

1、輕量化網絡
輕量化網絡是一類計算複雜度低、參數量小、內存佔用少的神經網絡模型,其核心目標是在保證模型性能(如精度、速度)的前提下,降低模型的計算和存儲開銷,使其能高效部署在移動端、嵌入式設備、邊緣計算節點等資源受限的硬件平台上。與傳統大型模型相比,輕量化網絡通過結構優化、參數壓縮等手段,實現了”小而精“的特徵,是AI從雲端走向終端的關鍵技術之一。
輕量化網絡的實現路徑可分為四大類:壓縮已訓練模型、直接訓練輕量化網絡、加速卷積運算、硬件部署優化。
- 壓縮已訓練好的模型:該方法針對已訓練完成的大型模型(如預訓練模型)進行”瘦身“,在損失少量京都的前提下大幅減少參數量和計算量。核心技術包括知識蒸餾、權重量化(將神經網絡中32位浮點型權重轉換為低比特整數或二進制,減少模型的存儲大小和計算複雜度,量化的本質是通過近似值替代準確值,通過精度損失換效率提升)、剪枝(移除神經網絡中冗餘的參數或結構,保留對模型性能貢獻大的部分)。
- 直接訓練輕量化網絡:從模型設計之初就採用輕量化結構,同故宮創新的網絡架構減少冗餘計算,無需依賴預訓練模型壓縮。核心思路是用高效的操作替代傳統卷積。
- 加速卷積運算:通過數學優化或硬件友好的操作,加速卷積計算過程,不改變模型結構本身。
- 硬件部署:針對特定硬件平台的架構特點,對模型進行適配和優化,最大化硬件利用率。
2、算法庫
- openMMLab:是由港中文商湯科技聯合實驗室發起的開源計算機視覺算法體系,其以模塊化設計為核心,提供從數據加載、模型構建、訓練優化到推理部署的全流程工具鏈。
- RepDistiller:是由清華大學團隊於2020年開源的知識蒸餾專用算法庫,專注於通過結構重參數化技術提升知識蒸餾的效率和性能,基於pytorch實現,是輕量化模型壓縮領域的經典工具之一。
3、論文精讀:Distilling the Knowledge in a Neural Network
(1)摘要
多模型集成(在相同數據上訓練多個不同模型並平均預測結果)是提升機器學習算法性能的簡單有效方法,但集成模型預測過程繁瑣且計算成本高,尤其是當單個模型為大型神經網絡時,難以部署給大量用户。Caruana等人的研究表明,可將集成模型中的“知識”壓縮到單個模型中,使其更易部署。本文進一步發展了這一方法,採用不同的壓縮技術。
通過知識蒸餾技術,將複雜集成模型的“暗知識”轉移到單個輕量模型中,解決集成模型部署難的問題,同時提出更高效的集成範式提升模型性能。
(2)引言
我們經常會在訓練階段和部署階段用同一個模型,儘管訓練和部署的需求不一樣。訓練的目標是提取數據集中的特徵進行學習,會耗費很多計算資源。但部署時需求變了,如果需要部署給十幾億用户時,對實時性的要求很高,儘量少消耗計算資源。當笨重的模型訓練好後,可以用知識蒸餾的方式把其中的知識遷移到單個小模型上。
