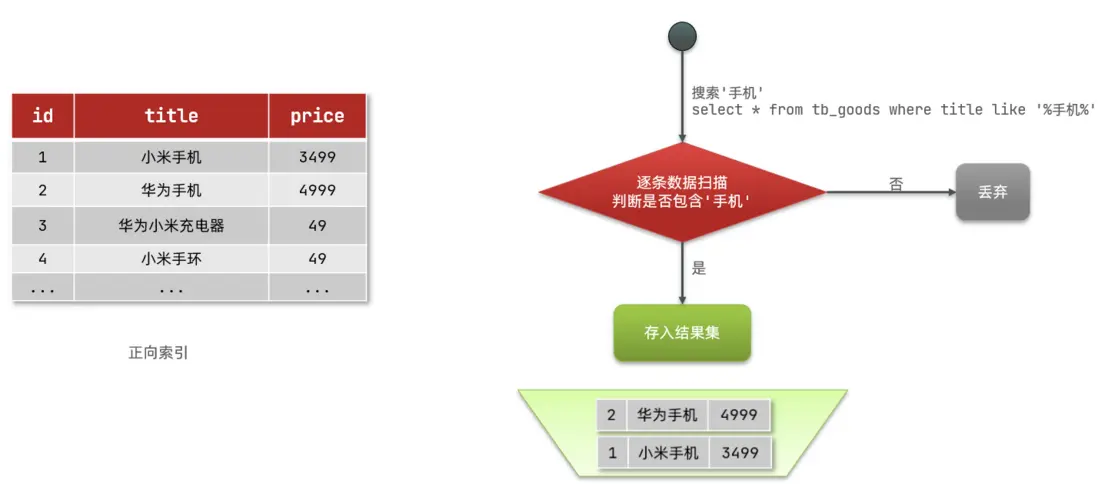
如果是根據id查詢,那麼直接走索引,查詢速度非常快。
但如果是基於title做模糊查詢,只能是逐行掃描數據,流程如下:
1)用户搜索數據,條件是title符合"%手機%"
2)逐行獲取數據,比如id為1的數據
3)判斷數據中的title是否符合用户搜索條件
4)如果符合則放入結果集,不符合則丟棄。回到步驟1
逐行掃描,也就是全表掃描,隨着數據量增加,其查詢效率也會越來越低。當數據量達到數百萬時,就是一場災難。
1.2.2.倒排索引
倒排索引中有兩個非常重要的概念:
- 文檔(
Document):用來搜索的數據,其中的每一條數據就是一個文檔。例如一個網頁、一個產品信息 - 詞條(
Term):對文檔數據或用户搜索數據,利用某種算法分詞,得到的具備含義的詞語就是詞條。例如:我是中國人,就可以分為:我、是、中國人、中國、國人這樣的幾個詞條
創建倒排索引是對正向索引的一種特殊處理,流程如下:
- 將每一個文檔的數據利用算法分詞,得到一個個詞條
- 創建表,每行數據包括詞條、詞條所在文檔id、位置等信息
- 因為詞條唯一性,可以給詞條創建索引,例如hash表結構索引
如圖:

倒排索引的搜索流程如下(以搜索"華為手機"為例):
1)用户輸入條件"華為手機"進行搜索。
2)對用户輸入內容分詞,得到詞條:華為、手機。
3)拿着詞條在倒排索引中查找,可以得到包含詞條的文檔id:1、2、3。
4)拿着文檔id到正向索引中查找具體文檔。
如圖:
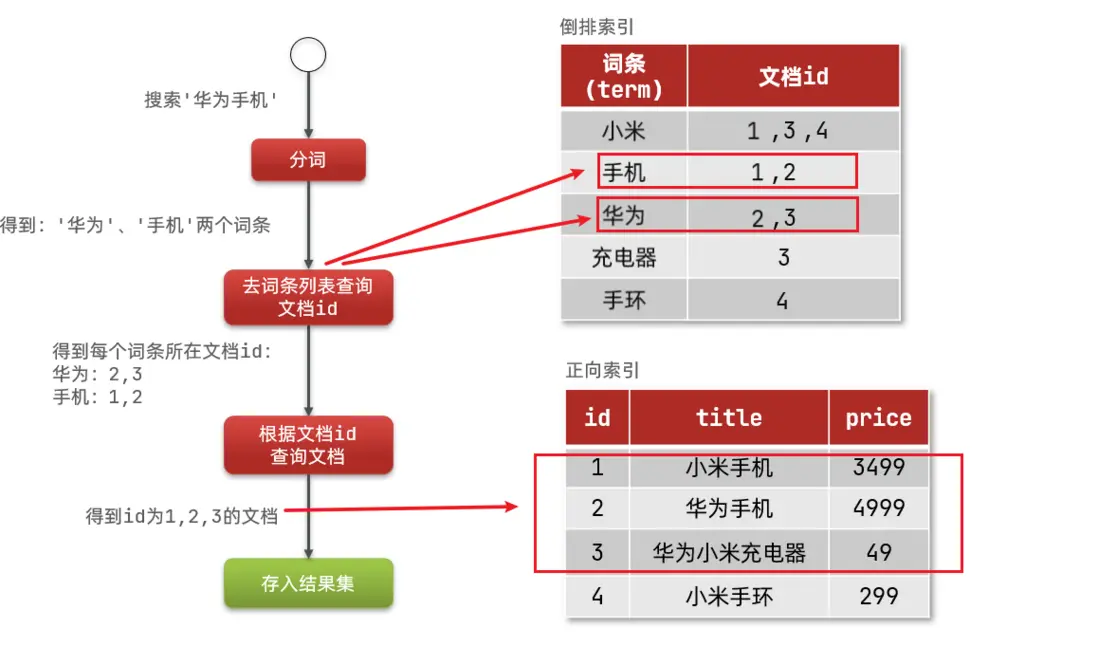
雖然要先查詢倒排索引,再查詢倒排索引,但是無論是詞條、還是文檔id都建立了索引,查詢速度非常快!無需全表掃描。
1.2.3.正向和倒排
那麼為什麼一個叫做正向索引,一個叫做倒排索引呢?
- 正向索引是最傳統的,根據id索引的方式。但根據詞條查詢時,必須先逐條獲取每個文檔,然後判斷文檔中是否包含所需要的詞條,是根據文檔找詞條的過程。
- 而倒排索引則相反,是先找到用户要搜索的詞條,根據詞條得到保護詞條的文檔的id,然後根據id獲取文檔。是根據詞條找文檔的過程。
是不是恰好反過來了?
那麼兩者方式的優缺點是什麼呢?
正向索引:
-
優點:
- 可以給多個字段創建索引
- 根據索引字段搜索、排序速度
2.索引庫操作
索引庫就類似數據庫表,mapping映射就類似表的結構。
要向es中存儲數據,必須先創建“庫”和“表”。
