

作者: vivo 互聯網大數據團隊-Wang Zhiwen、Cai Zuguang
vivo大數據平台通過引入RSS服務來滿足混部集羣中間結果(shuffle 數據)臨時落盤需求,在綜合對比後選擇了Celeborn組件,並在後續的應用實踐過程中不斷優化完善,本文將分享vivo在Celeborn實際應用過程中對遇到問題的分析和解決方案,用於幫助讀者對相似問題進行參考。
1分鐘看圖掌握核心觀點👇
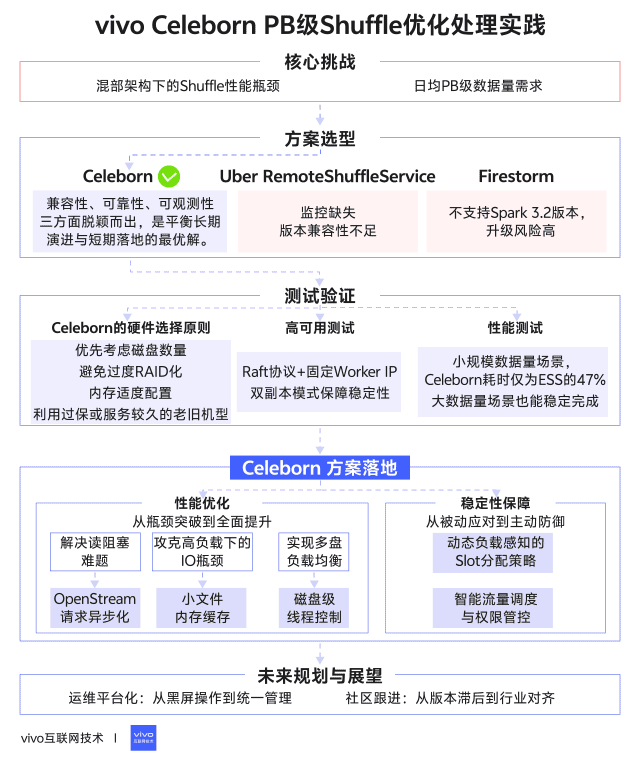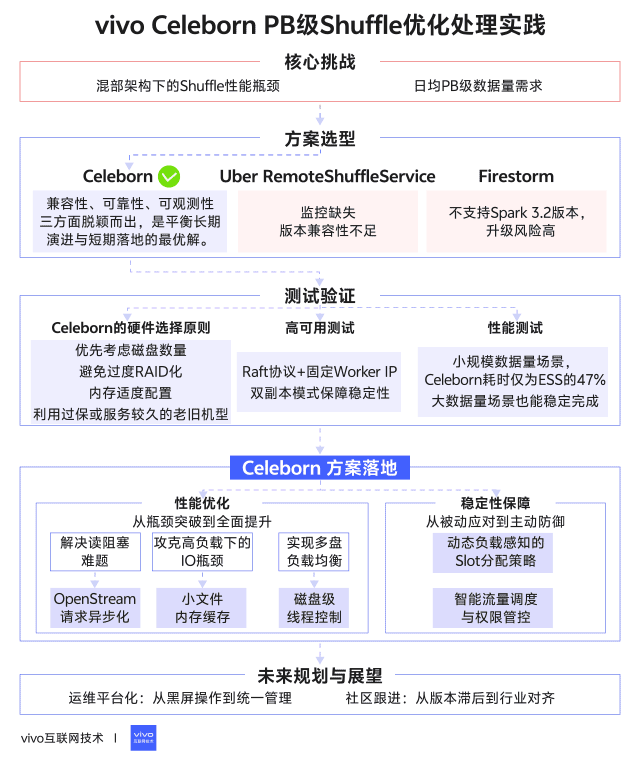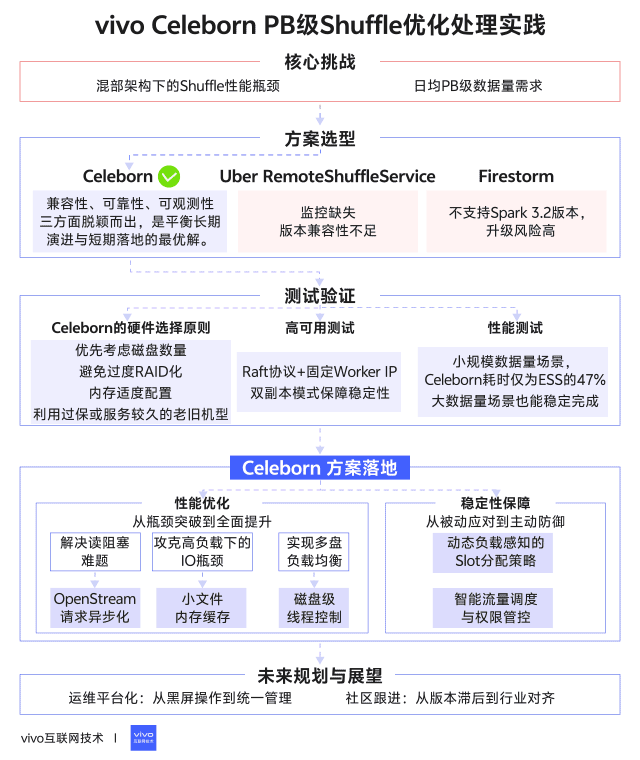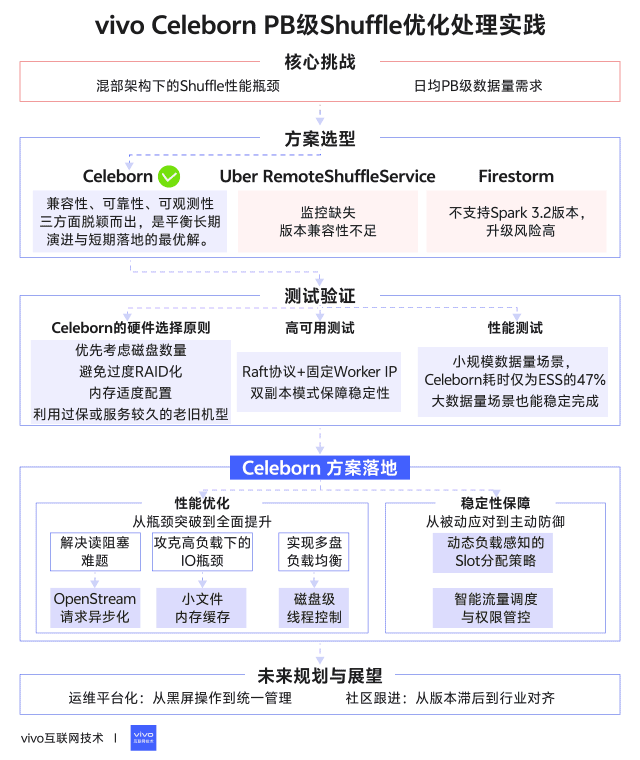
一、背景
近年來,隨着vivo大數據平台的數據量和任務量持續快速增長,新增的計算機資源已無法滿足不斷擴大的存儲和計算需求。同時,我們觀察到互聯網和算法等在線業務在白天流量高峯,而在夜間流量顯著下降,導致部分服務器在低峯時段資源利用不充分。與此相對,離線業務的高峯期正好落在在線業務的低峯期間。
在此背景下,我們於2023年起與容器團隊合作,啓動了在離線混部項目,旨在探索將海量的大數據離線任務運行到K8S在線集羣中。通過實現在線服務、大數據離線任務、與機器學習離線任務的混合部署,我們期望緩解計算資源的潮汐現象,實現資源的彈性伸縮和共享,增強大數據平台的資源供應,同時提升公司整體服務器的利用率並達到降本增效的目的。為實現上述混部效果我們對當前主流的方案YARN on K8S和Spark on K8S做了大量的調研,方案對比情況如下:

基於多方面因素綜合考慮,我們團隊決定採用Spark on K8S方案去支持在離線混部項目,為此我們急需一套成熟的remote shuffle service服務支持項目的推進。
二、RSS 初體驗
2.1 百花齊放,只取一支
在Spark作業中,高效的Shuffle服務對性能至關重要。我們對主流Shuffle方案(Celeborn、Uber RemoteShuffleService、Firestorm)進行了深度調研。以下是我們vivo團隊對主流shuffle服務的初步調研結論。
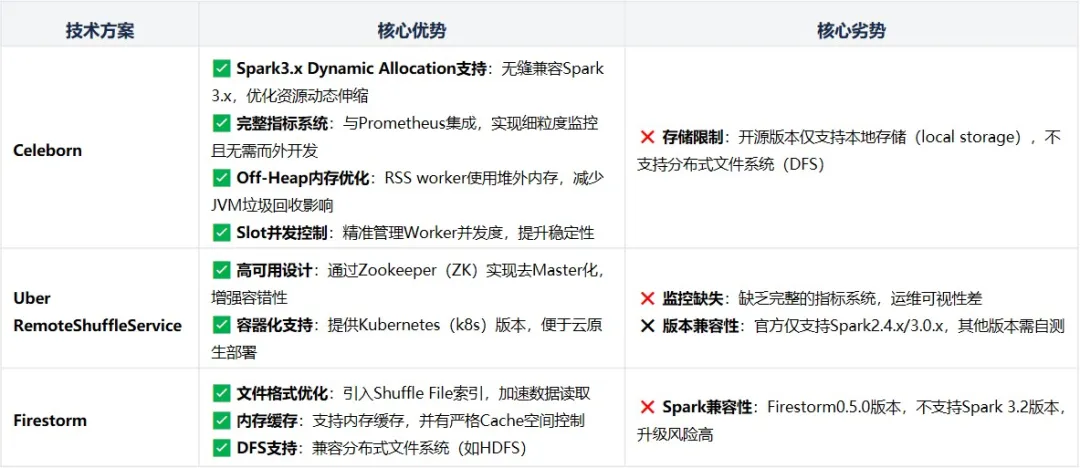
基於全面評估,我們團隊初步選擇Celeborn作為核心Shuffle解決方案。以下是我們選擇Celeborn的關鍵決策因素:
-