如何定義知識?教師網絡中預測結果中各類別概率的相對大小,如一張馬的照片喂到教師網絡,教師網絡會給出不同類別的概率,可能也有驢的概率,那麼不同類別之間的相對大小(或錯誤類別直接的相對大小)隱式包含了知識。不僅要告訴學生網絡這是一匹馬,還要告訴學生更像馬而更不像汽車。
教師網絡一般是個分類網絡,優化一個平均對數似然概率(優化一個交叉熵損失函數)。比如有三個類別“貓、狗、豬”,有三張圖片,各佔一個類別,那麼網絡會給每個照片對於每個類別都給一個預測值。我們希望讓教師網絡三種圖片全部預測正確的事件發送的概率最大(把正確類別預測的概率值乘起來,即似然概率),我們的目標就是最大化這個似然概率。
訓練神經網絡:有一個神經網絡,裏面有若干個權重,我們先求出損失函數,然後求出損失函數相對於每一個權重的偏導數,然後微調每一個權重使得損失函數最小化。(可以把每個權重想象成很多個水龍頭,求得偏導數後就知道水龍頭往哪個方向擰可以使得整個損失函數最小化,不斷迭代、微調,最後訓練出來的網絡使得損失函數收斂到一個很小的程度)
我們的目標是,平常用訓練集來訓練,最終到測試集上去驗證效果。訓練集好比是測試題,測試集是高考集,我們的目的是通過訓練集上的訓練讓他在測試集上表現好。若平時作業做很好,但高考考砸了就屬於過擬合。
如何讓學生網絡來學習教師模型?一個非常明顯的方法就是直接使用教師網絡的soft targets作為學生網絡的標籤去學習。這時可以用一個額外的數據集中的每個圖片喂到教師網絡中,獲取其對每張圖片的soft target,用這個soft target和數據集來訓練學生網絡。如果這個soft targets的熵很高(不同類別概率之間的差異很小),這樣可以體現出更豐富的信息。現在的交叉熵用soft targets(不是之前的hard targets非0即1了)。但是這種方法的一個缺點就是可能會導致不太像的類別非常低的置信度。我們可以用提高温度的方式讓soft targets變得更軟(不同概率之間的差別變小)。
知識蒸餾的另外一個好處是教師網絡已經訓練好了,可以用一個無限大的非監督數據集來獲得教師網絡的soft targets,以此來訓練學生網絡。
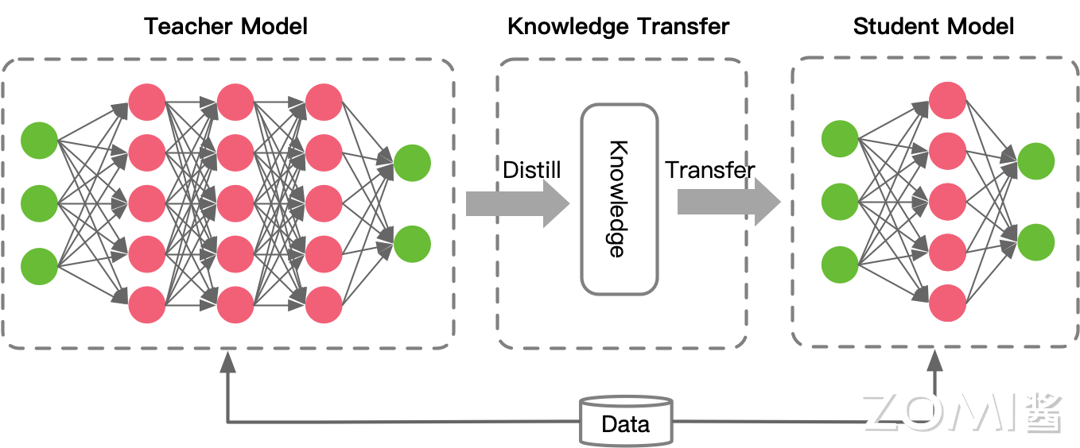
(3)整體介紹
知識蒸餾系統通常由三部分組成,分別是知識、蒸餾算法、師生架構。
- 知識:從教師模型中提取的有價值的信息,可以是輸出的logits(未歸一化概率)、中間層的特徵表示或模型參數等。
- 蒸餾算法:用於將教師模型的知識傳遞給學生模型的具體方法和技術。
- 師生架構:指的是教師和學生模型的設計和配置方式,包括它們之間的交互模式和訓練過程。
(4)知識類型
教師模型網絡中的知識來源很多,可以分為四類:Response-based、Feature-based、Relation-based、Architecture-based。
