

1)遊戲項目中如何制定資源管理與加載策略
2)對於熱更新包體大小的最佳實踐
3)URP某些Shader資源多次出現
4)關於手機發熱問題如何入手
5)如何優化Delegate.Add/Remove這類堆內存的分配
這是第267篇UWA技術知識分享的推送。今天我們繼續為大家精選了若干和開發、優化相關的問題,建議閲讀時間10分鐘,認真讀完必有收穫。
UWA 問答社區:answer.uwa4d.com
UWA QQ羣2:793972859(原羣已滿員)
Addressable
Q:第一個問題:現在Addressable的使用情況怎麼樣?使用類似Xassets一類的插件用於資源管理怎麼樣?
第二個問題:遊戲啓動的時候,熱更資源,資源文件下載是以散文件的方式一個個下載好,還是打成一個整包下載好?
第三個問題:以前我們把AssetBundle包打到安裝包內,然後安裝完之後第1次啓動時要把AssetBundle包解壓到外面文件夾。這麼做的好處就是統一維護一個外部資源目錄,加載資源時不需要先判斷外面目錄再判斷裏面,然後根據資源在哪個目錄寫兩種不同的加載方式。但是如果解壓到外面,安裝完之後整個遊戲會增大很多。聽説加載包內的資源比加載包外的更快,所以想問一下有沒有必要再做解壓這一個步驟?
A1:回答如下:
1.現在不太建議使用原生Addressable,因為在目前看到的一些項目中,冗餘問題依然存在,而且無論是加載還是內存,問題都很多。加載的效率並不高,一旦做錯,還會造成更差的問題,容錯率比較低。
現在的大型團隊基本上都在自己寫這套系統了,便於查找原因。加載這塊屬於一個遊戲的骨架(龍骨),不出問題沒人注意,一出問題就有可能是致命的。
2.Xasset沒做過調研不太清楚。
3.打成一個整包的,然後做差異化包,版本跨度越大,差異包越多,大文件下載也要考慮到斷點續傳的問題和多線程下載。要做很多處理,可能要接一個小插件,做加速、做斷點續傳、做多線程等,容易出問題。
散文件、顆粒度比較小,每次更新就更新幾個文件,不用生成差異包。大版本更新就會下很多文件,但是不用考慮它的斷點續傳,因為文件比較小。還有一個好處就是同時可以起多條鏈接下載,安卓目前取消了鏈接數量上限,但是IO會很多。
4.沒有必要解壓,它在包內StreamingAssets下也是非壓縮的,所以加載效率沒問題。
該回答由UWA提供
A2:冗餘問題, 估計他們是沒有用Analyze工具分析冗餘,我做過實驗用Analyze工具分析解決冗餘後,把生成後的Bundle提交到UWA的資源檢查,分析得到的結果符合預期,沒有意外的冗餘問題,基本檢查出的冗餘,只要你用工具解決了,分析後冗餘就不存在了。
感謝在路上哈哈@UWA問答社區提供了回答
A3:稍微補充一下:
1.Addressable針對做分包(核心包、可選包等)支持並不好,雖然有Catalog的分別下載更新,但是製作層面卻沒有很好支持。異步加載流程不能被Cancel掉,一旦發起必須走完,最後説這個資源不要了。它算是一項可選的比較通用的解決方案,但還是太通用和初級,一些中小型項目還是可以用的。但是項目一旦做複雜點,需求多了就可能應付不了。當然這也是Unity團隊無法面面俱到、對應齊全的。一種思路是前期使用它,然後需要安排人深入理解和掌握,到項目中後期出現需求的時候動手改,畢竟代碼都有。相對自己從0開始做一套系統還是有優勢的。2.下載環節還是建議考慮合包下載,畢竟不停開關N個HTTP連接消耗也是不少的,尤其當下載的粒度太細,Patch本身Size很小的情況下,會發現下載速度上不去。可以考慮客户端處理上還是小文件,但服務器端將相關Patch整理在一起合進大文件,然後利用HTTP的Range下載模式來定位下載這個大文件中一部分連續數據,這樣減少HTTP連接數,提高下載效率。
3.讀取在StreamingAssets內的AssetBundle文件不大,引擎自己搞定,但是讀取非AssetBundle的資源,在Android平台下需要自行處理一下,無法用File.Open的形式打開,需要接入NDK的AAssetManager接口來訪問。
