

作者:vivo 互聯網項目團隊- Ding Junjie
摘要:作者通過使用Vibe Coding和Claude Code等AI編程工具的實踐經驗,分享了與AI協作的方法和技巧。文章探討了當前AI工具與理想中"賈維斯"智能助手的差距,包括缺少持續記憶、意圖理解需反覆對齊、決策點過於依賴人工等問題。作者提出了通過模板化常見場景、記錄決策過程、優化溝通方式等方法來改進人機協作模式,並構想了一個包含記憶層、執行層、學習層的AI組織者系統,為實現更智能的人機協作提供了思路和方向。
1分鐘看圖掌握核心觀點👇
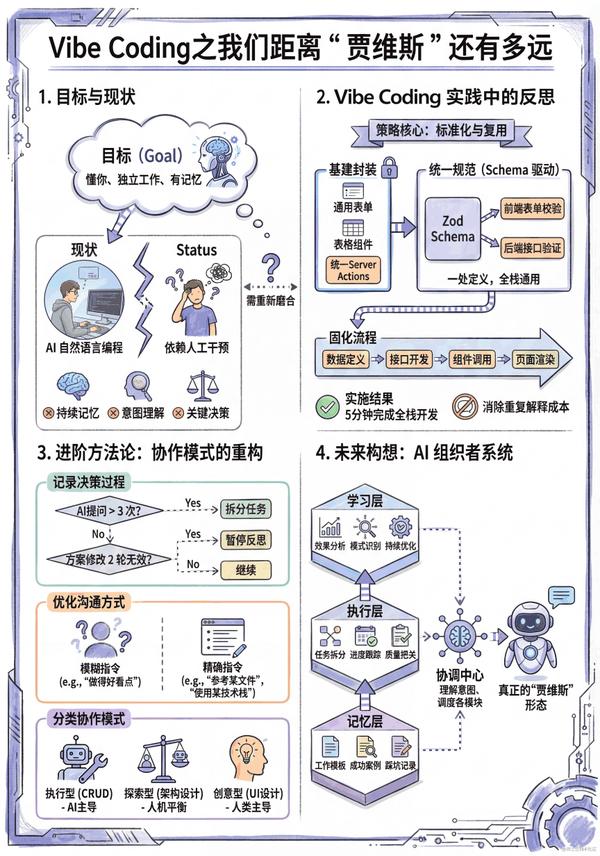

圖1 VS 圖2,您更傾向於哪張圖來輔助理解全文呢?歡迎在評論區留言。
一、前言
Vibe Coding 一年多了,最近試了 Claude Code。現在這個場景變得特別常見:我可以邊做飯邊寫代碼,順便還能擼個貓。
聽起來很玄?其實就是這樣:我只要把想法説清楚——比如"做個用户登錄頁面",AI就會自己去翻項目文件、理解代碼結構、查看接口文檔,然後一步步把功能實現出來。我完全不用一直盯着屏幕,去倒杯水、拿個快遞,回來就能看到能跑的代碼。
這種體驗讓我想起了《鋼鐵俠》裏的賈維斯——一個真正懂你、能獨立工作的智能助手。雖然現在的 AI Agent 主要還是在編程領域,但我相信這種"協作模式"會擴展到更多場景。

也許每個人都會有自己的"賈維斯"。想象一下:設計師只需要説"我想要一個温暖的品牌形象",賈維斯就能從市場調研到視覺設計全套搞定;醫生描述症狀,賈維斯瞬間整合全球病例數據給出診斷建議;老師説想讓學生更好理解量子物理,賈維斯就設計出沉浸式的教學方案...
這篇文章想分享一下我的體驗和思考。即使你不寫代碼,這些協作的思路也許對你有用。
二、我是怎麼和 AI 協作的?
開場先講清三件事:目標是什麼、背景信息在哪、有什麼限制條件。信息越清楚,執行效果越好。這樣 AI 就知道邊界在哪,不會跑偏。
任務大小動態調整:我不會一開始就把任務切得很細,而是先給一個相對大的目標。如果 AI 卡住了或者理解偏了,我就分析原因,把任務拆得更具體。這個過程很像項目管理——需要判斷是需求不清楚、信息不夠,還是執行思路有問題。
執行中的關鍵決策點:AI 工作過程中會遇到很多選擇:用什麼方案、怎麼處理異常情況、如何平衡各種因素。這些地方它會主動問我,或者我看到結果不對會及時糾正。這種反覆對齊想法的過程,其實是整個協作的核心。
基於反饋的迭代:每個階段性成果都是一次反饋。不是按時間切分,而是按"能否驗證"來切分。做出來了、能用了、效果出來了,這些都是天然的檢查點。
用了這套方法後,效率確實提高了很多。但用得越多,我越發現離真正的賈維斯還有明顯差距。
三、距離賈維斯,我們還差什麼?