- response-based:基於響應的知識通常是指教師模型的輸出,如分類任務中通過softmax處理後輸出的類型概率分佈(soft targets)。該方法利用教師模型對輸入數據的預測結果來幫助學生模型學習,從而提高性能。
- 假設z_t為教師模型的輸出logits,z_s為學生模型的輸出logits,那麼這裏的蒸餾損失表示為L_R(z_t, z_s),降低這個蒸餾損失即可。
- 這種方法的優勢在於可以只關注模型對樣本的預測輸出,而不用關注神經網絡模型的內在結構或特徵表達。
- feature-based knowledge:上面一種方法中,輸出層提供的信息是有限的,在神經網絡中,數據通過多個層次的神經元進行傳遞和處理,每一層都可以看作是一次特徵提取。考慮到網絡的複雜,因此模型的中間層的輸出,也可以作為知道學生模型學習的知識。
- 雖然基於特徵的知識轉移為學生提供了更多信息,但是由於學生模型和教師模型的結構不一致,如何從教師模型中選擇某一層網絡,從學生模型中選哪一層網絡進行模仿也是一個問題。
- relation-based knowledge:該知識類型認為,知識不僅是特徵輸出的結果,而且還可能是網絡層與層之間的及樣本數據之間的關係。傳統蒸餾只教“單個樣本的特徵”(比如貓有鬍鬚),但樣板間的關係能幫模型理解更抽象的規律:如即使遇到沒見過的動物(如狐狸),模型也能通過“狐狸和貓/狗的相似度”判斷它屬於“陸生寵物”類,而不是“水生動物”類。
- 基於關係的知識蒸餾,本質上是讓學生模型學習教師模型對“數據之間隱藏聯繫”的理解,而不只是表面的特徵。1)網絡層與層之間的關係:教你“步驟的邏輯”。2) 樣本之間的關係:教你“數據的分類和關聯”(如哪些菜是一類,哪些動物更像)。
(5)知識蒸餾方式
一般分為三種:離線蒸餾、在線蒸餾以及自蒸餾。
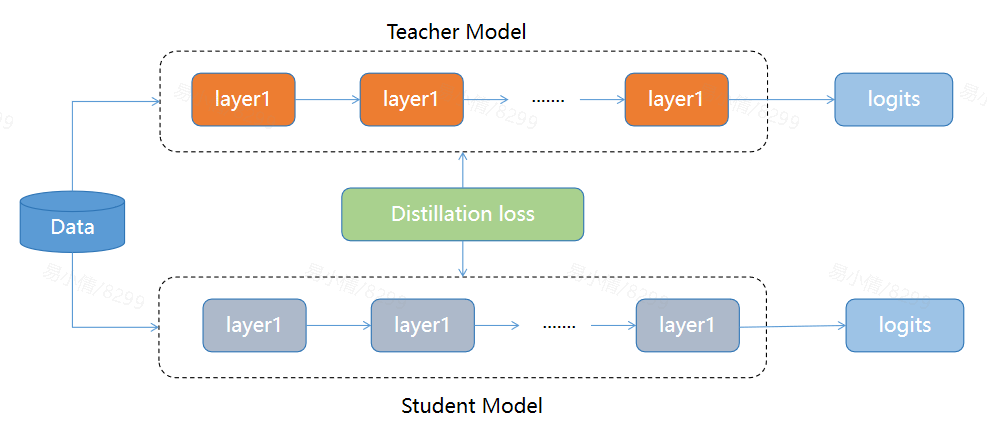
- 離線蒸餾:教師模型已完成訓練,並且其參數在整個過程中被凍結。主要包含以下三個過程:
- 蒸餾前教師模型預訓練:教師模型在大規模數據集上訓練,收斂。這個過程通常耗時耗資源。
- 知識提取:將教師模型的知識提取處理,這裏可以用上面説的三種常用的知識。
- 學生模型的訓練:這訓練過程中,使用教師模型傳授的知識作為直到。學生模型通過一個額外的蒸餾損失函數,學習如何模擬教師模型的輸出。常見的蒸餾損失函數包括交叉熵損失和均方誤差損失。
- 該方法重點在於知識遷移,教師模型的參數量很大,一些大模型會通過這種方式得到較小模型(如BERT通過蒸餾學習得到tinyBERT)。優點在於:可以靈活選擇預訓練好的教師模型,訓練過程只需關注學生模型的學習,而不用動教師模型的參數,簡單可控。缺點是:學生模型非常依賴教師模型。
- 在線蒸餾:教師模型不再是預訓練好的,而是一起參與訓練。這種方式使得教師和學生可以動態適應數據變化和任務需求,更適合跨領域、多模態等場景。
