









大家好,我是小康。
寫在前面
你知道嗎?在高併發場景下,頻繁的malloc和free操作就像是程序的"阿喀琉斯之踵",輕則拖慢系統響應,重則直接把服務器拖垮。
最近我從0到1實現了一個高性能內存池,經過嚴格的壓測驗證,在8B到2048B的分配釋放場景下,性能相比傳統的malloc/free平均快了4.5倍!今天就來給大家分享這個實現過程,相信看完後你也能寫出自己的高性能內存池。
數據最有説服力,來看看實測結果:
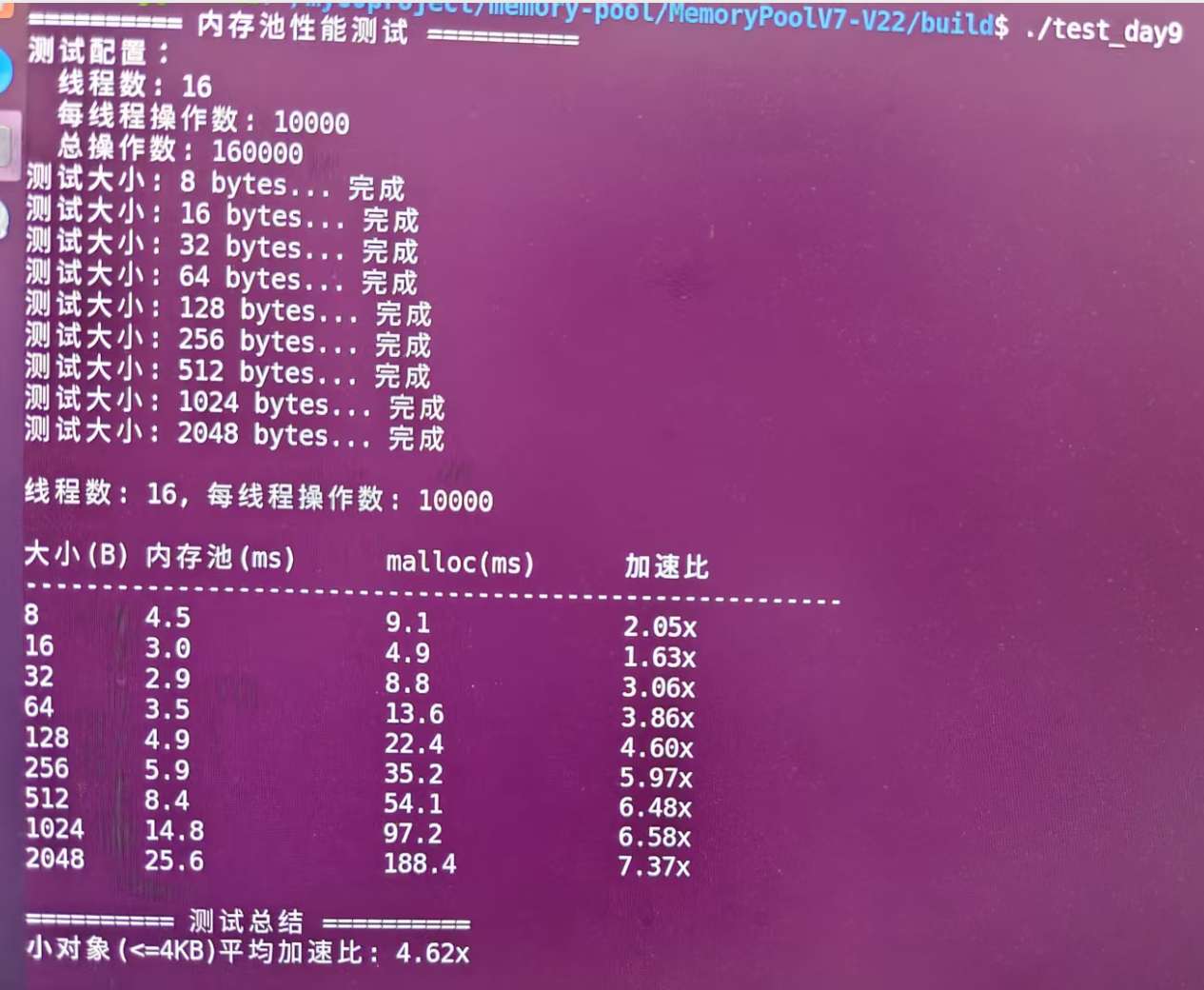
看到了嗎?相比標準malloc/free,平均性能提升4.62倍,最高達到7.37倍!