生態兼容性:Celeborn對Spark 3.x(包括最新Spark版本)的Dynamic Allocation原生支持,優於Uber RSS的有限兼容(僅Spark2.4/3.0)和Firestorm的不支持Spark 3.2。符合vivo當前使用的spark版本,避免未來Spark兼容帶來的風險。
-
可觀測性與運維友好性:Celeborn的完整指標系統(集成Prometheus)提供了端到端監控能力,可在運維過程中實時識別瓶頸。而Uber RSS的監控缺失和Firestorm無指標問題,將顯著增加生產環境故障排查難度。
-
性能與穩定性保障:Celeborn使用Off-Heap內存機制大幅減少JVM垃圾回收的STW停頓,提升吞吐量。同時採用Slot併發控制避免Worker過載,預防資源爭搶導致的作業失敗。Firestorm雖優化文件格式,但不支持最新Spark版本;Uber RSS缺乏併發管理能力。
-
劣勢的可行性規避:Celeborn不支持DFS的情況,在當前架構下可接受,未來開源社區正推進DFS支持,技術債可控。
基於上述的全面評估,Celeborn在兼容性、可靠性、可觀測性三方面脱穎而出,是平衡長期演進與短期落地的最優解。
2.2 精心培養,綻放異彩
2.2.1 硬件適配:機型選擇與性能調優
我們選取了三類線上常見且服務時間較長的服務器進行測試,充分利用現有硬件資源,驗證Celeborn在不同配置下的性能表現:
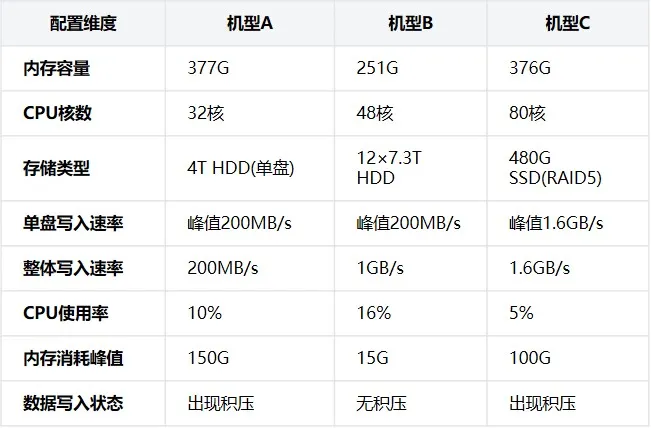
通過對比發現,機型B表現出最佳的綜合性能,而機型C雖然單盤性能出色(SSD達1.6GB/s),但受限於RAID5配置和較小容量,在持續寫入場景反而出現數據擠壓,這提示我們Celeborn對磁盤數量比單盤性能更敏感。基於測試結果,我們總結出Celeborn的硬件選擇原則:
-
優先考慮磁盤數量:多塊HDD的聚合帶寬往往優於少量高性能SSD
-
避免過度RAID化:shuffle數據一般為臨時數據,即使有少量丟數對離線業務影響也不大,無需做raid
-
內存適度配置:Celeborn對內存需求並非線性增長,250G左右已能滿足PB級Shuffle需求
-
利用過保或服務較久的老舊機型:Celeborn對硬件要求相對寬容,是消化老舊服務器的理想場景
這些結論幫助我們優化了硬件選擇策略,將Celeborn集羣部署在性價比最優的機型B配置上,實現了資源利用的最大化。
2.2.2 服務健壯性:高可用與運維驗證
作為關鍵基礎設施,Celeborn的服務穩定性和運維友好性是我們評估的重點。我們設計了多場景的故障模擬測試,驗證其生產級可靠性。
