

近日,DeepSeek 連續發佈兩款新模型——DeepSeek‑V3.2 與 DeepSeek‑V3.2‑Speciale,憑藉顯著提升的推理能力在業界引發關注。DeepSeek‑V3.2 已能與 GPT‑5 正面競爭,Speciale 則在長思考與定理證明方面媲美 Gemini‑3.0‑Pro,甚至被部分用户戲稱應改名為 V4。
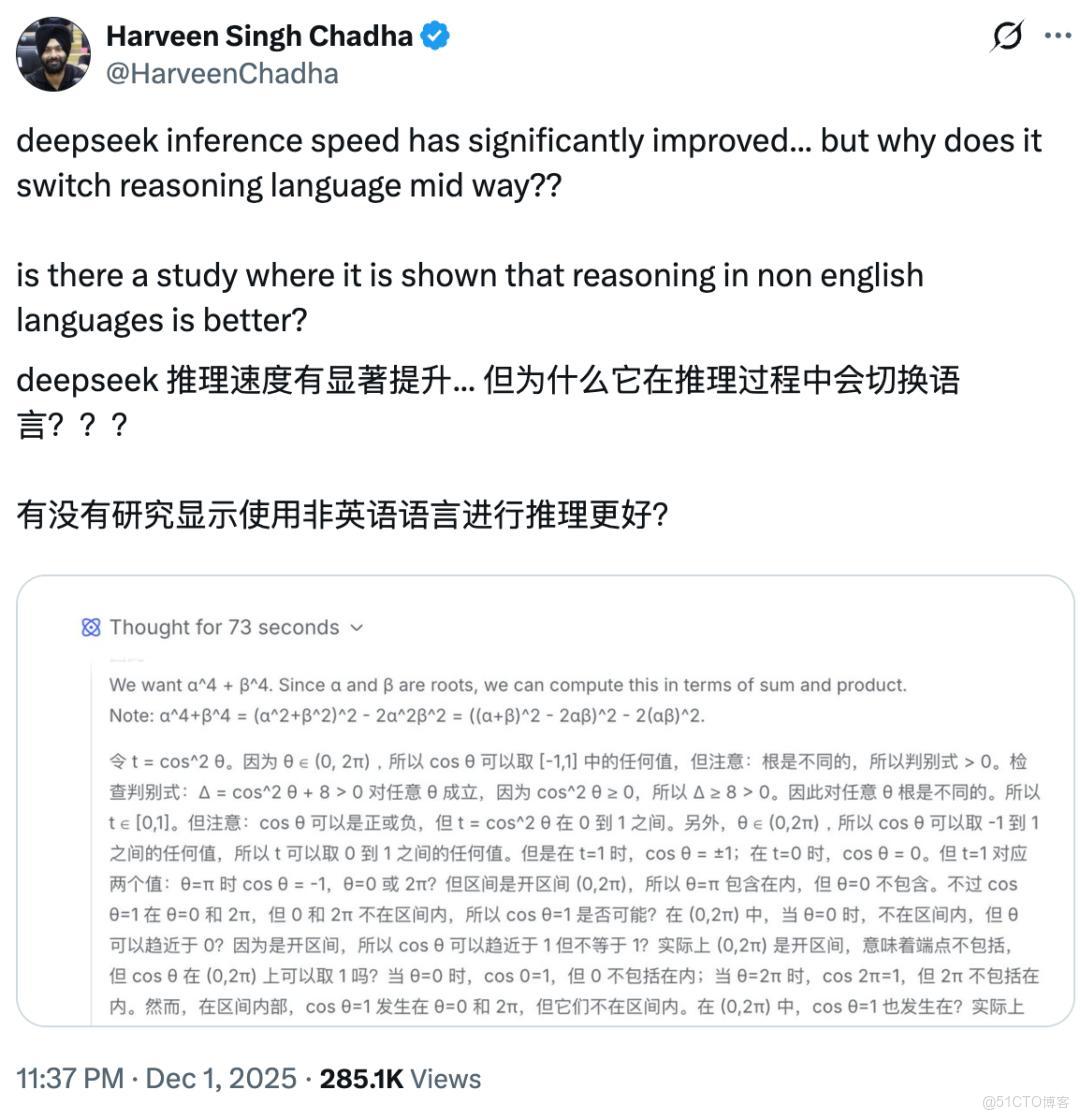
然而,海外研究者在使用英文提問時,卻意外發現模型的內部推理過程仍會切回“神秘的東方文字”。一張展示模型思考軌跡的截圖顯示,儘管輸入為英文,DeepSeek 在內部仍以中文進行推理,這讓不少國外用户感到“傻眼”。評論區的聲音分為兩派:一方認為中文信息密度更高,能夠在相同語義下使用更少的字符;另一方則指出模型訓練數據中中文佔比更大,導致模型傾向中文思考。

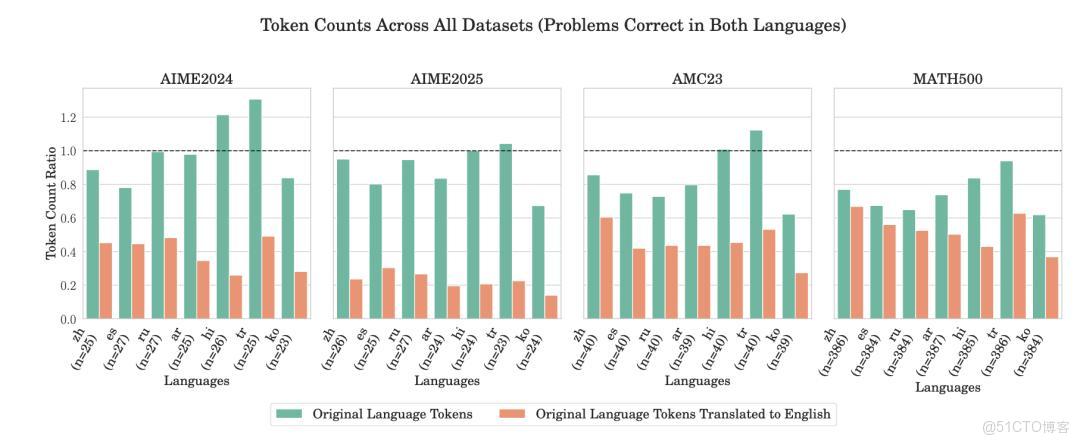
對此,來自亞馬遜的研究者進一步解釋:中文的字符信息密度確實更高,因而在 token 壓縮上更具優勢。若大模型的推理與語義壓縮相關,中文相較於英文在 token 使用上更為高效,這也解釋了“中文更省 token”的説法。與此同時,微軟最新論文《EfficientXLang: Towards Improving Token Efficiency Through Cross‑Lingual Reasoning》指出,使用非英語語言進行推理可在 20%‑40% 的範圍內顯著降低 token 消耗,而準確率基本不受影響。實驗中,DeepSeek‑R1 在中文推理時的 token 減少量為 14.1%‑29.9%,而其他語言(如西班牙語)甚至更高。
