


本章我們將為大家介紹如何利用RAG解決統計問題。
首先介紹傳統RAG在處理統計問題中的缺陷:無法直接處理結構化數據以及缺乏動態計算能力,然後我們介紹了RAG解決統計問題的基本思路,以及通過SQL Call和Function Call機制。
接下來分別介紹二者,首先介紹SQL的相關概念以及如何構建SQL數據庫,然後介紹Text2SQL技術和sql_tool工具的具體實現。
最後介紹Function Call的基本概念,以及如何利用Function Call機制對RAG系統的統計分析能力進行增強。
在第14講中,我們利用自定義解析PDF Reader和向量庫milvus搭建了一個論文問答助手,將rag的能力從純文本領域擴展到了多模態領域。該論文問答助手的基本架構如下圖所示:

然而如果我們想進一步瞭解關於這些論文的信息,例如想了解某個論文數據庫的論文有多少篇、每年論文的發表數量、增長趨勢,又或者更普遍一些,不僅針對論文數據庫,假設現在有公司的銷售額、利潤等相關數據,我們希望瞭解“過去兩年每個月的銷售數據和增長趨勢是什麼?”,“過去三年內,季度利潤增長率的變化情況如何?”,對於這類統計問題,僅通過前面介紹的內容就不夠了。
RAG能否解決這些統計問題?答案是肯定的!那麼接下來就讓我們來走進帶有統計功能的RAG~
傳統RAG在統計問題中的缺陷
首先讓我們來理解“什麼是統計問題”。統計問題其實就是與數據有關的各種問題,目的是從數據中找到有用的信息,幫助我們做決策或理解某些現象。比如現在有班級的考試成績,問班級學生的考試成績總體如何?平均分是多少?哪個科目最難?又或者有相關的銷售數據,本月我們的銷售額是多少?產品A的銷售量是否有所增長?
介紹完統計的基本概念,讓我們仔細思考下傳統RAG在統計問題中的缺陷。
在先前的章節中,我們介紹的RAG主要是利用LLM的自然語言理解和生成能力進行基於資料的問答。在第13講課程中,儘管我們介紹了對錶格數據的處理方式,但統計問題中的表格規模遠比論文等PDF中的表格更大,無法直接通過圖像數據進行解析,而且統計問題中通常會結構化存儲海量的數據,例如excel、SQL等。
結構化數據統計問題通常涉及具體的數字、表格、數據庫等信息,需要精確的計算、推理和模型構建,而傳統RAG方法主要依賴於從大量文本數據中檢索相關信息並通過生成模型生成答案。具體來説,有如下2個缺陷:
(一)無法直接處理結構化數據
結構化數據通常以表格、CSV文件、數據庫等形式呈現,而RAG模型的生成和檢索模塊主要處理的是自然語言文本。雖然傳統RAG模型可以檢索和生成基於文本的答案,但它並不具備直接解析、理解和操作表格、數據庫等結構化數據的能力。
例如,如果統計問題涉及到某些特定的數據列運算(如計算均值、標準差、彙總統計等),傳統RAG模型可能無法直接從結構化數據中提取所需信息進行計算或推理。
(二)缺乏動態計算能力
許多結構化數據統計問題需要進行實時的計算和推理,例如通過SQL查詢提取數據、利用數學公式進行統計分析。傳統的RAG模型只能基於已經檢索到的信息生成答案,而無法在檢索過程中執行這些複雜的計算任務。
例如,在多元迴歸分析中,傳統RAG可能檢索到相關文獻,但卻無法基於輸入數據執行迴歸計算並給出準確結果。從下圖可以看到,當我們向普通 RAG 提出一個統計類問題時,會發現它無法執行動態計算,給出了一個錯誤的答案。


正確答案:

有沒有一種辦法可以讓的RAG也具備處理結構化數據和動態計算的能力?有的兄弟姐妹們!有的!這就是我們本節課要介紹的內容,讓RAG具備解決統計問題的能力。
RAG解決統計問題基本思路
(一)架構概述
為了更清晰地闡述利用RAG模型解決統計問題的思路,首先我們直接給出帶統計分析能力的RAG模型的基本架構,如下圖所示。