Master高可用測試
Celeborn採用Raft協議實現Master高可用,其高可用的能力是我們驗證的重中之重,為此我們模擬線上的日常操作對master進行測試驗證得出以下結論:
-
無髒數據情況下,Master節點輪流重啓不影響運行中任務
-
整個過程中Shuffle服務零中斷
-
三Master架構下,即使兩個節點同時故障,只要一個存活就不影響任務運行
在整個測試中我們發現在k8s環境下Worker重啓會帶來IP的變動,若有頻繁的重啓會在Master產生髒數據,當Master觸發重啓操作時恢復會非常慢。為此我們在k8s環境上都固定了Worker的IP,讓Worker的變動不影響master。
服務熱更新驗證
版本變更是生產環境常態,我們測試了不同副本配置下的更新影響:
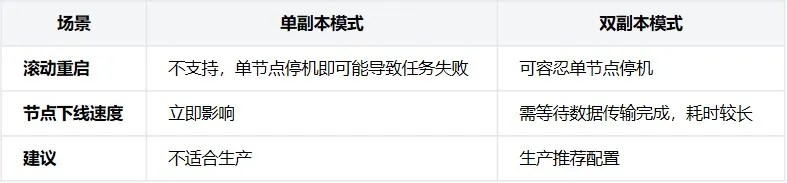
測試表明,雙副本模式是生產環境的必選項,雖然節點下線需要更長時間等待數據傳輸完成,但保證了服務連續性。
2.2.3 性能測試
在性能方面我們對RSS的要求是不明顯低於ESS,為此我們在3master+5slave的集羣下做了對比驗證,測試數據如下:
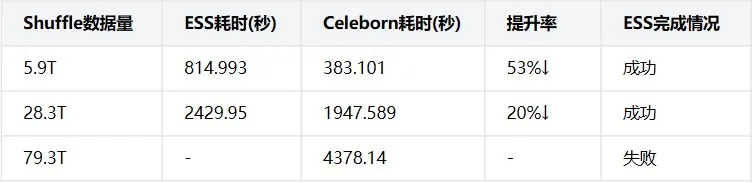
結果呈現三個顯著趨勢:
-
全面加速:在小規模數據量(5.9TB)場景,Celeborn耗時僅為ESS的47%,優勢明顯
-
穩定優勢:隨着數據量增大,Celeborn始終快於ESS,28.3TB時仍有20%提升
-
可靠性差異:ESS在79.3T及以上Shuffle量時完全失敗,而Celeborn能穩定完成所有測試案例
另外在數據驗證中我們發現使用Celeborn會偶發存在丟數情況,對此我們反饋給社區開發人員一起聯調測試,發現Celeborn確實存在有丟數的情況,問題詳細記錄在CELEBORN-383。對此非常感謝社區的大力支持,幫助我們快速修復問題得以項目能準時上線。
三、與Celeborn共渡800天后的經驗分享
在大數據計算領域,Shuffle作為連接Map階段和Reduce階段的關鍵環節,其性能與穩定性直接影響着整個作業的執行效率。大數據平台運維團隊目前運營着多個Celeborn集羣,用上百個節點規模去支撐日均PB級Shuffle數據量、幾十萬應用,我們在過去800天的生產實踐中,針對Celeborn這一新興的Remote Shuffle Service進行了深度優化與調優。接下來的篇章中將系統性地分享我們在性能提升和穩定性保障兩方面的實戰經驗,涵蓋問題定位、優化思路、實現方案以及最終效果,為同行提供可落地的參考方案。