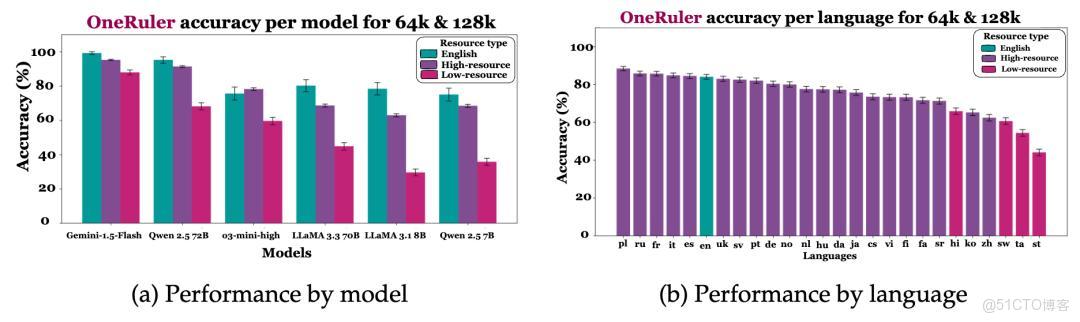
另一篇由馬里蘭大學與微軟合作的論文《One ruler to measure them all: Benchmarking multilingual long‑context language models》進一步表明,長上下文任務中,英語並非表現最佳語言,波蘭語在 26 種語言中排名第一,中文僅居第六。該研究顯示,模型在不同語言間的性能差異受多因素影響,訓練數據分佈、語言資源豐富度以及模型架構均起關鍵作用。
綜合上述研究,業內普遍認為 DeepSeek 在英文提問時仍使用中文思考,主要源於兩大因素:
訓練數據傾斜——DeepSeek 採用了大量中文語料進行預訓練,模型內部語言偏好自然傾向中文。
語言效率優勢——中文字符的高信息密度在 token 計數上具備天然優勢,能夠在保持推理質量的同時降低計算成本。
對此,DeepSeek 官方在 36 氪授權發佈的文章中指出,模型的多語言推理能力並非單純追求效率,而是兼顧了訓練數據的分佈特性與實際使用場景的需求。未來,隨着更多非英語語料的引入和跨語言推理技術的進一步優化,模型在不同語言間的切換或將更加平滑,避免出現“中文思考”這種讓海外用户感到意外的現象。
結語
DeepSeek 的“中文思考”現象折射出大模型在多語言環境下的複雜平衡:既要利用中文的高信息密度提升推理效率,又要兼顧訓練數據的多樣性以滿足全球用户需求。隨着跨語言推理研究的深入,業界期待看到更為均衡、透明的多語言模型表現。