

在多模態大模型迅速發展的今天,我們已經能讓模型"看圖説話",甚至"讀懂表格",但要讓模型真正理解複雜的文檔結構(例如在PDF中準確識別章節、表格、公式與圖像的邏輯關係)依然是一個未被徹底解決的問題。
UniParse正是為此而生:它是一款面向AI應用的通用文檔解析工具 ,旨在將文檔中的非結構化內容轉化為結構化語義信息,使多模態模型能夠高效、精準地理解和利用文檔內容。
本文將從技術視角介紹UniParse,功能方面的介紹請移步產品上線|商湯自研智能文檔解析工具UniParse,重新定義文檔處理!
一、為什麼需要文檔解析
現代大模型已經能夠處理文本、圖像、語音等多種模態,但在面對文檔時仍然存在明顯短板:
- 格式複雜:PDF、Word等文件中同時包含文字、表格、圖片、公式、頁眉頁腳等多種內容,且層次不統一。
- 結構缺失:OCR只能識別文字,卻無法恢復章節層級與邏輯順序。
- 語義混亂:表格、圖像與正文往往存在隱含關聯,模型難以在語義上進行對齊。
這意味着,如果直接把整份文檔輸入多模態模型,模型將面臨巨大的上下文噪聲和空間混亂,生成效果不穩定,也無法進行精確問答。UniParse的作用,就是在模型"讀文檔"之前,幫它理清結構、分清語義、建立關聯。
二、UniParse的技術流程
UniParse的核心流程分為兩個主要階段:版面分析(LayoutAnalysis)與內容提取(ContentExtraction) ,並輔以預處理 與內容合併兩個輔助流程。整個流程既保持模塊化設計,又在數據層實現了結構化信息流動,使得不同模態內容(文字、圖片、表格、公式)能夠被統一建模和調用。
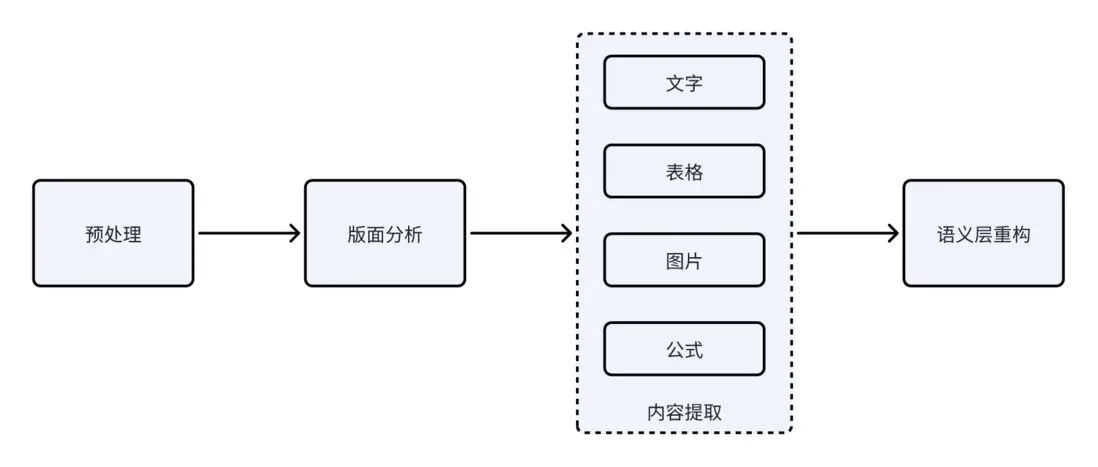
1️⃣文檔預處理
UniParse的預處理階段主要任務是統一輸入格式 。系統會將各類文檔(PDF、DOC、DOCX等)逐頁渲染為高分辨率圖像,保證不同文件格式在後續視覺模型中具有一致的輸入維度。這一過程通常基於PyMuPDF或libreoffice的渲染引擎實現,可控制分辨率以兼顧清晰度與性能。
同時,預處理階段還執行以下步驟:
- 頁面編號與座標標準化:為每頁圖像生成統一的座標系,用於後續版面元素定位;
- 去噪與邊緣裁剪:提升模型在掃描件、照片類文檔上的魯棒性;
- 文件元信息提取:(如頁數、文件名、創建時間),用於文檔追蹤與任務調度。
經過預處理後,所有文檔都被轉化為一組圖像文件及其基礎元信息,為後續的版面解析與內容提取提供統一輸入。
2️⃣版面分析
版面解析是UniParse的核心之一,目標是還原文檔的空間與語義結構 。這一階段採用視覺語言聯合建模方法:
- 在視覺層面,利用版面分析模型(如LayoutLMv3或自研視覺Transformer)識別標題、正文、表格、圖像、公式、腳註等區域;
- 在語言層面,通過文本塊的字體、縮進、上下文語義判斷章節層次與邏輯順序;
- 最終將視覺檢測結果與文本序列對齊,生成一個包含位置、類型與層級的結構化版面樹。
3️⃣內容提取
UniParse針對不同類型內容採用專用解析管線:
- 文字:OCR模型或文本提取API結合版面座標進行文本恢復與段落重建;
- 表格:基於結構化表格識別網絡(如TableFormer或自研模型)恢復單元格位置、合併關係與層級結構,輸出HTML/LaTeX格式;
- 圖片:通過OCR或視覺語言模型(VLM)獲取圖像描述,為多模態模型提供語義錨點;
- 公式:採用基於Transformer的公式識別引擎將公式區域轉化為可編輯的LaTeX表達式。
每種內容在抽取後都會帶有來源頁、座標和上下文標籤,以便在合併階段進行定位與關聯。
4️⃣語義層重構
最後一步是內容合併與輸出。系統將前述多類型元素按照版面樹的層級進行拼接,恢復出原文檔的邏輯順序與結構。這一階段還可以進行:
- 內容去重與段落融合(防止跨頁重複文本);
- 模態鏈接(表格、圖像與正文語義匹配);
- 結構化輸出(統一輸出為JSON、HTML或Markdown格式)。
通過這一設計,UniParse能在保持文檔可讀性的同時,為下游多模態模型提供可計算的結構化輸入。
三、UniParse與多模態大模型的協同機制
多模態模型的核心挑戰之一是模態對齊。傳統方法依賴模型內部注意力機制去"猜測"文本與視覺區域的對應關係,而UniParse提供了顯式的結構錨點。
從工程上看,UniParse的結構化輸出可以直接映射到模型輸入的不同通道:
- 文本節點被編碼為語言向量;
- 表格與公式節點可轉換為結構token序列;
- 圖像節點對應視覺特徵向量;
- 節點之間的層級關係(如章節樹)可編碼為attentionmask,用於指導模型的跨模態關注。
通過這種方式,UniParse在模型輸入階段實現了結構化對齊:
- 模型在編碼時能基於文檔結構進行有選擇的注意力分配;
- 上下文檢索與問答更精確,因為每個節點都帶有位置標籤;
- 生成內容可以反向追溯到原文檔區域,實現可解釋性。
換言之,UniParse並非一個單純的"預處理器",而是為多模態大模型提供了結構感知接口,讓模型真正理解"這是一份文檔",而不僅僅是一組視覺與文本片段。
四、應用場景:從文檔解析到智能理解
UniParse的技術能力為多模態模型打開了更廣闊的應用空間:
- 智能問答(QA):大模型可直接基於結構化數據進行文檔問答,不僅能回答正文問題,也能解析表格、公式或圖表。
- 知識抽取與檢索增強生成(RAG):通過文檔語義圖構建可檢索知識庫,支持高精度上下文匹配。
- 報告生成與內容審校:結構化信息流使模型能生成符合格式規範的總結、分析報告或審閲意見。
- 圖文理解與多模態推理:表格、公式、圖片被視為獨立模態單元,與文本共同構成推理輸入,適用於學術報告、財務報表等複雜文檔。
小結
在多模態智能系統的發展路徑中,結構化理解是必經之路。UniParse作為文檔解析的基礎設施,為大模型提供了語義層級、視覺位置與邏輯關係的橋樑,使文檔理解從模糊感知走向可解釋推理。未來,模型的"讀文檔"能力將不斷演進------它們不再僅僅識別信息,而是能夠基於文檔的結構和語義進行真正的理解與推理。
更多技術討論,歡迎移步 "萬象開發者" gzh!