3.1 性能優化:從瓶頸突破到全面提升
在超大規模集羣環境下,Celeborn作為Shuffle數據的"交通樞紐",面臨着諸多性能挑戰。我們通過全鏈路監控和細粒度分析,識別出三個關鍵性能瓶頸點,並實施了針對性的優化措施。
3.1.1 異步處理OpenStream請求:解決讀阻塞難題
問題現象與影響
在日常運維中,我們頻繁觀察到Shuffle Read耗時異常波動的情況:讀取耗時從正常的幾十毫秒突然增加到秒級甚至分鐘級,同時讀取數據量呈現斷崖式下降。這種現象在業務高峯期尤為明顯,直接導致作業執行時間延長30%以上。
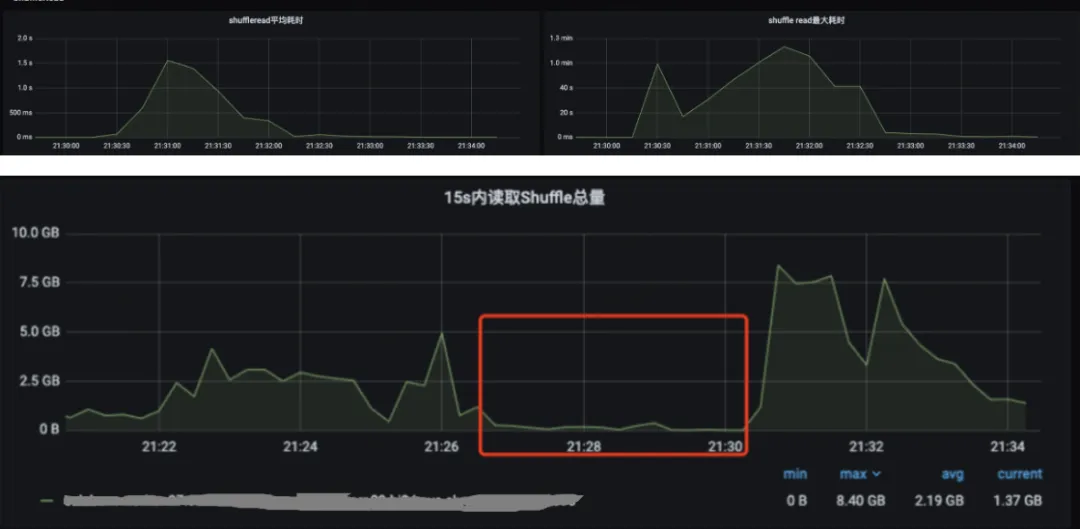
根因分析
通過分析Celeborn Worker的線程堆棧和IO等待情況,我們發現當Worker節點在進行大規模文件排序操作時,讀取排序文件的reduce任務會同時發起對排序文件讀取的openstream請求到Worker,這些請求會長期佔用線程直到排序結束,從而導致Worker的讀線程數被佔滿,後續的讀請求無法被處理形成惡性循環。
優化方案
我們通過修改客户端發起異步openstream請求方式去減少服務端線程被長時間佔用的問題,從而降低對fetch請求的影響,相應的pr為:Github | apache | celeborn
3.1.2 小文件緩存:攻克高負載下的IO瓶頸
問題現象
在Celeborn集羣負載超過70%時,我們注意到一個反常現象:部分本應快速完成的KB級小文件讀取操作,耗時卻異常攀升至幾十分鐘級別。這類"小任務大延遲"問題導致簡單作業的SLA難以保障。
根因定位
通過服務和機器負載的持續分析,我們發現高負載場景下小文件的讀取的耗時主要用在io等待上,造成這一情況的主要原因是操作系統對於io的調度是遵循FIFO實現的,即按請求到達的順序處理,在請求較多或較隨機時,即使很小的文件也可能出現長時間等待的問題。
優化實現
在Celeborn中讀寫框架大概可以分為三個階段:shuffle文件寫入階段、shuffle文件commit階段、shuffle文件讀取階段。shuffle文件寫入階段主要是spark程序主動推送數據到Celeborn服務端,Celeborn通過pushHandler將數據保留到服務端,在將數據寫入磁盤對應的文件前會先將數據寫入FlushBuffer,當buffer被寫滿的時候才會生產FlushTask將數據做落盤處理,也以此來降低磁盤的iops。