與傳統的RAG模型相比,新增了三個關鍵組件:意圖識別模塊、SQL數據庫和SQL Call。
- 意圖識別模塊:將用户自然語言輸入映射到預定義意圖類別。
- SQL數據庫:將數據寫入數據庫,便於後續大模型生成SQL語句後進行查找。
- SQL Call:將自然語言查詢直接映射為可執行的 SQL 語句,並在數據庫中查取數據並返回。
此處為了便於理解,您可以將Text2SQL和sql_tool看作是RAG模型中的retriever組件,將SQL數據庫看作普通的數據庫,這樣就能與傳統RAG模型的結構保持一致。即依舊是從外部數據源中檢索相關信息。檢索到的數據與用户的查詢一起輸入到大模型中,最終生成詳細的答案。
在下文,我們將介紹SQL數據庫、Text2SQL和sql_tool的具體原理和實現,此處我們首先舉幾個例子來讓您對“利用RAG解決統計問題的基本思路”有個“總體上的理解”。
結合以上架構圖,我們可以將利用RAG解決統計分析問題的流程抽象為以下三個步驟:
- 檢索相關數據:根據用户的問題,從數據庫或數據源中檢索出相關的數據。這一步我們需要調用Text2SQL和sql_tool工具,得到用於檢索的SQL語句,並執行得到檢索結果。
- 計算相關指標:對檢索到的數據進行統計計算,如增長率、平均值、總和等。這一步我們將上一步檢索到的結果輸入給大模型,結合用户所提query,即可完成對相應指標的計算。
- 生成報告:根據計算出的指標和相關數據,生成自然語言形式的分析報告。
(二)舉例説明
接下來我們舉兩個簡單的例子,方便理解上面所説的三個步驟:
案例1:時間序列數據的統計問題
問題:“過去兩年每個月的銷售數據和增長趨勢是什麼?”
解決流程:
1️⃣檢索相關數據:
- 使用Text2SQL將用户問題轉換為SQL查詢語句,例如檢索過去兩年每月的銷售額數據。
- 通過sql_tool執行SQL語句,從數據庫中提取相關數據。
2️⃣計算相關指標:
- 對檢索到的銷售額數據進行統計計算,如計算每月的環比增長率、同比增長率,並分析整體趨勢。
3️⃣生成報告:
- 將計算結果與用户查詢結合,生成自然語言形式的分析報告,描述銷售數據的趨勢和增長情況。
案例2:數據彙總與報告生成
問題:“請給我去年年度財報中的主要財務數據彙總,包括總收入、淨利潤、成本等。”
解決流程:
1️⃣檢索相關數據:
- 使用Text2SQL將用户問題轉換為SQL查詢語句,例如檢索去年財報中的總收入、淨利潤、成本等財務指標。
- 通過sql_tool執行SQL語句,從數據庫中提取相關數據。
2️⃣計算相關指標:
- 對檢索到的財務數據進行彙總和計算,如計算總收入、淨利潤的總和或平均值。
3️⃣生成報告:
- 將彙總結果與用户查詢結合,生成自然語言形式的財務報告,包括數據分析、總結和趨勢預測。
核心模塊原理及實現思路
(一)意圖識別
意圖識別是將用户自然語言輸入映射到預定義意圖類別的關鍵模塊,在客服機器人、智能語音助手、對話式搜索等場景中廣泛應用,能夠顯著提升人機交互的準確性和效率。
例如,在智能客服場景中,用户輸入“我要退款”需被快速分類至“售後申請”意圖,觸發自動化工單系統;在語音助手中,“明早八點提醒我開會”需識別為“日程管理”意圖並調用日曆接口。
當前主流方法包括基於規則、傳統機器學習和大規模預訓練模型三類:
1️⃣基於規則的方法
- 關鍵詞匹配與正則表達式:通過預先定義的關鍵詞、短語和正則模板進行精確匹配,實現對常見意圖的快速識別,優點是易於理解與部署,但對多樣化表達和同義詞擴展支持不足。
2️⃣傳統機器學習方法
- 支持向量機(SVM)與邏輯迴歸:將文本向量化後,利用SVM、邏輯迴歸等分類器進行訓練,可通過特徵工程(如TF-IDF、詞性標註)獲得較穩定的效果,但對特徵設計依賴較高,擴展新意圖需大量手工調整。
- 決策樹、樸素貝葉斯等:在小規模數據集上表現良好,但難以捕捉語義上下文信息。
3️⃣預訓練深度模型
- BERT及其變體:利用大規模語料預訓練的Transformer模型,能學習豐富的上下文表示,顯著提升長尾意圖與小樣本意圖的識別準確率。
- 更大型的大模型(如GPT系列):通過少樣本示例或提示工程(Prompting)方式,僅需極少標註數據即可完成意圖分類任務,同時支持動態擴展新意圖類別。