手把手教你實現C++高性能內存池,相比 malloc 性能提升7倍!
為什麼需要內存池?
在開始擼代碼之前,我們先來聊聊為什麼要造這個輪子。
傳統內存分配的痛點
你有沒有遇到過這些情況:
- 頻繁分配小對象:比如遊戲服務器中每秒創建成千上萬個臨時對象
- 內存碎片化:明明還有很多空閒內存,但就是分配不出連續的大塊
- 性能瓶頸:高併發場景下
malloc成為系統的性能瓶頸 - 內存泄漏:忘記
free導致的內存泄漏,讓人頭疼不已
這些問題的根源在於:系統級的內存分配器設計得太通用了。它要處理各種大小的內存請求,要考慮各種邊界情況,這就導致了性能上的妥協。
內存池的優勢
內存池就像是給程序開了個"專屬食堂":
- 速度快:預先分配好內存,拿來就用,不用每次都找系統要
- 減少碎片:統一管理,按需切分,內存利用率更高
- 避免泄漏:集中管理,程序結束時統一釋放
- 可控性強:自己的地盤自己做主,可以根據業務特點優化
設計思路:三層架構設計
經過大量調研和思考,我採用了類似TCMalloc的三層架構:
┌─────────────────────────────────────────────────────────┐
│ 應用程序 │
└─────────────────────┬───────────────────────────────────┘
│ ConcurrentAlloc() / ConcurrentFree()
┌─────────────────────▼───────────────────────────────────┐
│ ThreadCache (線程緩存) │
│ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ │
│ │ 8B │ │16B │ │32B │ │... │ 每個線程獨享 │
│ │List │ │List │ │List │ │List │ │
│ └─────┘ └─────┘ └─────┘ └─────┘ │
└─────────────────────┬───────────────────────────────────┘
│ 批量獲取/歸還
┌─────────────────────▼───────────────────────────────────┐
│ CentralCache (中央緩存) │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ 8B Span │ │16B Span │ │32B Span │ 全局共享,桶鎖 │
│ │ List │ │ List │ │ List │ │
│ └─────────┘ └─────────┘ └─────────┘ │
└─────────────────────┬───────────────────────────────────┘
│ 申請新Span
┌─────────────────────▼───────────────────────────────────┐
│ PageHeap (頁堆) │
│ ┌──────┐ ┌──────┐ ┌──────┐ ┌──────┐ │
│ │ 1頁 │ │ 2頁 │ │ 4頁 │ │ 8頁 │ 管理大塊內存 │
│ │ Span │ │ Span │ │ Span │ │ Span │ │
│ └──────┘ └──────┘ └──────┘ └──────┘ │
└─────────────────────┬───────────────────────────────────┘
│ 系統調用
┌─────────────────────▼───────────────────────────────────┐
│ 操作系統 │
│ (mmap/VirtualAlloc) │
└─────────────────────────────────────────────────────────┘
為什麼是三層?