而shuffle文件commit階段則是對之前寫入的文件做一個確認,服務端同時將在FlushBuffer中的數據做最後一次落盤處理。shuffle文件讀取階段則通過服務端的FetchHandler處理spark stage的shuffle read請求,返回相應的shuffle數據。為解決上述的小文件讀取瓶頸我們基於原有的讀寫框架設計了文件緩存體系來優化小文件訪問,整體實現框架如下:
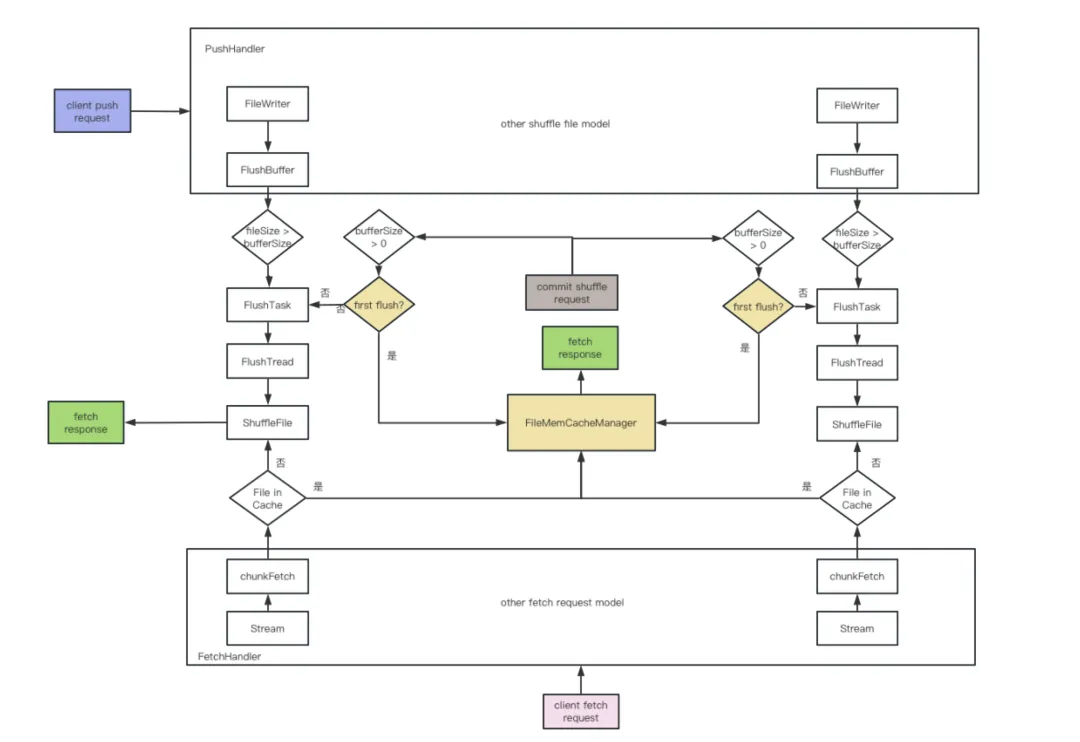
小文件緩存主要是通過增加一個FileMemCacheManager並作用在shuffle文件commit階段實現,當服務端收到某個文件的commit請求時,會判斷該文件是否之前有發生過刷盤操作,若沒有且文件大小符合緩存策略,則會將文件緩存到FileMemCacheManager中去避免落盤。在Shuffle讀取階段,也會先校驗文件是否被緩存,若緩存在內存中則從FileMemCacheManager中獲取相應的文件數據,否則走原邏輯從磁盤中獲取。
優化效果
通過灰度發佈驗證,優化後效果顯著:
-
最差情況:Shuffle Read最大耗時從4分鐘降至2分鐘以內
-
平均延遲:從200ms+降至60ms以下

優化前壓測服務指標
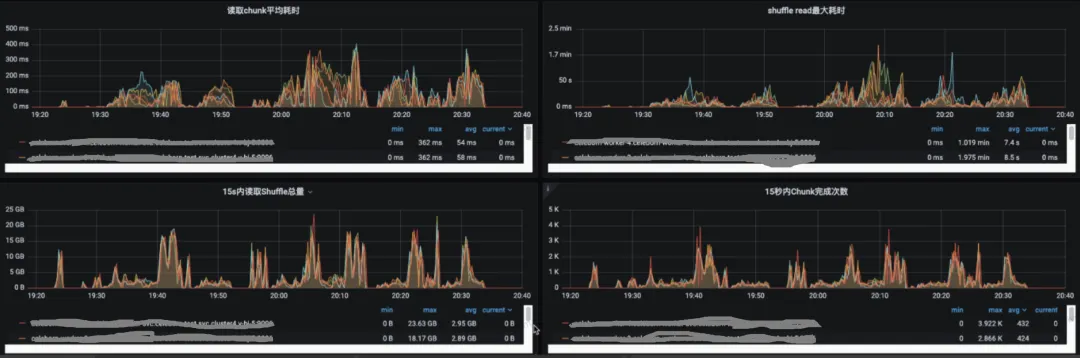
優化後壓測服務指標
3.1.3 磁盤級線程控制:實現多盤負載均衡
問題現象
在多磁盤(12-24塊)配置的Worker節點上,我們經常觀察到磁盤利用率不均衡現象:1-2塊磁盤的IO利用率持續保持在100%,而其他磁盤卻處於空閒狀態。這種不均衡導致整體吞吐量無法隨磁盤數量線性增長。
技術分析
Celeborn原有的線程分配策略採用全局共享線程池,所有磁盤的讀請求競爭同一組線程資源。當某塊磁盤因數據傾斜或硬件故障導致IO延遲升高時,它會獨佔大部分線程,造成資源分配失衡。
具體表現為:
-
單盤異常可導致節點吞吐量下降50%+
-
線程競爭引發大量上下文切換開銷
-
無差別的重試機制加劇磁盤擁塞
優化方案
針對上述場景我們設計了磁盤級線程均衡策略去嚴格控制每個磁盤能使用的線程上限,以此來避免單盤異常導致所有讀線程被佔用的情況。
整體設計思路如下:

在設計方案上引入兩個新的變量FetchTask和DiskReader,FetchTask主要用於把fetch請求的參數封裝保留給到DiskReader。而DiskReader則控制着單個磁盤讀寫並行度,每個磁盤對應一個DiskReader,其不負責具體的read實現邏輯,read邏輯還是在ChunkStreamManager中實現。