2.1.mapping映射屬性
mapping是對索引庫中文檔的約束,常見的mapping屬性包括:
-
type:字段數據類型,常見的簡單類型有:
- 字符串:text(可分詞的文本)、keyword(精確值,例如:品牌、國家、ip地址)
- 數值:long、integer、short、byte、double、float、
- 布爾:boolean
- 日期:date
- 對象:object
- index:是否創建索引,默認為true
- analyzer:使用哪種分詞器
- properties:該字段的子字段
例如下面的json文檔:
{
"age": 21,
"weight": 52.1,
"isMarried": false,
"info": "黑馬程序員Java講師",
"email": "zy@itcast.cn",
"score": [99.1, 99.5, 98.9],
"name": {
"firstName": "雲",
"lastName": "趙"
}
}對應的每個字段映射(mapping):
- age:類型為 integer;參與搜索,因此需要index為true;無需分詞器
- weight:類型為float;參與搜索,因此需要index為true;無需分詞器
- isMarried:類型為boolean;參與搜索,因此需要index為true;無需分詞器
- info:類型為字符串,需要分詞,因此是text;參與搜索,因此需要index為true;分詞器可以用ik_smart
- email:類型為字符串,但是不需要分詞,因此是keyword;不參與搜索,因此需要index為false;無需分詞器
- score:雖然是數組,但是 只看元素的類型,類型為float;參與搜索,因此需要index為true;無需分詞器
-
name:類型為object,需要定義多個子屬性
- name.firstName;類型為字符串,但是不需要分詞,因此是keyword;參與搜索,因此需要index為true;無需分詞器
- name.lastName;類型為字符串,但是不需要分詞,因此是keyword;參與搜索,因此需要index為true;無需分詞器
2.2.索引庫的CRUD
這裏 統一使用Kibana編寫DSL的方式來演示。
2.2.1.創建索引庫和映射
基本語法:
- 請求方式:PUT
- 請求路徑:/索引庫名,可以自定義
- 請求參數:mapping映射
格式:
PUT /索引庫名稱
{
"mappings": {
"properties": {
"字段名":{
"type": "text",
"analyzer": "ik_smart"
},
"字段名2":{
"type": "keyword",
"index": "false"
},
"字段名3":{
"properties": {
"子字段": {
"type": "keyword"
}
}
},
// ...略
}
}
}示例:
PUT /heima
{
"mappings": {
"properties": {
"info":{
"type": "text",
"analyzer": "ik_smart"
},
"email":{
"type": "keyword",
"index": "falsae"
},
"name":{
"properties": {
"firstName": {
"type": "keyword"
}
}
},
// ... 略
}
}
}2.2.2.查詢索引庫
基本語法:
- 請求方式:GET
- 請求路徑:/索引庫名
- 請求參數:無
格式:
GET /索引庫名示例:
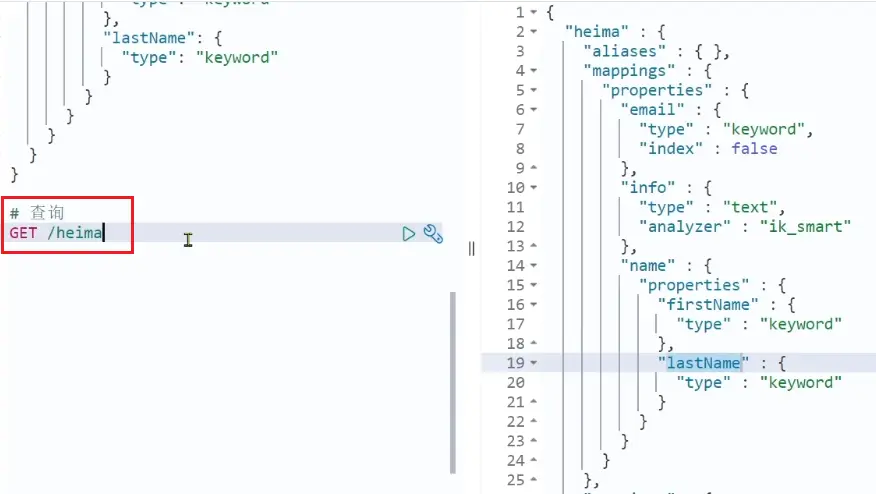
2.2.3.修改索引庫
倒排索引結構雖然不復雜,但是一旦數據結構改變(比如改變了分詞器),就需要重新創建倒排索引,這簡直是災難。因此索引庫一旦創建,無法修改mapping。
雖然無法修改mapping中已有的字段,但是卻允許添加新的字段到mapping中,因為不會對倒排索引產生影響。
語法説明:
PUT /索引庫名/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}示例:
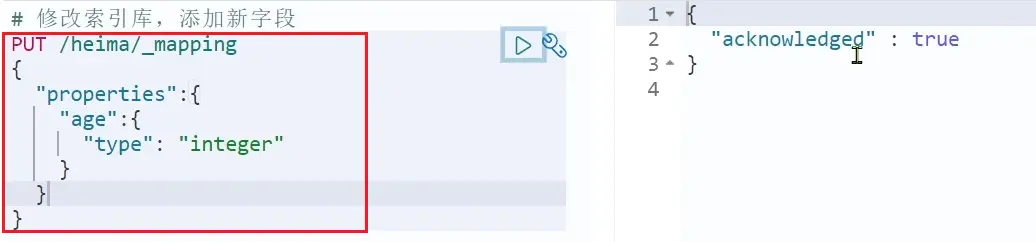
2.2.4.刪除索引庫
語法:
- 請求方式:DELETE
- 請求路徑:/索引庫名
- 請求參數:無
格式:
DELETE /索引庫名在kibana中測試:

2.2.5.總結
索引庫操作有哪些?
- 創建索引庫:PUT /索引庫名
- 查詢索引庫:GET /索引庫名
- 刪除索引庫:DELETE /索引庫名
- 添加字段:PUT /索引庫名/_mapping
🚀✨ (未完待續)項目系列下一章
📚下一篇 將進入更精彩的環節!
🔔 記得收藏 & 關注,第一時間獲取更新!
🍅 一起見證整個系列逐步成型的全過程。