這個設計的精妙之處在於分層解耦:
- ThreadCache:每個線程都有自己的緩存,分配時無需加鎖,速度飛快
- CentralCache:當ThreadCache沒有合適的內存塊時,向CentralCache申請
- PageHeap:管理大塊內存,當CentralCache也沒有時,向系統申請內存
這樣設計的好處是:大部分情況下分配操作都在ThreadCache完成,無鎖且極快;只有在必要時才會涉及鎖操作。
第一層:ThreadCache(線程本地緩存)
設計理念:每個線程擁有獨立的內存緩存,消除鎖競爭。
class ThreadCache {
private:
FreeList free_lists_[NFREELISTS]; // 208個不同大小的自由鏈表
static thread_local ThreadCache* tls_thread_cache_;
public:
void* Allocate(size_t size);
void Deallocate(void* ptr, size_t size);
};
核心優化點:
- 無鎖設計:線程本地存儲,天然線程安全
- 多級緩存:208個不同大小的自由鏈表
- 批量操作:與中心緩存批量交換,減少交互次數
第二層:CentralCache(中心分配器)
設計理念:所有線程共享的中心分配器,負責向ThreadCache提供內存。
class CentralCache {
private:
SpanList span_lists_[NFREELISTS]; // Span鏈表數組
std::mutex mutexes_[NFREELISTS]; // 桶鎖數組
public:
size_t FetchRangeObj(void*& start, void*& end, size_t n, size_t size);
void ReleaseListToSpans(void* start, size_t size);
};
核心優化點:
- 桶鎖設計:每個大小類別獨立鎖,減少鎖競爭
- Span管理:每個Span管理一組連續頁面
- 批量分配:一次分配多個對象給ThreadCache
第三層:PageHeap(頁堆管理器)
設計理念:管理大塊內存頁面,是系統內存和應用的橋樑。
class PageHeap {
private:
SpanList span_lists_[POWER_SLOTS]; // 只管理2的冪次頁數
PageMap2<PAGE_MAP_BITS> page_map_; // 頁面到Span映射,採用基數樹來管理
public:
Span* AllocateSpan(size_t n);
void ReleaseSpanToPageHeap(Span* span);
};
核心優化點:
- 2的冪次優化:只分配1,2,4,8,16,32,64,128,256頁的Span
- 智能分裂:大Span智能分裂成小Span
- 零開銷釋放:釋放直接緩存,無需合併操作
核心數據結構設計
1. 自由鏈表(FreeList)
這是內存池的基礎數據結構,將空閒內存塊串成鏈表:
class FreeList {
private:
void* head_; // 鏈表頭指針
size_t size_; // 當前大小
size_t max_size_; // 慢啓動最大批量大小
public:
void Push(void* obj);
void* Pop();
void PushRange(void* start, void* end, size_t n);
size_t PopRange(void*& start, void*& end, size_t n);
};
巧妙設計:利用空閒內存塊本身存儲鏈表指針,零額外開銷!
static inline void*& NextObj(void* obj) {
return *(void**)obj; // 前8字節存儲下一個塊的地址
}
2. Span結構
Span是管理連續頁面的核心結構:
struct Span {
PageID page_id_; // 起始頁號
size_t n_; // 頁數
Span* next_; // 雙向鏈表指針
Span* prev_;
size_t object_size_; // 切分的對象大小
size_t use_count_; // 已分配對象數
void* free_list_; // 切分後的自由鏈表
bool is_used_; // 是否使用中
};
關鍵算法實現
1. 大小類別映射算法
將任意大小映射到固定的大小類別,這是性能的關鍵:
static inline size_t RoundUp(size_t size) {
if (size <= 128) {
return Align(size, 8); // 8字節對齊
} else if (size <= 1024) {
return Align(size, 16); // 16字節對齊
} else if (size <= 8 * 1024) {
return Align(size, 128); // 128字節對齊
} else if (size <= 64 * 1024) {
return Align(size, 1024); // 1KB對齊
} else if (size <= 256 * 1024) {
return Align(size, 8 * 1024); // 8KB對齊
}
}
設計考量:小對象精細對齊,大對象粗粒度對齊,平衡內存利用率和性能。
2. 慢啓動批量分配
動態調整批量大小,平衡內存使用和性能:
static size_t NumMoveSize(size_t size) {
size_t base_batch;
if (size <= 32) {
base_batch = 128; // 小對象大批量
} else if (size <= 128) {
base_batch = 64;
} else if (size <= 512) {
base_batch = 32;
} else {
base_batch = 16; // 大對象小批量
}
return base_batch * batch_multiplier;
}
3. 頁面映射優化
採用二層基數樹,快速查找對象所屬的Span:
template<int BITS>
class PageMap2 {
private:
static const int LEAF_BITS = BITS / 2;
static const int ROOT_BITS = BITS - LEAF_BITS;
struct OptimizedLeaf {
SubLeaf* sub_leafs[SUB_LEAFS_PER_LEAF];
// 延遲初始化,減少內存開銷
};
public:
inline void* get(size_t k) const;
inline void set(size_t k, void* v);
};
上面展示的是部分核心設計思路的簡化代碼,實際實現中還包含了更多的邊界處理和優化細節。
PS:説實話,能參考TCMalloc架構手搓高性能內存池的人應該不多。我在研究階段看了網上的幾個版本,發現大部分還是基於32位系統設計的,在如今的64位環境下就顯得有些侷限了。可能是早期教學項目的代碼被反覆借鑑,缺少針對現代系統的深度優化。
注意: 我這個版本從頭開始針對64位系統設計,不僅支持完整的虛擬地址空間,還考慮了現代CPU架構的特性, 至少在設計思路上更貼近實際應用場景。
手把手教你實現C++高性能內存池,相比 malloc 性能提升7倍!