以下是幾個不同場景的意圖識別示例:
1️⃣客服場景
用户輸入:"我的訂單怎麼還沒發貨?"
識別意圖:查詢訂單狀態
用户輸入:"我要退換貨"
識別意圖:申請售後
2️⃣智能助手場景
用户輸入:"明天北京天氣怎麼樣?"
識別意圖:查詢天氣
用户輸入:"定一個明天上午9點的會議"
識別意圖:創建日程
3️⃣電商場景
用户輸入:"2000元以內的藍牙耳機推薦"
識別意圖:商品推薦
用户輸入:"怎麼用優惠券?"
識別意圖:使用優惠
4️⃣銀行/金融場景
用户輸入:"查一下我的餘額"
識別意圖:查詢賬户餘額
用户輸入:"轉賬給張三500元"
識別意圖:發起轉賬
儘管意圖識別技術已經廣泛應用,但傳統方法在實際場景中仍面臨明顯侷限。基於規則或傳統機器學習的方式依賴人工設計,難以應對用户表達的多樣性和新意圖的快速變化,尤其在處理長尾類別和複雜語義時準確率不足。
相比之下,以BERT等為代表的大模型憑藉強大的語義建模能力和上下文理解能力,顯著提升了意圖識別的準確性與魯棒性,特別適合少樣本和高變動的業務場景。因此,基於大模型的意圖識別已成為當前主流方案,並正逐步取代傳統方法,成為行業發展的關鍵趨勢。
(二)SQL概念及數據庫構建
1.基本概念
在深入理解SQL之前,這裏先對數據庫系統的整體生態做一個簡要的介紹。數據庫按數據組織方式主要分為關係型和非關係型兩大類。
1️⃣關係型數據庫(如 MySQL、PostgreSQL、SQLite)
以表格結構管理數據,支持事務和複雜查詢,適用於結構化數據。
2️⃣非關係型數據庫
根據數據模型又細分為:
- 文檔型:MongoDB,適合靈活存儲半結構化數據;
- 鍵值型:Redis,主要用於高性能緩存;
- 向量數據庫:FAISS、Milvus,專為高維向量檢索設計,應用於推薦系統、搜索引擎等場景。

我們接下來的應用主要針對的是關係型數據庫,它基於關係模型,由表(table)、行(row)、列(column)組成,採用SQL(結構化查詢語言)進行數據操作和查詢。
相比Excel等電子表格工具在處理中小規模數據時的便捷性,關係型數據庫在面對大規模數據時表現出更高的性能與一致性保障。它通過明確的數據結構和組織方式,使得存儲、檢索、更新和管理數據變得高效、靈活,並能夠支持複雜的查詢和多表關聯操作。
SQL(Structured Query Language,結構化查詢語言)是一種專門用於管理和操作關係型數據庫的標準編程語言。它通過一系列聲明性語句,使得用户能夠在數據庫中執行數據查詢、數據插入、數據更新、數據刪除等操作,並支持創建和管理數據庫結構,如表、視圖、索引等。
SQL語言的設計目標是簡化對數據庫的操作,使得用户不必關心數據存儲的具體細節,能夠專注於如何有效地管理和查詢數據。
下面這句SQL語言的含義是篩選工資大於5000元的員工。
SELECT name FROM employees WHERE salary > 5000;2.構建SQL數據庫
接下來我們從一個簡單的例子出發,講解如何構建SQL數據庫:
假設現在有一組電商平台的相關數據,經過統計我們得到了每個訂單的相關信息。包含以下列:order\_id,product\_id,product\_category,product\_price,quantity,cost\_price,order\_date。表格中的內容為:
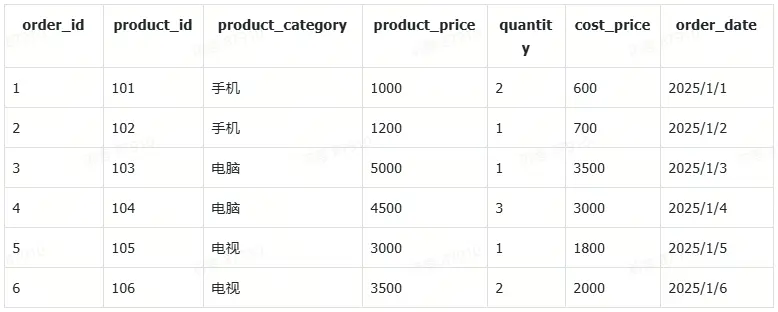
我們可以通過以下流程完成數據庫的創建:

可以利用如下python代碼實現上述流程:
(代碼GitHub鏈接:
https://github.com/LazyAGI/Tutorial/blob/7abc91dbb82a007a78731845dd8c360ac0cc1e75/rag/codes/chapter15/%E8%BF%9B%E9%98%B64%EF%BC%9A%E5%88%A9%E7%94%A8RAG%E8%A7%A3%E5%86%B3%E7%BB%9F%E8%AE%A1%E9%97%AE%E9%A2%98.py#L1)
import sqlite3 # 導入sqlite3模塊,用於操作SQLite數據庫
# 連接到數據庫
# 如果數據庫文件'ecommerce.db'不存在,SQLite會自動創建一個新的數據庫文件
conn = sqlite3.connect('ecommerce.db')
cursor = conn.cursor() # 創建一個遊標對象,用於執行SQL操作
# 創建 orders 表
# 使用CREATE TABLE語句創建一個新的表,表名為 orders
# IF NOT EXISTS 子句確保如果表已經存在,不會重複創建
cursor.execute('''
CREATE TABLE IF NOT EXISTS orders (
order_id INT PRIMARY KEY,
product_id INT,
product_category TEXT,
product_price DECIMAL(10, 2),
quantity INT,
cost_price DECIMAL(10, 2),
order_date DATE
)
''')
# 訂單ID,作為主鍵,確保每個訂單有唯一標識
# 產品ID
# 產品類別(例如,手機、電腦、電視等)
# 產品價格,保留2位小數
# 購買數量
# 產品成本價格,保留2位小數
# 訂單日期
# 插入數據
# 定義一個包含多個訂單的列表,每個訂單的相關信息(如訂單ID、產品ID、價格等)
data = [
[1, 101, "手機", 1000, 2, 600, "2025/1/1"],
[2, 102, "手機", 1200, 1, 700, "2025/1/2"],
[3, 103, "電腦", 5000, 1, 3500, "2025/1/3"],
[4, 104, "電腦", 4500, 3, 3000, "2025/1/4"],
[5, 105, "電視", 3000, 1, 1800, "2025/1/5"],
[6, 106, "電視", 3500, 2, 2000, "2025/1/6"]
]
# 執行插入操作,將每一條數據插入到 'orders' 表中
# cursor.executemany() 方法用於執行多個INSERT語句,批量插入數據
cursor.executemany('''
INSERT INTO orders (order_id, product_id, product_category, product_price, quantity, cost_price, order_date)
VALUES (?, ?, ?, ?, ?, ?, ?)
''', data)
# 提交更改
# 使用 conn.commit() 提交事務,將所有插入操作保存到數據庫中
conn.commit()
# 關閉連接
# 在完成操作後,關閉數據庫連接,釋放資源
conn.close()接下來,我們使用 SQL 瀏覽工具來查看一下數據庫文件 ecommerce.db 的具體內容:

可見我們已經成功創建order表格並將數據成功寫入數據庫,接下來我們將用這張表格來進行數據庫的查詢。
(三)SQL Call
在介紹SQL Call之前,我們先介紹下SQL Call的核心模塊:Text2SQL。
Text2SQL是一種自然語言處理(NLP)技術,旨在將人類的自然語言查詢轉化為 SQL 查詢語句。通過這種技術,用户無需學習 SQL 語言的語法或結構,直接用自然語言提出問題,就能自動生成相應的 SQL 查詢。
Text2SQL 系統通常依賴於深度學習模型和自然語言處理技術。它的主要工作流程如下:

1️⃣輸入自然語言查詢: 用户通過文本輸入查詢,例如“列出所有銷售額超過1000的訂單”。
2️⃣語言理解與解析: 系統通過自然語言理解技術(如詞嵌入、依賴解析等)理解用户意圖、識別查詢中的關鍵實體和關係,例如識別出“銷售額”和“訂單”是查詢的核心內容。
3️⃣SQL 生成: 根據語言理解的結果,系統自動生成對應的 SQL 查詢語句,確保語法正確並與數據庫結構相匹配。
4️⃣輸出 SQL 查詢: 最終,系統返回一個正確的 SQL 查詢語句,用户可以直接用這個語句在數據庫中執行。
還是以上面電商平台的數據為例,輸入query為“請給我每個品類的盈利彙總,按照盈利從高到低排序”,我們就可以通過Text2SQL得到對應的SQL查詢語句:
SELECT product_category,
SUM(product_price * quantity) - SUM(cost_price * quantity) AS profit
FROM orders
GROUP BY product_category
ORDER BY profit DESC;
有了 Text2SQL 這一核心功能作為基礎,SQL-call 進一步實現了從自然語言理解、SQL 生成,到自動執行查詢與結果反饋的全流程閉環,讓大模型不僅能“寫出”SQL,還能真正“用起來”。

SQL-call利用大模型(LLM)的函數調用接口,將自然語言查詢直接映射為可執行的 SQL 語句,並在數據庫中查取或更新數據,實現結構化問答能力。
在傳統 RAG 主要處理非結構化文本檢索的基礎上,SQL-call 打通了大模型與數據庫的交互通路,使模型能夠通過“調工具”來從數據庫獲得實時、準確的結構化數據信息,從而進行更精準和複雜的下游問答任務。
SQL-call 的應用場景非常廣泛,例如:
ChatBI 與數據平台助手:
- 如騰訊雲 ChatBI,通過意圖識別與 SQL-call 將用户的自然語言分析請求自動轉為 SQL 查詢,並以圖表、報表形式呈現,極大降低了 BI 使用門檻。
智能客服與對話機器人:
- 在智能客服中,用户提出如“查詢訂單狀態”或“退貨進度”等問題時,系統通過 SQL-call 查詢數據庫中的相關信息,並將結果轉化為自然語言回覆給用户,如“您的訂單已發貨,預計三天內送達”。
- 這樣不僅提高了響應速度,還實現了業務流程的自動化。
SQL-call 系統包含三個核心模塊:
- Text2SQL:將自然語言query轉換為SQL語句
- SQL數據庫:存儲結構化數據
- SQL Manager(檢索器):執行SQL並返回查詢結果
支持SQL call的數據庫類型有:
- 關係型數據庫:MySQL、PostgreSQL、SQLite、SQL Server、Oracle
- 分佈式數據庫:CockroachDB、TiDB 等
藉助意圖識別模塊和 SQL Call模塊,我們已經具備了在傳統 RAG 框架基礎上支持 SQL 相關問答的核心能力。具體的系統搭建流程將在後續的實戰課程中進行詳細講解。
1.將SQL Call加入到RAG中
我們可以將 SQL 的統計問答能力引入到RAG中,具體流程為用户輸入query,經過意圖識別模塊,決定是否調用 SQL Call 還是隻使用傳統 RAG。

🔍對於 SQL 分支:
- 根據用户的請求將 query 轉化成相應的 SQL 查詢語句
- 調用 SQL 語句得到查詢結果
- 將查詢結果返回給 LLM
從知識庫中提取信息到數據庫