- 自蒸餾:教師模型和學生模型採用相同的網絡模型的在線蒸餾。在該過程中,雪漠西從自身的輸出中學習,説明學生模型將深層的信息傳遞給淺層,以指導自身的訓練,而無需依賴教師模型。(比喻:離線蒸餾是知識淵博的老師向學生傳遞知識,在線蒸餾是老師和學生一起學習,自蒸餾是自學)
- 該方法主要是為了解決傳統兩階段蒸餾方法的問題:1)預先訓練大模型會消耗大量時間和資源,且學生和教師之間能力不匹配,可能導致學生無法有效學習老師。
- 該方法不依賴教師指導,而是通過模型自身輸出來學習,使得學生在沒有指導的情況下也能自我提升,加快訓練。
(6)蒸餾算法
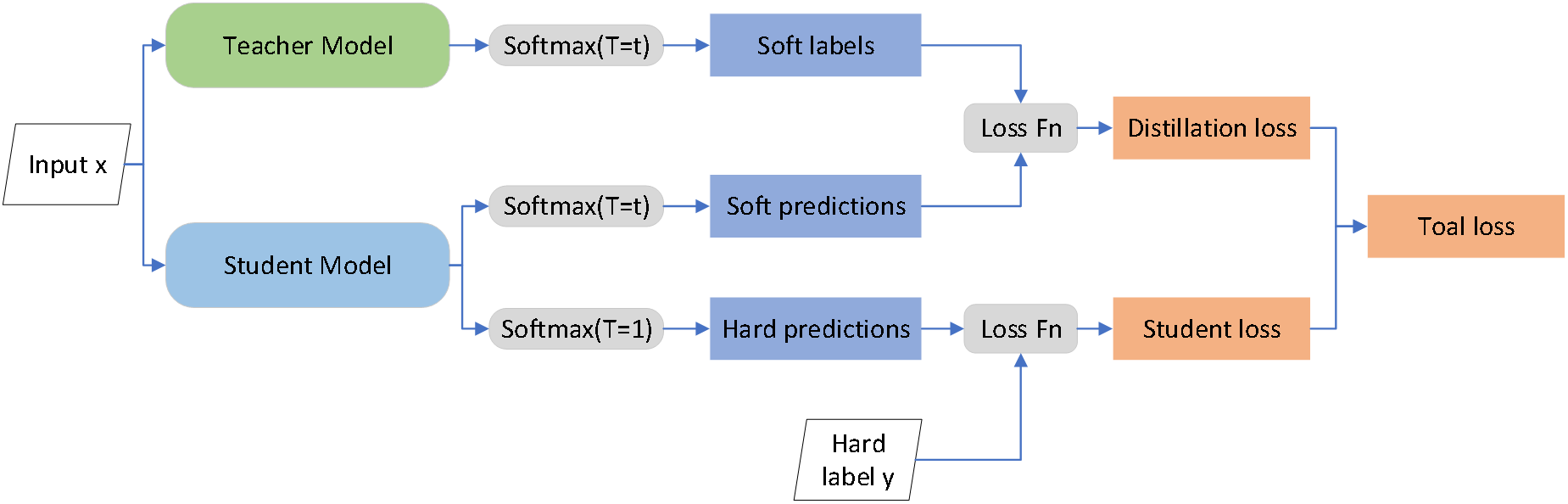
知識蒸餾的核心邏輯是教師模型向“學生模型”傳遞經驗,讓輕量化的小模型在保留大模型性能的同時實現高效部署。具體來説,教師網絡會對輸入數據生成經過温度T調整的“軟標籤”——這種標籤並非簡單的“非黑即白”分類結果,而是通過平滑的概率分佈傳遞類別間的相似性等隱藏知識(比如貓和狗同屬動物的關聯);學生網絡則同步進行雙向學習,一方面用相同温度T生成軟標籤,與教師的軟標籤計算損失以學習隱藏知識,另一方面直接輸出常規softmax結果與真實硬標籤擬合以保證基礎精度,最終通過加權求和的總損失完成訓練,推理時學生網絡直接輸出常規softmax結果即可。
温度T是調節軟標籤“軟硬度”的關鍵參數,它就像教師講解知識的“深度”:T越大,軟標籤的概率分佈越平滑,隱藏知識越豐富(比如貓90%、狗8%的分佈能體現兩者的相似性),但T過大可能導致分佈被拉平(如各類別概率接近30%),反而讓學生無法捕捉有效信息;T越小,軟標籤越尖鋭接近硬標籤,雖能快速傳遞核心分類知識,但會丟失隱藏的關聯信息。這種“軟標籤傳遞隱藏知識+硬標籤保證基礎精度”的雙向學習,讓小模型在參數量減少70%、速度提升3倍的情況下,性能仍接近甚至超過大模型,成為AI從雲端走向手機、嵌入式設備等終端場景的關鍵技術。
(7)實驗
為了看知識蒸餾的效果,我們訓練了一個教師網絡(2個隱含層,每個隱含層有1200個relu函數的神經元,這個網絡被正則化了,使用了dropout和限制權重大小的正則化。droput可以視為一個非常有效的防止過擬合的手段。)學生網絡有2個隱含層,每個隱含層有800個relu函數的神經元,沒有使用正則化。
如果用T=20,用教師網絡的soft targets來做學生網絡的標籤來訓練,學生網絡的犯錯次數減少了,説明知識蒸餾的作用是有效的。
參考:
1、https://www.bilibili.com/video/BV1N44y1n7mU?spm_id_from=333.788.videopod.sections&vd_source=99ec55b57f4eeedd9ed62c43e87cb6ff
2、https://github.com/Infrasys-AI/AISystem/blob/main/04Inference/03Slim/06Distillation.md