FetchTask的數據解構如下:
class FetchChunkTask(client: TransportClient, request: ChunkFetchRequest, fetchBeginTime: Long){
private val cli = client
private val req = request
private val beginTime = fetchBeginTime
def getClient: TransportClient = cli
def getRequest: ChunkFetchRequest = req
def getBeginTime: Long = beginTime
}
DiskReader控制磁盤讀寫並行度的邏輯大概如下:
-
嘗試申請對當前磁盤的讀操作
-
申請成功則佔用處理鎖並從FetchTask隊列中獲取待處理的Task
-
處理Task中的fetch邏輯
-
釋放處理鎖
實施效果
優化後集羣表現出更好的數據吞吐:
-
機器磁盤io利用率無明顯差異
-
單盤異常對節點影響範圍縮小80%
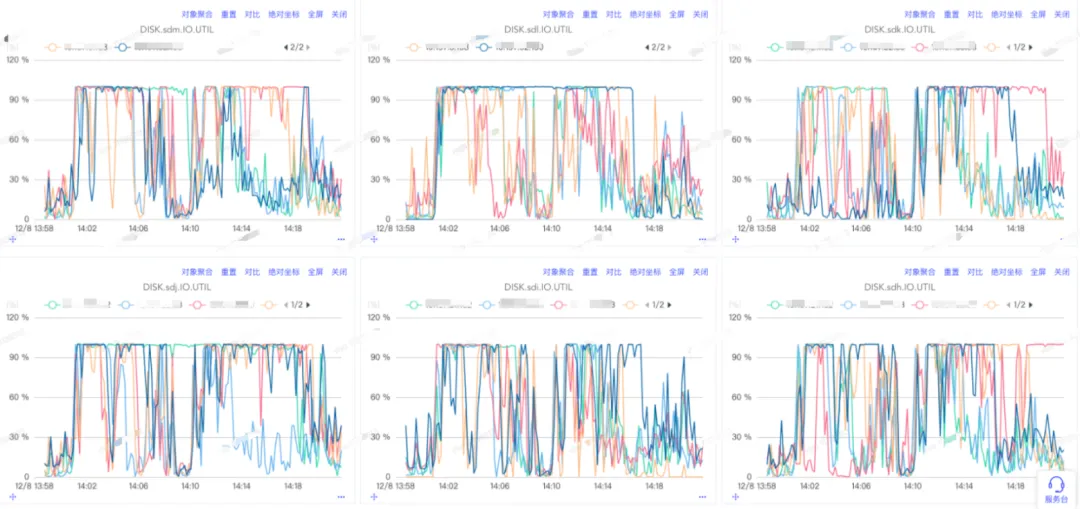
優化後壓測各磁盤表現情況
3.2 穩定性保障:從被動應對到主動防禦
在保證性能優化的同時,集羣的長期穩定運行同樣至關重要。我們針對Celeborn在超大規模集羣環境下暴露出的穩定性問題,構建了多層次保障體系。
3.2.1 動態負載感知的Slot分配策略
問題背景
Celeborn提供RoundRobin和LoadWare兩種slot分配策略,其中RoundRobin分配策略相對簡單,其主要邏輯是獲取當前可用磁盤並對這些磁盤做輪詢分配。而LoadWare分配策略則需要先按照每個磁盤的讀寫壓力進行排序分組,按照磁盤的壓力等級逐級降低各個組的slot分配數量。在我們線上採用後者分配方式將slot分配到各個Worker儘量避免worker持續處於高負載的情況。在實際運營中我們發現當worker有磁盤出現shuffle壓力時會很難恢復,有一部分原因可能是按照LoadWare分配策略集羣仍可能往上面分配新的寫任務從而惡化情況,雖然我們可以通過調整celeborn.slots.assign.loadAware.num-
DiskGroups和celeborn.slots.assign.loadAware