感謝黃程@UWA問答社區提供了回答,歡迎大家轉至社區交流:
AssetBundle
Q:對於熱更新包體的大小,最佳實踐是多少?多大以上的更新建議不採用熱更新而採用全包更新?如果一次更新的內容比較大,是否建議還是全包更新比較合適?包含多個AssetBundle。
A1:基本上現在AssetBundle都已經將其每個大小控制在5~10MB以下(5.3以前是1MB),這樣就可以保證IO次數和熱更新內容都儘可能小。
整包更新都不太好,會有大概10~15%的用户流失,所以能熱更還是熱更。熱更新包的大小主要是去除冗餘,因為LZ4本身已經是壓縮級別了。
感謝OCEAN@UWA問答社區提供了回答
A2:國內渠道商比較多,獲客成本比較高,所以換包的損失比較大,能走熱更新還是儘量走熱更新。
然後也可以考慮一下國內的一些第三方熱更公司,比如樂變,他們支持無感知邊玩邊下,以熱更新的方式替換主包。
感謝蕭小俊@UWA問答社區提供了回答,歡迎大家轉至社區交流:
Shader
Q:如下圖所示:
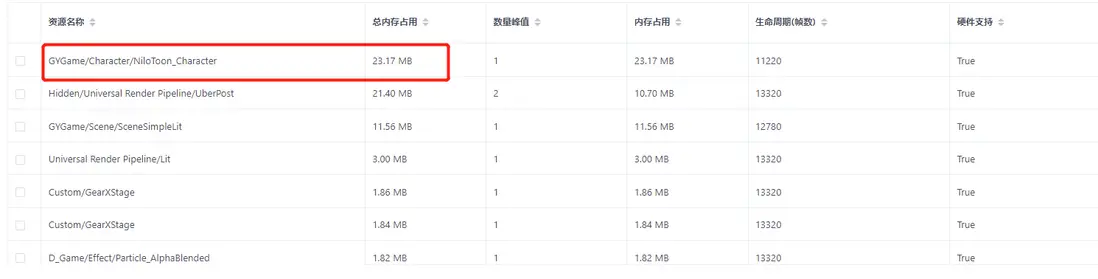
1.現象:這些資源出現2份是什麼原因?
2.目前Shader內存佔用太高了,能否給些推薦建議?
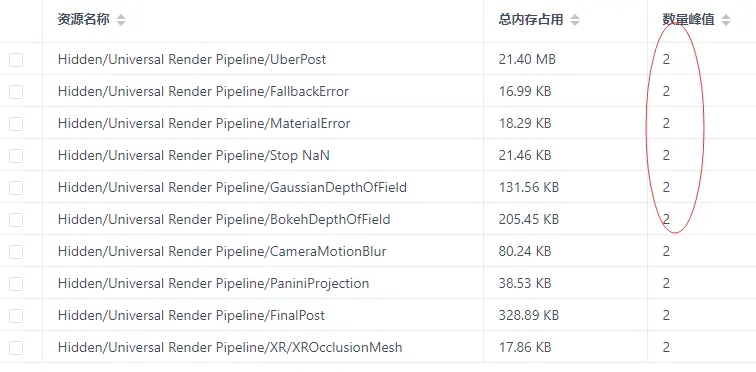
A:1.在編輯器中,當GraphicsSettings裏面設置了RenderPipelineAsset之後,RenderPipelineAsset最終會引用PostProcessData,PostProcessData中引用了各種後處理相關的Shader,所以打包的時候,會將各種後處理相關的Shader打包進包體,比如UberPost、Bloom等。
而且這些資源會在RenderPipeline初始化的時候被加載進內存。這是UberPost的第一個實例的來源。
2.當我們在遊戲實時運行的時候,比如涉及到切換RenderPipeline的操作,使用了AssetBundle加載RenderPipelineAsset,這樣在AssetBundle中就又有了一份PostProcessData,因此這些後處理相關的Shader就又被加載了一次。總共就有2份UberPost了。
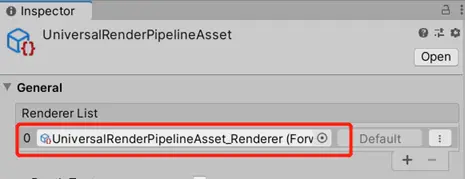
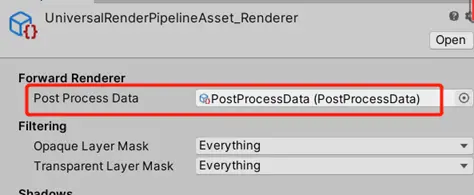
3.對此我們建議所有的RenderPipelineAsset相關的資源都由AssetBundle處理,在Editor的GraphicsSettings中將RenderPipelineAsset移除。通過腳本來動態從AssetBundle中加載並賦值。
4.可以創建一個空場景放在所有場景之前,在這個場景中動態加載RenderPipelineAsset,並賦值給GraphicsSetting.renderPipelineAsset,如下圖:
之後所有的問題都只要注意AssetBundle的冗餘就可以了。
優化Shader:
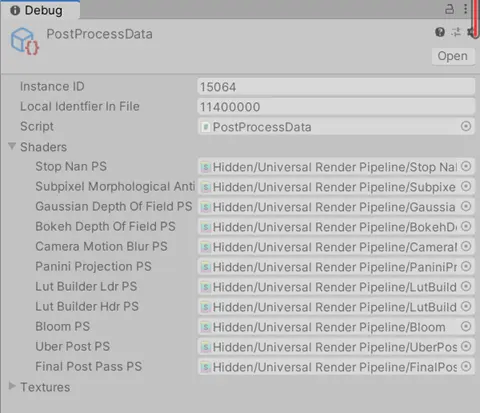
1.UberPost的Shader可以考慮將用不到的Keyword給註釋掉。如下圖:
2.對於內存佔用非常多的Shader,需要優化Keyword組合數量,建議參考《Stripping scriptable shader variants》,使用後處理來優化Shader變體組合數量。

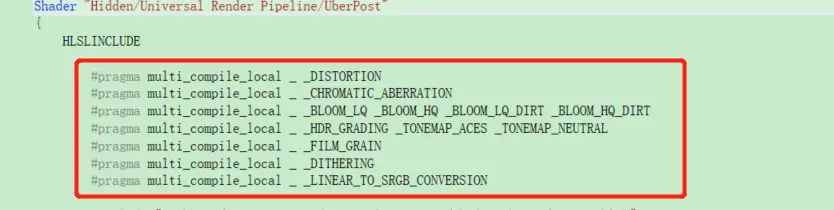
感謝一直有點困的倉鼠@UWA問答社區提供了回答,歡迎大家轉至社區交流:
Performance
Q:關於手機發熱問題,該從哪些方面入手?我們項目主要有大量PBR,另外模型都是高模。是不是手機性能越高,發熱越明顯?