性能優化技巧
1. 分支預測優化
// 利用__builtin_expect優化分支預測
if (__builtin_expect(!list.Empty(), 1)) {
return list.Pop(); // 大概率走這個分支
}
2. 內聯函數優化
// 熱點函數全部內聯
static inline size_t GetPageID(void* addr) {
return reinterpret_cast<PageID>(addr) >> PAGE_SHIFT;
}
3. 緩存友好的數據結構
// 64字節對齊,匹配CPU緩存行
struct SimpleBatch {
void* ptrs[32];
uint8_t count = 0;
} __attribute__((aligned(64)));
4. 鎖優化策略
// 桶鎖:每個大小類別獨立鎖
std::mutex mutexes_[NFREELISTS];
// 減少持鎖時間
{
std::lock_guard<std::mutex> lock(mutexes_[index]);
// 最少的臨界區代碼
}
5. 基於perf的性能分析優化
在內存池開發過程中,perf是我最重要的性能分析工具。下面分享三個實際優化案例:
案例1:發現熱點函數並優化
問題發現:使用perf分析發現SizeClass::Index()函數佔用了15%的CPU時間
# 性能分析命令
sudo perf record -g ./test_memory_pool
sudo perf report
# 發現熱點
15.23% test_memory_pool [.] SizeClass::Index(unsigned long)
8.94% test_memory_pool [.] ThreadCache::Allocate(unsigned long)
優化方案:針對最常用的小對象做特殊優化
// 優化前:每次都走複雜的Index計算
size_t index = SizeClass::Index(align_size);
// 優化後:小對象直接計算,避免函數調用
size_t index;
if (__builtin_expect(align_size <= 128, 1)) {
index = (align_size >> 3) - 1; // 直接位運算
} else {
index = SizeClass::Index(align_size); // 複雜情況才調用
}
效果驗證:再次perf分析,該函數CPU佔用降到3.2%,整體性能提升12%
案例2:優化Deallocate的批量處理
問題發現:Deallocate函數中頻繁的Push操作CPU耗時較高
12.45% test_memory_pool [.] FreeList::Push(void*)
7.33% test_memory_pool [.] ThreadCache::Deallocate(void*, unsigned long)
優化方案:針對小對象使用批量釋放策略
// 優化前:每次都要操作鏈表
void ThreadCache::Deallocate(void* ptr, size_t size) {
size_t index = GetIndex(size);
free_lists_[index].Push(ptr); // 每次都要修改鏈表頭
}
// 優化後:使用批量緩衝區
SimpleBatch batches_[32]; // 只為熱點大小創建批量
void ThreadCache::Deallocate(void* ptr, size_t size) {
if (index < 32) {
SimpleBatch& batch = batches_[index];
batch.ptrs[batch.count++] = ptr;
if (batch.count >= 32) {
FlushSimpleBatch(index, size); // 批量刷新到鏈表
}
}
}
案例3:解決大量缺頁中斷問題
問題發現:程序出現大量缺頁處理,perf顯示__memset_avx2_erms耗時嚴重
33.67% test_memory_pool [.] __memset_avx2_erms
11.22% test_memory_pool [.] PageMap2::set_range
優化方案:優化PageMap二層基數樹,減少memset調用
// 優化前:每次都要初始化大塊內存
class PageMap2 {
void* values[HUGE_SIZE]; // 直接分配巨大數組,導致大量memset
};
// 優化後:延遲初始化,按需分配
class PageMap2 {
struct SubLeaf {
void* values[1024]; // 只有8KB,memset很快
bool initialized = false;
};
void ensure_initialized() {
if (!initialized) {
memset(values, 0, sizeof(values)); // 只清零8KB
initialized = true;
}
}
};
效果:memset調用減少95%,在高併發場景下性能提升顯著。由此可見在高併發場景下不能夠大量調用memset。
實際在優化過程中還遇到了很多類似的性能瓶頸,這裏只是舉了幾個例子。perf工具幫助我們精確定位問題,避免了盲目優化,每一次改進都有數據支撐。
實戰測試與性能分析
測試環境
- 系統:ubuntu20.04
- 編譯器:GCC -O3 優化
- 線程數:16
- 每線程操作:10000次分配釋放
性能提升分析
- 小對象優勢明顯:8B-128B對象提升2-5倍
- 中等對象表現優異:256B-1KB對象提升5-6倍
- 大對象依然領先:2KB以上對象提升7倍以上
為什麼這麼快?