.diskGroupGradient參數來讓部分磁盤不分配slot,但這個參數相對比較難合理的評估出來,而且出現的節點往往只是個別的機器磁盤,通過原來分組的方式可能會影響其他同組正常的worker讀寫數據,為此我們決定保留原有的配置上實現了剔除高負載磁盤分配的策略,具體實現如下:
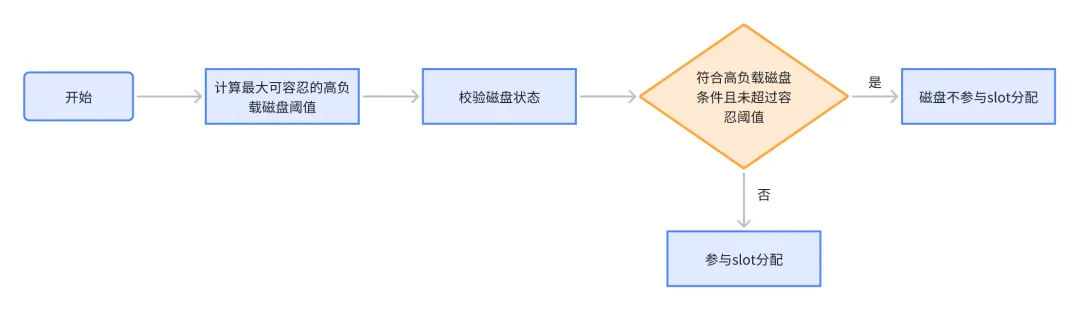
在上述流程中計算最大可容忍的高負載磁盤個數我們通過設置的celeborn.slots.assign.loadAware
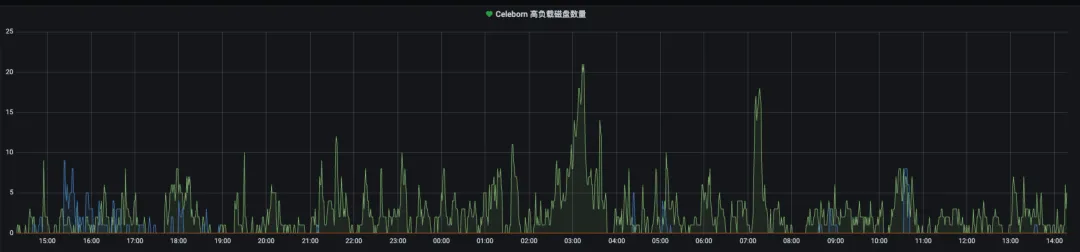
.discardDisk.maxWeight(默認配置0.3)參數計算得來,其計算公式為集羣磁盤總數 * celeborn.slots.assign.loadAware.discardDisk.maxWeight,例如我們總共有500塊磁盤,按上述公式我們最多可能容忍150塊磁盤不參與slot分配。對於高負載磁盤的判定,我們參考線上實際的平均讀、寫耗時閾情況將閾值設置為200ms。通過引入上述策略,在凌晨高峯期時能及時剔除部分負載特別高的磁盤,防止worker持續惡化讓服務性能更加穩定。
3.2.2 智能流量調度與權限管控
挑戰分析
在管理800+節點的Celeborn集羣時,我們面臨如下問題:
-
接入數量不可控:Master地址暴漏後無法控制接入人羣
-
任務流量不可控:異常大shuffle任務會衝擊整個集羣穩定性
-
故障隔離差:單集羣問題影響全站業務
-
運維複雜度:多集羣協同困難
客户端用户鑑權與任務切流
為了解決上述問題,我們在Celeborn 客户端側做了一些改造,用户接入Celeborn不再依賴Mater URL配置(spark.celeborn.master.endpoints),在客户端側僅需要配置一個Celeborn集羣標識,Celeborn客户端會基於集羣標識和用户賬號向VIVO配置中心發起請求,通過配置中心獲取真實的Master URL
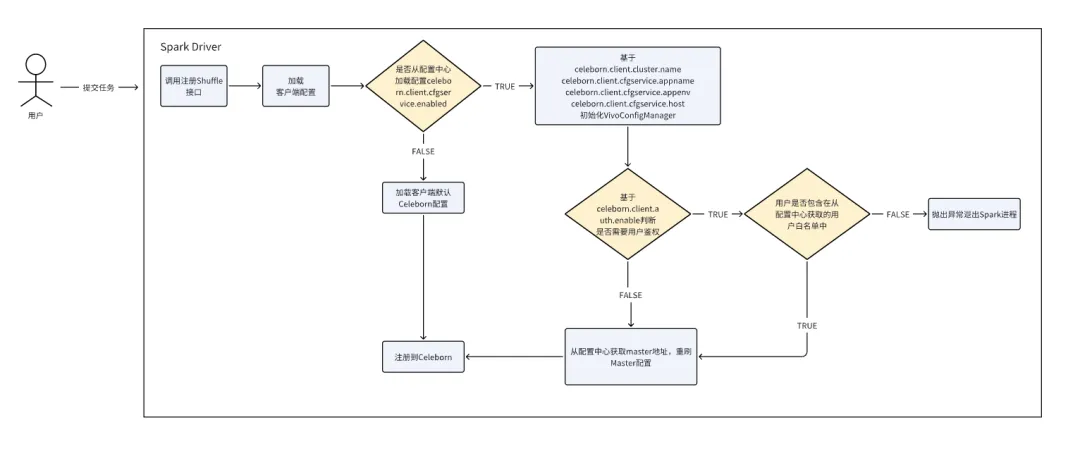
以上改造一個是解決了用户任務接入不受限制的情況,另一個是在客户端和集羣中間多了一個配置層,一旦單個集羣出現故障,可以通過在配置層修改Master URL進行熱遷移。
服務端異常shuffle流量識別
Celeborn開源版本提供一個CongestionControl功能,可以針對user粒度進行push過程的流量控制,在CongestionControl這套功能架構下有流量統計的模塊代碼(基於滑動窗口原理實現),可以基於該模塊做app粒度的流量監控,識別push流量明顯異常的application