統計分析能力增強
(一)ChatBI
1.ChatBI 是什麼?
ChatBI(Chat-based Business Intelligence),即聊天式商業智能,是一種結合了自然語言處理(NLP)、大語言模型(LLM)與數據分析能力的智能系統,允許用户通過自然語言與數據對話,像和人聊天一樣完成數據查詢、報表生成、分析洞察等任務。
以DataFocus BI為例,它以“檢索式BI”為特色,提供了豐富的圖表樣式和簡潔的交互界面,支持SQL自由和數據平等的理念。

2.ChatBI 架構設計圖
我們基於 ChatBI 的理念,設計了一種融合 SQL 查詢與圖表繪製能力的 RAG 系統。

📊整體流程是:
- 用户提出問題後,通過意圖識別後,系統首先使用 Text2SQL 工具將自然語言轉化為對應的 SQL 語句並執行查詢;
- 接着將查詢結果交給大語言模型(LLM)處理,併為其註冊好繪圖函數,使得模型能夠基於數據結果調用繪圖工具,自動生成相應圖表。
這樣,系統就能實現數據分析與可視化的一體化輸出。
(二)Function Call
1.Function Call基本概念
前面我們通過SQL Call技術(即構建數據庫、Text2SQL以及SQL查詢三個步驟),成功使RAG具備了處理結構化數據的統計能力,解決了傳統RAG在統計問題中的第一個缺陷,對於RAG缺乏動態計算能力的問題,我們是否有辦法能解決呢?同時上述SQL查詢雖然可以執行一些簡單的數學運算和邏輯運算,但實際中您可能會面臨非常複雜的數學計算甚至建模問題,這類問題就無法通過SQL直接執行了。
針對這些難點,我們可以引入Function Call機制為系統賦予高階的統計分析能力。接下來我們將首先介紹Function Call的基本概念和使用,然後介紹如何在RAG中使用Function Call機制。
當你詢問任意大模型 「北京目前天氣如何」,一般都會返回些亂回答的內容,因為它們的訓練資料都有一個截止日期,這些最新的信息對它們是不可見的。
針對這種情況,Function Call應運而生,Function Call(函數調用)是指在編程中執行一個已經定義的函數,以便運行該函數中包含的代碼邏輯。
在上述例子中,我們可以定義一個天氣API,當用户詢問時,調用天氣API就可以拿到最新的天氣資訊回答用户的問題,提升用户的使用體驗。其實上文中的sql_tool也是一種基於Function Call的外部函數調用。

Function Call的原理和我們在編程中使用函數的原理是一樣的,我們告訴大模型現在有若干個函數可以調用,每個函數對應哪種能力,入參和出參分別是什麼,這樣大模型就可以根據需求給出一個函數調用的參數列表。
當然函數調用及出入參解析是需要通過傳統編程實現的,這時使用框架可以幫助您節約這部分代碼的開發,直接輸入可用方法即可實現Function Call。
下面簡單講一個例子帶大家深入體會一下Function Call,同樣以天氣查詢案例為例,現在有這樣一個天氣查詢API,它接收地點為參數,返回對應位置的天氣情況,將其以JSON的形式表示為:
{
"type": "function",
"function": {
"name": "get_current_weather",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string"}
}
}
}
}我們把這個API描述和用户Query傳給大模型,當大模型接收到與天氣相關的查詢時會根據用户輸入和API參數相關信息返回一個API調用信息:
{
"id": "call_12345xyz",
"type": "function",
"function": { "name": "get_current_weather", "arguments": "{'location':'Beijing'}" }
}上述json中清晰的表達了接下來系統需要調用名為“get\_current\_weather”的函數,入參為“location=Beijing”。函數調用結束後您會得到一個這樣的結果:
{
"status":"1",
"info":[
{
"province":"北京",
"city":"北京市",
"weather":"晴",
"temperature":"6",
"winddirection":"西北",
"windpower":"≤3",
"humidity":"15",
"reporttime":"2025-01-03 15:00:13"
}
]
}針對上述API返回的結果,您需要通過傳統編程進行有效數據提取後將其與用户查詢一同傳入大模型,模型會返回北京天氣的自然語言描述。
對於用户而言,Function Call通常是不可見的,因此看起來像是大模型完成了一次天氣查詢和解答,同樣我們可以將其應用至當前的統計分析中。
2.Function Call 中的函數定義和使用方式
以繪圖為例,我們定義了一個使用 Matplotlib 繪製柱狀圖的函數,通過裝飾器@fc_register(“tool”)將其註冊成為可以調用的工具。
@fc_register("tool")
def plot_bar_chart(subjects, values):
"""
Plot a bar chart using Matplotlib.
Args:
subjects (List[str]): A list of subject names.
values (List[float]): A list of values corresponding to each subject.
"""
...
plt.show()🚨注意:
在撰寫函數時,一定要在函數下方加上註釋,格式如上(函數下方紅色部分)。在大模型調用該函數時,將通過函數的描述(如上面的Plot a bar chart using Matplotlib.)以及參數的表述(即subjects (List[str])和 values (List[float]) ),決定何時調用以及傳入參數。
下面為LazyLLM中Function Call的函數簡單使用方式。
from lazyllm.tools import FunctionCallAgent
llm = lazyllm.OnlineChatModule(source="sensenova", model="...")
tools = ["plot_bar_chart"]
query = "...."
fc = FunctionCallAgent(llm, tools)
ret = fc(query)3.常用的 Function Call 算法