A1:這個可以反推一下:
發熱=耗電高
耗電高=GPU CPU高負荷
最有效的方式應該是先鎖幀,然後就是想辦法優化GPU和CPU了,針對這2個優化方案有很多,可以找找適合你們項目的。
感謝蕭小俊@UWA問答社區提供了回答
A2:回答如下:
1.發燙的問題都是從CPU\GPU和IO入手的。
2.不是。性能越差,同樣的計算力,發熱才會更明顯。這塊個人認為是需要定位下耗時在哪裏才好做判斷的。沒有統一説性能好發熱也明顯的説法。比如:你們做了分級策略,在高端設備上開的效果越大,那自然發熱發燙就明顯。
感謝OCEAN@UWA問答社區提供了回答
A3:發熱是一定會有的,並不是説做好了之後就沒有發熱,而是多久能發熱到多少度,達到一個預期就行:
1.首先要定好分級策略,其次再查對應分級設備上的發熱問題。
2.還有就是先限制好30幀,做好30幀的發熱問題,再去做高幀率的發熱問題。
3.可以通過UWA的温度模塊看發熱的趨勢,還是比較準確的,温度過高就會導致降頻。
4.就我們項目解決發熱的流程來看,發熱與功耗是正相關的。這個功耗可能是CPU,也可能是GPU,功耗可以通過PerfDog查看,也可以參考雨鬆的文章《Unity3D研究院之實時獲取手機電流、電壓、計算功率發熱(一百一十八)》,分別測試CPU和GPU哪塊功耗高具體定位一下。
PBR項目可能主要是GPU,GPU主要就是帶寬和計算量,帶寬佔大頭,帶寬也分為兩部分Read/Write Bandwidth。Read是上傳幾何信息和貼圖,Write主要是寫回到FrameBuffer和RT的存儲,關於帶寬可以使用Arm MS StreamLine工具或者PerfDog輔助查看一下(只有Mali的GPU可以看),到最後可能還是讓美術去優化資源。
5.CPU的就要具體模塊具體看了,注意線程的使用。Profiler看不到,當時我們就是遇到線程內的問題導致的發熱,查起來比較麻煩。
感謝範世青@UWA問答社區提供了回答,歡迎大家轉至社區交流:
Script
Q:如何優化Delegate.Add/Remove這類堆內存分配問題?
A1:降低使用頻率,尤其是不要在一個代理里加過多的函數,會導致其堆內存分配更大,因為其實現原理是複製一個List來使用的。
感謝OCEAN@UWA問答社區提供了回答
A2:其實Delegate的+= 是會有很嚴重的GC問題的,可以考慮用一個字典去代替。

感謝蕭小俊@UWA問答社區提供了回答,歡迎大家轉至社區交流:
20210913
更多精彩問題等你回答~
1.Vulkan API的性能及兼容性
2.Unity TMP字體方案如何選擇
3.如何實現AAB包的增量更新
封面圖來源於網絡
今天的分享就到這裏。當然,生有涯而知無涯。在漫漫的開發週期中,您看到的這些問題也許都只是冰山一角,我們早已在UWA問答網站上準備了更多的技術話題等你一起來探索和分享。歡迎熱愛進步的你加入,也許你的方法恰能解別人的燃眉之急;而他山之“石”,也能攻你之“玉”。
官網:www.uwa4d.com
官方技術博客:blog.uwa4d.com
官方問答社區:answer.uwa4d.com
UWA學堂:edu.uwa4d.com
官方技術QQ羣:793972859(原羣已滿員)