仔細想想賈維斯和現在AI的區別:賈維斯不需要託尼每次都詳細解釋背景,它"記得"之前所有的項目、偏好和決策模式。而我現在每次還得從頭描述上下文,重新磨合工作習慣。
差距1:缺少持續記憶
每次協作都要重新"磨合"。即使是做過很多次的任務,我還是得重新解釋背景、重新設定邊界。AI沒有"工作記憶"。
差距2:意圖理解還需反覆對齊
傳統的聊天模式很低效——你説一大段,AI理解偏了,再糾正,來回好幾輪。雖然也能解決問題,但這個過程還是很"手工"。
差距3:決策點太依賴人工
真正有挑戰的不是讓AI幹具體的活,而是那些需要人來決策的地方:
- 什麼時候該把大任務拆小?拆到什麼程度?
- 不同階段需要什麼背景資料?
- AI的輸出質量如何?是繼續還是調整方向?
- 業務在變化,如何讓系統的"記憶"保持新鮮?
能不能把這些痛點系統化解決?
四、一口吃不成胖子,但是一定有向前探索的路徑
先找到重複的操作,把這些重複的協作模式"重構"一下
實戰案例:我給 AI 搭了條"流水線"
我在一個 Next.js 全棧項目裏,我做了一套標準化的工作流
效果:現在 AI 可以在 5 分鐘內從數據庫到後端到前端完成一個完整的 業務功能。
小科普:Next.js 是一個全棧框架,可以在一個項目裏同時寫前端和後端。它的 Server Actions 功能讓你可以直接在前端調用後端函數,就像調用普通函數一樣,不需要寫傳統的 API 接口(也可以寫接口)。
核心是三件事:
1. 基礎能力已經封裝好,直接用
- 支持配置的表單組件(輸入框、下拉框、富文本編輯器、等等)
- 支持配置的表格組件(支持排序、篩選、分頁)
- 統一的 Server Actions 客户端(封裝了authActionClient,負責權限校驗,actionClient無校驗,都記錄日誌)
2. 定義統一規範
- 數據結構定義一次,前後端共用(藉助zod的schema)
- 前端校驗表單、後端驗證接口,用的是同一套規則
- 類型安全貫穿全棧,改一處同步生效
3. 固化工作流程
- 數據定義 → 後端接口 → 前端組件 → 頁面
- 每一步都有明確的規範,AI 照着走就行
舉個例子,我説:"做一個景點管理功能,包括增刪改查。"
AI 就按照固定的流程開始工作了:
1. Schema 定義 (數據的"身份證",只寫一次,前後端都用)
// 表單用的 schema - 定義用户要填什麼
const attractionFormSchema = z.object({
name: z.string().min(1, '名稱不能為空'),
cityId: z.string().min(1, '請選擇城市'),
minDays: z.coerce.number().int().positive(),
imagePaths: z.array(z.string()).optional()
});
// 列表用的 schema - 定義展示什麼數據
const serializableAttractionSchema = attractionFormSchema.extend({
id: z.string(),
createdAt: z.date(),
city: z.object({ id: z.string(), name: z.string() }),
images: z.array(z.object({ path: z.string() }))
});2. Server Actions (後端函數,注意這裏用了同一個 attractionFormSchema)
// 創建景點的後端函數
exportconst createAttraction = authActionClient // 需要登錄才能調用
.inputSchema(attractionFormSchema) // ← 和前端用的是同一個 schema!
.action(async ({ parsedInput }) => {
// parsedInput 已經過校驗,類型安全
const attraction = await prisma.attraction.create({
data: parsedInput
});
return { success: true, data: attraction };
});3. 前端表單 (同樣也用 attractionFormSchema)
const form = useForm({
resolver: zodResolver(attractionFormSchema), // ← 還是這個 schema!前端自動校驗
defaultValues: { name: '', cityId: '', minDays: 1 }
});
const onSubmit = async (values) => {
// 直接調用後端函數 createAttraction,就像調用本地函數一樣
await createAttraction(values);
};4. 數據表格 (列配置 + 數據,配置化表格直接渲染)
const columns = [
{ id: 'name', header: '景點名稱', enableSorting: true },
{ id: 'city', header: '所在城市', enableSorting: true },
{ id: 'minDays', header: '建議遊玩天數', enableSorting: true }
];為什麼這麼快?