📌 更多有關 Function Call 的內容與詳細實戰操作,請關注後續 RAG 教程。
4.Function Call 流程展示
示例問題:請問湯姆的同桌的姐姐的家鄉明天的氣温怎樣?
Plan:大模型把問題分解成若干步驟
Q1:湯姆的同桌是誰?得到答案 A1
Q2:A1 的姐姐是誰?得到答案 A2
Q3:A2 的家鄉是哪個城市?得到答案 A3
Q4:A3 明天的氣温是多少?得到最終答案 A4下面為LazyLLM中的簡單示例流程代碼。
def get_sister_name(name: str) -> str: ...
def get_hometown(name: str) -> str: ...
def get_deskmate(name: str) -> str: ...
def get_tomorrow_temperature(city: str) -> Optional[float]: ...
agent = PlanAndSolveAgent(llm=TrainableModule("internlm2-chat-7b").start(),
tools=[get_sister_name, get_hometown, get_deskmate,
get_tomorrow_temperature])
ret = agent("請問湯姆的同桌的姐姐的家鄉明天的氣温怎樣?")Solve:大模型從工具列表中選擇合適的工具解答問題

在得到問題後,大模型會把問題分成若干步驟,然後根據需要調用合適的工具。
5.常用可視化工具
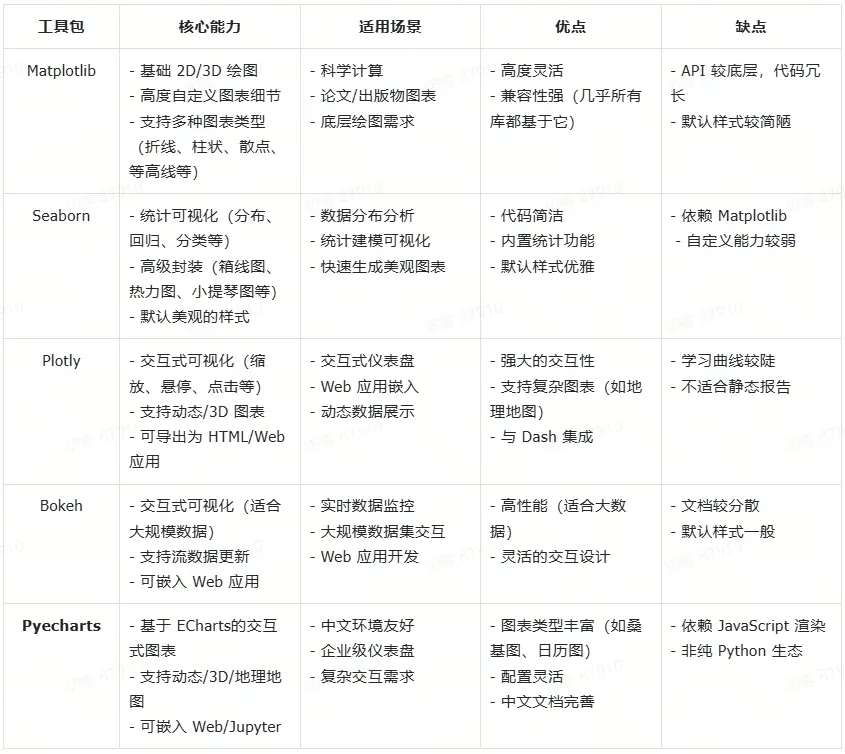
(三)在RAG中使用 Function Call
這裏我們通過一個簡單的例子為大家講解如何通過Function Call實現數值計算,以此來提升RAG系統的動態計算能力。
假設我們要分析某公司過去 12 個月的營收數據,那麼在第一步驟中我們通過SQL轉寫與查詢,得到了過去12個月的營收數據如下:

我們可以通過prompt對大模型進行指示,告知目前有均值計算方法可以瞭解一段時間內的整體水平,以及計算方差的函數可以幫助瞭解數據在一段時間內的波動性,方差越小波動性越小,並將各個函數對應的入參信息進行標註,如下所示(您可以自定義函數説明格式):
[{
"type": "function",
"function": {
"name": "get_mean",
"description": "計算輸入值的平均值,可以瞭解一段時間內的整體水平",
"parameters": {
"type": "object",
"properties": {
"data": {"type": "list"}
}
}
}
},
{
"type": "function",
"function": {
"name": "get_variance",
"description": "計算數據方差,瞭解數據在一段時間內的波動性,方差越小波動性越小",
"parameters": {
"type": "object",
"properties": {
"data": {"type": "list"}
}
}
}
}]當大模型接收到這些數據後選擇了其中的某個分析方法,就可以調用對應的函數進行均值(或方差)計算,進一步豐富統計結果的描述。均值方差是最基礎的分析方式,您也可以根據需求設計一些複雜的算子進行計算能力增強。
(四)繪製圖表
觀察上述12月營收表,我們可以發現這個表非常適合繪製折線圖,可以更直觀的向用户展示12個月以來的營收趨勢。
已知Function Call可以實現任意外部函數的調用,即系統可以實現圖表繪製,那麼我們就可以實現一個簡單的圖表繪製程序對SQL查詢數據進行折線圖、餅圖等的繪製,給到用户更直觀清晰的答覆。整體的思路如下圖:

首先我們提出一個query,輸入給Text2SQL工具轉化成SQL語句,然後得到查詢結果,查詢結果送給LLM,並預先註冊好Drawing Function,這樣LLM就能結合查詢結果和畫圖的工具,繪製出來相應的圖像,輸出圖像的形式如下圖所示,可以看到與純文字相比,圖像的方式更加清晰明瞭。

思考
能否讓大模型直接輸出代碼,然後執行代碼,返回結果?

大模型輸出代碼,在沙箱中執行?
📊整體流程是:
- 用户提出問題後,通過意圖識別後,系統首先使用 Text2SQL 工具將自然語言轉化為對應的 SQL 語句並執行查詢;
- 接着將查詢結果交給大語言模型(LLM)處理,並通過Code Interpret,使得模型能夠生成繪圖代碼,然後在沙箱中執行代碼生成相應圖表。
這樣,系統就能實現數據分析與可視化的一體化輸出。
總結
通過整合 Text2SQL 和 FunctionCall,不僅能夠自動化生成查詢語句並執行復雜的數據分析,還能有效提升分析過程的效率和準確性。
其中,Text2SQL 技術使得用户能夠用自然語言直接提問,系統自動將其轉化為 SQL 查詢語句。這大大降低了用户與數據庫交互的門檻,使非技術背景的用户也能夠通過自然語言實現數據查詢。
而Function Call 提供了一個自動化執行工具調用的機制,使系統可以在提取的數據上進行復雜的數學計算或圖表繪製,使數據分析不僅限於提取數據,還可以進行深度分析和推理,甚至可以對不同數據集進行比較和可視化,進一步洞察數據背後的趨勢和規律。

通過結合 Text2SQL 和 FunctionCall,RAG 系統可以在無需人工干預的情況下,實現從數據獲取到統計分析的一體化過程。
在實戰課中,我們將實現如上圖所示的工作流,實現一個既能回答統計問題,又能回答論文問答問題的系統。
更多技術內容,歡迎移步 “LazyLLM” 討論!