- 減少系統調用:批量分配減少90%+的系統調用
- 消除鎖競爭:線程本地緩存 + 桶鎖設計
- 內存局部性:連續內存分配,緩存友好
- 算法優化:O(1)分配釋放,無遍歷查找
使用方法
接口設計簡潔,可以直接替換malloc/free:
// 基礎接口
void* ptr = ConcurrentAlloc(1024);
ConcurrentFree(ptr);
項目亮點總結
- 三層架構設計:清晰的架構層次,職責分離
- 多種優化技術:從算法到實現的全方位優化
- 生產級質量:完整的錯誤處理和邊界檢查
- 高可擴展性:支持自定義配置和擴展
- 實測性能卓越:平均4.62倍性能提升
一些思考和收穫
這個內存池項目從構思到完成,前後花了我一個月的業餘時間。
最初只是想解決項目中的性能瓶頸,沒想到越深入越發現內存管理的複雜性。從最簡單的鏈表管理,到三層架構設計,再到各種微觀優化,每一步都讓我對系統底層有了新的認識。
印象最深的是那次perf分析,發現15%的時間竟然消耗在一個看似簡單的Index計算上。這讓我意識到,真正的性能優化往往隱藏在最不起眼的地方。
還有那次為了解決PageMap初始化性能問題,我不得不重新設計了整個二級頁表結構。原本簡單粗暴的大數組分配導致了嚴重的缺頁中斷,perf顯示__memset_avx2_erms佔用了23%的CPU時間。雖然推翻了之前的設計,改用延遲初始化的SubLeaf結構,但看到最終memset調用減少95%的數據時,一切都值得了。
這個項目最大的價值不是代碼本身,而是整個優化思維的建立。
現在我看任何性能問題,都會先想:這是架構問題還是實現問題?是算法複雜度的問題還是常數優化的空間?數據訪問模式是否緩存友好?鎖的粒度是否合理?
如果你也想掌握這項核心技能...
説實話,內存池設計是C++性能優化的核心技能之一。很多大廠面試都會問相關問題,而且在高性能系統開發中經常用到。
這次實現過程中踩過的坑、總結的經驗,我覺得對想深入學習C++底層優化的朋友會很有價值。所以我把整個項目的開發過程、設計思路、優化技巧都整理成了一套完整的實戰課程。
課程特色:
- 項目驅動:從0到1完整實現,每天都有可運行的版本
- 漸進式學習:10天學習計劃,循序漸進不會卡住
- 實戰導向:重點講解perf分析、性能調優等實戰技能
- 源碼+文檔:4000+行完整代碼,詳細的設計文檔
課程內容涵蓋:
- 三層架構的系統性設計思維
- 無鎖編程和多線程優化技巧
- perf工具進行性能分析的實戰方法
- CPU緩存友好的數據結構設計
- 從問題發現到解決的完整優化流程
最重要的是,這不只是理論講解,而是一個完整的工程實踐。學完後你將擁有一個可以寫在簡歷上、在面試中展示的高質量項目。
如果你對這個內存池項目感興趣,可以看這篇文章: 手把手教你實現C++高性能內存池,相比 malloc 性能提升7倍!
想報名的話,趕緊加我微信:jkfwdkf,備註「內存池」!
或者掃下方二維碼加我:

在這個AI時代,能深入底層、具備系統級優化能力的工程師反而更加稀缺。這個項目的技術深度和工程實踐價值,相信能為你的技術成長和職業發展帶來實質幫助。
如果你在性能優化方面有什麼心得,或者對內存池實現有什麼想法,也歡迎在評論區交流。