因為我不需要每次都解釋"怎麼做表單校驗"、"怎麼調用接口"、"怎麼展示列表"。這些基礎能力都已經封裝好了,AI 只需要:
- 定義一次 schema(數據結構即規則)
- 前後端都用這個 schema(前端校驗表單,後端校驗接口,改一次同步生效)
- 配置表單和表格(組件直接用,Schema 驅動)
上面的代碼,attractionFormSchema 這個變量:
- 在前端的 zodResolver(attractionFormSchema) 裏用了
- 在後端的 .inputSchema(attractionFormSchema) 裏也用了
- 同一個定義,確保前後端的校驗邏輯完全一致
這就像搭樂高:
- 積木塊(基礎組件)都是現成的
- 説明書(工作流程)是標準的
- 圖紙(Schema)定義了要搭什麼
更關鍵的是可複用:這套標準適用於任何 CRUD 場景。做"用户管理"、"訂單管理"、"商品管理",流程完全一樣,只是改改 schema 字段。
我只需要告訴 AI "要管理什麼數據",剩下的都是標準化執行。這就是"模板化"的價值——把重複的協作模式提煉成標準流程,讓 AI 可以直接套用。
上面的 CRUD 只是一個例子。要想真正建立起這套協作模式,需要在幾個方面持續積累:
4.1 記錄決策過程
那些關鍵的決策點——什麼時候需要拆分任務、什麼時候該換思路、哪些反饋信號最有效。這些"套路"可能比具體的執行技巧更有價值。
我總結的幾個決策規則:
- 任務拆分信號:當 AI 連續問了 3 個以上的澄清問題,説明任務太大了,該拆分了。
- 方向調整信號:如果一個方案改了 2 輪還不對,不是繼續修,而是停下來重新思考方向(checkPointer)。
- 文檔同步規則:每次修改數據庫 schema,AI 會自動提醒"是否需要更新 API 文檔?"這是我之前踩坑總結出來的。
這些決策規則就像"編程規範",一旦記錄下來,AI 每次遇到類似情況都能按規則處理,不需要我反覆提醒。
4.2 優化溝通方式
觀察哪些任務描述效果好,哪些容易讓 AI 理解偏。
效果好的描述方式:
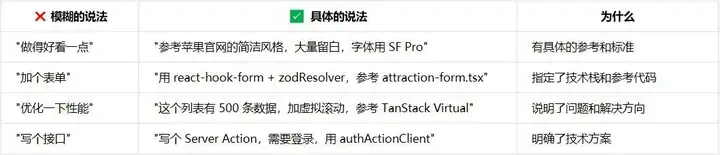
我的溝通技巧:
- 指向具體文件:"參考 attraction-action.ts 的寫法",比"寫一個增刪改查接口"清楚得多。
- 提供邊界條件:"表單字段不超過 10 個"、"列表支持排序和搜索,不需要高級篩選"。
- 説明優先級:"先做基礎功能,圖片上傳放後面"。
溝通的本質是降低理解成本,越具體的描述,AI 的執行越準確。
4.3 分類協作模式
不同類型的工作,人機協作的方式是不同的。我把協作模式分成了幾類:
執行型任務(AI 主導)
- 特徵:有明確的標準和規範
- 例子:CRUD 開發、代碼重構、bug 修復
- 協作方式:我提供規範 + 驗收標準,AI 執行 + 我檢查結果
探索型任務(人機平衡)
- 特徵:需要嘗試多個方案
- 例子:性能優化、算法選型、架構設計
- 協作方式:AI 給出 3-5 個方案 + 優缺點分析,我決策後 AI 執行
創意型任務(人類主導)
- 特徵:需要創新和審美判斷
- 例子:UI 設計、產品定位、文案撰寫
- 協作方式:我提供靈感和方向,AI 提供素材和具體實現
學習型任務(雙向互動)
- 特徵:我不熟悉的技術領域
- 例子:學習新框架、理解複雜代碼
- 協作方式:AI 解釋概念 + 提供示例,我提問 + AI 補充
關鍵發現:執行型任務標準化程度越高,AI 效率越高。這也是為什麼 CRUD 這種重複性工作最適合用 AI。
一次提煉,多次複用,這才是標準化協作模式的真正價值。
這讓我想到一個有趣的可能性:如果有一個系統能夠:
- 統一管理工作的背景資料和相關文檔
- 記錄每次的任務拆分和決策過程
- 分析哪些協作模式效果最好
- 甚至基於用户的工作習慣進行學習和優化
這不就是賈維斯的初級形態嗎?
🤔 賈維斯初級版:AI 組織者系統
如果要設計這樣一個系統,也許需要這幾個部分:
📚 記憶層 🎯 執行層 📊 學習層
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 工作模板? │◄───────►│ 任務拆分? │◄──────►│ 效果分析? │
│ 成功案例? │ │ 進度跟蹤? │ │ 模式識別? │
│ 踩坑記錄? │ │ 質量把關? │ │ 持續優化? │
└─────────────┘ └─────────────┘ └─────────────┘
▲ ▲ ▲
│ │ │
└────────────────────────┼───────────────────────┘
▼
┌─────────────────────┐
│ 🤖 協調中心? │
│ │
│ 這裏應該做什麼?? │
│ • 理解用户意圖? │
│ • 調度各個模塊? │
│ • 整合反饋信息? │
└─────────────────────┘這樣的系統可能比單純的 AI 工具更有價值。它不只是幫你幹活,還能幫你總結經驗、優化流程。
五、寫在最後
分享這些體驗,主要是想拋磚引玉。我相信很多人都有類似的感受,也有自己的協作技巧。
如果把這些個人經驗匯聚起來,會不會產生一些有趣的化學反應?比如:
- 不同人的任務拆分策略有什麼共性?
- 哪些決策點是最關鍵的?
- 如何設計一個既能學習又能適應的協作系統?
- 人機協作的最佳實踐是什麼?
我覺得這些問題比單純提升 AI 能力更有意思。畢竟,真正的賈維斯不只是一個更強的助手,而是一個懂你的協作夥伴。
這一天,可能比我們想象的更近。關鍵是要找到正確的路徑。
*本文僅分享作者基於個人技術實踐的思考和主觀觀點,不構成決策依據。