Celeborn開源版user粒度Push異常流量識別流程圖:
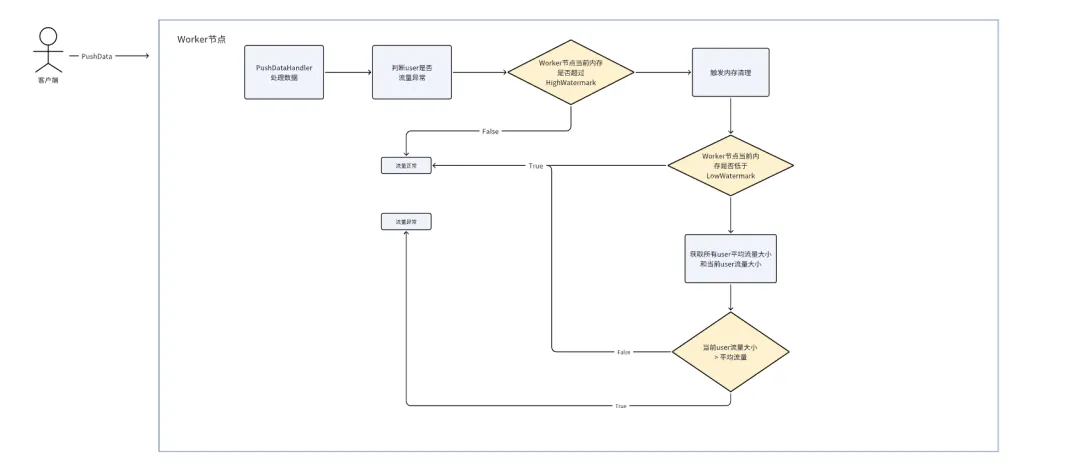
功能擴展:Shuffle Write階段App Push異常流量識別流程圖
相較於社區版user粒度的異常流量識別,app粒度的異常流量識別有更嚴格的判斷,首先該app本身的流量要大於設定的閾值(我們當前設定的是200MB/s),其次該app本身的流量要大於所有app平均流量/raito,raito相當於一個權重比例,通過以上兩種方式提升異常流量app的識別準確性。
服務端識別出異常app以後,會返回給客户端一個狀態碼,至於客户端如何處理,Celeborn有提供不同的PushStrategy給用户選擇(通過celeborn.client.push.limit.strategy配置),也可以自定義開發,常見的策略例如,客户端先暫停推送,間隔一段時間以後再恢復推動。
四、未來規劃與展望
作為支撐日均6PB級Shuffle數據、13萬+應用的核心基礎設施,我們的Celeborn集羣已進入穩定運營期,刷盤耗時控制在5ms以內(平均1.5ms),文件讀取耗時低於500ms(平均50ms)。這一成績的取得來之不易,但技術演進永無止境。後續我們會持續在運維平台化和社區跟進兩大方向投入人力去持續優化現有集羣,並進一步展望Celeborn在雲原生、智能化等前沿領域的可能性。
4.1 運維平台化:從黑屏操作到統一管理
當前Celeborn集羣的部署模式經歷了從Kubernetes獨立部署到物理機混合部署的演進,但運維操作仍以手工命令行為主,面臨三大核心痛點:
-
操作風險高:擴縮容、配置變更等關鍵操作依賴人工執行,易出錯且難以追溯
-
效率瓶頸:集羣規模突破800+節點後,人工運維響應速度跟不上業務需求
-
配置維護混亂:通過黑屏操作Celeborn服務很難統一集羣配置
目前我們所有大數據組件都是通過ambari做統一管理,未來我們也計劃將Celeborn服務加入ambari去管理,通過ambari去實現節點快速擴縮容、配置統一下發等替代人工黑屏操作的工作。
4.2 社區跟進:從版本滯後到行業對齊
當前集羣仍運行Celeborn 0.3.0版本,落後社區最新版本多個重要迭代,錯失了包括列式Shuffle、向量化加速等關鍵特性,版本升級不僅是功能更新,更是技術債償還的過程。Celeborn作為下一代Shuffle基礎設施,還有更廣闊的創新空間值得我們探索,後續我們團隊也會持續投入人力跟緊同行的步伐一起探索Celeborn的更多可能性。